
- 1iconfont字体图标和各种CSS小图标
- 2pythondcnda算法聚类_ML-hand/5kmeans聚类.ipynb at master · Briareox/ML-hand · GitHub
- 3unity 3D模型展示旋转缩放_unity 模型旋转
- 4CFAR原理详解及其matlab代码实现
- 5OpenCV4.5 dnn模块+QT5.12.9实现人脸识别Demo_cv::facedetectoryn::create
- 6antd源码-form解析(初始化到表单收集校验过程)_antd validatemessages
- 7互动照片墙效果之扩散效果(一)_unity ui 扩散效果
- 8echarts实现3d环形饼状图_echart 3d饼状图
- 9ant-design-vue切换主题+换肤+自定义换肤+less动态换肤_ant-design-vue 在线换肤
- 10vue 循环数组使用el-input,输入一次以后光标不见了,无法输入第二次_el-input数组
多层感知机:Multi-Layer Perceptron
赞
踩
多层感知机:MLP
多层感知机由感知机推广而来,最主要的特点是有多个神经元层,因此也叫深度神经网络(DNN: Deep Neural Networks)。
感知机:PLA
多层感知机是由感知机推广而来,感知机学习算法(PLA: Perceptron Learning Algorithm)用神经元的结构进行描述的话就是一个单独的。
感知机的神经网络表示如下:
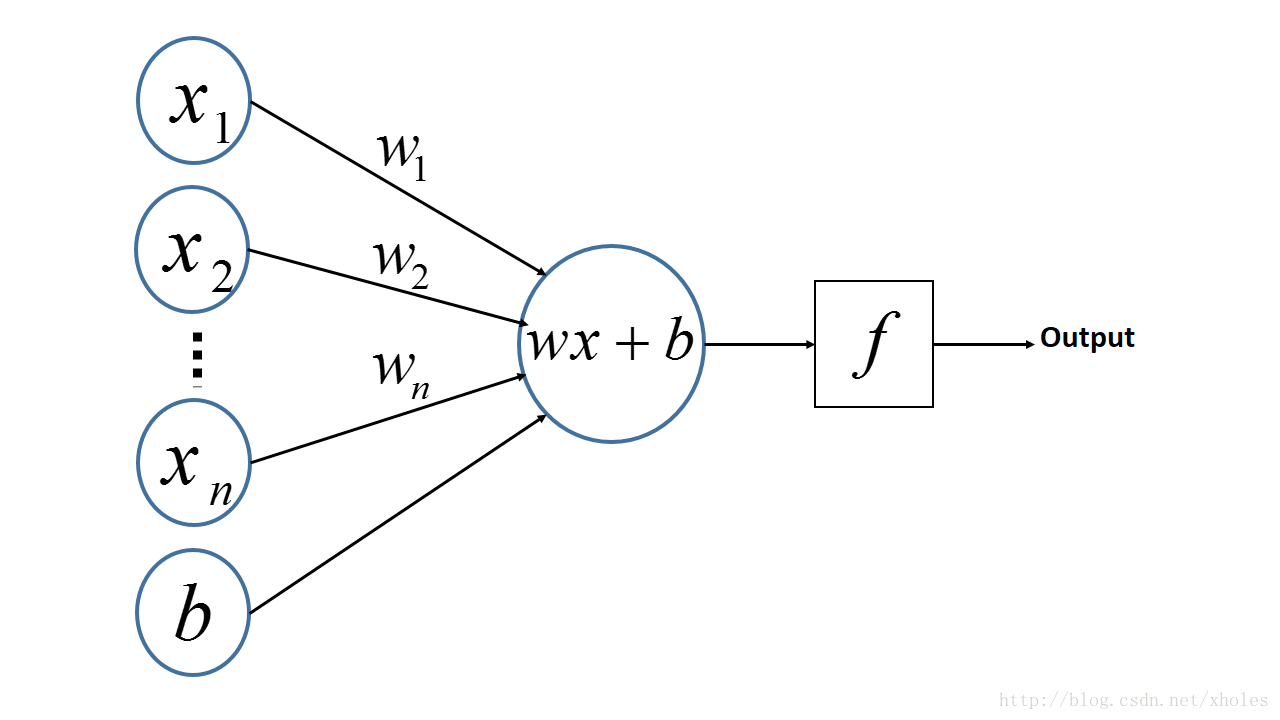
从上述内容更可以看出,PLA是一个线性的二分类器,但不能对非线性的数据并不能进行有效的分类。因此便有了对网络层次的加深,理论上,多层网络可以模拟任何复杂的函数。
多层感知机:MLP
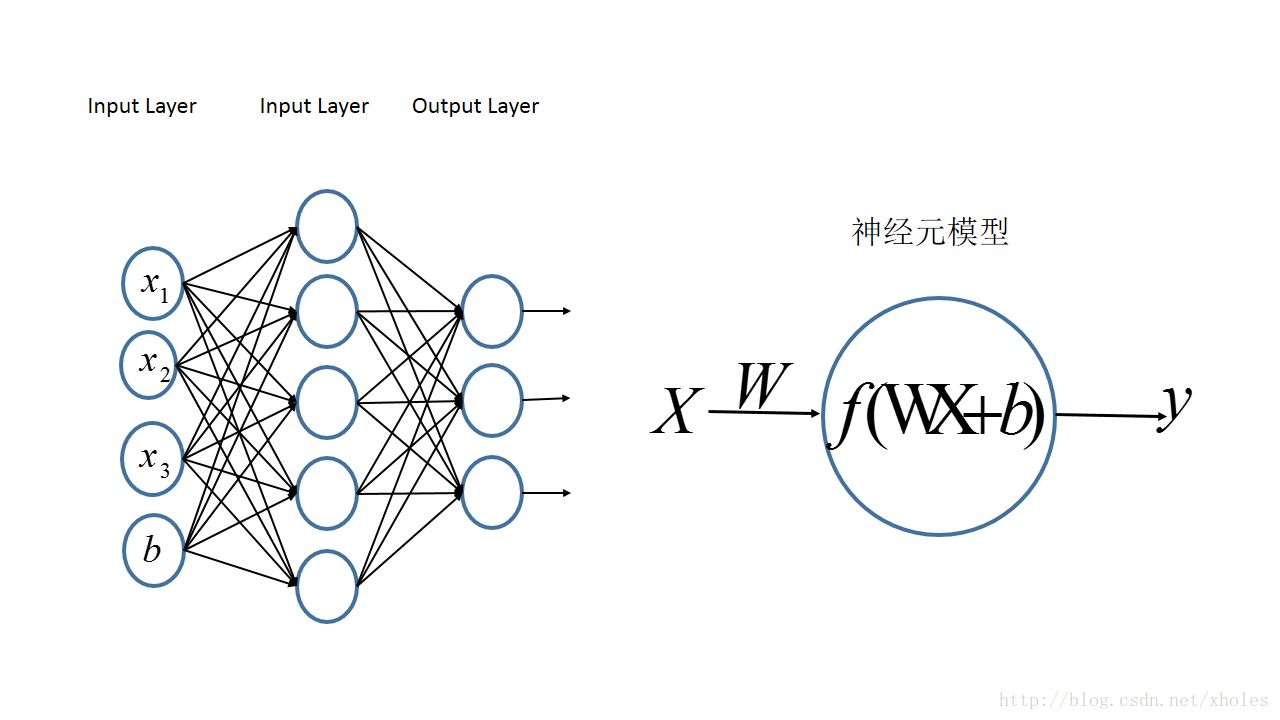
多层感知机的一个重要特点就是多层,我们将第一层称之为输入层,最后一层称之有输出层,中间的层称之为隐层。MLP并没有规定隐层的数量,因此可以根据各自的需求选择合适的隐层层数。且对于输出层神经元的个数也没有限制。
MLP神经网络结构模型如下,本文中只涉及了一个隐层,输入只有三个变量
前向传播
前向传播指的是信息从第一层逐渐地向高层进行传递的过程。以下图为例来进行前向传播的过程的分析。
假设第一层为输入层,输入的信息为
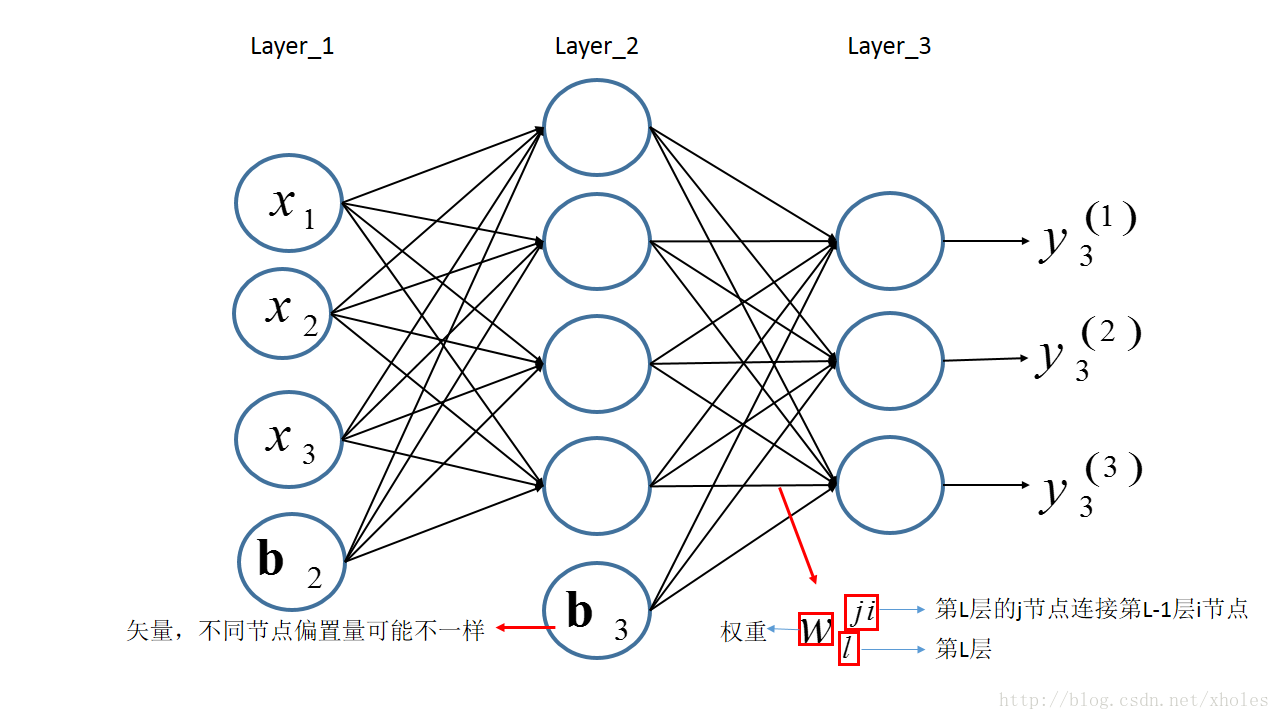
结合之前定义的字母标记,对于第二层的三个神经元的输出则有:
将上述的式子转换为矩阵表达式:
将第二层的前向传播计算过程推广到网络中的任意一层,则:
反向传播
基本的模型搭建完成后的,训练的时候所做的就是完成模型参数的更新。由于存在多层的网络结构,因此无法直接对中间的隐层利用损失来进行参数更新,但可以利用损失从顶层到底层的反向传播来进行参数的估计。(约定:小写字母—标量,加粗小写字母—向量,大写字母—矩阵)
假设多层感知机用于分类,在输出层有多个神经元,每个神经元对应一个标签。输入样本为
对于层
对于网络的最后一层第
为了极小化损失函数,通过梯度下降来进行推导:
在上式子中,根据之前的定义,很容易得到:
那么则有:
另有,下一层所有结点的输入都与前一层的每个结点输出有关,因此损失函数可以认为是下一层的每个神经元结点输入的函数。那么:
此处定义节点的灵敏度为误差对输入的变化率,即:
那么第
结合灵敏度的定义,则有:
上式两边同时乘上
注意到上式中表达的是前后两层的灵敏度关系,而对于最后一层,也就是输出层来说,并不存在后续的一层,因此并不满足上式。但输出层的输出是直接和误差联系的,因此可以用损失函数的定义来直接求取偏导数。那么:
至此,损失函数对各参数的梯度为:
上述的推到都是建立在单个节点的基础上,对于各层所有节点,采用矩阵的方式表示,则上述公式可以写成:
其中运算符
常见的几个激活函数的导数为:
根据上述公式,可以得到各层参数的更新公式为:
References:

