
- 1操作系统进程实验课程设计_试编制一个程序段, 完成下图所示流程图的功能。
- 2python中npy转txt文件(科学计数法/十进制类型)_npy文件
- 3详解进程虚拟地址空间区域划分_进程地址空间怎么识别地址是什么区的
- 4DNS学习总结_dns服务器配置实验心得
- 5Multi-Video Temporal Synchronization论文笔记_multi-camera spatio-temporal synchronization
- 6MYSQL每日一用:SELECT 语句中比对(between and \ like \ left)
- 7es6标准下ajax类封装及使用_使用es6class封装ajax类
- 8【jellyfin】解决使用自定义域名和免费ssl证书安卓端无法访问服务器的问题_jellyfin绑定域名
- 9Ubuntu 安装pytorch指定版本_ubuntu torch==2.1.2 安装制定版本
- 10CentOS停服遭替代,这些操作差异,你了解了吗?_centos7.9 替代
2023 英特尔On技术创新大会直播 | 用AI丈量世界之我见
赞
踩
一、简介

英特尔On技术创新峰会是开发者优先的全球年度盛会,是一个由开发者组织,为开发者举办的盛会。英特尔On技术创新大会是由英特尔公司举办的一年一度的盛大活动,旨在展示和探讨最新的科技创新和发展趋势。该大会汇集了来自全球各行业的顶尖科技专家、创新者和业界领袖,开发人员和技术精英可以分享有关先进技术、开放式生态系统资源、创新计算解决方案、动手实验和教程、交流沟通和社区建设的最新信息,并在这些方面开展协作、实现发展。在大会上,参与者可以通过主题演讲、研讨会、展览和互动体验等形式,深入了解英特尔最新的技术创新和产品发展,探讨行业未来的发展方向和机遇。
二、大会安排
你现在是不是对技术创新大会充满好奇了呢?2023英特尔On技术创新大会已经来了!大会通过线上活动邀请你一起探索最前沿的科技世界!大会通过2场主题演讲、5大技术洞察、19堂专题课程,深度讲解最新一代增强AI能力的计算平台如何支持开放、多架构的软件方案,塑造未来的技术和应用创新。
大会时间:12月19日-12月20日
会参方式:通过网上报名,线上参与的方式进行,大会地址:英特尔On技术创新大会 (intel.cn)
会议安排:大会安排了2个主题演讲,5大技术洞察和19个专题论坛,从云到端,全面赋能AI开发,干货满满,不容错过。
2场主题演讲

