- 1java bridge 模式_JAVA设计模式之 桥接模式【Bridge Pattern】
- 2CSS优惠券、卡券样式绘制_css 优惠券内凹
- 3谷粒商城实战笔记-143-性能压测-压力测试-JMeter在windows下地址占用bug解决
- 42.机器学习:实现网上游戏AI_小游戏都是用的机器学习中的什么学习
- 5多屏幕时将Dock菜单栏固定在Mac Book Pro 主屏幕_mac分屏怎么让dock保持在主屏上
- 6SpringMVC请求的资源[路径]不可用_springmvc请求资源不可用
- 7html可以做题的app,开始答题.html
- 8微信小程序主体如何变更?小程序迁移流程详解_小程序主体信息可以更换吗
- 9从零开始玩转Franka Panda机器人
- 10全网最最最详细centos7如何安装docker教程_docker安装centos7_centos7安装docker
简单的docker学习 第12章 Docker Swarm
赞
踩
第12章 Docker Swarm
12.1 swarm 理论基础
12.1.1 简介
Docker Swarm 是由 Docker 公司推出的 Docker 的原生集群管理系统,它将一个 Docker主机池变成了一个单独的虚拟主机,用户只需通过简单的 API 即可实现与 Docker 集群的通信。Docker Swarm 使用 GO 语言开发。从 Docker 1.12.0 版本开始,Docker Swarm 已经内置于Docker 引擎中,无需再专门的进行安装配置。Docker Swarm 在 Docker 官网的地址为:https://docs.docker.com/engine/swarm/
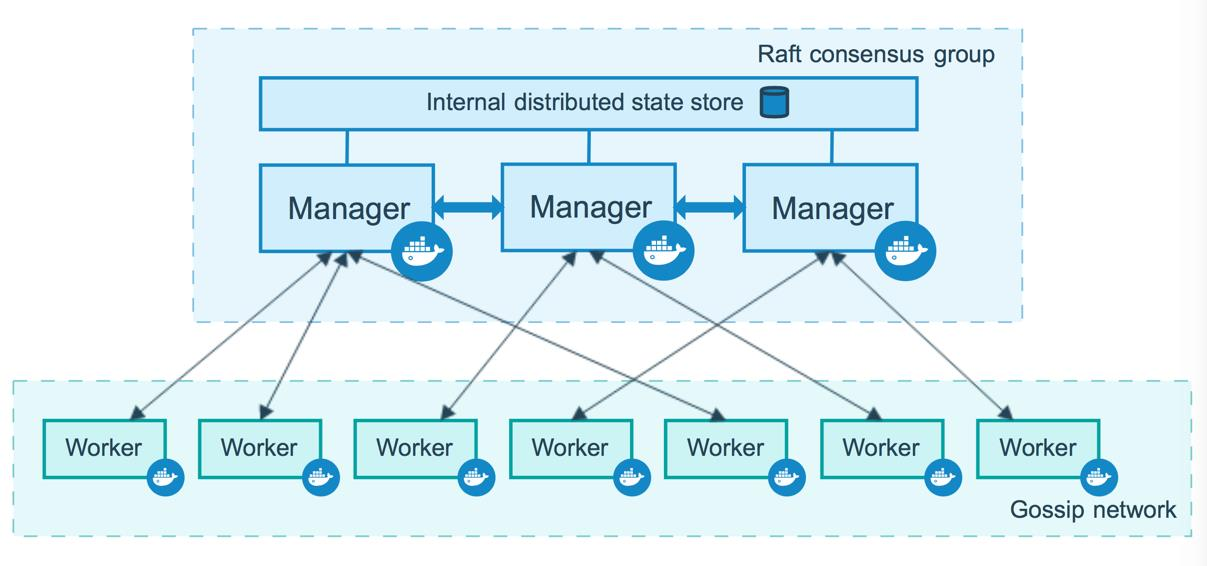
12.1.2 节点架构
-
架构图
-
swarm node
从物理上讲,一个 Swarm 是由若干安装了 Docker Engine 的物理机或者虚拟机组成,这些主机上的 Docker Engine 都采用 Swarm 模式运行。从逻辑上讲,一个 Swarm 由若干节点 node 构成,每个 node 最终会落实在一个物理Docker 主机上,但一个物理 Docker 主机并不一定就是一个 node。即 swarm node 与 Docker主机并不是一对一的关系。swarm node 共有两种类型:manager 与 worker。
-
Manager
Manager 节点用于维护 swarm 集群状态、调试 servcie、处理 swarm 集群管理任务。为了防止单点故障问题,一个 Swarm 集群一般都会包含多个 manager。这些 manager 间通过Raft 算法维护着一致性。
-
Worker
Worker 节点用于在其 Contiainer 中运行 task 任务,即对外提供 service 服务。默认情况下,manager 节点同时也充当着 worker 角色,可以运行 task 任务
-
角色转换
manager 节点与 worker 节点角色并不是一成不变的,它们之间是可以相互转换的。
-
manager 转变为 worker 称为节点降级
-
worker 转变为 manager 称为节点升级
-
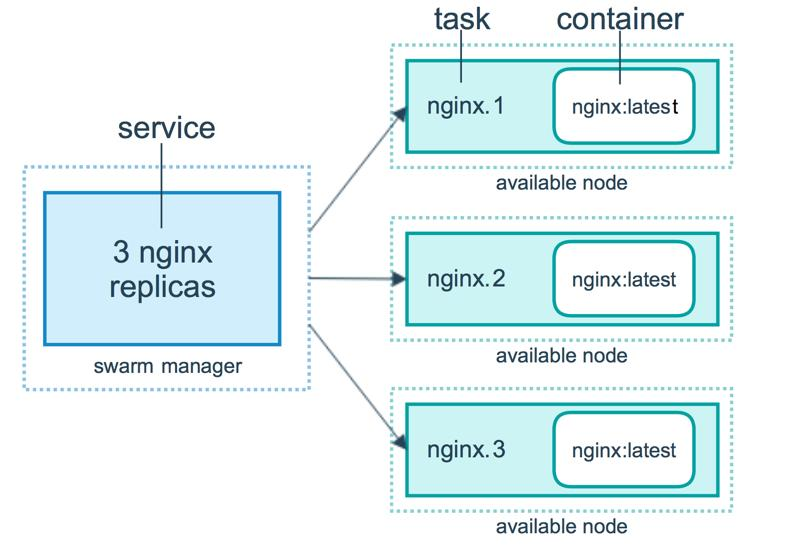
12.1.3 服务架构
-
架构图
-
service
搭建 docker swarm 集群的目的是为了能够在 swarm 集群中运行应用,为用户提供具备更强抗压能力的服务。docker swarm 中的服务 service 就是一个逻辑概念,表示 swarm 集群对外提供的服务。
-
task
一个 service 最终是通过任务 task 的形式出现在 swarm 的各个节点中,而每个节点中的task 又都是通过具体的运行着应用进程的容器对外提供的服务。
-
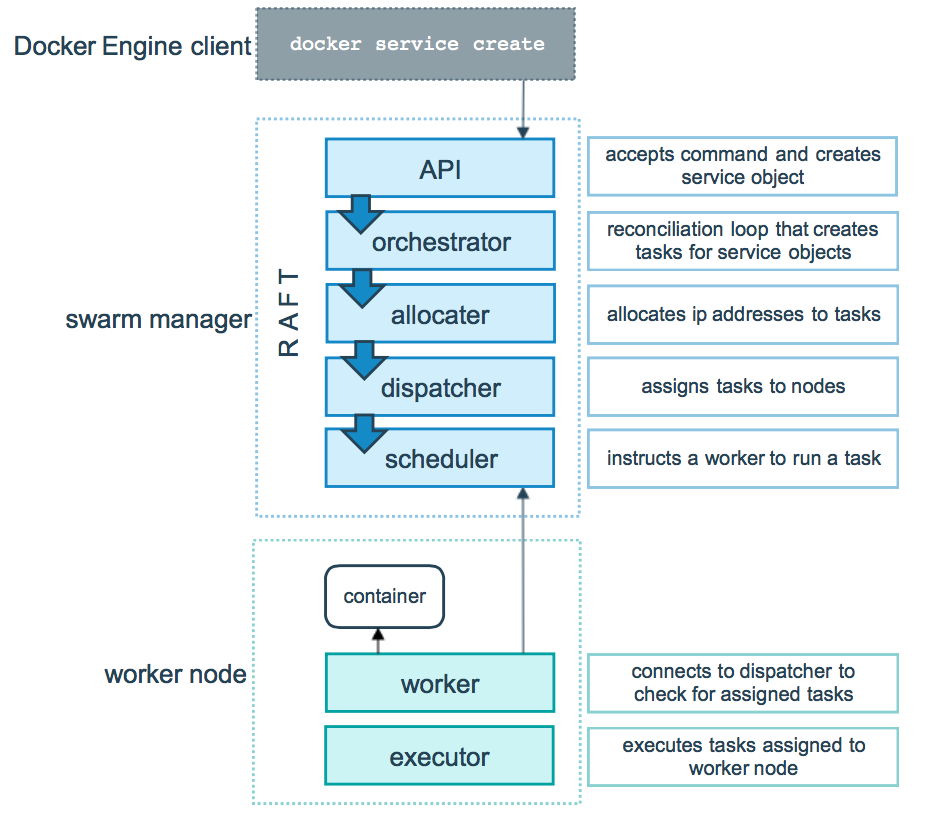
编排器
在 swarm manager 中具有一个编排器,用于管理副本 task 任务的创建与停止。例如,当在 swarm manager 中定义一个具有 3 个 task 副本任务的 service 时,编排器首先会创建 3个 task,为每个 task 分配一个 taskID,并通过分配器为每个 task 分配一个虚拟 IP,即 VIP。然后再将该 task 注册到内置的 DNS 中。当 service 的某 task 不可用时,编排器会在 DNS 中注销该 task。
-
分发器
在 swarm manager 中具有一个分发器,用于完成对副本 task 任务的监听、调度等操作。在前面的例子中,当编排器创建了 3 个 task 副本任务后,会调用分发器为每个 task 分配节点。分发器首先会在 swarm 集群的所有节点中找到 3 个 available node 可用节点,每个节点上分配一个 task。而每个 task 就像是一个“插槽”,分发器会在每个“插槽”中放入一个应用容器。每个应用容器其实就是一个具体的 task 实例。一旦应用容器运行起来,分发器就可以监测到其运行状态,即 task 的运行状态。
如果容器不可用或被终止,task 也将被终止。此时编排器会立即在内置 DNS 中注销该task,然后编排器会再生成一个新的 task,并在 DNS 中进行注册,然后再调用分发器为之分配一个新的 available node,然后再该节点上再运行应用容器。编排器始终维护着 3 个 task副本任务。
分发器除了为 task 分配节点外,还实现了对访问请求的负载均衡。当有客户端来访问swarm 提供的 service 服务时,该请求会被 manager 处理:根据其内置 DNS,实现访问的负载均衡
12.1.4 服务部署模式
-
官方图
service 以副本任务 task 的形式部署在 swarm 集群节点上。根据 task 数量与节点数量的关系,常见的 service 部署模式有两种:replicated 模式与 global 模式。
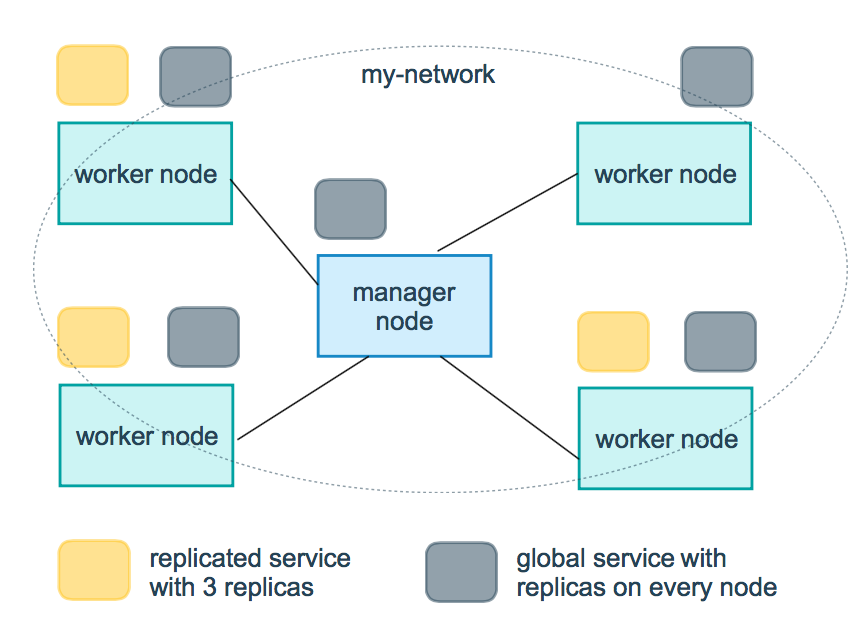
-
replicated 模式
replicated 模式,即副本模式,service 的默认部署模式。需要指定 task 的数量。当需要的副本任务 task 数量不等于 swarm 集群的节点数量时,就需要使用 replicated 模式。manager中的分发器会找到指定 task 个数的 available node 可用节点,然后为这些节点中的每个节点分配一个或若干个 task。
-
global 模式
global 模式,即全局模式。分发器会为每个 swarm 集群节点分配一个 task,不能指定 task的数量。swarm 集群每增加一个节点,编排器就会创建一个 task,并通过分发器分配到新的节点上
12.2 swarm 集群搭建
现要搭建一个 docker swarm 集群,包含 5 个 swarm 节点。这 5 个 swarm 节点的 IP 与暂时的角色分配如下(注意,是暂时的):
| hostname | ip | role |
|---|---|---|
| docker1 | 192.168.138.129 | master |
| docker2 | 192.168.138.130 | master |
| docker3 | 192.168.138.131 | master |
| docker4 | 192.168.138.132 | worker |
| docker5 | 192.168.138.133 | worker |
12.2.2 克隆主机
克隆两台前面 docker 主机,这两台主机名分别为 docker2、docker3、docker4 与 docker5。
克隆完毕后修改如下配置文件:
-
修改主机名:/etc/hostname
分别修改docker1 => docker5 对应的hostname以及 hosts文件内容,具体内容如下
# hostname docker1 # hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.138.130 docker2 192.168.138.131 docker3 192.168.138.132 docker4 192.168.138.133 docker5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

12.2.3 查看 swarm 激活状态
在任意 docker 主机上通过 docker info 命令可以查看到当前 docker 引擎 Server 端对于swarm 的激活状态。由于尚未初始化 swarm 集群,所以这些 docker 主机间没有任何关系,且 swarm 均未被激活。
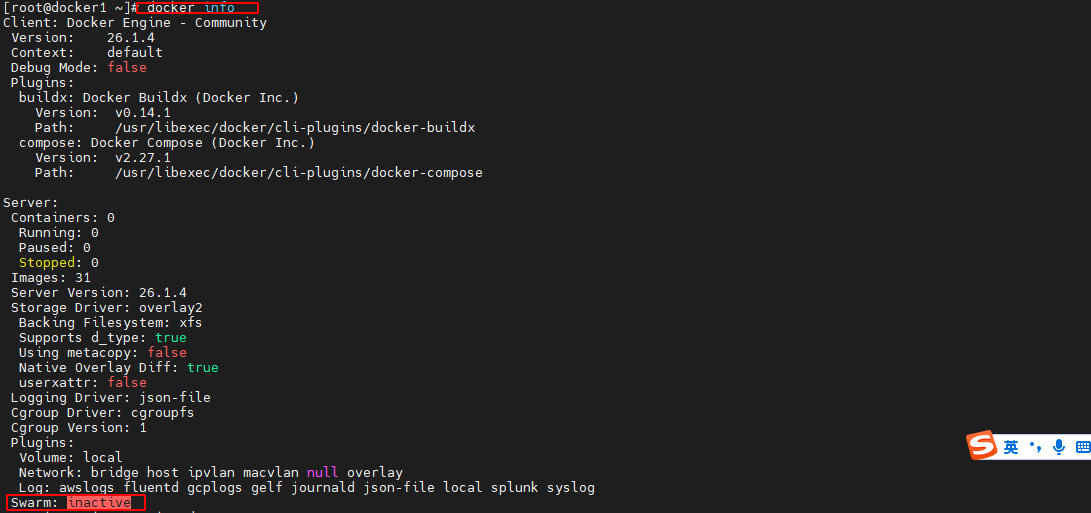
12.2.4 swarm 初始化
在主机名为docker1的主机上运行 docker swarm init 命令,创建并初始化一个 swarm。
docker swarm init
# 获取初始化脚本为
# 或者使用 docker swarm join-token worker
docker swarm join --token SWMTKN-1-2ia3harocxprk7l26e4x2sl71pmqe4u3o7sacomxatd44o2okd-dtwfx95zf6cjtkca3khkdkl6q 192.168.138.129:2377
- 1
- 2
- 3
- 4
- 5
- 6

12.2.5 添加 worker 节点
复制 docker swarm init 命令的响应结果中添加 wroker 节点的命令在 docker4 与 docker5节点上运行,将这两个节点添加为 worker 节点。
docker swarm join --token SWMTKN-1-2ia3harocxprk7l26e4x2sl71pmqe4u3o7sacomxatd44o2okd-dtwfx95zf6cjtkca3khkdkl6q 192.168.138.129:2377
- 1


12.2.6 添加 manager 节点
- 获取添加命令
若要为 swarm 集群添加 manager 节点,需要首先在 namager 节点获取添加命令。
docker swarm join-token manager
# 获取命令如下
docker swarm join --token SWMTKN-1-2ia3harocxprk7l26e4x2sl71pmqe4u3o7sacomxatd44o2okd-4447brphqzw1t1nfyckm14xq1 192.168.138.129:2377
- 1
- 2
- 3
-
添加节点
复制 docker swarm join-token 命令生成的 manager 添加命令,然后在 docker2 与 docker3节点上运行,将这两个节点添加为 manager 节点。
docker swarm join --token SWMTKN-1-2ia3harocxprk7l26e4x2sl71pmqe4u3o7sacomxatd44o2okd-4447brphqzw1t1nfyckm14xq1 192.168.138.129:2377- 1


12.2.7 查看 swarm 节点 node ls
在 manager 节点 docker、docker2、docker3 上通过 docker node ls 命令可以查看到当前swarm 集群所包含的节点状态数据
docker node ls
- 1

但在 worker 节点上是不能运行 docker node ls 命令的。

12.3 swarm 集群维护
12.3.1 退出 swarm 集群 swarm leave
当一个节点想从 swarm 集群中退出时,可以通过 docker swarm leave 命令。不过 worker节点与 manager 节点的退群方式是不同的
-
worker 退群
此时在 manager 节点中查看节点情况,可以看到 docker5 已经 Down 了。
docker swarm leave- 1


