
- 1Linux音频相关学习资料汇总(持续更新...)_pulseaudio
- 2redis的搭建及应用(六)-redis应用LUA脚本_lua redis
- 32024年GitHub-上那些优秀Android开源库,这里是Top10!_github android
- 4hive-窗口函数入门到精通_hive窗口函数入门到精通
- 5防火墙 ---iptables_reject-with icmp-port-unreachable
- 6ShardingSphere自定义分布式主键生成策略、自定义分片规则
- 7RabbitMQ通信方式之RPC_rabbitmq rpc
- 8CSPM可以自学吗?小白须知
- 9深度优先算法和广度优先算法(python)_广度优先法 记录open表和close表 python
- 10大数据时代的 9 大Key-Value存储数据库_键值数据库有哪些
一文读懂20多种AI大模型RAG优化方法
赞
踩
大规模语言模型(LLMs)已经融入了我们的日常生活和工作中,它们以卓越的多功能性和智能化改变了我们与信息互动的方式。
尽管LLMs的能力令人赞叹,但它们并非完美无缺。这些模型可能会产生误导性的“幻觉”,依赖的信息可能已过时,处理特定知识时效率不高,缺乏对专业领域的深入理解,同时在推理方面也存在不足。
在实际应用中,数据需要持续更新以反映最新发展,生成的内容必须是透明和可追溯的,以控制成本并保护数据隐私。因此,单纯依赖这些“黑盒”模型是不够的,我们需要更精细的解决方案来应对这些复杂需求。正是在这种背景下,检索增强生成技术(Retrieval-Augmented Generation,RAG)应运而生,成为LLM时代的一个主要趋势。
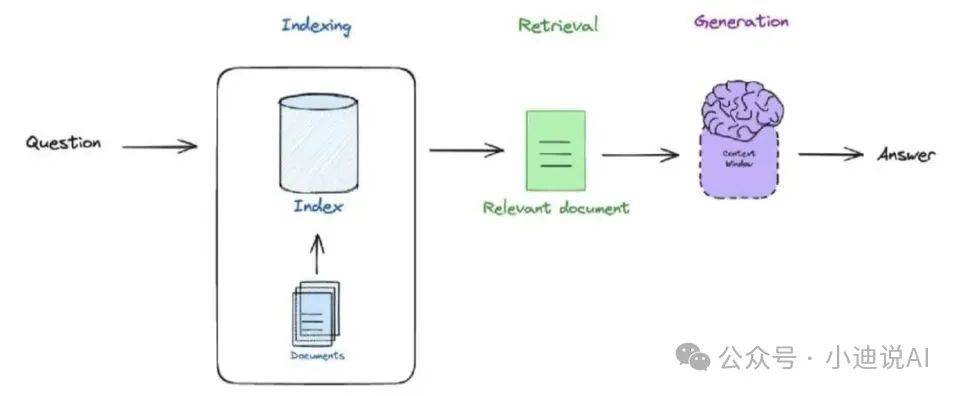
基础RAG架构的流程非常简单,其最大的特点是数据的单向流通。虽然构建这样一个系统相对快速,但要真正投入生产环境使用还有很长的路要走。为了提高原有架构的文档召回率和系统鲁棒性,优化路径主要有两个方向:一是增加召回管道,二是增加反馈机制。增加召回管道包括查询变换(子查询、rag-fusion)、混合检索等方法,通过多路召回来最大化召回率;增加反馈机制则包括rerank、后退提示、self-rag等方法,基于原始结果进行优化以提高准确率。
通过这两种路径,RAG架构的数据和信息不再是单向流通,而是变得多向且并行。
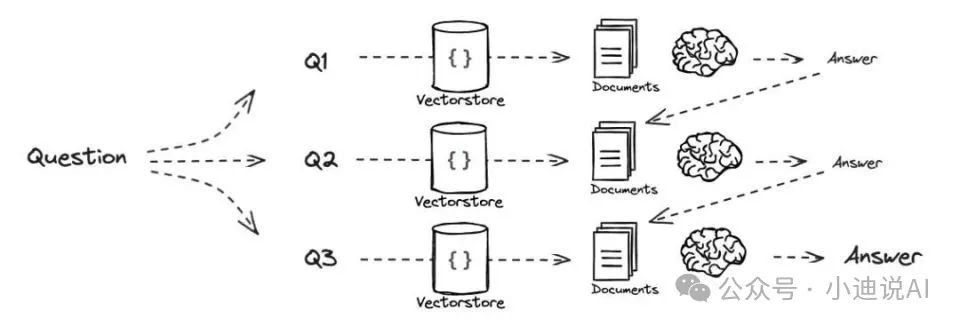
本文将按照数据流动的方向,从文本预处理、文本分块、嵌入、检索和生成等环节,依次介绍各个优化方法。
01 文本数据预处理
无论RAG系统结构多么复杂,由于其数据驱动的特性,高信噪比的数据始终至关重要。在检索之前对原始数据进行优化,包括以下方法:
1.实体解析:消除实体和术语的歧义,实现一致的引用。例如,将“LLM”、“大语言模型”和“大模型”统一为通用术语。
2. 文档划分:合理划分不同主题的文档,确保检索系统能够轻松判断查阅哪个文档以回答问题。
3. 数据增强:使用同义词、释义或不同语言的翻译来增加知识库的多样性。
4. 处理特殊数据:例如,对于经常更新的主题,实施机制来使过时的文档失效或更新。