主题:芯生无限 赋能 AI 创新: 英特尔公司首席执行官帕特·基辛格,英特尔公司高级副总裁、英特尔中国区董事长王锐博士,英特尔公司副总裁、英特尔中国软件生态事业部总经理李映博士分别就“芯生无限,赋能 AI 创新”作了主题演讲,王锐博士详细地介绍了“芯经济”的光明前景,英特尔在AI、数据中心、软件生态、制程等各个方面的工作情况,让我们能够从英特尔中国区“掌门人”的角度来了解英特尔的发展动向,以及对未来的看法。
主题:助力开发者 让 AI 无处不在: 英特尔公司首席执行官帕特·基辛格(Pat Gelsinger)就“助力开发者,让 AI 无处不在”作了主题演讲,他表示:“AI代表着新时代的到来。AI正在催生全球增长的新时代,在新时代中,算力起着更为重要的作用,让所有人迎来更美好的未来。对开发者而言,这将带来巨大的社会和商业机遇,以创造更多可能,为世界上的重大挑战打造解决方案,并造福地球上每一个人。”
5大技术洞察
主题:人工智能生产力和性能的新范式: 英特尔戴金权院士分享了高效解决行业挑战的变革性解决方案,一起探讨富有价值的平台、可移植的端到端软件工具和优化方案,以及能为 AI 加速的处理器和系统产品组合。
主题:新一代 AI PC 计算平台,全面重塑 PC 应用体验: 特尔客户端计算客户工程部高级首席工程师刘骏英分享 Meteorlake 的平台优势和我们的系统级技术方法,为大家讲解该方法如何确保软件与硬件无缝协作,使开发更高效、定制更灵活。
主题:新一代至强为云与人工智能构筑安全高效、广泛可用的算力基石: 英特尔数据中心平台工程与 AI 事业部首席工程师李志明分享针对下一代数据中心系统和平台的技术见解,深入探讨英特尔性能核(P-core)和能效核(E-core)的产品路线,介绍能够提供高性能和高能效的第五代英特尔 至强 可扩展处理器,以及如何通过机密计算在确保数据安全的基础上提供广泛可用的高能效计算能力。
主题:混合 AI: 边云协同加速 AI 解决方案商业化落地: 英特尔高级首席 AI 工程师 英特尔网络与边缘事业部中国区首席技术官 张宇博士分享英特尔对边缘人工智能发展趋势的判断,以及面向边缘人工智能的硬件与软件的新创新。
主题:计算创新演进,探索智能未来: 英特尔研究院副总裁 英特尔中国研究院院长宋继强分享了英特尔提出的五大超级技术力量(无所不在的计算,无处不在的连接,传感与感知,从云到边缘的基础设施和人工智能)并围绕这五大技术作了详细汇报。
19场专题论坛
专题论坛包含人工智能,新一代AI PC 计算平台,新一代至强平台,边云协同和先进技术这五个领域,分别就生成式人工智能技术及发展前景,各个场景下的加速推理,应用开放框架的优化与工具,在边缘侧革新传统应用及运营,赋能软件定义的边缘到云基础设施,新一代计算平台的软件开发,前沿创新洞察这些专题作了详细的分享。其中关于使用 OpenVINO™ 落地边缘端生成式 AI,打造自己的聊天机器人,打造 AI PC 生态系统,新一代 AI PC 计算平台,全面重塑 PC 应用体验,混合 AI: 边云协同加速 AI 解决方案商业化落地我进行了详细的学习,感受颇多,受益匪浅,欢迎大家也去学习,同时支持大家同我沟通分享,不吝赐教。
二、四大看点
1.全面拥抱人工智能