-
worker 重新加入
首先在 manager 节点上运行 docker swarm join-token worker 命令,生成加入 worker 节点的命令。
docker swarm join-token worker # 生成加入命令 docker swarm join --token SWMTKN-1-2ia3harocxprk7l26e4x2sl71pmqe4u3o7sacomxatd44o2okd-dtwfx95zf6cjtkca3khkdkl6q 192.168.138.129:2377- 1
- 2
- 3
复制生成的命令,在 docker5 节点上运行,将此节点添加到 swarm 集群
docker swarm join --token SWMTKN-1-2ia3harocxprk7l26e4x2sl71pmqe4u3o7sacomxatd44o2okd-dtwfx95zf6cjtkca3khkdkl6q 192.168.138.129:2377- 1

-
查看节点情况
此时在 manager 节点中查看节点情况,可以看到原来的 docker5 依然是 Down,但又新增了一个新的 docker5 节点,其状态为 Ready。

此时在 manager 节点通过 docker info 命令可以查看到节点数量变为了 6 个,这增加的一个就是两种状态的 docker5
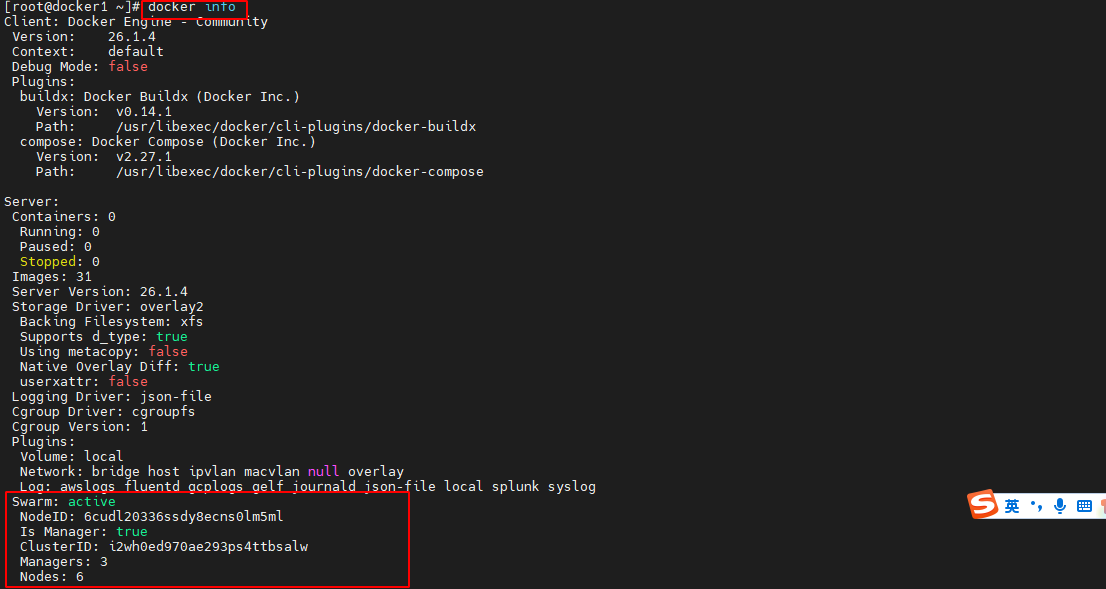
-
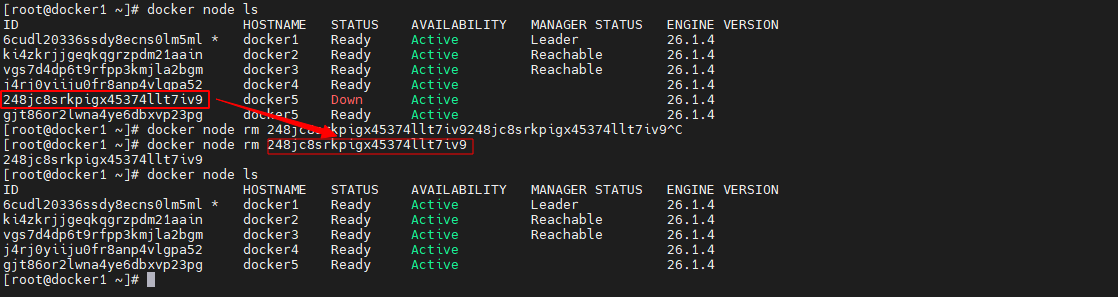
删除 Down 状态节点
对于Down状态的节点是完全可以将其删除的。通过在manager节点运行docker node rm命令完成。
docker node rm 248jc8srkpigx45374llt7iv9- 1
-
manager 退群
对于 manager 节点,原则上是不推荐直接退群的,这样会导致 swarm 集群的一致性受到损坏。如果 manager 执意要退群,可在 docker swarm leave 命令后添加-f 或–force 选项进行强制退群。
docker swarm leave --force- 1

12.3.2 swarm 自动锁定 autolock
-
swarm 集群自动锁定原理
在 manager 集群中,swarm 通过 Raft 日志方式维护了 manager 集群中数据的一致性。即在 manager 集群中每个节点通过 manager 间通信方式维护着自己的 Raft 日志。
但在通信过程中存在有一种风险:Raft 日志攻击者会通过 Raft 日志数据的传递来访问、篡改 manager 节点中的配置或数据。为了防止被攻击,swarm 开启了一种集群自动锁定功能,为 manager 间的通信启用了 TLS 加密。用于加密和解密的公钥与私钥,全部都维护在各个节点的 Docker 内存中。一旦节点的 Docker 重启,则密钥丢失。
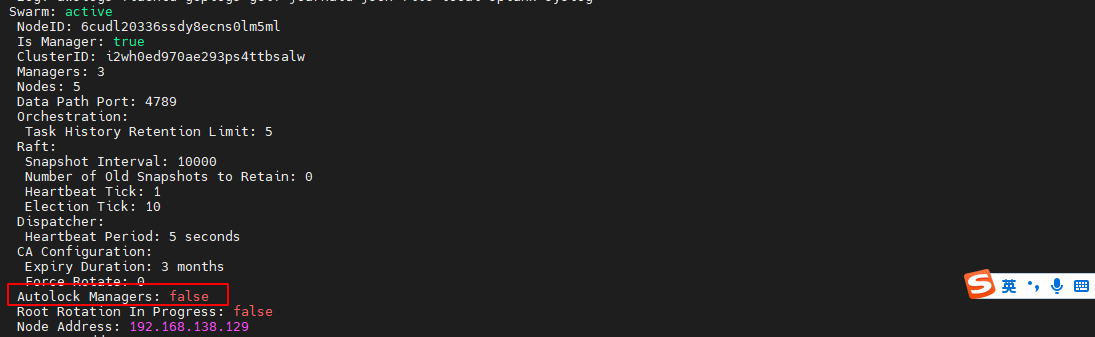
swarm 中通过 autolock 标志来设置集群的自动锁定功能:为 true 则开启自动锁定,为false 则关闭自动锁定
可以使用docker info查看锁定状态
docker info- 1
-
设置自动锁定
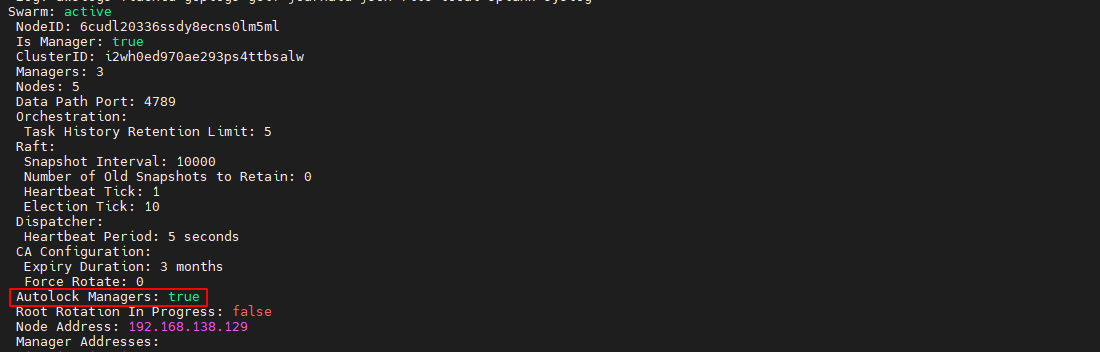
在 manager 节点通过 docker swarm update –autolock=true 命令可以开启当前 swarm 集群的自动锁定功能。
# --autolock=false 关闭 docker swarm update --autolock=true # 返回解锁key为 SWMKEY-1-QxLlKjKZd44LKfSaov39P0+jc6mYWG9+ubNqupiLTd4- 1
- 2
- 3
- 4

查看集群锁定状态
docker info- 1
-
查看解锁密钥
如果没有保存 docker swarm update --autolock=true 命令中生成的密钥,也可通过在manager 中运行 docker swarm unlock-key 命令查看。
docker swarm unlock-key- 1

-
关闭一个 manager
直接关闭 docker3 的 docker 引擎,模拟一个 manager 宕机的情况。
systemctl stop docker- 1

-
加入 manager
systemctl start docker- 1
此时再查看该节点的 docker info,可以看到 Swarm 值为 locked,即当前节点看到的 Swarm集群的状态为锁定状态,其若要加入,必须先解锁。

在 docker3 中运行 docker swarm unlock 命令,解锁 swarm。
docker swarm unlock # 之后输入上面生成的解锁key SWMKEY-1-QxLlKjKZd44LKfSaov39P0+jc6mYWG9+ubNqupiLTd4- 1
- 2
- 3

再次查看状态

注意:自动锁定状态不能把所有master节点都关闭,所有解锁信息都在内存中,全部关闭将丢失锁定秘钥信息,重启后导致docker swarm集群不可用
12.4 swarm 节点维护
12.4.1 角色转换 promote/demote
Swarm 集群中节点的角色只有 manager 与 worker,所以其角色也只是在 manager 与worker 间的转换。即 worker 升级为 manager,或 manager 降级为 worker。
-
worker 升级为 manager
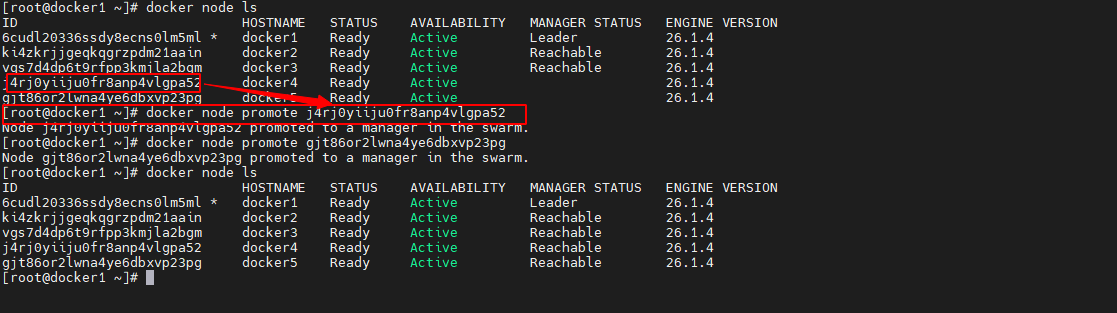
通过 docker node promote 命令可以将 worker 升级为 manager。
例如,下面的命令是将docker4 与 docker5 两个节点升级为了 manager,即当前集群中全部为 manager。
docker node promote- 1
-
manager 降级为 worker
通过 docker node demote 命令可以将 manager 降级为 worker。例如,下面的命令是将docker2 与 docker3 两个节点降级为了 worker。
docker node demote- 1

-
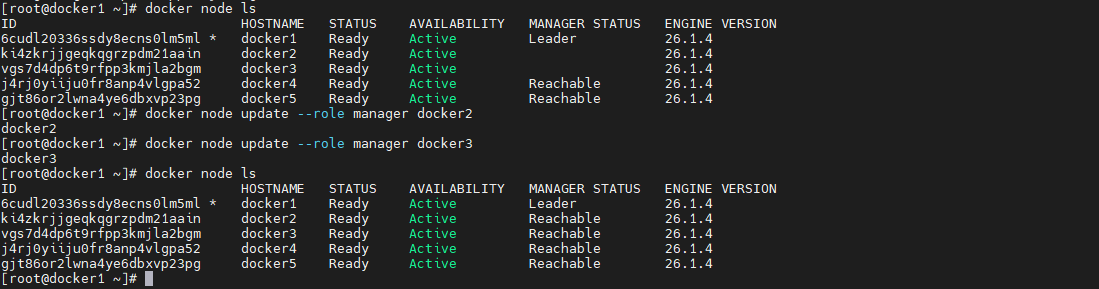
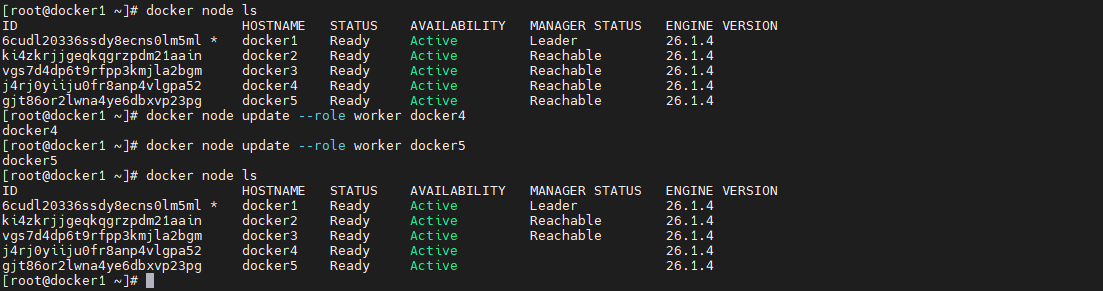
docker node update 变更角色
除了通过 docker node demote|promote 可以变更节点角色外,通过 docker node update --role [manager|worker] [node]也可变更指定节点的角色。以下命令将 docker2 与 docker3 两个节点又变为了 manager。
docker node update --role manager docker2 docker node update --role manager docker3- 1
- 2
以下命令将 docker4 与 docker5 两个节点又变为了 worker
docker node update --role worker docker4 docker node update --role worker docker5- 1
- 2
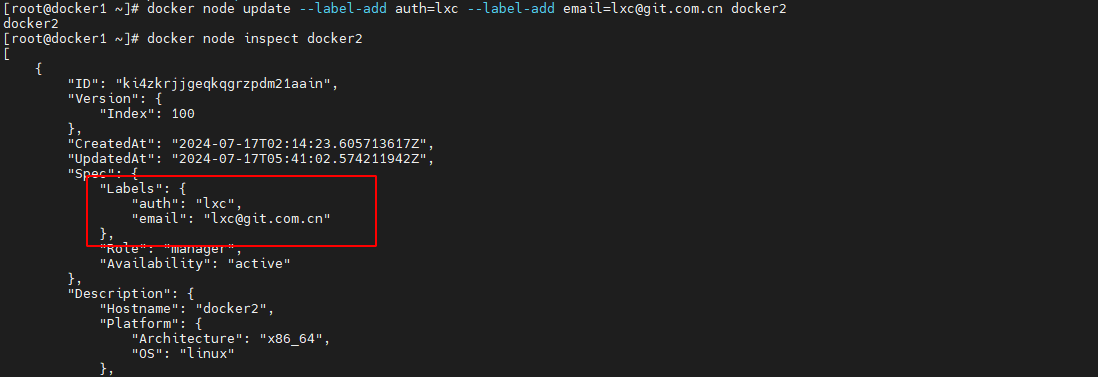
12.4.2 节点标签 label-add
swarm 可以通过命令为其节点添加描述性标签,以方便管理员去了解该节点的更多信息
-
添加/修改节点标签
通过 docker node update --label-add 命令可以为指定 node 添加指定的 key=value 的标签。若该标签的 key 已经存在,则会使用新的 value 替换掉该 key 的原 value。不过需要注意的是,若要添加或修改多个标签,则需要通过多个–label-add 选项指定。
docker node update --label-add auth=lxc --label-add email=lxc@git.com.cn docker2- 1
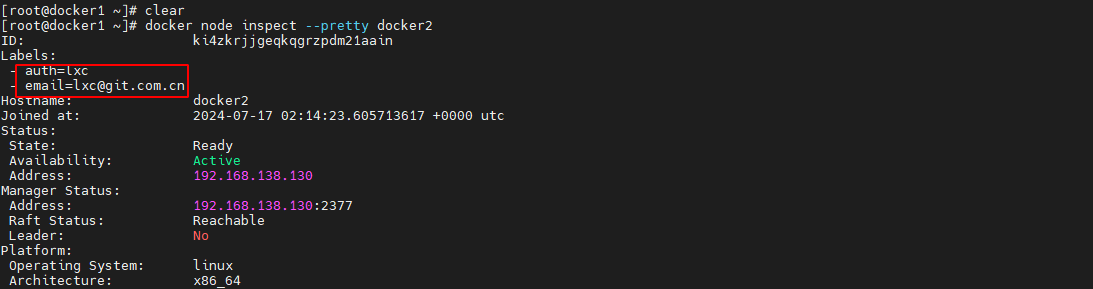
docker node inspect --pretty 可以 key:value 的形式显示信息
docker node inspect --pretty docker2- 1
-
删除节点标签
通过 docker node update --label-rm 命令可以为指定的 node 删除指定 key 的标签。同样,若要删除多个标签,则需要通过多个–label-rm 选项指定要删除 key 的标签。
docker node update --label-rm email docker2- 1

12.4.3 节点删除 node rm
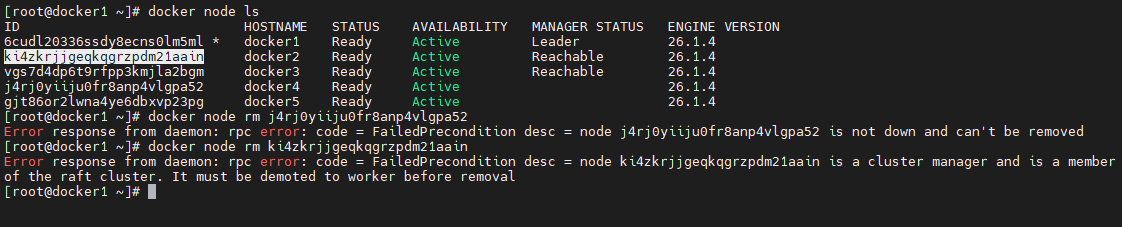
manager 节点通过 docker node rm 命令可以删除一个 Down 状态的、指定的 worker 节点。注意,该命令只能删除 worker 节点,不能删除 manager 节点。
-
有问题的删除
对于 manager节点以及Ready 状态的 worker 节点是无法直接删除的
docker node rm j4rj0yiiju0fr8anp4vlgpa52 docker node rm ki4zkrjjgeqkqgrzpdm21aain- 1
- 2
-
正确的删除
若要删除一个 worker 节点,首先要将该节点的 Docker 关闭,使该节点变为 Down 状态,然后再进行删除。关闭 docker2 节点的 Docker 引擎
# 关闭docker4服务器的docker进程 systemctl stop docker docker node rm j4rj0yiiju0fr8anp4vlgpa52- 1
- 2
- 3

