
- 1【Python】nltk库使用报错之punkt安装_nltk punkt
- 2超简单的Unity AR新手教程|五分钟上手_unity ar开发教程
- 3【安卓-自定义布局】安卓App开发思路 一步一个脚印(十)实现内嵌在app中的webview 腾讯开源X5 高效安全_安卓app webview模板
- 4专业140+总分420+天津大学815信号与系统考研经验天大电子信息与通信工程,真题,大纲,参考书。
- 5react router
- 6数据结构之----栈、队列、双向队列_先入后出的线性结构是
- 7linux 服务器进程、端口查找,nginx 配置日志查找,lsof 命令详解_linux查看nginx端口
- 8Java开源B2B2C商城搭建(H5+app+多端)_java b2b2c
- 9速盾:高防cdn和普通cdn的区别?
- 10每日一题python88:回文链表_判断回文链表python
CVPR2024满分论文出炉!分割万物再次火爆AI界
赞
踩
去年4月,Meta公布了一款名为SAM(Segment Anything Model)的技术,这是一个用于图像分割的AI大模型,会对图像进行观察、感知、思考、逻辑推理、得出结果,且操作极其简单。
我们邀请到台湾交通大学博士,多篇顶会一作作者Shawn老师为我们带来——“分割万物”的超强SAM模型,详解SAM模型的过去和未来的优化改进方向!
扫码免费参与课程
赠导师推荐50+最新SAM论文&ppt原稿

(文末福利)

2023最新50+SAM模型论文展示
课程讲师:Shawn老师
-台湾交通大学PHD
-以第一作者发表多篇论文,包括ICLR、ICDE等
-获多项校级奖学金,AI竞赛,并与新加坡科技部有合作
-研究方向: 深度学习,计算机视觉,音乐生成,多模态
课程大纲
1、SAM模型的劣势
2、SAM模型改进方向
3、SAM模型改进方法
扫码免费参与课程
赠导师推荐50+最新SAM论文&ppt原稿

(文末福利)

2023最新50+SAM模型论文展示
SAM 是一个提示型模型,其在 1100 万张图像上训练了超过 10 亿个掩码,实现了强大的零样本泛化。许多研究人员认为「这是 CV 的 GPT-3 时刻,因为 SAM 已经学会了物体是什么的一般概念,甚至是未知的物体、不熟悉的场景(如水下、细胞显微镜)和模糊的情况」,并展示了作为 CV 基本模型的巨大潜力。
它可以根据点、框、文本等输入形式,生成图像中所有对象的高质量掩模(Mask)。
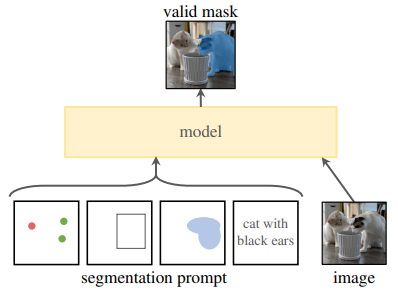
然而,sam模型仍有很多改进的方向,譬如,模型参数量较大,推理时间较长,对于某些特殊的目标分割效果较差(裂缝,阴影,医学影像等),无法分割复杂的物体结构,细粒度不足等问题。针对这些问题,仍有很大的改进空间。
扫码免费参与课程
赠导师推荐50+最新SAM论文&ppt原稿