英特尔AI软件解决方案工程师张建宇在 “ 使用 Intel 优化的 AI 框架 释放Intel XPU 的动能,加速 AI ”专题论坛中详细的介绍了英特尔关于人工智能落地的解决方案,其中提到用户可以在英特尔平台(包括客户端、边缘计算和数据中心)上,可以针对不同业务场景,选用各种英特尔 CPU、GPU 和 NPU 等深度学习计算引擎,配以 OpenVINO , IPEX, ITEX, ITREX, BigDL-LLM, SynapseAI, Optimum 等开发及优化工具链,加速生成式人工智能的持续调参优化和快速部署,让开发者能够灵活便捷地开发和交付面向消费者和企业级的 LLM/AIGC 业务软件,他分别从Intel oneAPI Power AI, Intel 优化框架,AI 参考套件,真实使用案例四个维度对基于英特尔平台,打造AI生态的过程进行了详细说明。
Intel oneAPI
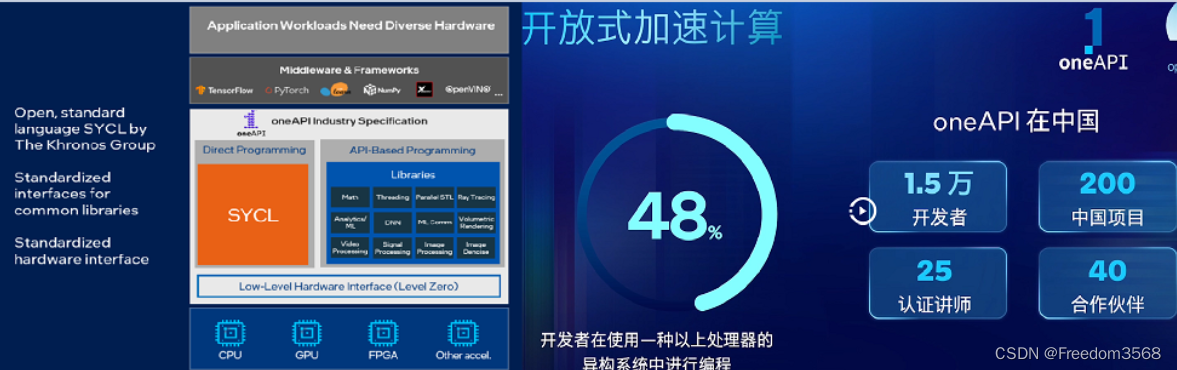
Intel oneAPI 是一个跨行业、开放、基于标准的统一的编程模型,旨在提供一个适用于各类计算架构的统一编程模型和应用程序接口。也就是说,应用程序的开发者只需要开发一次代码,就可以让代码在跨平台的异构系统上执行,底层的硬件架构可以是CPU、GPU、FPGA、神经网络处理器,或者其他针对不同应用的硬件加速器等等,同时加速繁重的计算工作负载,提供了一个高性能、高保真度、可拓展、性价比高的平台,将渲染能力提升至新的台阶。英特尔 oneAPI 提供了大量并且非常高质量的开发工具,英特尔新的开发人员生态系统,它既可以提高开发效率,又可以具有一定的性能可移植性。
AI参考套件:
AI参考套件是英特尔和埃森哲(Accenture)合作推出的 34 个开源 AI 参考套件,旨在简化和加快数据科学家和开发人员部署 AI 的过程。每套开源 AI 参考套件均包含模型代码、训练数据、设置机器学习管道的说明、库和 oneAPI 组件等,无论是在本地、云还是边缘计算,都可以优化 AI,提高易用性。这些开源 AI 参考套件可以满足消费品、能源、公用事业、金融服务、健康和生命科学、制造业、零售业、电信业等各个行业需求,让企业可以在采用不同架构的本地、云端和边缘环境下灵活应用。AI参考套件为数百万开发者和数据科学家在健康和生命科学、金融服务、制造业、零售业等诸多领域开发和扩展AI应用,提供了简便、高效且经济实惠的方式。
AI参考套件可以将解决方案的时间从数周缩短到数天,帮助数据科学家和开发者以更快的速度和更低的成本进行模型训练,克服专有环境的限制。在oneAPI驱动下,AI工具和优化能够更大限度地提高开放式加速计算应用的可移植性。
2.新一代 AI PC 计算平台

在PC 计算平台上开发 AI 应用需要强大的硬件性能、优化的能耗、先进的工具和开放的生态系统。英特尔致力于通过广泛的产品组合:基于AI加速的处理器和系统,加以对开放AI软件生态的投入,推动构建一个让AI触手可及的未来。在这里我们可以了解到英特尔新一代 AI PC 硬件平台(如英特尔 酷睿 Ultra 处理器和英特尔锐炫 显卡)及其出色的连接性如何助力您更轻松地进行 AI 应用开发和游戏开发,展示了英特尔开放的软硬件生态系统(如 OpenVINO™ 和 OneAPI)和与合作伙伴推出的最新解决方案。
英特尔 酷睿 Ultra 处理器:

英特尔 酷睿 Ultra 处理器是英特尔正式推出第五代英特尔至强可扩展处理器(代号 Emerald Rapids),在提高人工智能、科学计算、网络、存储、数据库、安全等关键工作负载性能,以及降低总体拥有成本方面有出色表现,旨在为在云、网络和边缘环境中部署人工智能的客户提供更高的性能。第五代英特尔至强可扩展处理器每个内核均具备 AI 加速功能,无需添加独立加速器,即可处理要求严苛的端到端AI工作负载,其中包括可将参数量多达200亿的大语言模型的推理性能提高42%,延迟低于100毫秒。
英特尔锐炫:

有句话叫做:从无到有,从有到优,从优到精。如果说2022年10月份英特尔推出锐炫A770、锐炫A750这两款台式机显卡,实现从无到有,向世人展现了英特尔进军高性能显卡领域的鸿鹄之志,那么在2023年一整年沉下心来打磨驱动,则是英特尔高性能显卡从有到优的实力沉积。
英特尔锐炫是英特尔自己的全新高性能显卡品牌。英特尔锐炫专为消费端打造,涵盖硬件、软件和服务三方面。其硬件产品将涉及多代,不仅包括首代基于 Xe HPG 微架构的 Alchemist 显卡(DG2),还将包括代号分别为 Battlemage、Celestial 和 Druid 的后续几代产品。英特尔锐炫显卡基于 Xe HPG 微架构所打造,融合了英特尔 Xe LP、HP 和 HPC 微架构的优势,将通过高级的显卡功能,提供出色的可扩展性和计算效率。代号为 Alchemist 的第一代英特尔锐炫™️ 高性能显卡产品将采用基于硬件的光线追踪和人工智能驱动的超级采样,为 DirectX 12 Ultimate 提供全面支持。
-
高级 Xe 媒体引擎:带有专门 AI 加速、宽编解码器支持和超快速媒体性能功能的超级媒体引擎让您超越创作的边界。得益于 Xe 媒体引擎,全球首款支持 AV1 编码和强大媒体加速的电脑让您跨入下一代内容创作。凭借英特尔锐炫™ 显卡现在即可构建未来的内容,执行最高需求的创作工作流程。
-
AV1:视频的未来:英特尔锐炫是全球首款对于 AV1、下一代和免版税视频编解码器具有硬件加速编码功能的 GPU。随着最大的在线视频平台采用 AV1 作为视频的未来,已准备好创建、直播、分享和消费高质量的 AV1 内容,分辨率高达 8K,性能和能效均达到全新水平。
-
游戏优化:对于游戏优化,英特尔锐炫显卡堪称全方位的。特别是在DX9、DX11等较老的游戏当中,英特尔锐炫显卡团队进行性能优化堪称“恶补”。
-
XMX 加速创作:AI 实现更智能的创作: 利用英特尔锐炫™ 显卡内置的强大 XMX AI 功能,快速、轻松地提升和修饰照片和视频,在 AI 加速的创作任务中发挥出最佳效果。把您的设计能力提高到一个新的水平 – 让 AI 来处理那些细微的、费力的和耗时的任务,而您则专注于大局。利用 Deep Link 超级计算功能,通过智能地利用多个计算引擎,甚至是英特尔® 锐炫™ + 英特尔® 酷睿™ 系统上的人工智能功能,加速视频和图像工作流程。
3.新一代至强平台

云计算和大模型时代浪潮正在革命性地重新定义云计算,全新一代英特尔至强可扩展处理器应运而生。其内置的英特尔 AMX 加速引擎为 AI 带来极致加速性能表现,其他众多内置加速器 (QAT, IAA, DSA, DLB) 可对各个云业务进行加速和性能优化;同时,在英特尔 SGX、英特尔 TDX “双保险” 的加持下,安全的运行环境能为业务保驾护航;英特尔还具备丰富的全栈软件优化 (Kernel, Hypervisor, AI FW and lib[oneDNN], IPEX 等),赋能各个云软件,充分释放至强潜能, 软硬协同加速云计算及 AI 创新。

第五代至强可扩展处理器通过架构增强,实现了算力的全面优化。较上一代产品,第五代至强在相同 TDP 下平均性能提升高达21%,内存带宽提升高达 16%,三级缓存容量提升近 3倍,能够为AI训练和推理提供更高的支持,AI推理性能提升高达 42%,且更适用于大型模型。在相同热设计功耗范围内提供更高的算力和更快的内存,整体性能提升21%,每瓦性能提升36%。同时,该处理器与上一代产品的软件和平台兼容,使客户能够升级并大幅增加基础设施的使用寿命,同时降低成本和碳排放。为AI加速而生的第五代英特尔至强可扩展处理器,在图像分类性能提升高达42%,在(边缘侧)图像分类性能提升高达24%,在建模/仿真工作负载性能提升高达42%,至强处理器旨在为在云、网络和边缘环境中部署人工智能的客户提供更高的性能。

第五代至强专为AI加速而设计,通过增强型架构、内置AI加速技术,实现了卓越的性能,能够帮助用户更高效地应对要求严苛的 AI工作负载,让智能开发及应用无处不在。借助第五代至强,用户无疑可继续使用 CPU 将 AI 应用到各个领域,从而解决GPU挑战,帮助广泛的产业用户将AI融入业务逻辑各环节,并应对部署中可能遭遇的硬件可用性、成本、集成和扩展方面的挑战,实现在通用的服务器基础架构上高效运行AI应用,提升性能成本收益。
4.边云协同