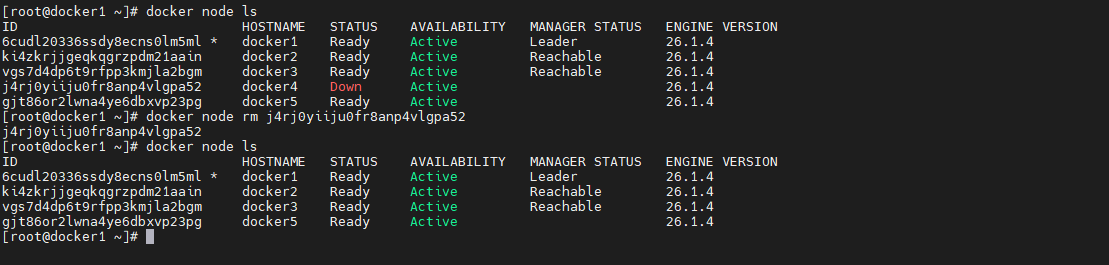
-
强制删除
前面的删除方式有些麻烦,其实也可以通过添加-f 选项来实现强制删除
docker node rm -f gjt86or2lwna4ye6dbxvp23pg- 1

注意:manager节点,即使使用强制删除也无法进行删除,docker node rm –f 命令会使一个节点强制退群,而 docker swarm leave 命令是使当前的docker 主机关闭 swarm 模式。
-
删除恢复
# 首先进行leave操作,退出集群 docker swarm leave # 在master节点上执行命令获取添加worker命令 docker swarm join-token worker # 再进行worker节点执行添加worker命令 docker swarm join --token SWMTKN-1-2ia3harocxprk7l26e4x2sl71pmqe4u3o7sacomxatd44o2okd-dtwfx95zf6cjtkca3khkdkl6q 192.168.138.129:2377- 1
- 2
- 3
- 4
- 5
- 6

12.5 swarm 安全(PKI)
Docker 内置了 PKI(public key infrastructure,公钥基础设施),使得保障发布容器化的业务流程系统的安全性变得很简单。
12.5.1 TLS 安全保障
Swarm 节点之间采用 TLS 来鉴权、授权和加密通信。具体来说是,当运行 docker swarm init 命令时,Docker 指定当前节点为一个 manager
节点。默认情况下,manager 节点会生成一个新的 swarm 的 CA 根证书以及一对密钥。同时,manager 节点还会生成两个 token,一个用于添加 worker 节点,一个用于添加 manager 节点。每个 token 包含上了 CA 根证书的 digest 和一个随机密钥。CA 根证书、一对密钥和随机密钥都将会被用在节点之间的通信上。
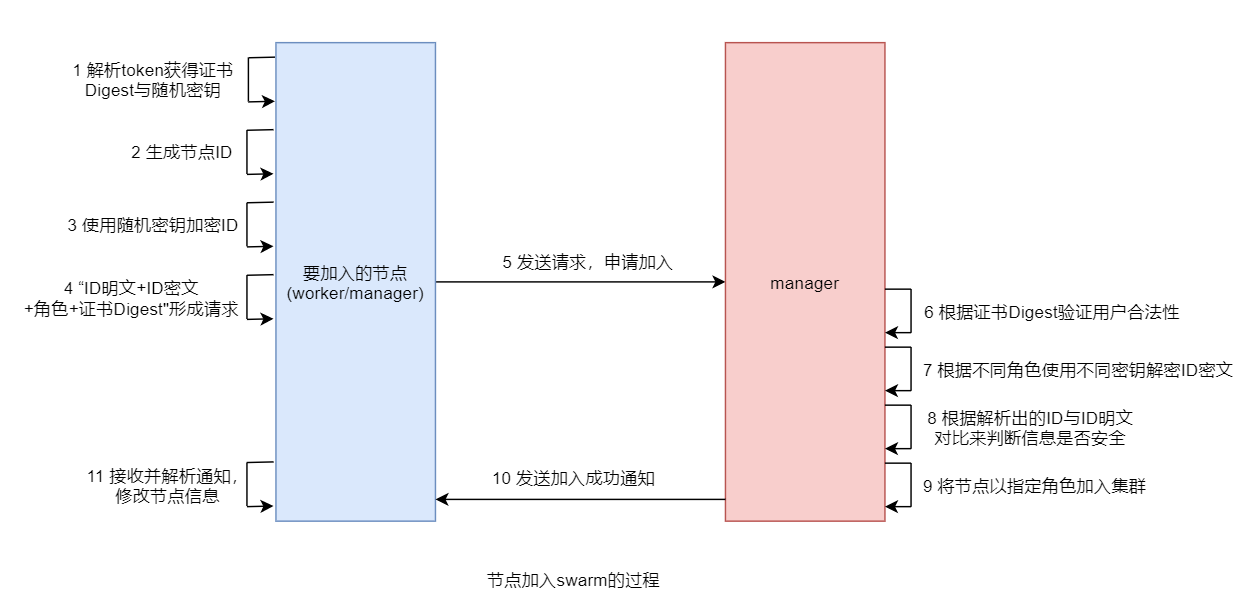
当有节点加入 Swarm 时,需要复制 manager 中相应的 docker swarm join 加入命令,并、在该节点中运行。而这个过程主要是通过随机密钥这种对称验证方式保障通信安全的。
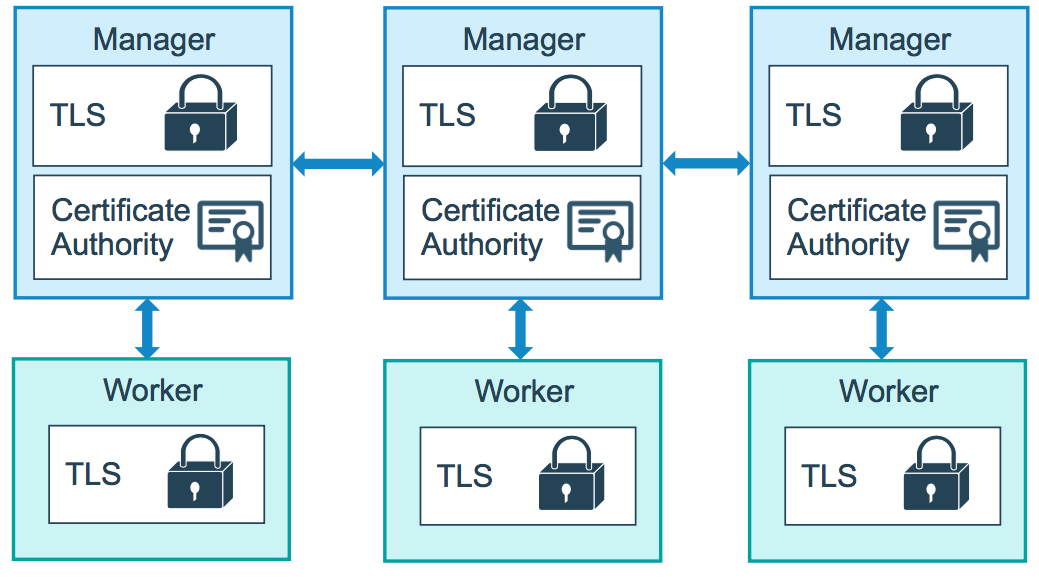
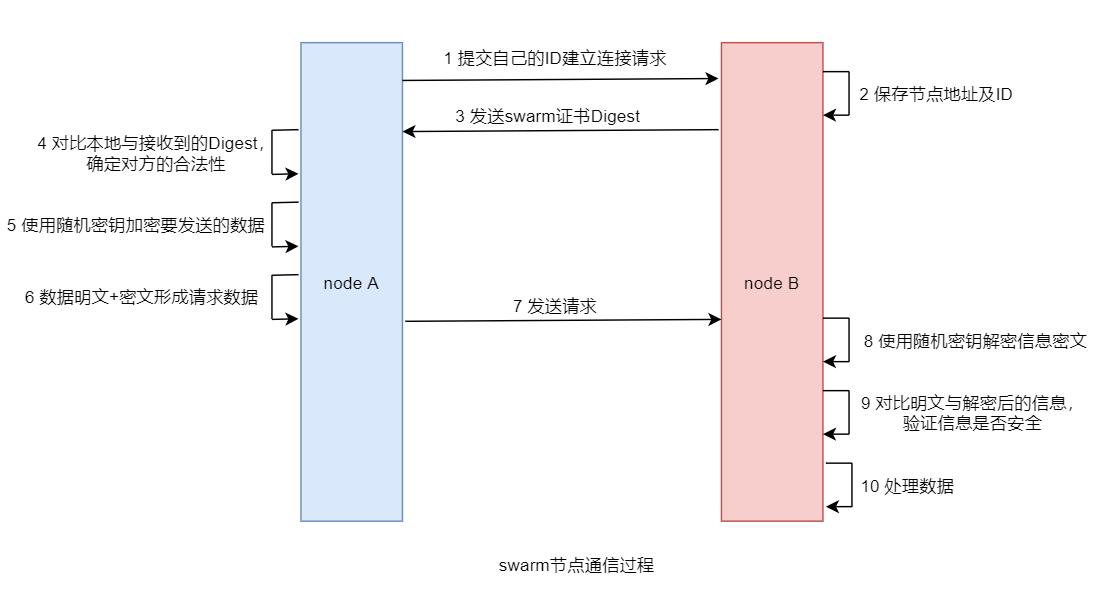
一旦节点加入了 Swarm 集群,那么它们间的通信全部都是通过 TLS 加密方式进行的。首先是通过 CA 证书对通信对方的身份进行验证,在验证通过后再进行数据通信。而通信的数据则是通过随机密钥加密过的
12.5.2 CA 数字证书轮换
-
轮换周期
Swarm 的 CA 数字证书也是有可能被攻击、篡改的。为了保证 swarm 的数字证书的安全性,Swarm 提供了 CA 数字证书轮换机制,定期更换 CA 数字证书。默认 swarm 的 CA 数字证书 90 天轮换一次。
-
指定证书
那么,用于轮换的新的 CA 数字证书来自于哪里呢?通过 docker swarm ca 命令可以指定外部 CA 数字证书,或生成新的 CA 数字证书。无论哪种数字证书变更方式,都需要 CA 根证书的加密/解密。而根证书也是会发生变化的,具体见“轮转过程”
-
轮转过程
当 manager 运行了 docker swarm ca --rotate 命令后,会按顺序发生下面的事情:
-
Docker 会生成一个交叉签名(cross-signed)根证书,即新根证书是由旧的根证书签署生成的,这个交叉签名根证书将作为一个过渡性的根证书。这是为了确保节点仍然能够信任旧的根证书,也能使用新的根证书验证签名。
-
在 Docker 17.06 或者更高版本中,Docker 会通知所有节点立即更新根证书。根据 swarm中节点数量多少,这个过程可能会花费几分钟时间。
-
在所有的节点都更新了新 CA 根证书后,manager 会通知所有节点仅信任新的根证书,不再信任旧根证书及交叉签名根证书。
-
所有节点使用新根证书签发自己的数字证书。
如果直接使用外部的 CA 根证书,那么就不存在交叉签名根证书的生成过程,直接由运行docker swarm ca命令的节点通知所有节点立即更新根证书。后续过程与前面的就相同了。
-
12.6 manager 集群容灾
12.6.1 热备容灾
Swarm 的 manager 节点集群采用的是热备方式来提升集群的容灾能力。即在 manager集群中只有一个处于 leader 状态,用于完成 swarm 节点的管理,其余 manager 处于热备状态。当 manager leader 宕机,其余 manager 就会自动发起 leader 选举,重新选举产生一个新的 manager leader。
12.6.2 容灾能力
manager 集群的 leader 选举采用的是 Raft 算法。Raft 算法是一种比较复杂的一致性算法,具体见后面“Raft 算法”。其选举 leader 的简单思路是,所有可用的 manager 全部具有选举权与被选举权。最终获得过半选票的 manager 当选新的 leader。为了保证一次性可以选举出新的leader,官方推荐使用奇数个manager。但并不是说偶数个manager就无法选举出leader。
12.6.3 容灾模拟
目前是 docker1、docker2、docker3 三个 manager,其中 docker1 为 leader,现在关闭 docker 主机的 docker daemon,模拟其宕机。
# docker1执行下面脚本
systemctl stop docker
- 1
- 2

然后在 docker2 或 docker3 主机上查看当前的节点情况,可以看到 docker2 或 docker3已经成为了新的 leader
docker node ls
- 1

此时如果再使某个 manager 宕机,例如使 docker2 的 docker daemon 关闭,那么整个swarm 就会瘫痪。因为剩下的 manager 已经无法达成过半的选票,无法选举出新的 leader。

12.7 service 创建
docker swarm 中的服务 service 就是一个逻辑概念,表示 swarm 集群对外提供的服务。注意,service 只能依附于 docker swarm 集群,所以 service 的创建前提是,swarm 集群搭建完毕。
12.7.1 创建 service create
docker service create 命令用于创建 service,需要在 manager 中运行。其与创建容器的命令 docker run 非常类似,具有类似的选项。目前的节点状态如下
docker node ls
- 1

现在要在 swarm 中创建一个运行 tomcat:8.5.32 镜像的 service,服务名称为 toms,包含3 个副本 task,对外映射端口号为 9000,
# 命令下生成的一串码为 service 的 ID。
docker service create --name cus_tomcat --replicas 3 -p 9000:8080 tomcat:8.5.32
# 容器容灾时候会出现很多shutdown容器,添加--update-order start-first可以自动清除
docker service create --name cus_tomcat --update-order start-first --replicas 3 -p 9000:8080 tomcat:8.5.32
- 1
- 2
- 3
- 4
–update-order start-first 这里,–update-order start-first 参数告诉 Docker Swarm 在更新服务时首先启动新的容器,然后再停止旧的容器。

12.7.2 服务列表 service ls
docker service ls 命令用于查看当前 swarm 集群中正在运行的 service 列表信息。一个swarm 中可以运行多个 service

12.7.3 服务详情 service inspect
通过 docker service inspect [service name|service ID]命令可以查看指定 service 的详情
docker service inspect cus_tomcat --pretty
- 1

12.7.4 用户访问服务
当服务创建完毕后,该服务也就运行了起来。此时用户就可通过浏览器进行访问了。用户可以访问 swarm 集群中任意主机。192.168.138.129~192.168.138.133,端口号为9000都可以访问到tomcat服务
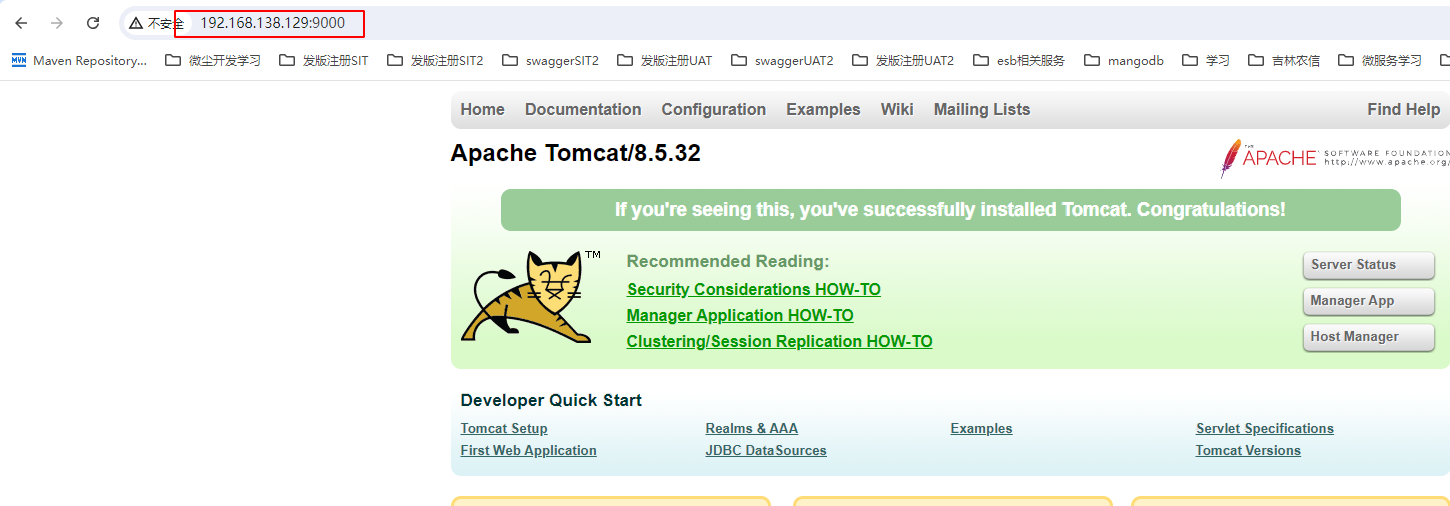
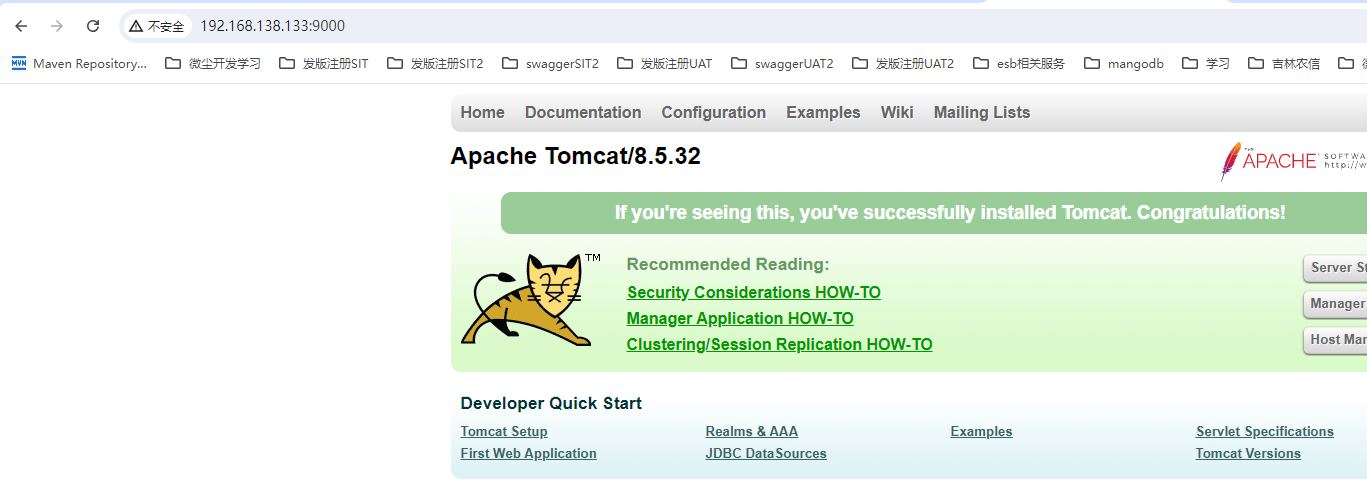
12.7.5 查看task节点 service ps
docker service ps [service name|service ID]命令可以查看指定服务的各个 task 所分配的节点信息
docker service ps cus_tomcat
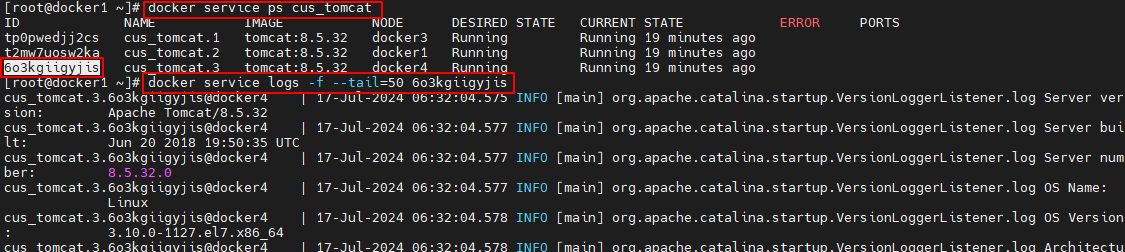
- 1

