
- 1智慧城管数据普查与综合数据建库_沭阳市城市部件普查
- 2C语言面向对象
- 3golang使用mqtt协议_golang setdefaultpublishhandler
- 4SpringBoot及其拓展_springboot可扩展性
- 5Codeforces 1120 D Power Tree —— 最小生成树_codeforces 最小生成树
- 6都什么年代了,你居然还连不上GitHub?
- 7多人姿态估计反思论文: Simple Pose(三)_bool simplepose::hasgpu = true;
- 8【不忘初心】Win10_2004.19041.329_X64_七合一_[纯净精简版](2020.06.18)
- 9Images之Dockerfile中的命令1
- 10python3后端加密,vue解密_vue + python3 sm2
大语言模型介绍(一)
赞
踩
什么是大语言模型
由于ChatGPT的火爆把大语言模型这个新名词推到了大众的视野里。那么,什么是大语言模型? 什么是GPT?
WIKI百科对大语言模型是这样解释的。
大语言模型 (英语:large language model,LLM) 是一种语言模型,由具有许多参数(通常数十亿个权重或更多)的神经网络组成,使用自监督学习或半监督学习对大量未标记文本进行训练。大型语言模型在 2018 年左右出现,并在各种任务中表现出色。尽管这个术语没有正式的定义,但它通常指的是参数数量在数十亿或更多数量级的深度学习模型。大型语言模型是通用的模型,在广泛的任务中表现出色,而不是针对一项特定任务。
翻译成白话就是在2018年开始陆续出现的一种技术(后续会解释为啥是2018年才开始陆续出现),这种技术的特征一个是大,一个是有通用性。
那什么是GPT呢?WIKI百科的解释是:
GPT(Generative pre-trained transformers)是一种大语言模型, 是生成式人工智能的重要框架。 第一个 GPT 于 2018 年由美国人工智能 (AI) 公司 OpenAI 推出。 GPT 模型是基于 transformer 架构的人工神经网络,在未标记文本的大型数据集上进行预训练,能够生成新颖的类人内容。
简单理解GPT其实是一种大语言模型技术的实现方案,由美国的OpenAI公司推出,重点是这个技术可以自动生成内容(看上去像人类生成的,而非人工智障生成的)。
现在大火的ChatGPT也就是基于GPT实现的一个落地应用。

这个应用唯一的功能就是聊天,你输入对话,它回答。
但就是这个聊天的功能的应用,却引爆了整个科技行业乃至人类社会。被誉为新一代的工业革命。
因为聊天这个功能似乎“无所不能”。比方说:
- 问问题:某个主题的基本知识、某个问题的答案
- 提供建议:根据您的需求给出相关的建议和指导,如健康、财务、职业等
- 语言翻译:将语言翻译成另一种语言
- 生成文章:生成符合您需求的文本
- 解题:理解题目,并给出解题过程和结果
- 写代码: 理解需求,产生一段计算机代码
…
所以说唯一限制我们使用场景的就是我们的想象力。
大语言模型背后的技术
我总结了大语言模型具有以下几个特征:
- 大规模预训练数据集。 大语言模型通常在大型文本数据集上进行预训练, 这些数据集的大小可达10万亿词。
- 神经网络。神经网络是一种人工智能技术,用于教计算机以受人脑启发的方式处理数据。这是一种机器学习过程,称为深度学习,它使用类似于人脑的分层结构中的互连节点或神经元。它可以创建自适应系统,计算机使用该系统来从错误中进行学习并不断改进。
- 涌现能力。涌现使模型可以自动生成具有语言上下文和逻辑关系的连贯文本,这些文本在预训练时并没有直接指定,而是通过模型自身的学习和推理得到的。涌现究竟是如何出现的,目前并没有确切的答案,更多的猜测是当数据量达到一定规模后,由于模型学习到了足够多的样本案例,逐渐出现的。
- 泛化能力(即通用能力)。由于模型在大规模文本数据上进行训练,它们具有较强的泛化能力,能够处理各种不同的任务和场景,如文本摘要、文本生成、机器翻译、问答等。
因此,要开发一个强大的大语言模型,首先要面对解决的是收集大量的自然语言语料进行训练。据相关资料显示GPT-3训练的语料量就高达45TB。注意这是文本类型的语料,想想我们一纯文本的电子书才多少KB。并且语料的来源应该是也多样化的,可以从公共数据看到一些大模型语言语料库的来源占比。从GPT-3的模型可以看到其中64%的训练数据来源于网页,17%的训练数据来源于代码,13%的电子书,5%来源于对话数据。
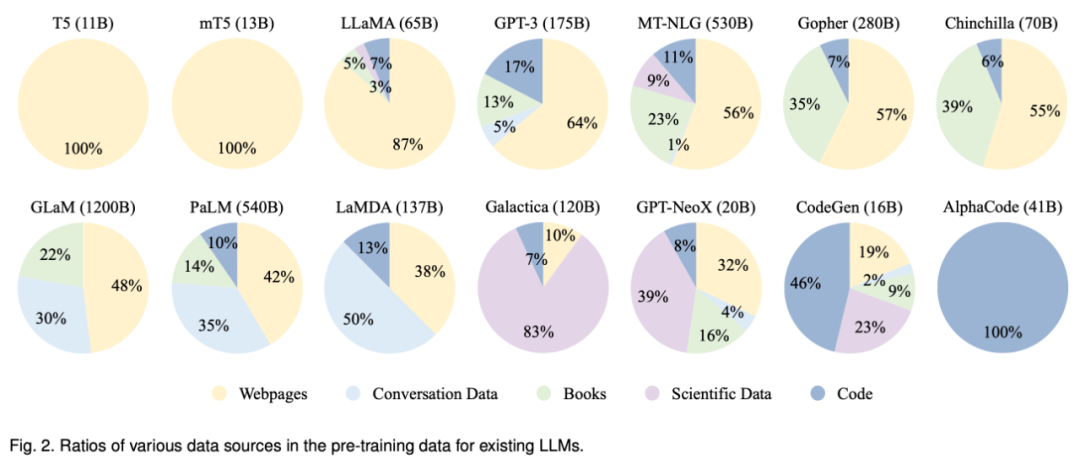 (图源来自互联网,如有侵权请联系删除)
(图源来自互联网,如有侵权请联系删除)
除了自然语言语料外,大语言模型还需要选定一个适合的基础架构。Transformer 架构已成为开发各大语言模型架构的事实标准。在2017年,Google发表了一篇论文 《Attention Is All You Need》 ,里面提到了一了self-attention 机制,其中就提出了大名鼎鼎的架构Transformer 。这也就不难理解为啥2018年后陆陆续续大语言模型出来了。如果对 《Attention Is All You Need》 这篇paper感兴趣的可以读一读原文https://arxiv.org/pdf/1706.03762.pdf。后续将会出个专门的篇章讲解。
简单理解,Transformer可以类比成一个具有魔法的机器,这个机器的作用是,读取一段话,预测这段话的下一个字出现的概率,然后选择最有可能性的字输出。再把这个字加上前面这段话作为新的对话输入,预测下一个字,循环往复,直到预测出终止符为出现概率最大的字为止。这些输出的字一个一个拼接起来,就成为了该机器的回答。
比如我们问:“你是谁?”,机器接受到这个输入以后,预测到下一个字是"我"的概率是99%,所以输出”我“。
然后机器自动把"你是谁?我"再输入到机器中,预测出下个字是"是"的概率是95%,那么会输出"是"。
一直循环往复,直到预测到下一个字是"END"这个终止符的概率最大时终止这个流程。
问: 你是谁?
答: 我是ChatGPT,一个由OpenAI开发的语言模型。我可以回答各种问题、提供信息和进行对话。有什么我可以帮助你的吗?
仅仅是对于下一个字的预测真的有那么神奇的能力,能让机器的输出的结果满足我们的预期?