在5G、大数据中心、AI等新基建的带动下,企业的数字化水平、业务的复杂度和专业度都有了显著提升。这让企业在进行云端部署时,对算力优化分配、数据及时性、系统稳定性、以及跨工作场景的灵活性提出了新的要求。因此,边云协同成为未来发展的重要趋势,许多企业开始构建边云协同模式和系统,以协同解决大数据发展下的计算难题。在云原生开发和边缘智能方面处于领先地位的英特尔,协同多年来与创新合作伙伴合作所积累的现代“边云协同”应用程序开发经验、技术、产品和平台,赋能以生成式 AI 大模型为核心的混合式 AI 解决方案,加速其商业化落地。OpenVINO提供好用易用的 AI 模型优化和部署方式,让 AI 模型高效地部署到从边缘到云端的英特尔平台上;边缘安全技术让边云协同的 AI 解决方案更加可靠;英特尔基础架构处理器也在 AI 集群、边缘 AI 等用户场景中提升数据中心性能。

英特尔的云边协同是一种新型的技术架构,旨在实现云端和边缘计算之间的高效协同和无缝连接。该架构将云端和边缘计算资源进行统一管理和调度,实现了数据的快速传输和处理,从而提高了计算效率和数据安全性。云边协同技术的核心是一种分层架构,其中云端和边缘节点通过高速网络进行连接。在该架构中,云端负责对大规模数据的处理和存储,而边缘节点则负责对数据进行实时处理和响应。通过将计算任务分配到最合适的计算节点上,云边协同实现了计算资源的最大化利用和数据的最快传输和响应。
英特尔的云边协同技术已经在各个领域得到了广泛的应用,例如智能制造、智能交通、智慧城市等。该技术可以帮助企业和组织更好地管理和利用数据,提高业务效率和安全性,同时也为人工智能、物联网等新兴技术的发展提供了强有力的支持。
四、全面拥抱AI
1. AI PC时代的到来

随着操作系统与AI应用的逐渐发展,AI能力正在从云端向边缘转移,作为传统个人终端的PC也开始了向AI PC的全面进化。基辛格说:“AI将通过云与PC的紧密协作,进而从根本上改变、重塑和重构PC体验,释放人们的生产力和创造力。我们正迈向AI PC的新时代。” 全新的PC体验,即将在接下来推出的产品代号为Meteor Lake的英特尔酷睿Ultra处理器上得到展现,该处理器配备英特尔首款集成的神经网络处理器(NPU),用于在PC上带来高能效的AI加速和本地推理体验,英特尔酷睿Ultra处理器取代了以往的酷睿i系列,在制程工艺、芯片架构、封装模式等方面做了全面更新。Meteor Lake处理器将采用Intel 4制程节点,在能效比方面有显著提升;其也将是英特尔首个采用Foveros封装技术的消费级芯粒设计芯片,包括计算模块、SoC模块、图形模块、IO模块在内的四个分离式模块像搭积木一样封装在一起。