可以看到,cus_tomcat 服务的 3 个 task 被分配到了 docker3、docker1、docker4 三个主机。其中 ID 为 task ID,NAME 为 task 的 name。task name 是 service name 后添加从 1 开始的流水号形成的。
12.7.6 查看节点task node ps
通过 docker node ps [node]可以查看指定节点中运行的 task 的信息。默认查看的是当前节点的 task 信息。

12.7.7 服务日志 service logs
通过 docker service logs 命令可以查看指定 service 或 task 的日志。通过 docker service logs –f 命令可动态监听指定 service 或 task 的日志
-
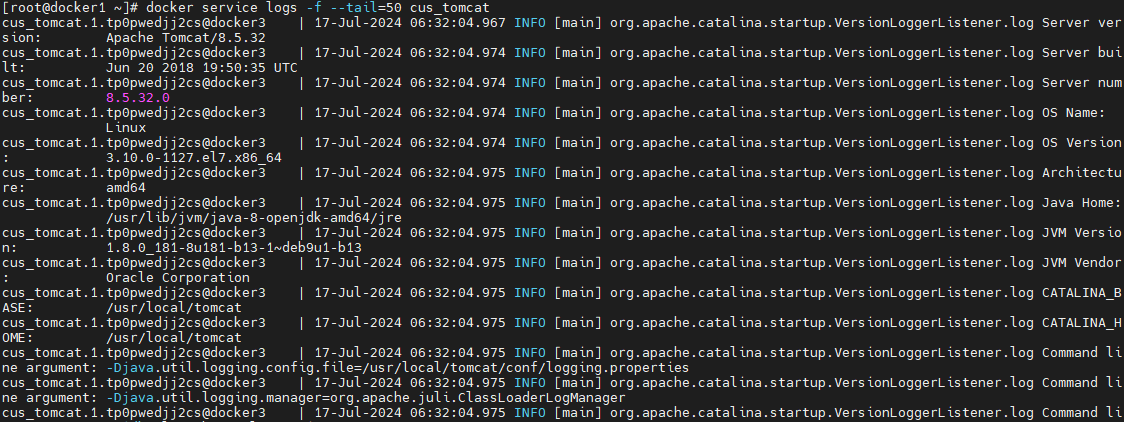
查看 service 日志
通过 docker service logs [service name|service ID]命令可以查看指定 service 的日志。这些日志实际是所有 task 在节点容器中的运行日志
docker service logs -f --tail=50 cus_tomcat- 1
-
查看 task 日志
通过 docker service logs [task ID]命令可以查看指定 task 的日志。注意,这里只能指定 taskID,不能指定 task name。这些日志实际是指定 task 在节点容器中的运行日志。
docker service ps cus_tomcat docker service logs -f --tail=50- 1
- 2
12.7.8 查看节点容器
在 docker1、docker4、docker3 三个主机中查看正在运行的容器列表,可以看到相应的tomcat 容器。但是在docker2以及docker5主机中是没有运行tomcat容器,容器的 NAME 是由 task name 后添加 task ID 形成的
docker service ps cus_tomcat
docker ps
- 1
- 2

12.7.9 负载均衡
当一个 service 包含多个 task 时,用户对 service 的访问最终会通过负载均衡方式转发给各个 task 处理。这个负载均衡为轮询策略,且无法通过修改 service 的属性方式进行变更。
但由于该负载均衡为三层负载均衡,所以其可以通过第三方实现负载均衡策略的变更,例如通过 Nginx、HAProxy 等。
-
创建 service
为了能够展示出 service 对访问请求负载均衡的处理方式,这里使用一个镜像containous/whoami。该镜像中应用端口号为 80,通过浏览器访问,返回结果中包含很多信息,其中最重要的是处理该请求的容器 ID。为了提高 service 的创建效率,可以先将该镜像下载到所有节点主机。
下面的命令用于创建该镜像的一个 service,包含 5 个副本 task。
docker service create --name web --replicas 5 -p 8080:80 containous/whoami- 1

-
记录容器 ID
可以看到,每个节点上都分配了一个 task,即每个节点上都运行了一个该 task 的容器
docker service ps web- 1

为了体现负载均衡的效果,这里需要将各个节点主机中该 service 的 task 容器的 ID 查询并记录下来。





-
访问
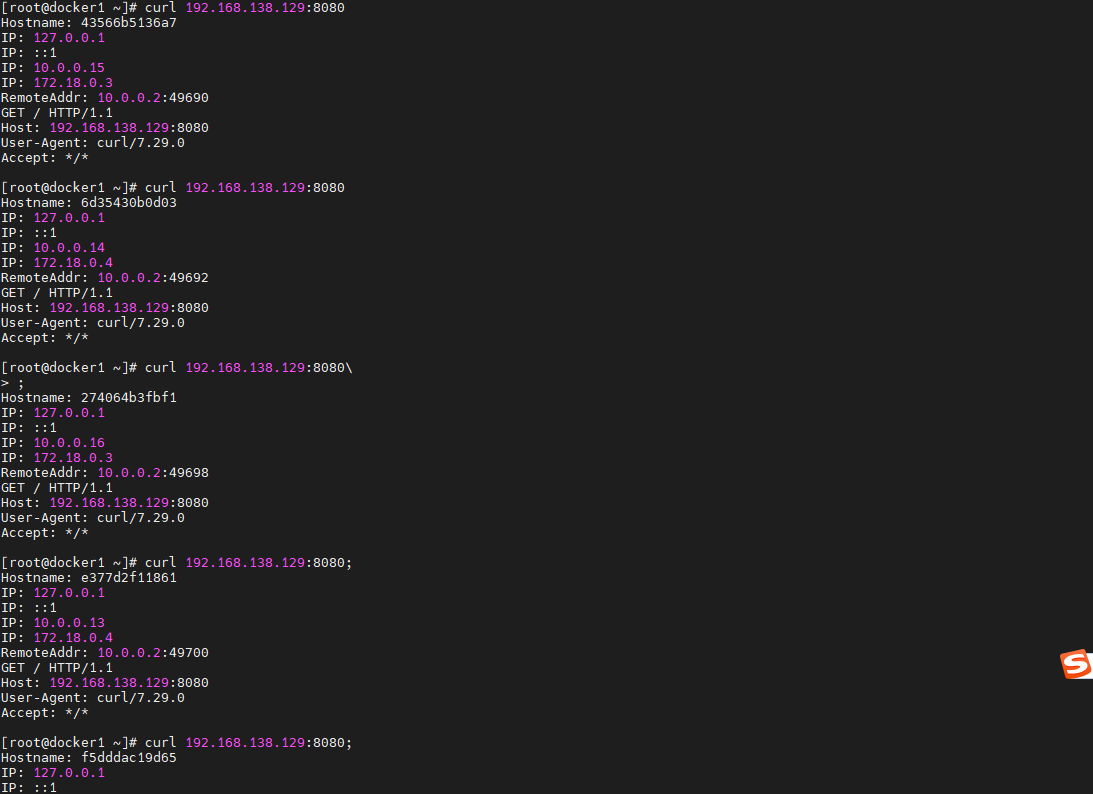
在任意主机上使用curl命令访问swarm集群中的任意节点,无论是manager还是worker,快速访问后,在返回结果中的 Hostname 值就是处理该请求的容器的 ID,第 2 个 IP 为该节点在 Swarm 集群局域网中的 IP。
从结果可以看出,这些请求被轮询分配给了各个 task 容器进行的处理,实现了 service对访问请求的负载均衡。
curl 192.168.138.129:8080- 1
12.8 service 操作
12.8.1 task 伸缩
根据访问量的变化,需要在不停止服务的前提下对服务的 task 进行扩容/缩容,即对服务进行伸缩变化。有两种实现方式:
-
docker service update 方式
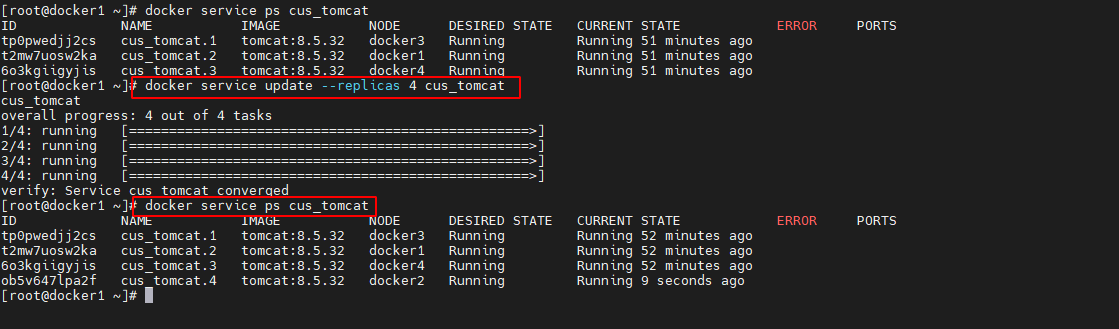
通过 docker service update --replicas 命令可以实现对指定服务的 task 数量进行变更
docker service update --replicas 4 cus_tomcat- 1
-
docker service scale 方式
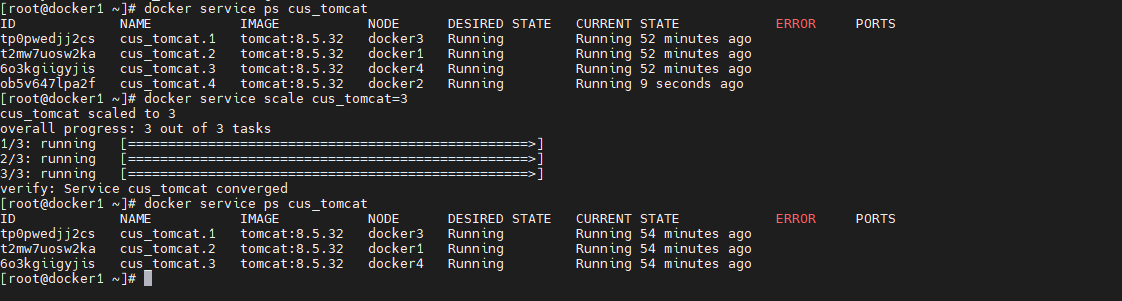
通过 docker service scale 命令可以为指定的服务变更 task 数量,如果设置容器数量多余集群主机数量,则部分主机上面会有多个容器运行
docker service scale cus_tomcat=3- 1
-
暂停节点的 task 分配
生产环境下,可能由于某主机性能不高,在进行 task 扩容时,不想再为该主机再分配更多的 task,此时可通过 pause 暂停该主机节点的可用性来达到此目的。
# 获取tomcat节点情况 docker service ps cus_tomcat- 1
- 2

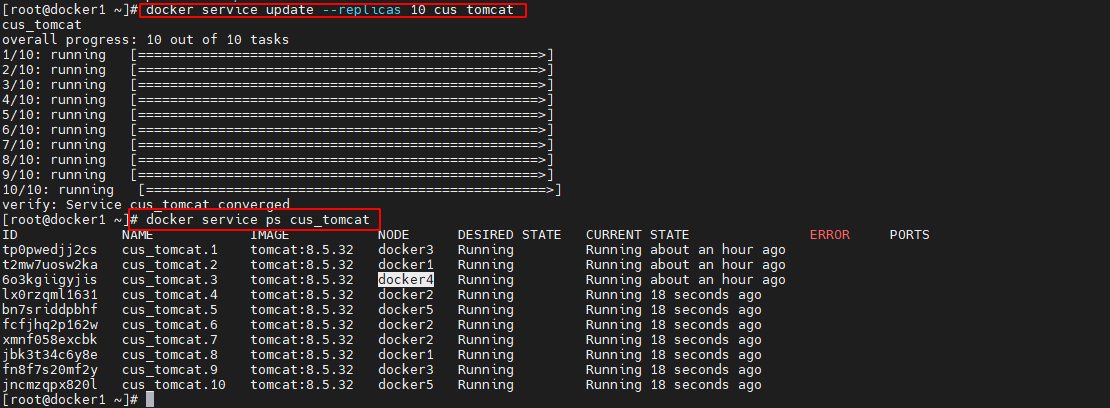
例如:当前 docker4、docker3 与 docker1 三个主机上的 cus_tomcat 服务的 task 情况如下。现准备将 cus_tomcat 服务的 task 扩容为 10,但保持 docker4节点中的 task 数量仍为 1 不变,此时就可通过 docker node update --availability pause 命令修改 docker4 节点的可用性。
docker node update --availability pause docker4 docker service update --replicas 10 cus_tomcat- 1
- 2
-
清空 task
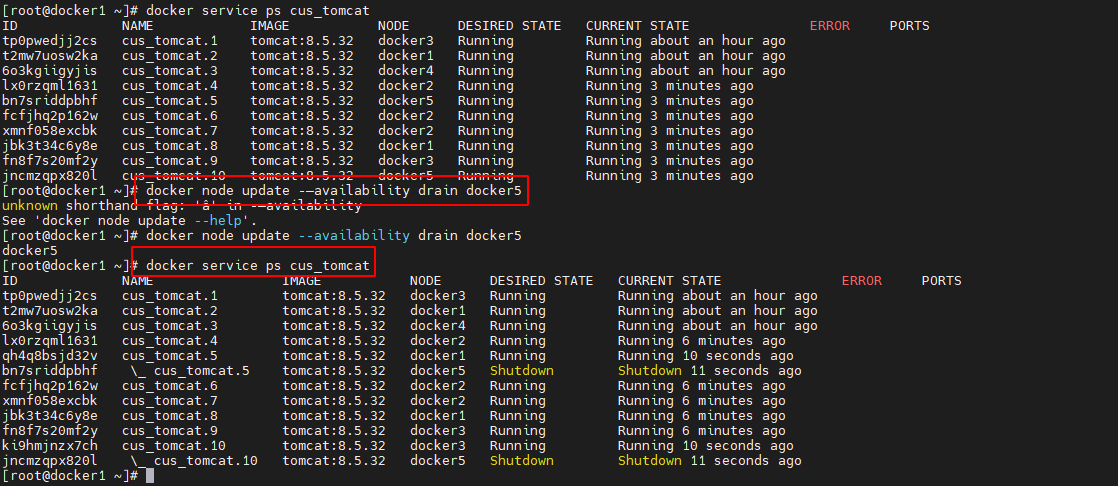
默认情况下,manager 节点同时也具备 worker 节点的功能,可以由分发器为其分配 task。但 manager 节点使用 raft 算法来达成 manager 间数据的一致性,对资源较敏感。因此,阻止 manager 节点接收 task 是比较好的选择。或者,由于某节点出现了性能问题,需要停止服务进行维修,此时最好是将该节点上的task 清空,以不影响 service 的整体性能。通过 docker node update -–availability drain 命令可以清空指定节点中的所有 task。这会导致 Docker Swarm 将所有正在运行的任务从该节点上迁移出去,以便进行维护或其他操作。
例如,目前各个节点的对于 toms 服务的 task 分配情况如下
docker service ps cus_tomcat- 1