体验过ChatGPT的人都会惊讶于该产品的体验,仿佛机器真的有该魔法能力一般,或者说拥有"智能"一般。
所以这个魔法能力来自哪里?答案是OpenAI的人也说不清。于是就有了这么一个词"Grokking",中文翻译成涌现能力。
当模型到达一定规模的时候,似乎涌现能力使模型可以自动生成具有语言上下文和逻辑关系的连贯文本,这些文本在预训练时并没有直接指定,而是通过模型自身的学习和推理得到的。涌现究竟是如何出现的,目前并没有确切的答案,更多的猜测是当数据量达到一定规模后,由于模型学习到了足够多的样本案例,逐渐出现的。直白一点也就是说量变引起了质变。
这个量变可以说是代表了人类一直以来对于人工智能探索的曲折。可以追溯到1950年,图灵提出的著名的"图灵测试",给出判断机器是否有智能的方法。从20世纪50年代至今,经过无数的前期铺垫和技术的演进,我们看到最近几年AI能力的"涌现", 而ChaGPT不过是新的序章的高潮部分而已。
国内百花齐放
目前国内在大语言模型方面可谓是百花齐放。
-
2023.02.20 复旦大学开放大语言模型MOSS
-
2023.03.15 智普AI开放大语言模型ChatGLM
-
2023.03.16 百度文心一言发布
-
2023.04.07 阿里巴巴通义千问发布
-
2023.04.09开放360智脑的内测
-
2023.04.10日日新亮相
-
2023.05.06科大讯飞发布星火大模型
…
可以看到国内有能力的厂商都在争先恐后,不遑多让。
国内也有针对中文通用的测评。中文通用大模型基准(SuperCLUE),是针对中文可用的通用大模型的一个测评基准。SuperCLUE从三个不同的维度评价模型的能力:基础能力、专业能力和中文特性能力。
基础能力:
包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等10项能力。
专业能力:
包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力。