5.增加元数据:增加内容摘要、时间戳、用户可能提出的问题等附加信息,丰富知识库。
02 文本分块
由于检索知识库中的数据量通常超过LLM的输入长度限制,合理的分块(Chunking)应确保块之间的差异性和块内部的一致性。以下是一些高级的分块方法:
1. 句分割:使用NLTK或spaCy库提供的句子分割功能。
2. 递归分割:通过重复应用分块规则来递归分解文本,灵活调整块的大小。
3. 语义分割:通过计算文本的向量相似度进行语义层面的分割。
4. 特殊结构分割:针对特定结构化内容的专门分割器,确保正确保留文档结构。
分块大小也是重要因素,需要根据文档类型、用户查询的长度及复杂性来决定。实际应用中,可能需要不断实验调整,128大小的分块往往是一个不错的起点。
03 嵌入
数据处理的最后一个环节是使用嵌入(Embedding)模型对文本数据进行向量化,以便在检索阶段使用向量检索。嵌入阶段的优化点包括:
1. 使用动态嵌入:动态嵌入能够处理一词多义的情况,如BERT模型可以根据上下文动态调整词义。
2. 微调嵌入:对嵌入模型进行微调,以更好地理解垂直领域的词汇。
3. 混合嵌入:对用户问题和知识库文本使用不同的嵌入模型。
04 查询优化
在实际环境中,用户的表述可能多样或模糊,导致检索阶段召回率和准确率较低。以下是一些查询优化方法:
1. 查询重写:通过LLM或问题重写器对用户问题进行改写。
2. 后退提示:提出一个抽象通用问题,与原始问题一起进行检索。
3. Follow Up Questions:使用LLM生成独立问题,针对历史对话和当前问题。
4. HyDE:用LLM生成一个假设答案,与问题一起进行检索。
5. 多问题查询:基于原始问题生成多个新问题或子问题,并使用每个新问题进行检索。
05 检索
检索的目标是获取最相关的文档或确保最相关文档在获取的文档列表中。以下是一些检索优化方法:
1. 上下文压缩:通过LLM帮助压缩文档内容或过滤返回结果。
2. 句子窗口搜索:将文档块周围的块作为上下文一并交给LLM。
3. 父文档搜索:将文档分为主文档和子文档,用户问题与子文档匹配,然后将主文档发送给LLM。
4. 自动合并:对文档进行结构切割,检索时只匹配叶子节点,如果多数叶子节点匹配问题,则返回父节点。
5. 混合检索:混合多个检索方法以最大化事实召回率。
6. 路由机制:选择最合适的索引进行数据检索。
7. 使用Agent:使用Agent决定采用何种检索方法。
06 检索后处理
检索后处理是对检索结果进行进一步处理,以便后续LLM更好地生成。典型的方法是重排序(Rerank),使用专门的重排序模型确保最相关的文档排在结果列表的最前面。
07 生成
生成阶段的优化主要考虑用户体验,包括:
1. 多轮对话:支持连续对话以深入了解解决问题。
2. 增加追问机制:在prompt中加入追问机制,根据背景知识内容对用户进行追问。
3. prompt优化:明确指出回答仅基于搜索结果,不要添加其他信息。
4. 用户反馈循环:基于用户反馈不断更新数据库,标记真实性。
08 结语
这些方法针对基础RAG在各个环节的优化,实际开发中需要根据应用场景选择合适的优化方法组合,以最大限度发挥RAG的作用。