现对 docker2 与 docker5 两个节点进行 task 清空操作
docker node update -–availability drain docker5- 1
此时可以看到,cus_tomcat服务的 task 总量并没有减少,只是 docker5 两个节点上是没有 task 的,而全部都分配到了 docker1、docker2、docker3 与 docker4 三个节点上了。这个结果就是由编排器与分发器共同维护的。
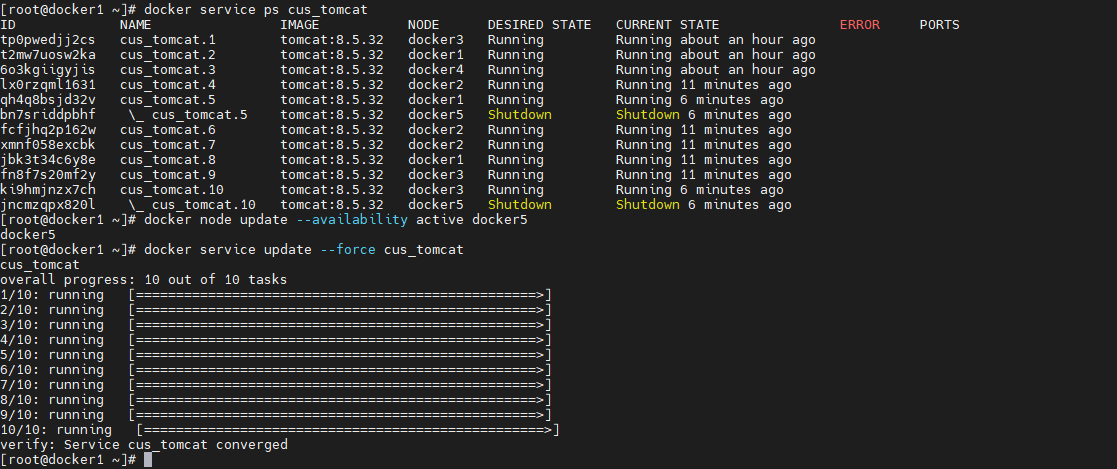
那么如果docker5主机维修完毕,可以提供服了了应该如何恢复呢,可以使用如下命令
# 恢复可用模式 docker node update --availability active docker5- 1
- 2
在更改节点的可用性之后,Docker Swarm 的调度器将开始考虑将新的容器实例放置在该节点上。然而,对于已经运行在其他节点上的容器,它们不会立即迁移到 docker5 上。如果想要强制重新平衡工作负载,你可以更新服务以触发重新调度,例如增加或减少副本数量,然后再次恢复到原来的数量,或者使用 --force 选项更新服务:
docker service update --force cus_tomcat- 1
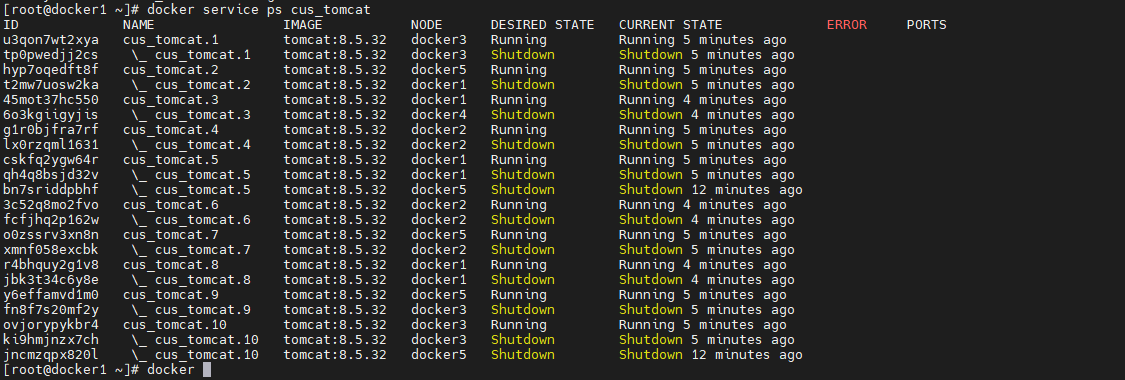
12.8.2 task容错
当某个 task 所在的主机或容器出现了问题时,manager 的编排器会自动再创建出新的task,然后分发器会再选择出一台 available node 可用节点,并将该节点分配给新的 task。
-
停掉容器
现在通过停掉 docker5 主机容器的方式来模拟故障情况。例如停掉 docker5的
# 停止docker5主机的docker服务 systemctl stop docker- 1
- 2

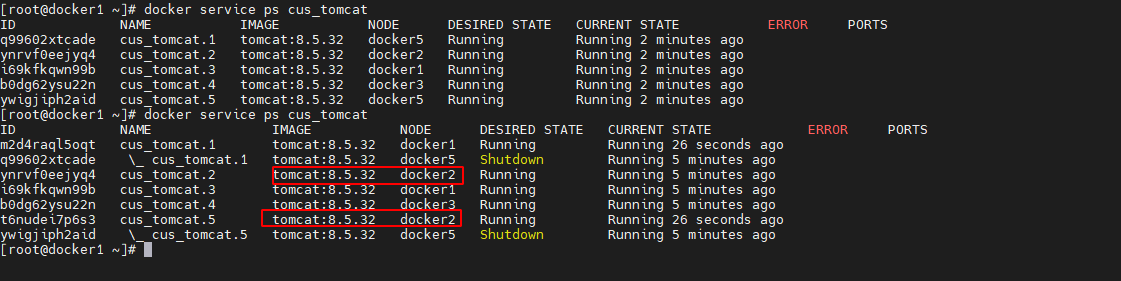
此时再次查看服务,发现docker5对应节点信息已经停止,而docker2上面新增一个节点,进行了补充
12.8.3 服务删除
通过 docker service rm [service name|service ID]可以删除指定的一个或多个 service
docker service rm cus_tomcat
- 1
删除后,该 service 消失,当然,该 service 的所有 task 也全部删除,task 相关的节点容器全部消失。
12.8.4 滚动更新
当一个 service 的 task 较多时,为了不影响对外提供的服务,在对 service 进行更新时可采用滚动更新方式
-
需求
这里要实现的更新时,将原本镜像为 tomcat:8.5.32 的 service 的镜像滚动更新为tomcat:8.5.39。
-
创建 service
创建一个包含 10 个副本 task 的服务,该服务使用的镜像为 tomcat:8.5.32
docker service create \ --name cus_tomcat \ --replicas 10 \ --update-parallelism 2 \ --update-delay 3s \ --update-max-failure-ratio 0.2 \ --update-failure-action rollback \ --rollback-parallelism 2 \ --rollback-delay 3s \ --rollback-max-failure-ratio 0.2 \ --rollback-failure-action continue \ -p 9000:8080 \ tomcat:8.5.32- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
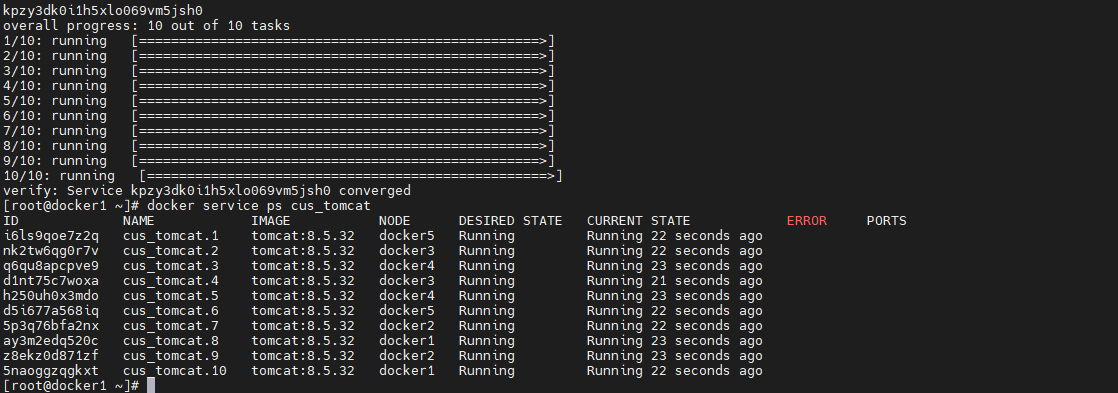
-
更新 service
现要将 service 使用的镜像由 tomcat:8.5.32 更新为 tomcat:8.5.39。
docker service update --image tomcat:8.5.39- 1

会发现这个更新的过程就是前面在创建服务时指定的那样,每次更新 2 个 task,更新间隔为 3 秒。更新完毕后再查看当前的 task 情况发现,已经将所有任务的镜像更新为了 8.5.39 版本。
12.8.5 更新回滚
在更新过程中如果更新失败,则会按照设置的回滚策略进行回滚,回滚到更新前的状态。
但用户也可通过命令方式手工回滚。下面的命令会按照前面设置的每次回滚 2 个 task,每次回滚间隔 3 秒进行回滚。下面的是回滚过程中的某个回滚瞬间。
docker service update --rollback cus_tomcat
- 1
回滚完毕后再查看当前的 task 情况发现,已经将所有任务的镜像恢复为了 8.5.32 版本。但需要注意,task name 保持未变,但 task ID 与原来的 task ID 也是不同的,并不是恢复到了更新之前的 task ID。即编排器新创建了 task,并由分发器重新为其分配了 node。
12.9 service 全局部署模式
根据 task 数量与节点数量的关系,常见的 service 部署模式有两种:replicated 模式与global 模式。前面创建的 service 是 replicated 模式的,下面来创建 global 模式的 service。
12.9.1 环境变更
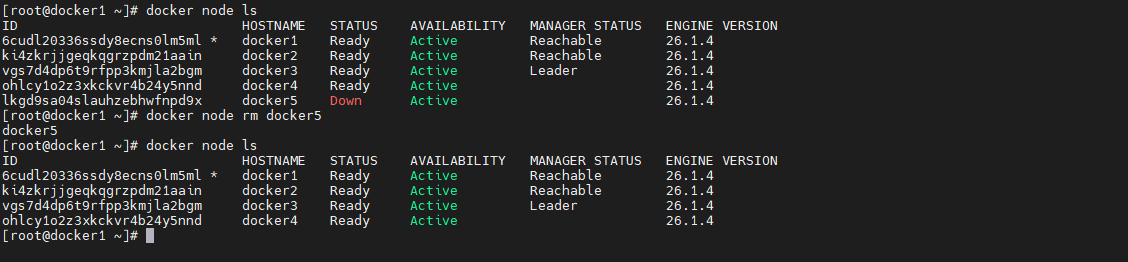
为了后面的演示效果,让 swarm 集群的节点变为 4 个。这里先使 docker5 退群\
docker swarm leave
- 1

将此节点再从 swarm 集群中删除
docker node rm docker5
- 1
12.9.2 创建 service
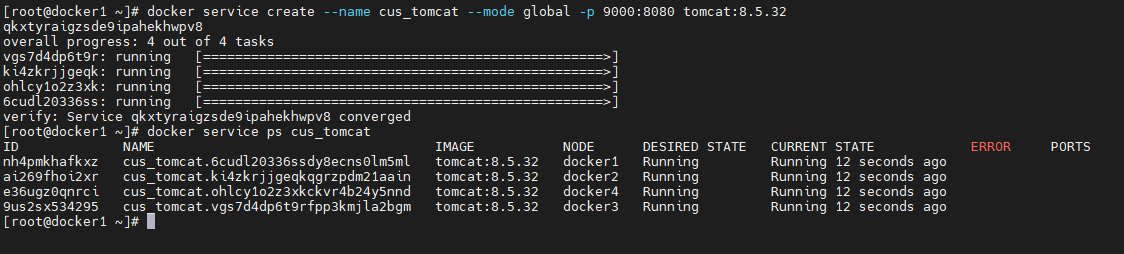
在 docker service create 命令中通过 –mode 选项可以指定要使用的 service 部署模式,默认为 replicated 模式。该模式会在每个节点上分配一个 task
docker service create --name cus_tomcat --mode global -p 9000:8080 tomcat:8.5.32
- 1
12.9.3 task 伸缩
对于 global 模式来说,若要实现对 service 的 task 数量的变更,必须通过改变该 servicve所依附的 swarm 集群的节点数量来改变。节点增加,则 task 会自动增加;节点减少,则 task会自动减少。
下面要在这个 4 节点的 swarm 集群中增加一个节点,以使 toms 服务的 task 也增一。首先在 manager 节点获取新增一个节点的 token。
docker swarm join-token worker
# 返回shell命令如下
docker swarm join --token SWMTKN-1-2ia3harocxprk7l26e4x2sl71pmqe4u3o7sacomxatd44o2okd-dtwfx95zf6cjtkca3khkdkl6q 192.168.138.129:2377
- 1
- 2
- 3

在docker5上执行此命令
docker swarm join --token SWMTKN-1-2ia3harocxprk7l26e4x2sl71pmqe4u3o7sacomxatd44o2okd-dtwfx95zf6cjtkca3khkdkl6q 192.168.138.129:2377
- 1

返回docker manager查看容器情况,发现多了一个docker5节点信息
docker service ps cus_tomcat
- 1

12.10 overlay 网络
12.10.1 测试环境1搭建
-
暂停分配 task
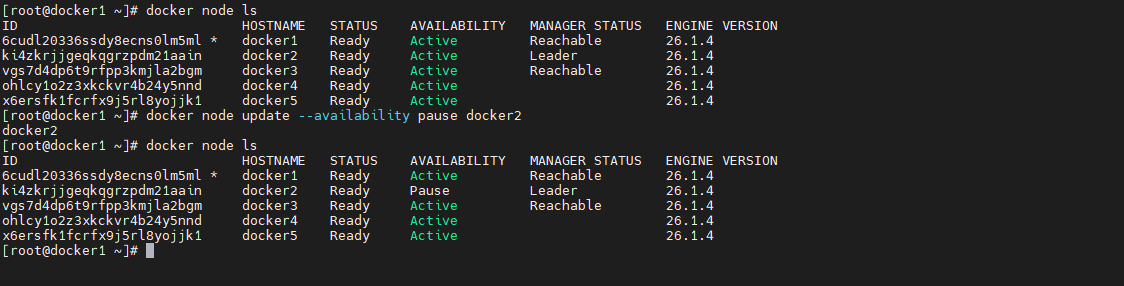
暂停docker2对外提供分配服务
docker node ls docker node update --availability pause docker2- 1
- 2
-
创建 service
现启动一个 service,包含 10 个 task
docker service create --name cus_tomcat --update-order start-first --replicas 10 -p 9000:8080 tomcat:8.5.32- 1
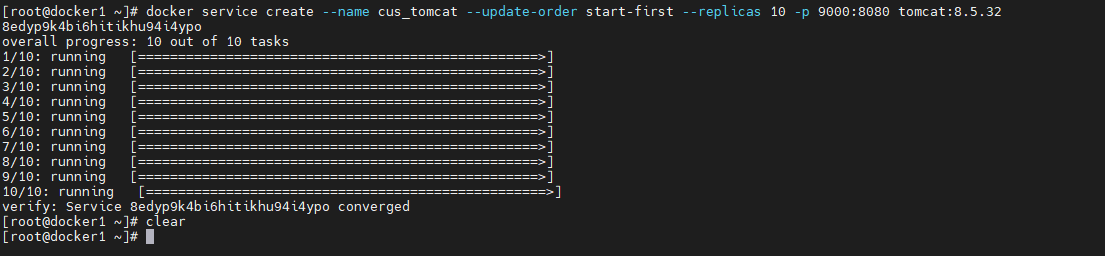

当前 swarm 集群共有 5 个节点,10 个 task 被分配到了 4 个可用节点上,其中除了被暂停的 docker2 节点上是没有分配 task 外,其余节点都分配了多个 task
12.10.2 overlay 网络概述
-
overlay 网络简介
overlay 网络,也称为重叠网络或覆盖网络,是一种构建于 underlay 网络之上的逻辑虚拟网络。即在物理网络的基础上,通过节点间的单播隧道机制将主机两两相连形成的一种虚拟的、独立的网络。
Docker Swarm 集群中的 overlay 网络主要是通过 iptables、ipvs、vxlan 等技术实现的、基于其本身通信需求的网络模型。
-
overlay 网络模型
这里要说的 overlay 网络模型,确切地说,是 Docker Swarm 集群的 overlay 网络模型
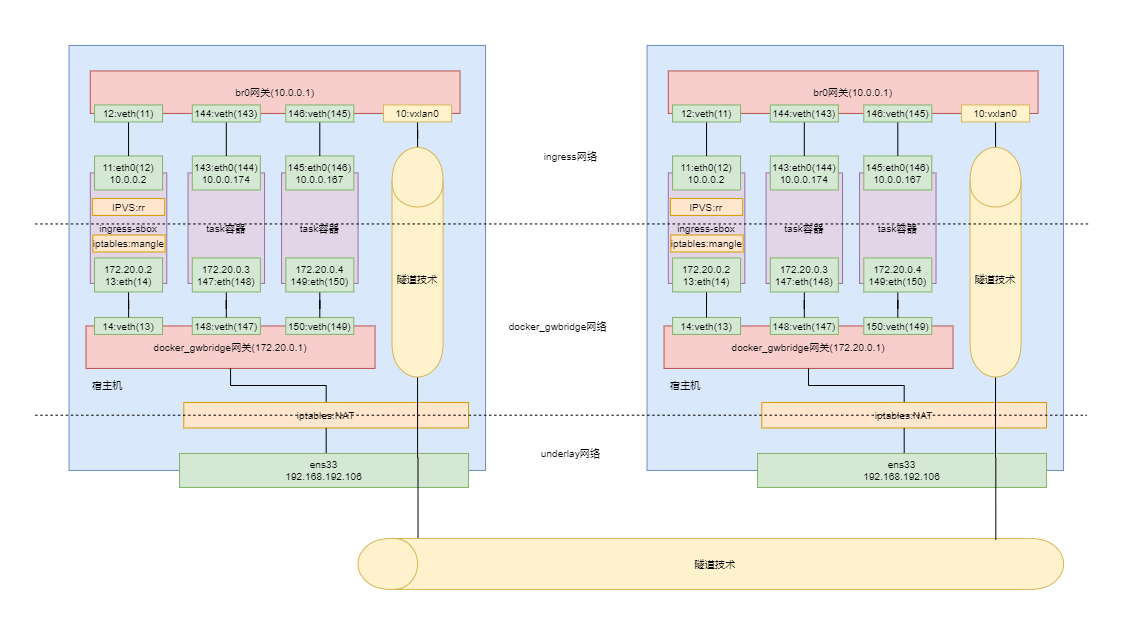
Docker Swarm 集群的 overlay 网络模型在创建时,会创建出两个网络:docker_gwbidge网络与 ingress 网络。这就是典型的 overlay 网络——在宿主机的物理网络之上又创建出新的网络。同时还创建出了 docker_gwbidge 网关与 br0 网关,及 ingress-sbox 容器。
当请求到达后会首先经由 docker_gwbidge 网关跳转到 ingress-sbox 容器,在其中具有当前整个service的所有容器IP,在其中通过轮询负载均衡方式选择一个容器IP作为目标地址,然后再跳转到 br0 网关。在 br0 网关中会根据目标地址所在主机进行判断。若目标地址为本地容器 IP,则直接将请求转发给该容器处理即可。若目标地址非本地容器 IP,则会将请求经由 vxlan 接口,通过 vxlan 隧道技术将请求转发给目标地址容器
12.10.3 docker_gwbridg网络基础信息
在详细分析 overlay 网络模型的通信原理之前,首先来了解一下 docker swarm 的 overlay网络的基础信息。
-
查看 docker_gwbridge 网络详情
docker swarm 集群的 overlay 网络模型在创建时,会自动创建两个网络:docker_gwbridge网络与 ingress 网络。
docker network ls- 1