中文特性能力:
针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
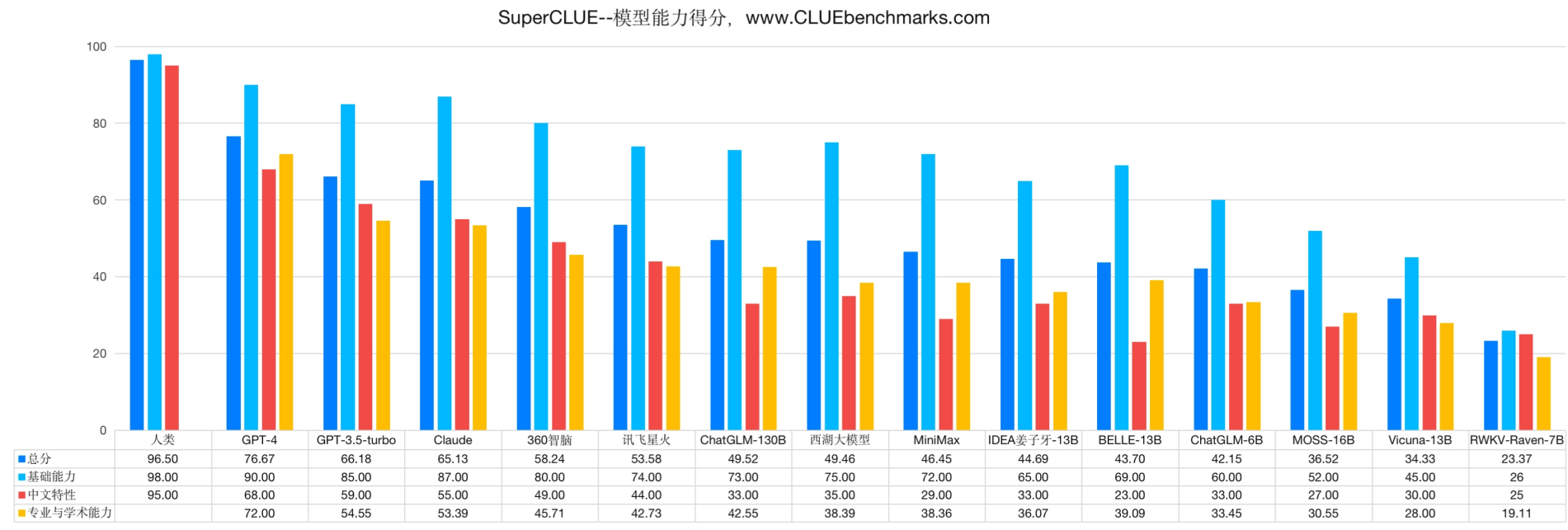
测评的项目地址:https://github.com/CLUEbenchmark/SuperCLUE。
与此同时国内开源模型这块也有类似ChatGLM-6B这样可玩度非常高的模型,家用级显卡就能跑模型。并且由此衍生出较多的开源项目

项目地址:https://github.com/THUDM/ChatGLM-6B
发展趋势
多模态
多模态是指利用来自不同模态的输入数据(例如视觉、音频、文本等)来改进学习和推理。例如,一个多模态模型可能会同时考虑图片(视觉模态)和文本(文本模态)来进行决策或预测。
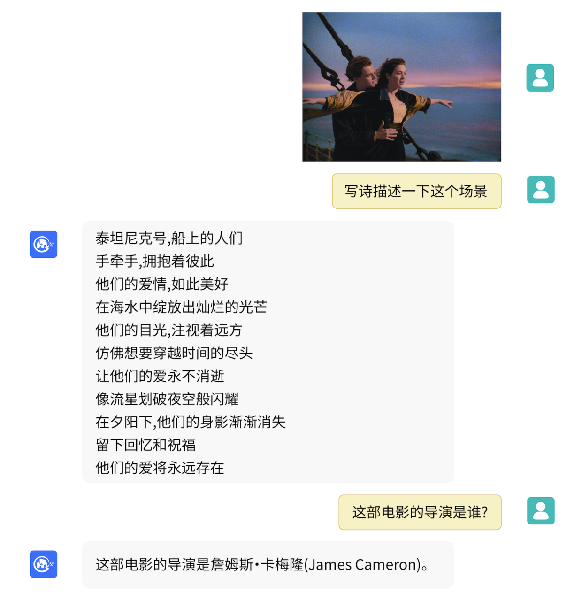
(图源来自项目https://github.com/THUDM/VisualGLM-6B,如有侵权请联系删除)
OpenAI在发布GPT-4的时候,曾演示了只需要用手稿画的设计图就能让GPT生成网站代码的能力。虽然目前还没开放相关入口。但是可以从国内模型比如科大讯飞星火模型,可以输入语言已经部分开源模型,比如VisualGLM-6B窥探出一二。
后续多模态必然会成为大语言模型发力的重点。
插件
OpenAI在ChatGPT中首次引入了插件的支持。插件是专门为语言模型设计的工具,它们的在安全的前提下可以帮助ChatGPT获取最新的信息,运行计算,或者使用第三方服务。
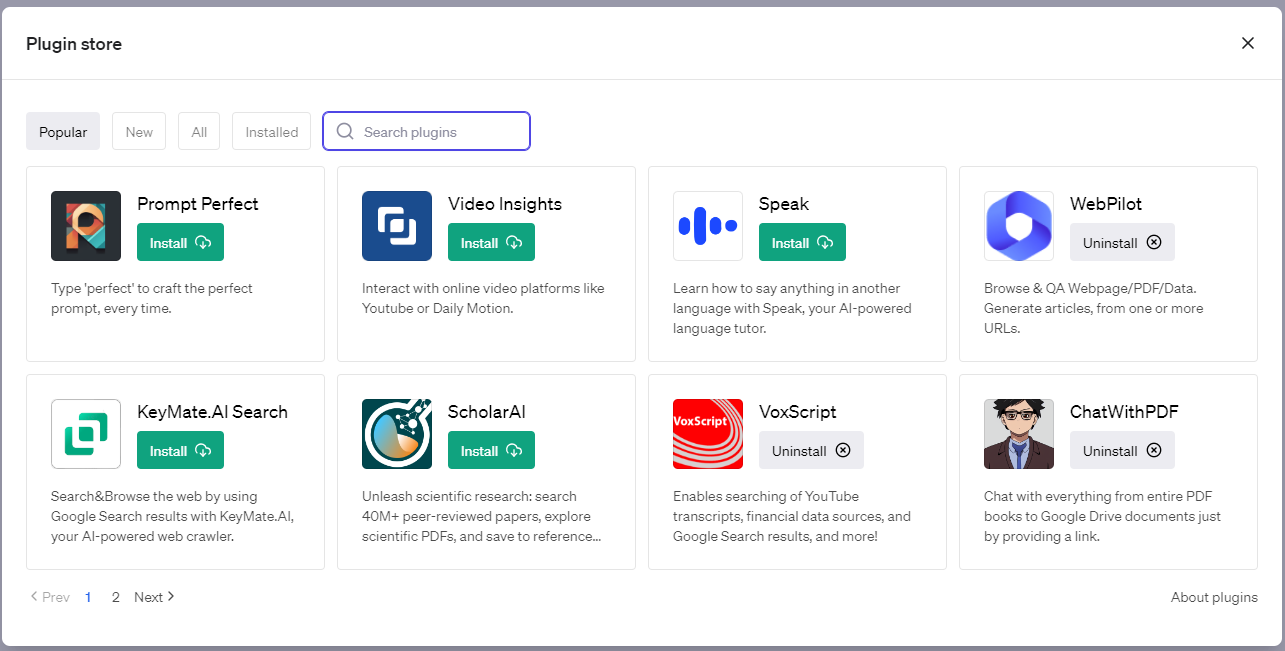
可以这样想象,类GPT这样的大模型是机器的大脑,插件就是机器的手脚,针对不同的场景,只要更换不同的插件就能拥有相关场景的能力,比如GPT不具备上网的能力,可以通过网络插件来获取上网的功能,比如GPT不能点外卖,可以通过相关插件获取点外卖的功能。