AI PC将为我们的日常生活和工作带来了许多便利和乐趣,AI PC能够根据用户的习惯和需求进行智能学习和个性化推荐,让用户体验更加智能、个性化的服务。AI PC通过语音识别、图像识别等技术,为用户提供更加便捷的操作方式,让人机交互更加自然和高效。AI PC还可以通过智能识别和分析,帮助用户更好地管理和利用数据,提高工作效率和生活品质。AI PC的出现将为我们的生活和工作带来更多新的可能性和体验,相信它将在未来继续为我们带来更多惊喜。
2.边缘端生成式AI
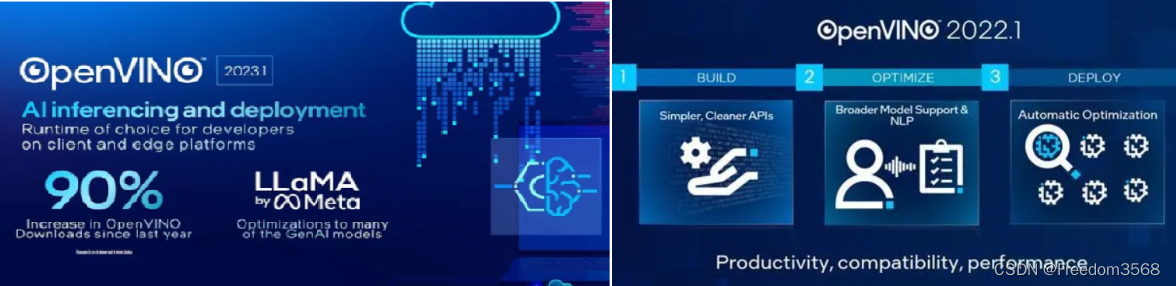
OpenVINO是英特尔的AI推理和部署运行工具套件,在客户端和边缘平台上为开发人员提供了优质选择。该版本包括针对跨操作系统和各种不同云解决方案的集成而优化的预训练模型,包括多个生成式AI模型,例如Meta的Llama 2模型。同时,英特尔为开发人员提供一套全栈式 AI 软件产品组合,这套产品组合自下而上首先是作为基础层的oneAPI,它能够支持一系列具有通用功能的英特尔处理器。其次,对于推理优化和部署来说,OpenVINO则能够针对每款英特尔处理器进行调整,助力开发人员轻松实现可扩展及高性能的深度学习推理。
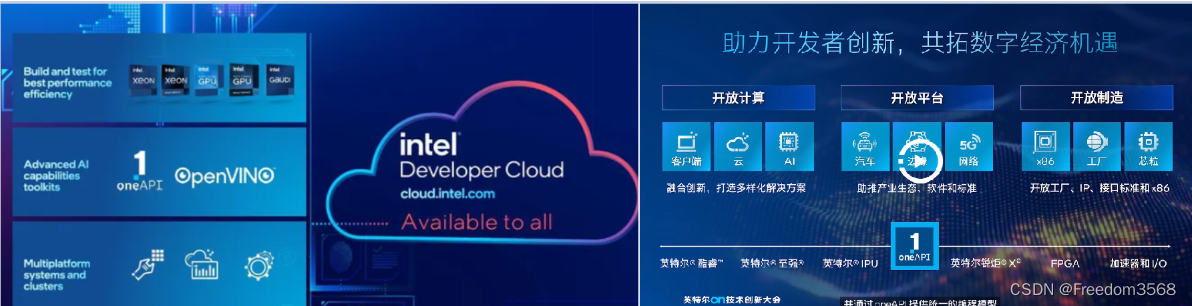
在大会上,英特尔还宣布了英特尔开发者云平台全面上线,该平台可以帮助开发者利包括Gaudi2加速器在内的最新英特尔软硬件进行AI开发,并授权他们使用第五代英特尔至强可扩展处理器、英特尔数据中心GPU Max系列1100和1550等最新硬件平台。通过英特尔开发者云平台,开发者可以构建、测试和优化AI以及科学计算应用程序,运行从小规模到大规模的AI训练、模型优化和推理工作负载。英特尔开发者云平台建立在oneAPI编程模型基础上,可以支持多架构、多厂商硬件,满足代码重用和可移植性需求,这与英伟达CUDA体系截然不同。
边缘端生成式AI是一种非常令人兴奋的技术,它将人工智能的强大能力引入了边缘设备,使得设备可以在本地进行实时的智能决策和数据处理,而无需依赖云端计算。我个人对这项技术充满了期待和好奇,边缘端生成式AI的出现,可以为智能设备赋予了更多的自主性和智能化能力,使得设备可以更加灵活地应对各种复杂的实时场景,从而提高了设备的响应速度和性能表现。同时这种技术也有望加速实现隐私保护和数据安全,因为数据可以在设备本地进行处理,不必传输到云端,从而减少了数据泄露和隐私风险。基于OpenVINO的边缘端生成式AI技术的发展将为智能设备的普及和应用带来了新的可能性,个人非常期待它将会在各个行业领域的应用与表现。
3.以芯片为基石助力AI