查看 docker_gwbridge 网络详情可以看到,docker_gwbridge 网络包含的子网为 172.18.0.0/16,其网关为 172.18.0.1。那么,这个网关是谁呢
docker network inspect docker_gwbridge- 1
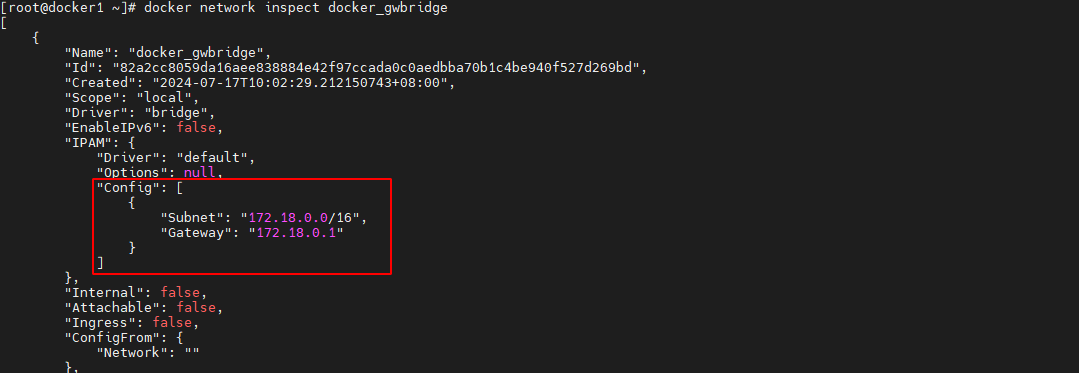
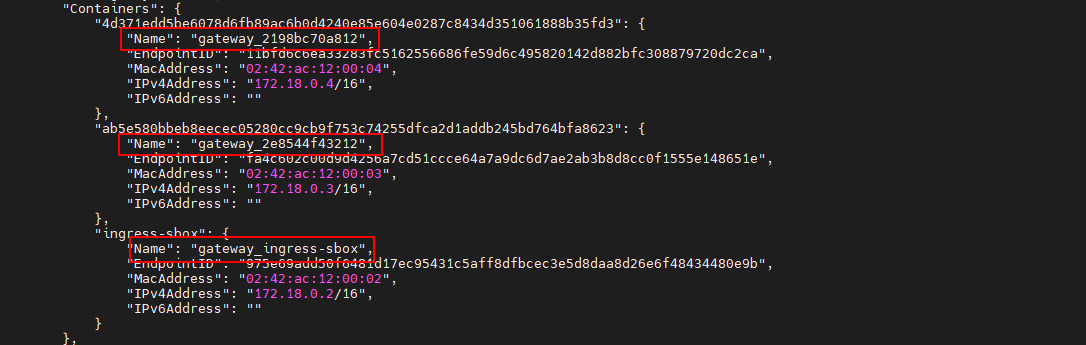
同时还看到,该网络中包含了 3 个容器。其中 2 个为 service 的 task 容器,另一个的容器 ID 为 ingress-sbox。
-
ingress-sbox容器
docker ps -a- 1

通过 docker ps –a 命令查看当前主机中的所有容器,发现并没有 ingress-sbox 容器。为什么?因为 docker ps 命令的本质是 docker process status,查看的是当前主机中真实存在的容器进程的状态。而 ingress-sbox 容器是由 overlay 网络虚拟出的,并不是真实存在的进程,所以通过 docker ps 命令是查看不到的。
从 docker_gwbridge 的网络详情中可以看到,其中 2 个为 service 的 task 容器,其 ID 由64 位 16 进制数构成,而 ingress-sbox 容器的 ID 就是 ingress-sbox,与其它 2 个容器的 ID 构成方式完全不同
-
docker_gwbridge 网关
docker_gwbridge 的网络详情中的网关 172.18.0.1 是谁呢?
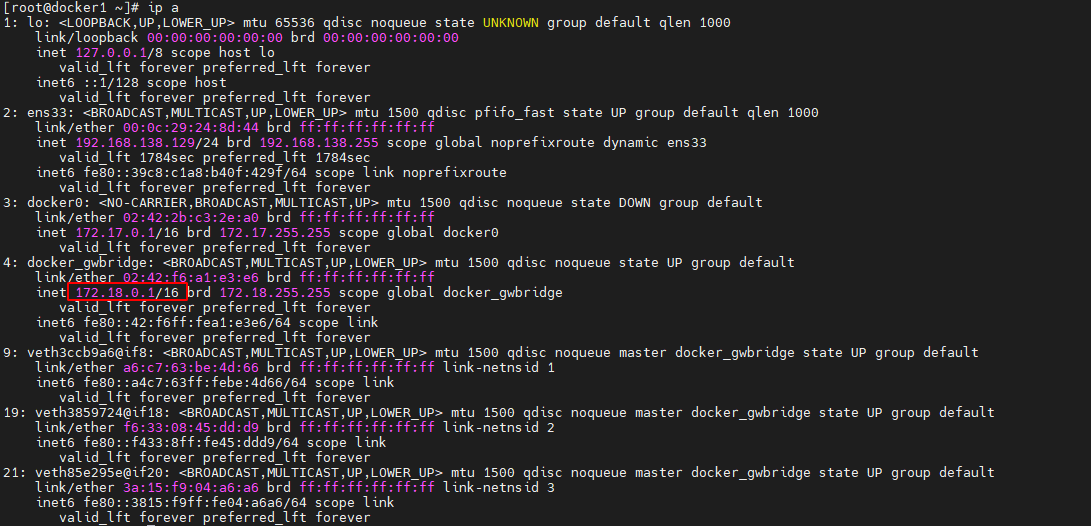
在宿主机中通过 ip a 命令查看宿主机的网络接口,可以看到 docker_gwbridge 接口的 IP为 172.18.0.1。即 docker_gwbridge 网络中具有一个与网络名称同名的网关。同时还看到,下面的 3 个接口全部都是连接在 docker_gwbridge 上的。
-
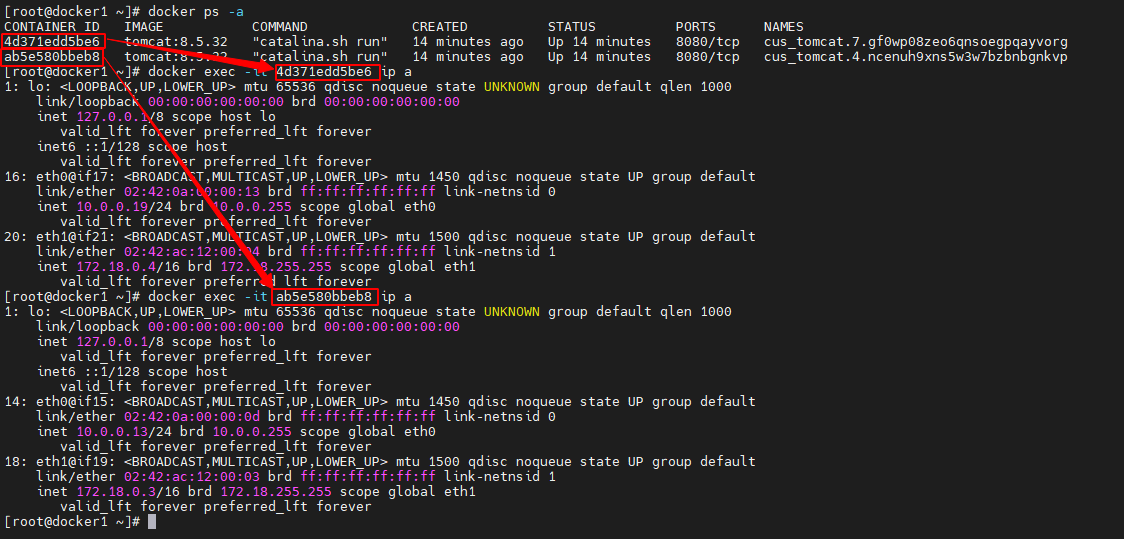
查看task容器的接口
查看 docker_gwbridge 网络的 task 容器的接口情况,可以看到这些容器中正好有接口与docker_gwbridge 网关中的相应接口构成 veth paire4
docker ps -a docker exec -it 4d371edd5be6 ip a docker exec -it ab5e580bbeb8 ip a- 1
- 2
- 3
-
查看 ingress-sbox 容器的接口
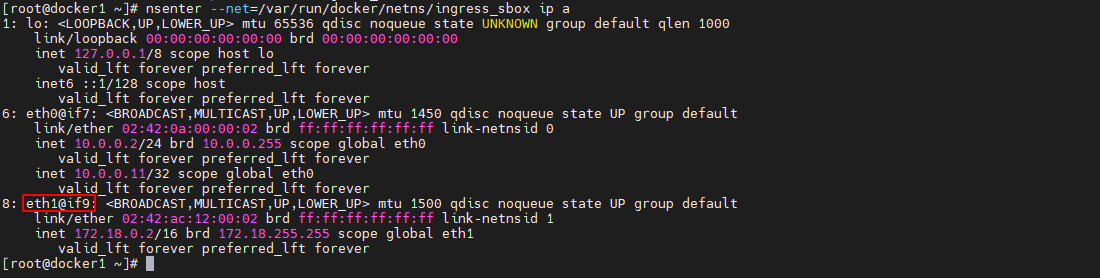
如何查看docker_gwbridge网络的ingress-sbox容器的接口情况呢?每个容器都具有一个独立的网络命名空间,而每个 docker 主机中的网络命名空间,都是以文件的形式保存在目录/var/run/docker/netns 中
ll /var/run/docker/netns- 1

其中 ingress_sbox 就是容器 ingress-sbox 的网络命名空间。通过 nsenter 命令可进入该命名空间并查看其接口情况。可以看到该命名空间中正好也存在接口与 docker_gwbridge 网关中的相应接口构成 veth paire
nsenter --net=/var/run/docker/netns/ingress_sbox ip a- 1
12.10.4 ingress网络基础信息
-
查看 ingress 网络详情
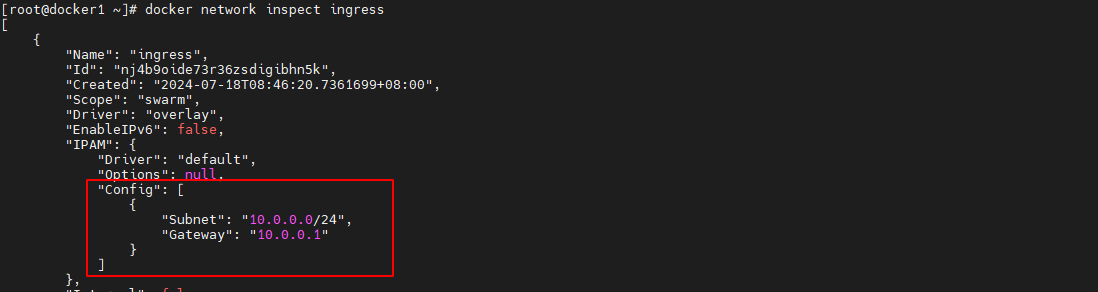
overlay 网络除了创建了 docker_gwbridge 网络外,还创建了一个 ingress 网络
docker network ls- 1

查看 ingress 网络详情可以看到,ingress 网络包含的子网为 10.0.0.0/24,其网关为 10.0.0.1。那么,这个网关是谁呢
同时还看到,该网络中也包含了 3 个容器,这 3 个容器与 docker_gwbridge 网络中的 3个容器是相同的容器,虽然 Name 不同,IP 不同,但容器 ID 相同。说明这 3 个容器都同时连接在 2 个网络中。
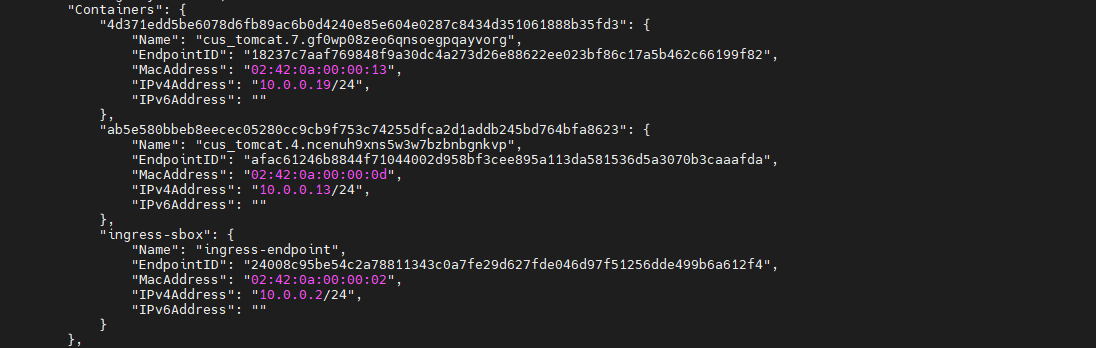
-
br0 网关
10.0.0.1 网关是谁呢?每个容器都具有一个独立的网络空间,而每个 docker 主机中的网络命名空间,都是以文件的形式保存在/var/run/docker/netns 目录中。查看当前主机的网络空间:
ll /var/run/docker/netns- 1

查看/var/run/docker/netns 目录中的命名空间发现,其包含的 4 个命名空间中,有 2 个命名空间是 2 个 task 容器的,它们的名称由 12 位长度的 16 进制数构成;ingress_sbox 是ingress-sbox 容器的命名空间。那么,1-nj4b9oide7 命名空间是谁呢?进入该命名空间,查看其接口信息。
nsenter --net=/var/run/docker/netns/1-nj4b9oide7 ip a- 1
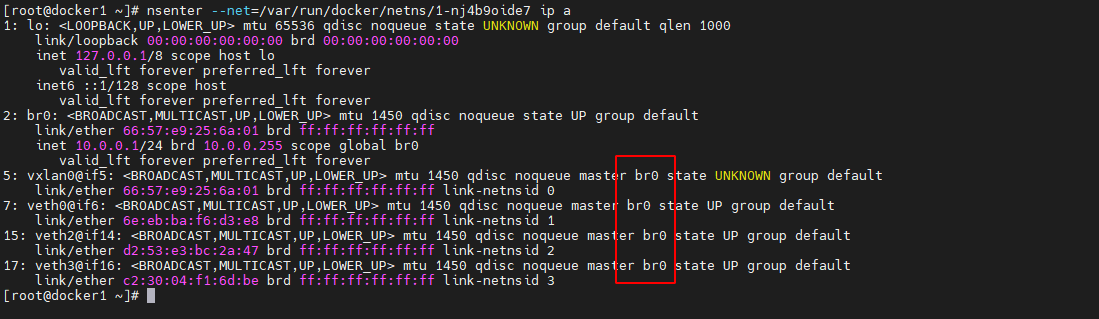
可以看到 2 号接口 br0 的 IP 为 10.0.0.1,即 ingress 网络的网关为 1-nj4b9oide7 命名空间中的 br0。同时还看到,br0 上还连接着 4 个接口,说明 br0 就是一个网关。那么,都是谁连接在这 4 个接口上呢?
-
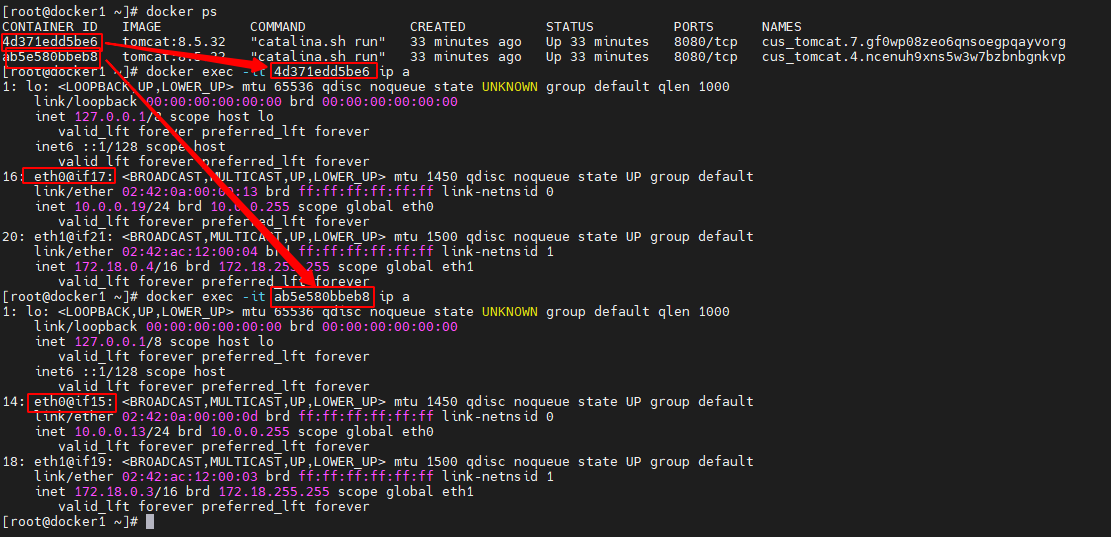
查看task容器的接口
查看 ingress 网络的 task 容器的接口情况,可以看到这些容器中正好有接口与 br0 网关中的相应接口构成 veth paire
-
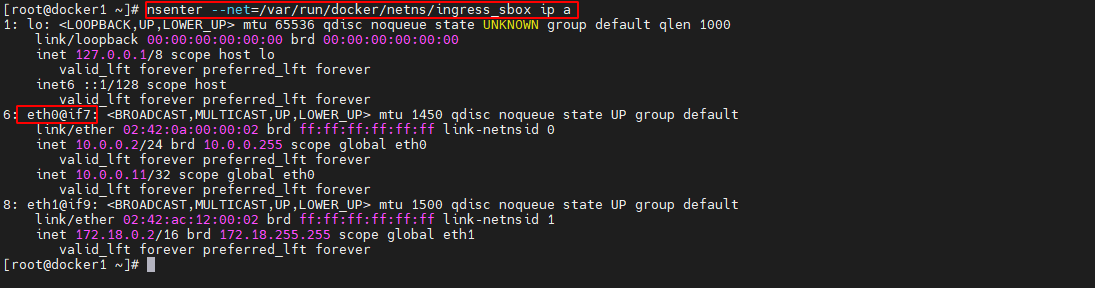
查看 ingress-sbox 容器的接口
查看 ingress-sbox 容器的命名空间 ingress_sbox 的接口情况,可以看到该命名空间中正好也存在接口与 br0 网关中的相应接口构成 veth paire
nsenter --net=/var/run/docker/netns/ingress_sbox ip a- 1
12.10.5 宿主机的 NAT 过程
-
查看宿主机路由
用户提交的192.168.138.129:9000请求会首先被192.168.138.129主机的哪个接口接收并处理呢?通过命令 ip route 可以查看当前网络命名空间中的静态路由信息
ip route- 1