插件的功能将赋予了大模型无线的想象力。后续我会对OpenAI的热门插件进行测评。有兴趣可以继续关注我的更新。
其他
除此之外针对大模型的出现也出现了一个新的职业Prompt工程师。
什么是Prompt?
Prompt在人工智能和计算机科学中通常指的是提供给模型或系统的输入或指令,用于触发或指导模型或系统的行为。在与聊天机器人或语言生成模型(例如GPT-3)的交互中,Prompt通常指的是用户提供的输入,这个输入将指导模型生成响应。Prompt的设计和选择对模型生成的结果有很大影响。一个好的Prompt可以帮助模型更准确地理解用户的需求,生成更相关和有用的回答。相反,一个不明确或含糊的Prompt可能会导致模型生成不准确或不相关的回答。
可以简单理解就是怎么科学地和机器聊天。那你可能会问,聊天还需要专门的职业吗?那你可小瞧Prompt了,这里面可是有很大的门道。有些有趣的项目可能会颠覆你对聊天的认知, 比如https://github.com/JushBJJ/Mr.-Ranedeer-AI-Tutor项目,该项目通过聊天的方式把GPT-4训练成一个AI导师。
毕竟大语言模型训练的是通用模型,对于一些垂直领域的专有知识了解可能存在不足。因此大部分大语言模型提供了finetune的能力。
finetune或称为微调,是一种机器学习技术,特别是在深度学习中使用较多。在这个过程中,一个已经在大量数据上预训练过的模型被进一步训练(微调),通常是在更小、特定任务相关的数据集上。这种方法的背后思想是:模型在大规模预训练阶段已经学到了大量有用的知识(例如语言模型学到的词汇、语法和部分语义信息),然后在微调阶段,这些知识被细化和适应,以优化模型在特定任务上的表现。
finetune的能力是大模型落地各行各业的基础。随着国产大模型技术越趋于成熟,将会有越来越多的专有领域模型借着finetune的能力落地到各个行业。
本文只是对大模型做了一个简单的介绍,后续将会继续更新该系列。