在此次大会上,英特尔推出了代号为Meteor Lake的酷睿Ultra处理器。英特尔酷睿Ultra处理器取代了以往的酷睿i系列,在制程工艺、芯片架构、封装模式等方面做了全面更新。AI能力方面,Meteor Lake处理器在SoC模块集成了独立的神经网络处理器(NPU),用来在PC端完成高能效的AI加速和本地推理体验。独立的NPU不但可以实现持续的低功耗AI能力以及对CPU、GPU的AI卸载,也可以与CPU、GPU协同工作,满足高性能、高吞吐量的AI算力需求。
此外,采用能效核(E-core)设计的高能效至强处理器Sierra Forest将于2024年上半年上市。与第四代至强相比,最高拥有288核的Sierra Forest处理器将使机架密度提升2.5倍,每瓦性能提高2.4倍。采用性能核(P-core)设计的高性能至强处理器Granite Rapids会在Sierra Forest之后发布,与第四代至强相比其AI性能将提高2到3倍。而根据路线图,基于Intel 18A制程节点制造的代号为Clearwater Forest的下一代至强能效核处理器,将于2025年问世。在近期MLCommons官方公布的MLPerf AI推理性能基准测试结果当中,英特尔的CPU、AI加速器取得了不错的成绩,结合此前发布的MLCommons AI训练结果、Hugging Face性能基准测试成绩,充分说明了包括英特尔在AI领域的竞争力。特别是Gaudi2 AI加速器,在视觉语言模型等方面的表现已经超越了英伟达H100加速器。
酷睿Ultra处理器在能效表现上给我留下了深刻印象,它采用了先进的制程工艺和节能技术,使得在高性能的同时能够保持较低的功耗,延长了电池续航时间,也降低了设备的发热量。相信它将继续成为高性能处理器领域的佼佼者,为用户带来更加优异的使用体验。
4.小AI模型

随着人工智能技术的不断发展,人们开始认识到AI大模型在一些方面存在一些问题,而AI小模型可能会成为未来的发展趋势。
- AI大模型通常需要庞大的计算资源和能源消耗,这不仅增加了成本,也对环境造成了不小的压力。相比之下,小模型在计算资源和能源消耗上要低得多,更加环保和经济高效。
- AI大模型在部署和应用时往往需要更多的存储空间和内存,这对于一些资源受限的设备来说是一个挑战。而小模型相对来说更加轻量级,更容易在各种设备上进行部署和应用,能够更好地适应边缘计算和物联网设备的需求。
- AI小模型在一些特定的任务上可能会表现出更高的效率和性能,尤其是在一些嵌入式设备、移动设备和边缘设备上。它们可以更快速地进行推理和响应,适用于更多的场景和应用,比如在智能手机、移动设备、无人机、自动驾驶汽车、机器人、穿戴设备、农业、医疗、体育、娱乐等各种硬件设施和各行各业中。
五、小结
“AI代表着新时代的到来。AI正在催生全球增长的新时代,在新时代中,算力起着更为重要的作用,让所有人迎来更美好的未来。对开发者而言,这将带来巨大的社会和商业机遇,以创造更多可能,为世界上的重大挑战打造解决方案,并造福地球上每一个人”,帕特·基辛格在大会上的发言至今回响在我的脑海中。
英特尔On技术创新大会不仅是一个展示科技创新成果的平台,也是一个促进行业交流和合作的重要平台,更是一场面向智算时代开发者的年度技术盛会。通过本届大会上,参与者不仅可以了解英特尔在芯片及人工智能等技术创新领域的最新动态,还可以探索未来的发展方向,为自己的业务和技术发展寻找灵感和机遇,帮助他们更好地了解和掌握最新的技术和趋势,推动自己的业务和技术发展。再次感谢英特尔大会为我们提供了这样一个平台,让我们可以和全世界的客户、合作伙伴和专家共同的交流和学习,共同探讨人工智能的未来发展方向,同时祝愿英特尔公司基业常青,On技术创新大会越办越好。
**彩蛋:**欢迎点赞-收藏-加关注,关注我,交个朋友,带你了解更多关于人工智能的前沿咨询,让我们共同成长。