可以看出,所有对 192.168.138.0/24 网络的请求,都需要经过 ens33 接口,而该接口连接的 IP 为 192.168.138.129。即 ens33 接口会处理该请求。当然,查看该主机的接口情况也可以看到,ens33 接口地址为 192.168.138.129
ip a- 1
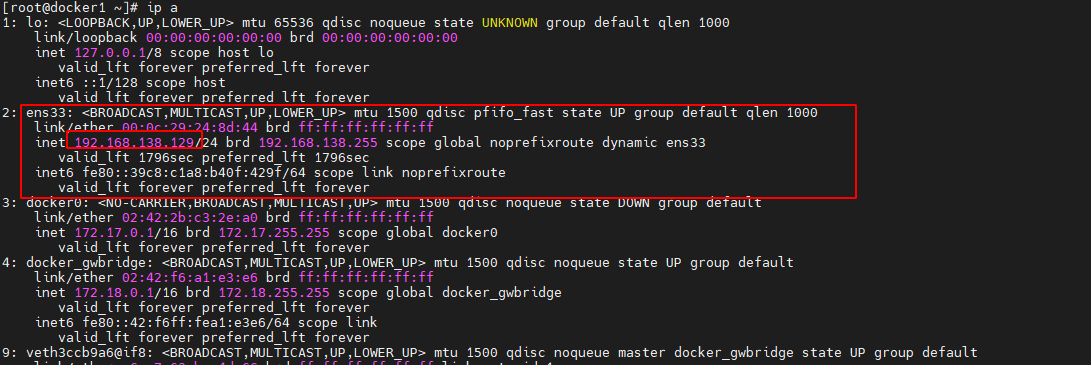
那么 ens33 接口又会将请求转发到哪里呢?这就需要查看宿主机的路由转发表 nat 中的路由规则了。
-
查看 ip 转换规则
首先通过 iptables –nvL –t nat 命令来查看宿主机中网络地址转发表 nat 中的转发规则。nat 表的主要功能是根据规则进行地址映射、端口映射,以完成地址转换
iptables -nvL -t nat- 1
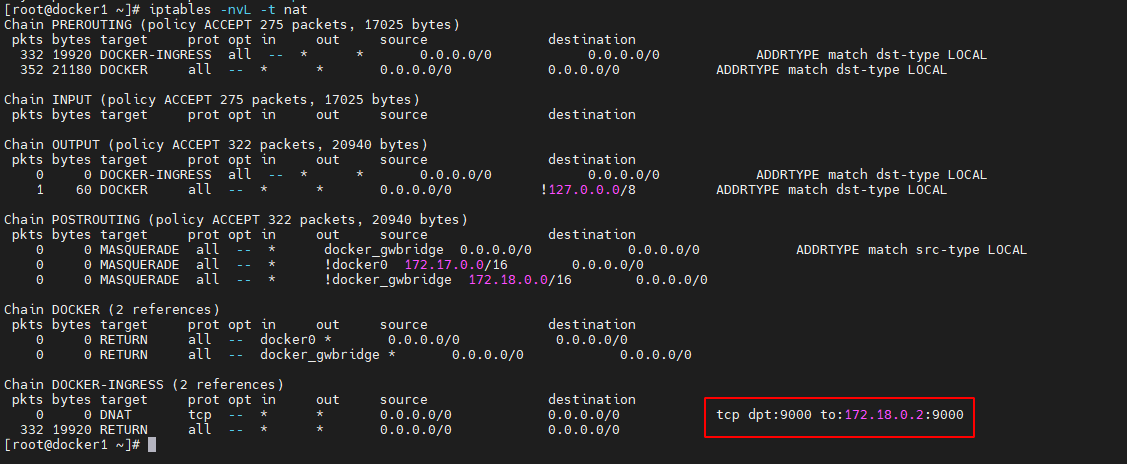
DOCKER-INGRESS 路由链路中的 DNAT 映射规则中指出,对于任何源 IP,只要其访问端口号为 9000,就会将其转换为 172.18.0.2:9000 的请求,即将请求转发到 172.18.0.2。那么请求是如何到达 172.18.0.2 的呢?
-
查看宿主机路由
通过 ip route 命令查看当前宿主机的静态路由信息
ip route- 1

可以看出,所有对 172.18.0.0/16 网络的请求,都需要经过 docker_gwbridge 接口,而该接口连接的 IP 为 172.18.0.1。即 docker_gwbridge 接口会处理该请求。由一个网络去访问另一个网络必须要经过该目标网络的网关。经前面的学习知道,docker_gwbridge 正好就是172.18.0.0/16 网络的网关。
也就是说,客户端提交的 192.168.138.129:9000 的请求,经 docker_gwbridge 网关,被路由到了 IP 为 172.18.0.2 的接口。那么谁的 IP 是 172.18.0.2 呢?经过前面网络基础信息查看可知,docker_gwbridge 网络中包含 IP 为 172.18.0.2 的 ingress-sbox 容器。
12.10.6 ingress_sbox 的负载均衡
客户端请求经宿主机的 NAT 已经成功通过 docker_gwbridge 网关转发到了 172.18.0.2,即转发到了 ingress-sbox 容器,或者更确切地说,是转发到了 ingress_sbox 命名空间。那么,ingress_sbox 命名空间又会将请求转发到哪里呢?这就需要查看 ingress_sbox 命名空间的iptables 的 mangle 表与 IPVS 功能了
-
查看ingress_sbox 的mangle表
mangle 表的主要功能是根据规则修改数据包的一些标志位,以便其他规则或程序可以利用这种标志对数据包进行过滤或路由
nsenter --net=/var/run/docker/netns/ingress_sbox iptables -nvL -t mangle- 1
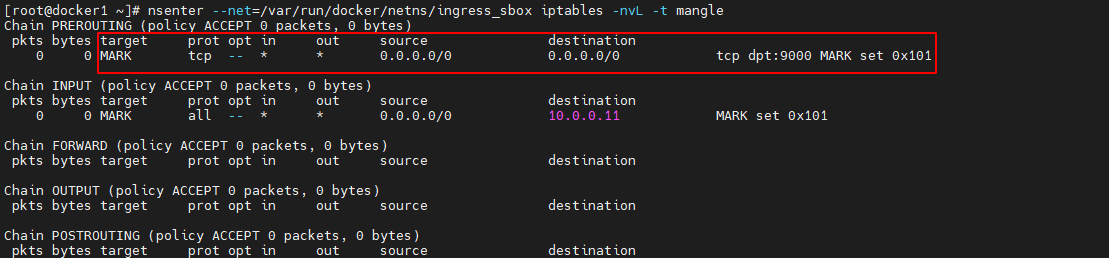
该路由链中为任意源地址端口为 9000 的请求打了一个 MARK 标记 0x101,该 MARK 标记将被 IPVS 用于负载均衡
-
安装 ipvsadm 命令
后面我们需要使用该命令查看 IPVS 实现的负载均衡规则,但由于 CentOS 系统中默认没有安装 ipvsadm 命令,所以需要先 yum 安装。
yum install -y ipvsadm- 1
-
查看 ingress_sbox 负载均衡规则
nsenter --net=/var/run/docker/netns/ingress_sbox ipvsadm- 1
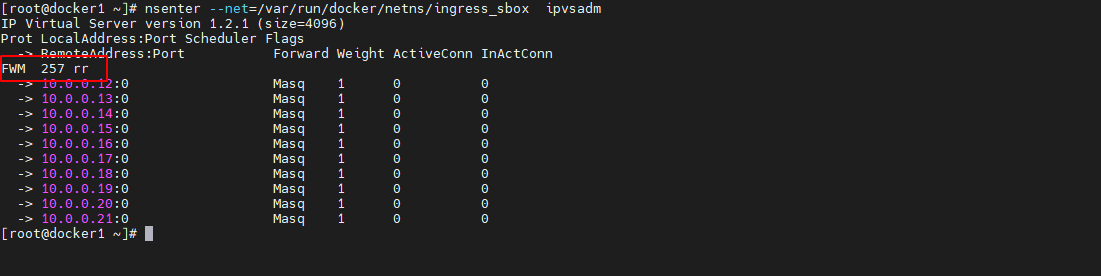
端口为 9000 的请求被打上了一个数值为 257 的 MARK 标记,该标记通过 LVS 的 IPVS 的负载均衡,将该请求转发到了下面的 10 个 IP 接口,且这 10 个接口的权重 weight 是相同的,都是 1。这 10 个 IP 接口具有一个共同点,全部来自于 10.0.0.0/24 网络。那么,如何能到达10.0.0.0/24 网络呢
-
查看命名空间路由
通过前面的学习可知,若要由一个网络转发到另一个网络,则必须要先到目标网络的网关。由于目前尚在 172.18.0.0/16 网络,预转发到 10.0.0.0/24 网络,所以必须要先到 10.0.0.0/24网络的网关 10.0.0.1,即 br0。通过查看 br0 所在命名空间 1-nj4b9oide7的静态路由也可看出
nsenter --net=/var/run/docker/netns/1-nj4b9oide7 ip route- 1

但存在的问题是,请求目前尚在 ingress_sbox 命名空间中,怎样才能从 ingress_sbox 命名空间中出去,然后跳转到 br0 呢?查看 ingress_sbox 命名空间中的静态 IP 路由
nsenter --net=/var/run/docker/netns/ingress_sbox ip route- 1

可以看出,所有对 10.0.0.0/24 网络的请求,都需要经过 eth0 接口,而该接口连接的 IP为 10.0.0.2。在 ingress_sbox 命名空间中 eth0 接口就是 7 号接口,其 veth pair 接口就是 br0中的 7 号接口。所以,ingress_sbox 命名空间中请求经由 6 号接口跳转到了 br0 网关
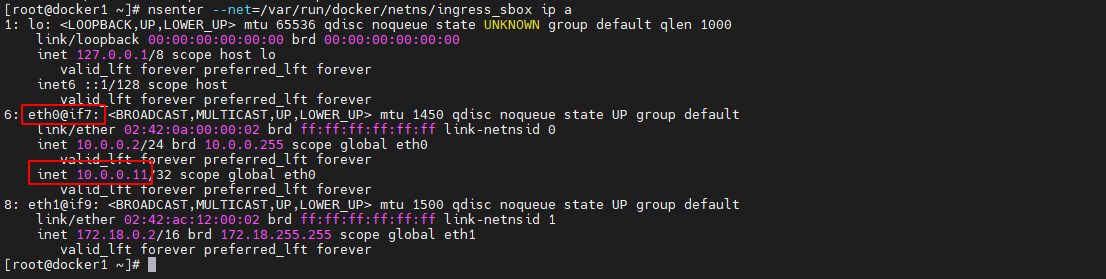
-
br0网关的处理
到达 br0 后,再将请求从 br0 的哪个接口转发出去,是由目标地址决定的,而目标地址就是 IPVS 负载均衡选择出的 IP。请求到达 br0 后,首先会将目标地址与本地的 task 容器地址进行比较,若恰好就是当前宿主机中的 task 容器的 IP,那么直接将请求通过相应的接口将其转发;若不是当前宿主机中的 IP,则会将请求转发到 vxlan0 接口。经过 vxlan0 接口,\可经由 VXLAN 技术将请求通过“网络隧道”发送到目标地址
12.10.7 VXLAN
-
VXLAN 简介
VXLAN 是一种隧道技术,可以将不同协议的数据包重新封装后发送。新的包头提供了路由信息,从而使被封装的数据包在隧道的两个端点间通过公共互联网络进行路由。被封装的数据包在公共互联网络上传递时所经过的逻辑路径称为隧道。一旦到达网络终点,数据将被解包并转发到最终目的地。
-
测试环境 2 搭建
为了能够看清楚请求在不同主机的容器间所进行了通信,及通信过程中所使用的 VXLAN技术,这里将原来的服务先删除,然后再创建一个新的服务。不过,该服务仅有一个副本。
首先删除原来的 service,然后在任意主机中创建一个新的 servivce,其仅包含一个副本。这里在 docker3 主机创建了服务。可以看到,这唯一的副本被分配到了 docker5 主机。
docker service rm cus_tomcat docker service create --name cus_tomcat --replicas 1 -p 9000:8080 tomcat:8.5.32- 1
- 2

-
安装tcpdump命令
这里准备使用 tcpdump 命令对 VXLAN 数据进行监听,但在 centOS7 系统中默认是没有安装 tcpdump 命令的,需要使用 yum 命令先在 docker1 主机安装
yum install -y tcpdump- 1