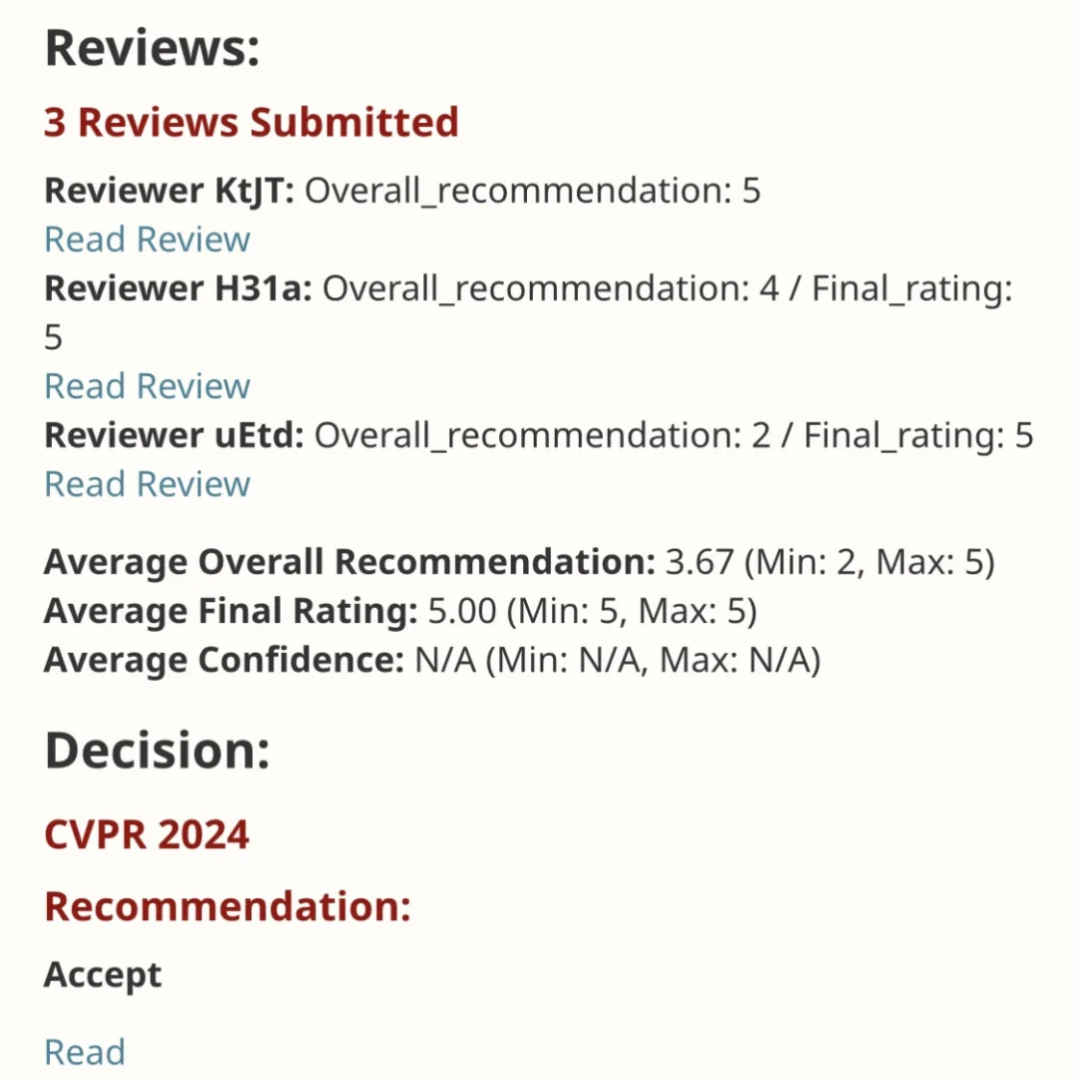
EfficientSAM 这篇工作以5/5/5满分收录于CVPR 2024!作者在某社交媒体上分享了该结果,如下图所示:
在最近的一项研究中,Meta 研究者提出了另外一种改进思路 —— 利用 SAM 的掩码图像预训练 (SAMI)。这是通过利用 MAE 预训练方法和 SAM 模型实现的,以获得高质量的预训练 ViT 编码器。

这一方法降低了 SAM 的复杂性,同时能够保持良好的性能。具体来说,SAMI 利用 SAM 编码器 ViT-H 生成特征嵌入,并用轻量级编码器训练掩码图像模型,从而从 SAM 的 ViT-H 而不是图像补丁重建特征,产生的通用 ViT 骨干可用于下游任务,如图像分类、物体检测和分割等。然后,研究者利用 SAM 解码器对预训练的轻量级编码器进行微调,以完成任何分割任务。
为了评估该方法,研究者采用了掩码图像预训练的迁移学习设置,即首先在图像分辨率为 224 × 224 的 ImageNet 上使用重构损失对模型进行预训练,然后使用监督数据在目标任务上对模型进行微调。
通过 SAMI 预训练,可以在 ImageNet-1K 上训练 ViT-Tiny/-Small/-Base 等模型,并提高泛化性能。对于 ViT-Small 模型,研究者在 ImageNet-1K 上进行 100 次微调后,其 Top-1 准确率达到 82.7%,优于其他最先进的图像预训练基线。
研究者在目标检测、实例分割和语义分割上对预训练模型进行了微调。在所有这些任务中,本文方法都取得了比其他预训练基线更好的结果,更重要的是在小模型上获得了显著收益。
对于还没有发过第一篇论文,还不能通过其它方面来证明自己天赋异禀的科研新手,学会如何写论文、发顶会的重要性不言而喻。
发顶会到底难不难?近年来各大顶会的论文接收数量逐年攀升,身边的朋友同学也常有听闻成功发顶会,总让人觉得发顶会这事儿好像没那么难!
但是到了真正实操阶段才发现,并不那么简单,可能照着自己的想法做下去并不能写出一篇好的论文、甚至不能写出论文。掌握方法,有人指点和引导很重要!
还在为创新点而头秃的CSer,还在愁如何写出一篇好论文的科研党,一定都需要来自顶会论文作者、顶会审稿人的经验传授和指点。
很可能你卡了很久的某个点,在和学术前辈们聊完之后就能轻松解决。
扫码二维码
免费与大牛导师1v1meeting

文末福利
给大家送一波大福利!我整理了100节计算机全方向必学课程,包含CV&NLP&论文写作经典课程,限时免费领!


立即扫码 赠系列课程
-END-