-
docker3 先监听
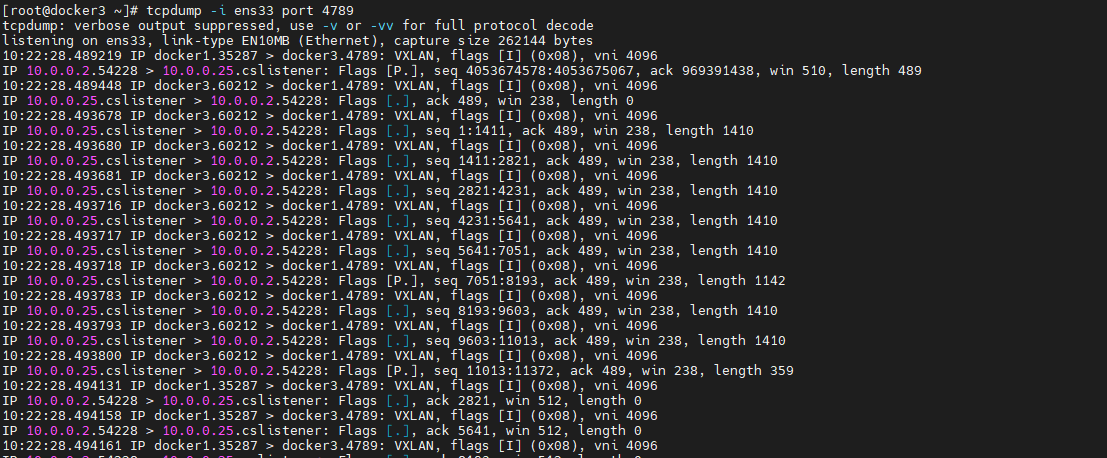
无论对哪个主机的该服务进行访问,请求最终都会通过 docker3 主机的 ens33 接口进入,然后再找到该 task 容器。所以这里要先监听 docker3 的 ens33 接口。
tcpdump -i ens33 port 4789- 1
通过浏览器访问docker1,docker3会监听到docker1发过来的请求信息
12.11 Raft 算法
12.11.1 基础
Raft 算法是一种通过对日志复制管理来达到集群节点一致性的算法。这个日志复制管理发生在集群节点中的 Leader 与 Followers 之间。Raft 通过选举出的 Leader 节点负责管理日志复制过程,以实现各个节点间数据的一致性。
12.11.2 角色、任期及角色转变
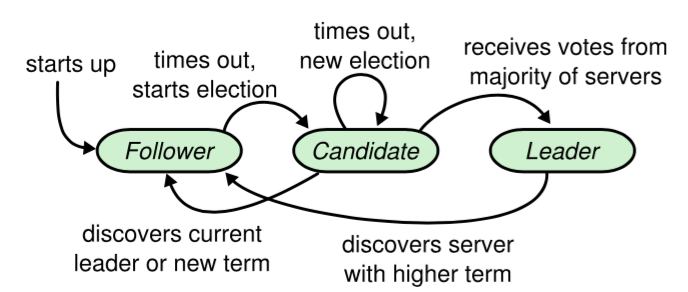
在 Raft 中,节点有三种角色
- Leader:唯一负责处理客户端写请求的节点;也可以处理客户端读请求;同时负责日志复制工作
- Candidate:Leader 选举的候选人,其可能会成为 Leader。是一个选举中的过程角色
- Follower:可以处理客户端读请求;负责同步来自于 Leader 的日志;当接收到其它Cadidate 的投票请求后可以进行投票;当发现 Leader 挂了,其会转变为 Candidate 发起Leader 选举
12.11.3 leader 选举
通过 Raft 算法首先要实现集群中 Leader 的选举
-
我要选举
若 follower 在心跳超时范围内没有接收到来自于 leader 的心跳,则认为 leader 挂了。此时其首先会使其本地 term 增一。然后 follower 会完成以下步骤:
-
此时若接收到了其它 candidate 的投票请求,则会将选票投给这个 candidate
-
由 follower 转变为 candidate
-
若之前尚未投票,则向自己投一票
-
向其它节点发出投票请求,然后等待响应
-
-
我要投票
follower 在接收到投票请求后,其会根据以下情况来判断是否投票
- 发来投票请求的 candidate 的 term 不能小于我的 term
- 在我当前 term 内,我的选票还没有投出去
- 若接收到多个 candidate 的请求,我将采取 first-come-first-served 方式投票
-
等待响应
当一个 Candidate 发出投票请求后会等待其它节点的响应结果。这个响应结果可能有三种情况
- 收到过半选票,成为新的 leader。然后会将消息广播给所有其它节点,以告诉大家我是新的 Leader 了
- 接收到别的 candidate 发来的新 leader 通知,比较了新 leader 的 term 并不比自己的 term小,则自己转变为 follower
- 经过一段时间后,没有收到过半选票,也没有收到新 leader 通知,则重新发出选举
-
选举时机
在很多时候,当 Leader 真的挂了,Follower 几乎同时会感知到,所以它们几乎同时会变为 candidate 发起新的选举。此时就可能会出现较多 candidate 票数相同的情况,即无法选举出 Leader为了防止这种情况的发生,Raft 算法其采用了 randomized election timeouts 策略来解决这个问题。其会为这些 Follower 随机分配一个选举发起时间 election timeout,这个 timeout在 150-300ms 范围内。只有到达了 election timeout 时间的 Follower 才能转变为 candidate,否则等待。那么 election timeout 较小的 Follower 则会转变为 candidate 然后先发起选举,一般情况下其会优先获取到过半选票成为新的 leader
12.11.4 数据同步
在 Leader 选举出来的情况下,通过日志复制管理实现集群中各节点数据的同步
-
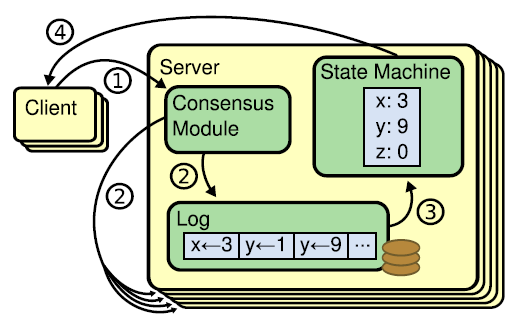
状态机
Raft 算法一致性的实现,是基于日志复制状态机的。状态机的最大特征是,不同 Server中的状态机若当前状态相同,然后接受了相同的输入,则一定会得到相同的输出
-
处理流程
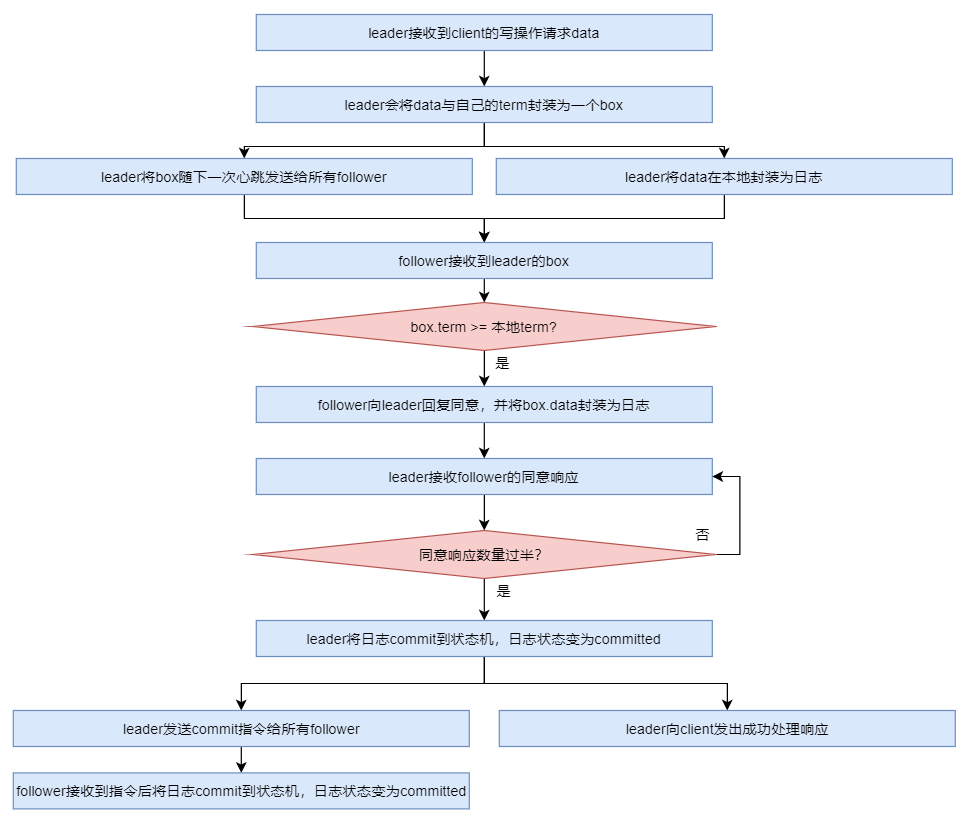
当 leader 接收到 client 的写操作请求后,大体会经历以下流程:
-
leader 在接收到 client 的写操作请求后,leader 会将数据与 term 封装为一个 box,并随着下一次心跳发送给所有 followers,以征求大家对该 box 的意见。同时在本地将数据封装为日志
-
follower 在接收到来自 leader 的 box 后首先会比较该 box 的 term 与本地记录的曾接受过的 box 的最大 term,只要不比自己的小就接受该 box,并向 leader 回复同意。同时会将该 box 中的数据封装为日志。
-
当 leader 接收到过半同意响应后,会将日志 commit 到自己的状态机,状态机会输出一个结果,同时日志状态变为了 committed
-
同时 leader 还会通知所有 follower 将日志 commit 到它们本地的状态机,日志状态变为了 committed
-
在 commit 通知发出的同时,leader 也会向 client 发出成功处理的响应
-
-
AP 支持
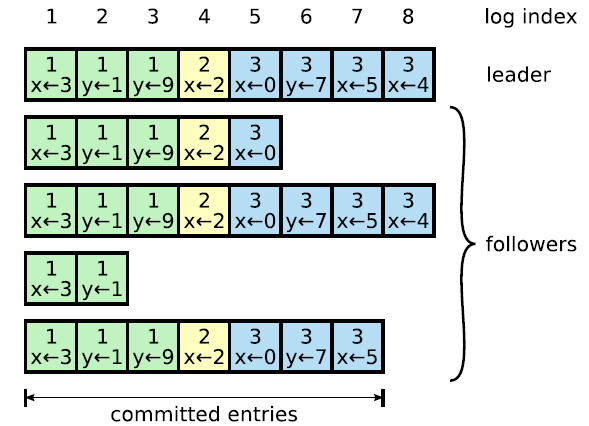
Log 由 term index、log index 及 command 构成。为了保证可用性,各个节点中的日志可以不完全相同,但 leader 会不断给 follower 发送 box,以使各个节点的 log 最终达到相同。
即 raft 算法不是强一致性的,而是最终一致的
12.11.5 脑裂
Raft 集群存在脑裂问题。在多机房部署中,由于网络连接问题,很容易形成多个分区。而多分区的形成,很容易产生脑裂,从而导致数据不一致。由于三机房部署的容灾能力最强,所以生产环境下,三机房部署是最为常见的。下面以三机房部署为例进行分析,根据机房断网情况,可以分为五种情况:
-
情况一 不确定
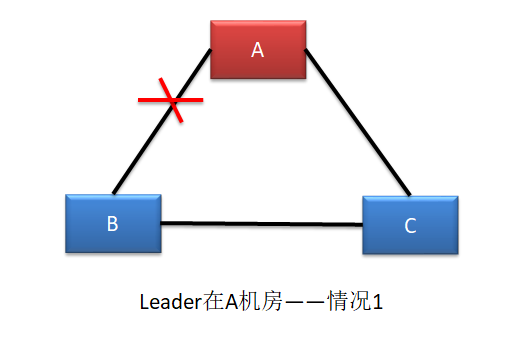
这种情况下,B 机房中的主机是感知不到 Leader 的存在的,所以 B 机房中的主机会发起新一轮的 Leader 选举。由于 B 机房与 C 机房是相连的,虽然 C 机房中的 Follower 能够感知到 A 机房中的 Leader,但由于其接收到了更大 term 的投票请求,所以 C 机房的 Follower也就放弃了 A 机房中的 Leader,参与了新 Leader 的选举。
若新 Leader 出现在 B 机房,A 机房是感知不到新 Leader 的诞生的,其不会自动下课,所以会形成脑裂。但由于 A 机房 Leader 处理的写操作请求无法获取到过半响应,所以无法完成写操作。但 B 机房 Leader 的写操作处理是可以获取到过半响应的,所以可以完成写操作。故,A 机房与 B、C 机房中出现脑裂,且形成了数据的不一致。
若新 Leader 出现在 C 机房,A 机房中的 Leader 则会自动下课,所以不会形成脑裂
-
情况二 形成脑裂
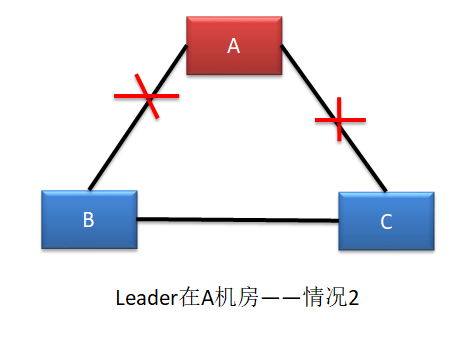
这种情况与情况一基本是一样的。不同的是,一定会形成脑裂,无论新 Leader 在 B 还是 C 机房
-
情况三 无脑裂
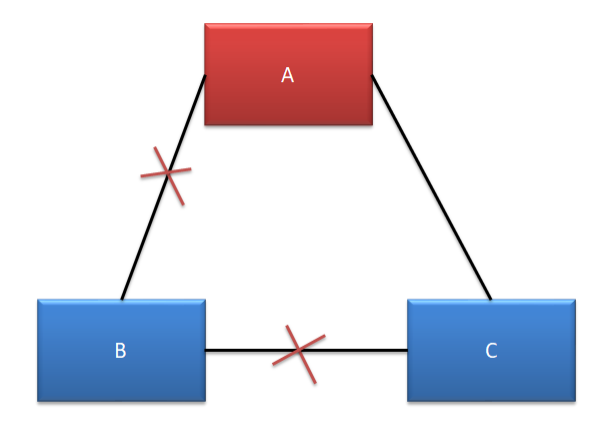
A、C 可以正常对外提供服务,但 B 无法选举出新的 Leader。由于 B 中的主机全部变为了选举状态,所以无法提供任何服务,没有形成脑裂。
-
情况四 无脑裂
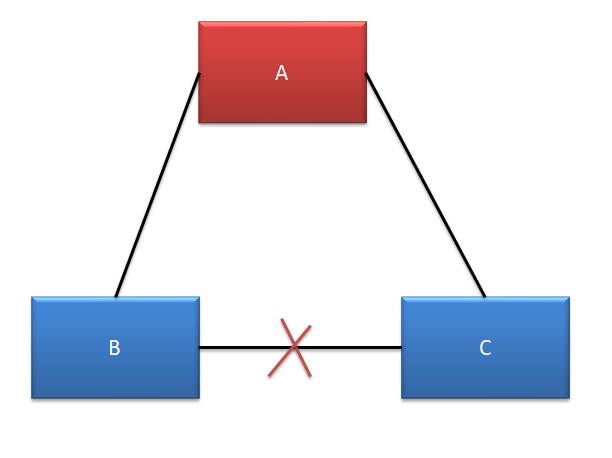
A、B、C 均可以对外提供服务,不受影响。
-
情况五 无脑裂
A 机房无法处理写操作请求,但可以对外提供读服务。B、C 机房由于失去了 Leader,均会发起选举,但由于均无法获取过半支持,所以均无法选举出新的 Leader。
12.11.6 Leader 宕机处理
-
请求到达前 Leader 挂了
client 发送写操作请求到达 Leader 之前 Leader 就挂了,因为请求还没有到达集群,所以这个请求对于集群来说就没有存在过,对集群数据的一致性没有任何影响。Leader 挂了之后,会选举产生新的 Leader。
由于 Stale Leader 并未向 client 发送成功处理响应,所以 client 会重新发送该写操作请求。
-
未开始同步数据前 Leader 挂了
client 发送写操作请求给 Leader,请求到达 Leader 后,Leader 还没有开始向 Followers发出数据 Leader 就挂了。这时集群会选举产生新的 Leader。Stale Leader 重启后会作为Follower 重新加入集群,并同步新 Leader 中的数据以保证数据一致性。之前接收到 client 的数据被丢弃。
由于 Stale Leader 并未向 client 发送成功处理响应,所以 client 会重新发送该写操作请求
-
同步完部分后Leader挂了
client 发送写操作请求给 Leader,Leader 接收完数据后向所有 Follower 发送数据。在部分 Follower 接收到数据后 Leader 挂了。由于 Leader 挂了,就会发起新的 Leader 选举。
- 若 Leader 产生于已完成数据接收的 Follower,其会继续将前面接收到的写操作请求转换为日志,并写入到本地状态机,并向所有 Flollower 发出询问。在获取过半同意响应后会向所有 Followers 发送 commit 指令,同时向 client 进行响应。
- 若 Leader 产生于尚未完成数据接收的 Follower,那么原来已完成接收的 Follower 则会放弃曾接收到的数据。由于 client 没有接收到响应,所以 client 会重新发送该写操作请求
-
commit 通知发出后 Leader 挂了
client 发送写操作请求给 Leader,Leader 也成功向所有 Followers 发出的 commit 指令,并向 client 发出响应后,Leader 挂了。由于 Stale Leader 已经向 client 发送成功接收响应,且 commit 通知已经发出,说明这个写操作请求已经被 server 成功处理。
12.11.7 Raft 算法动画演示
在网络上有一个关于 Raft 算法的动画,其非常清晰全面地演示了 Raft 算法的工作原理。该动画的地址为:http://thesecretlivesofdata.com/raft/
12.12 swarm 部署自定义程序
单机模式下,可以使用 Docker Compose 来编排多个服务。Docker Swarm 只能实现对单个服务的简单部署。而Docker Stack 只需对已有的 docker-compose.yml 配置文件稍加改造就可以完成 Docker 集群环境下的多服务编排。
stack是一组共享依赖,可以被编排并具备扩展能力的关联service。
Docker Stack和Docker Compose区别
- Docker stack 会忽略了“构建”指令,无法使用 stack 命令构建新镜像,它是需要镜像是预先已经构建好的。 所以 docker-compose 更适合于开发场景;
- Docker Compose 是一个 Python 项目,在内部,它使用 Docker API 规范来操作容器。所以需要安装 Docker -compose,以便与 Docker 一起在计算机上使用;Docker Stack 功能包含在 Docker 引擎中。你不需要安装额外的包来使用它,docker stacks 只是 swarm mode 的一部分。
- Docker stack 不支持基于第2版写的 docker-compose.yml ,也就是 version 版本至少为3。然而 Docker Compose 对版本为2和 3 的文件仍然可以处理;
docker stack 把 docker compose 的所有工作都做完了,因此 docker stack 将占主导地位。 - 单机模式(Docker Compose)是一台主机上运行多个容器,每个容器单独提供服务;集群模式(swarm + stack)是多台机器组成一个集群,多个容器一起提供同一个服务;
注意:docker-compose.yml文件中,version版本3.5开始引入的deploy属性
12.12.1 compose.yml deploy 配置说明
docker stack deploy 不支持的参数:(这些参数,就算yaml中包含,在stack的时候也会被忽略,当然也可以为了 docker-compose up 留着这些配置)
build
cgroup_parent
container_name
devices
tmpfs
external_links
links
network_mode
restart
security_opt
userns_mode
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
之前使用的docker-compse形式,部署了自定义的服务,现在想使用docker swarm形式进行部署,在Docker Swarm模式下,deploy属性用于指定服务的部署策略和运行时配置。它允许你控制服务的规模、更新策略、重启策略、资源限制、网络策略等。以下是deploy属性中各项的详细解释:
-
**mode: **定义了服务的部署模式。在Swarm中,有两种模式:
replicated: 指定固定数量的副本,这是默认值。
global: 在集群中的每一个节点上运行一个服务实例。
-
replicas: 当mode设置为replicated时,此属性定义了服务的副本数。例如,replicas: 1意味着在整个集群中只运行一个服务实例。
-
**endpoint_mode: **指定服务的端点模式,决定了如何处理服务的网络端点。有三种模式:
- vip (Virtual IP):
描述:这是默认模式。在Swarm集群中,Docker会在Ingress网络上为服务分配一个虚拟IP地址(VIP)。所有的服务实例都会通过这个VIP进行负载均衡。
优点:提供了服务发现和负载均衡的能力,使得外部流量可以均匀地分布到服务的所有实例上。
适用场景:适用于需要负载均衡和高可用性的服务。 - dnsrr (DNS Round Robin):
描述:在这种模式下,Docker会为服务的每个实例分配一个DNS记录,使用DNS轮询(Round Robin)算法返回这些记录。客户端每次查询DNS时,都会得到一个不同的服务实例地址。
优点:简化了服务实例的管理,因为每个实例都有一个固定的网络标识。
适用场景:适用于无状态服务,其中每个服务实例都可以独立处理请求,不需要共享状态。 - none:
描述:禁用了服务端点的自动暴露。这意味着服务不会自动创建任何端点,外部流量无法直接通过网络访问服务实例。
优点:提供了更细粒度的网络控制,可以手动配置网络规则或使用其他手段来访问服务。
适用场景:适用于内部服务,即那些仅用于服务间通信而不是公开访问的服务。
- vip (Virtual IP):
-
**placement: **
在Docker Swarm中,placement属性用于控制服务实例在集群中的放置策略,它允许你根据各种条件约束服务实例的部署位置。placement主要由两部分组成:constraints和preferences。
- constraints:
constraints是一系列布尔表达式,用于限定服务实例可以在哪些节点上运行。它们可以基于节点的属性、标签或状态来定义。常见的约束条件包括:- 节点属性:比如node.role == manager表示服务实例只能在管理节点上运行。
- 节点标签:如node.labels.env == production表示服务实例只能在标记为生产环境的节点上运行。
- 节点状态:例如node.platform.os == linux表示服务实例只能在Linux节点上运行。
- 节点的 hostname:例如node.hostname == node1表示服务实例只能在名为node1的节点上运行。
- 约束条件可以组合使用,以实现更复杂的放置逻辑。例如,你可以同时要求服务实例在标记为生产环境的管理节点上运行。
- preferences:
preferences是Swarm 1.13版本引入的一个特性,它允许你指定服务实例的放置偏好,但不强制执行。与constraints不同,preferences不会阻止服务实例的部署,而是作为调度器的参考,以尽量满足这些偏好。
- constraints:
-
restart_policy:
定义了当服务实例退出时的重启策略。condition可以是none、on-failure、any或none。例如,condition: any意味着无论服务实例为何种原因退出都会重启。
-
resources: 用于限制服务实例使用的资源,如CPU和内存。
12.12.2 新生成complose.yml
# version必须大于等于3.5 version: '3.5' services: app: image: cus_app:1.0 ports: - 9000:8088 volumes: - ./logs:/var/applogs networks: - net-test deploy: # 复制策略 mode: replicated # 创建docker容器数量 replicas: 5 # 容器内部的服务端口映射到VIP endpoint_mode: vip #容器重启策略 restart_policy: condition: any depends_on: - mysql - redis mysql: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: 101022 ports: - 3306:3306 volumes: - /root/mysql/log:/var/log/mysql - /root/mysql/data:/var/log/mysql - /root/mysql/conf:/etc/mysql/conf.d networks: - net-test deploy: # 复制策略 mode: replicated # 创建docker容器数量 replicas: 1 # 容器内部的服务端口映射到VIP endpoint_mode: vip placement: # 约束条件,只有主机名为server155时才生效 constraints: - "node.Hostname == docker1" #容器重启策略 restart_policy: condition: any #由docker创建一个新的网络 networks: net-test: driver: overlay

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
12.12.3 启动服务
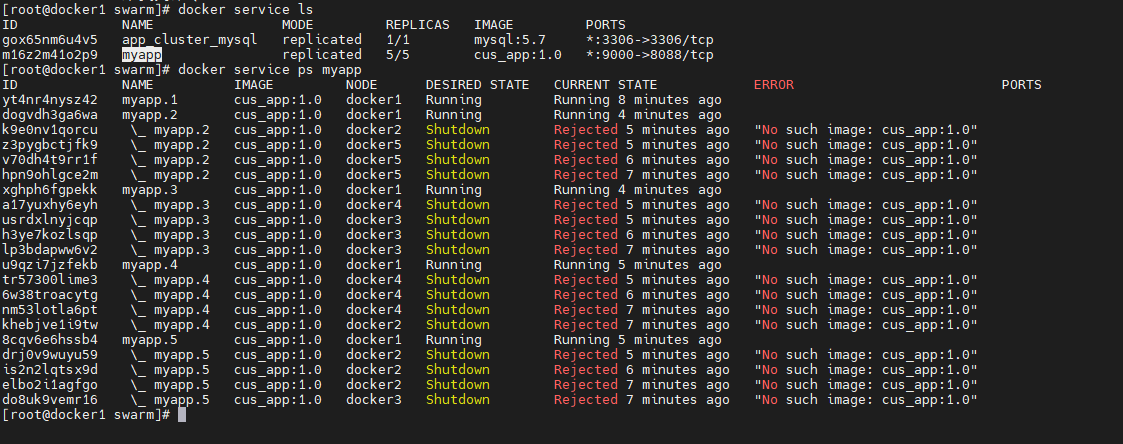
# 通过docker swarm启动服务命令
docker stack deploy --compose-file compose.yml app_cluster
- 1
- 2