- 1Visual Studio 2013 无法启动 IIS Express 的解决办法,新建web项目时出错,系统找不到指定文件_-visual studio-iis express 2013 工具 web 项目
- 2代码笔记
- 3Unity3D开发环境的搭建_unity开发环境搭建
- 4PostgreSQL锁详解_postgresql 行锁
- 5qt 汉字输出 中文输出 显示乱码 qDebug() 乱码 解决
- 6uniapp微信小程序进度条progress渐变色效果(demo)_uniapp 进度条背景色可以是渐变色吗
- 7Android性能测试用例_高通 android设备的性能测试用例
- 8真机调试设备不够?华为AGConnect云调试帮你忙
- 9【Google Play】正式版上架流程 ( 创建版本 | 设置国家地区 | 发布正式版 )
- 10皮肤电数据简介及预处理指南_皮肤电信号处理
hadoop3.x-尚硅谷笔记1(入门与背景知识)_尚硅谷hadoop3笔记
赞
踩
20220114-20220115听的课,P1-P17
尚硅谷大数据Hadoop 3.x(入门搭建+安装调优)_哔哩哔哩_bilibili
课前背景
课程改变:hadoop3.1.3 主要变化内容yarn调度器与调度算法
集群搭建完毕后的压测,多目录配置,集群的动态增加与减少
生产调优参数,hadoop源码解析以及RPC源码解析
技术基础:
javase+maven+idea+linux
概念基础:
大数据:海量数据的采集+存储+计算问题
特点:“4V”
volume大量(TB,EB级别的数据)
velocity高速(快速产生数据,要求处理效率高)
variety多样(结构化数据+非结构化数据)
value低价值密度(在海量数据中进行数据提纯)数据清洗ETL
应用场景:
零售行业,物流仓储,保险,金融,房地产
业务流程分析:
Hadoop入门
概念+环境准备+生产集群搭建+常见错误
Hadoop发展历史:lucene框架的优化升级,面临海量数据的存储与处理,构造类似Google的框架
Hadoop优势:高可靠性(底层维护多个副本),高扩展性(动态增加动态删除),高效性(并行工作),高容错性(失败任务重新分配)
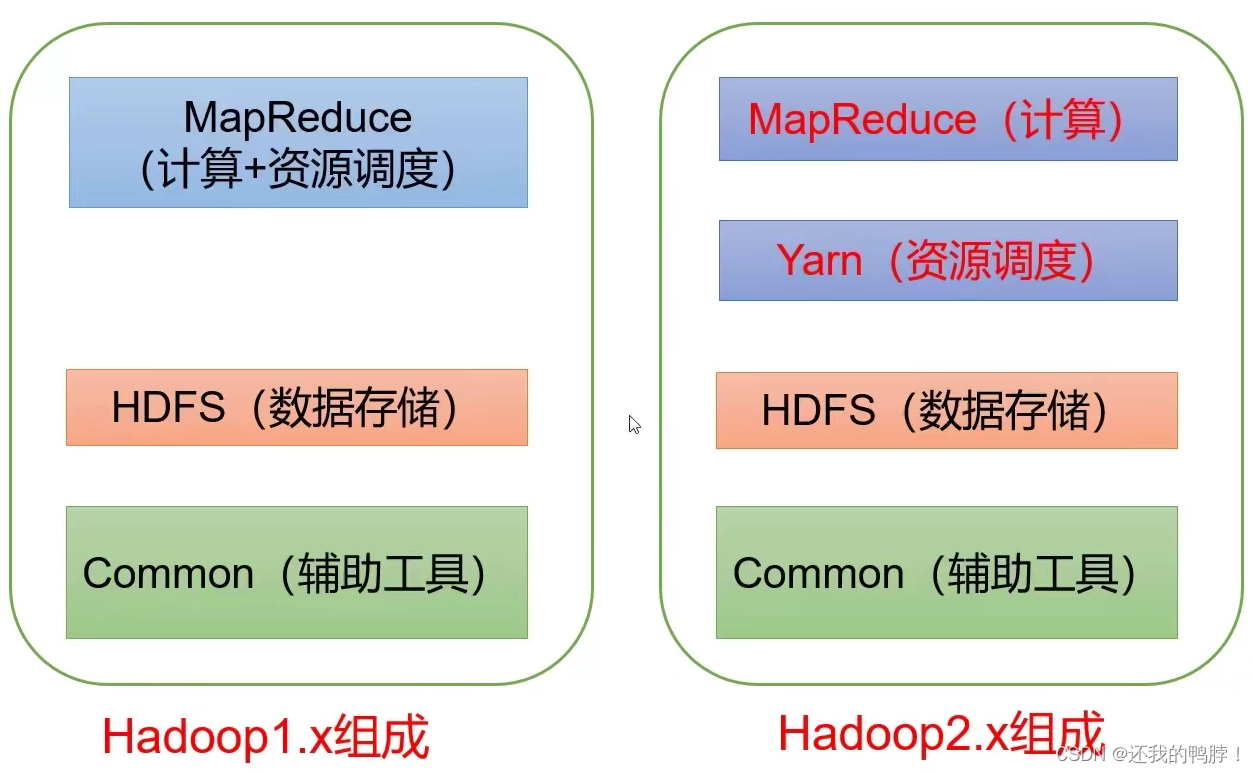
Hadoop组成:HDFS+yarn+MapReduce
2.x增加了yarn,管理CPU和内存
HDFS Hadoop distribute file system 分布式文件系统
NameNode:数据为NameNode,表示整体数据的存储情况,文件名,文件目录结构,文件属性等
DataNode:分布存储在多台服务器上,每台为一个DataNode,即具体存储数据,以及块数据的校验和
2NN(Secondary NameNode):辅助namenode工作,隔一段时间备份
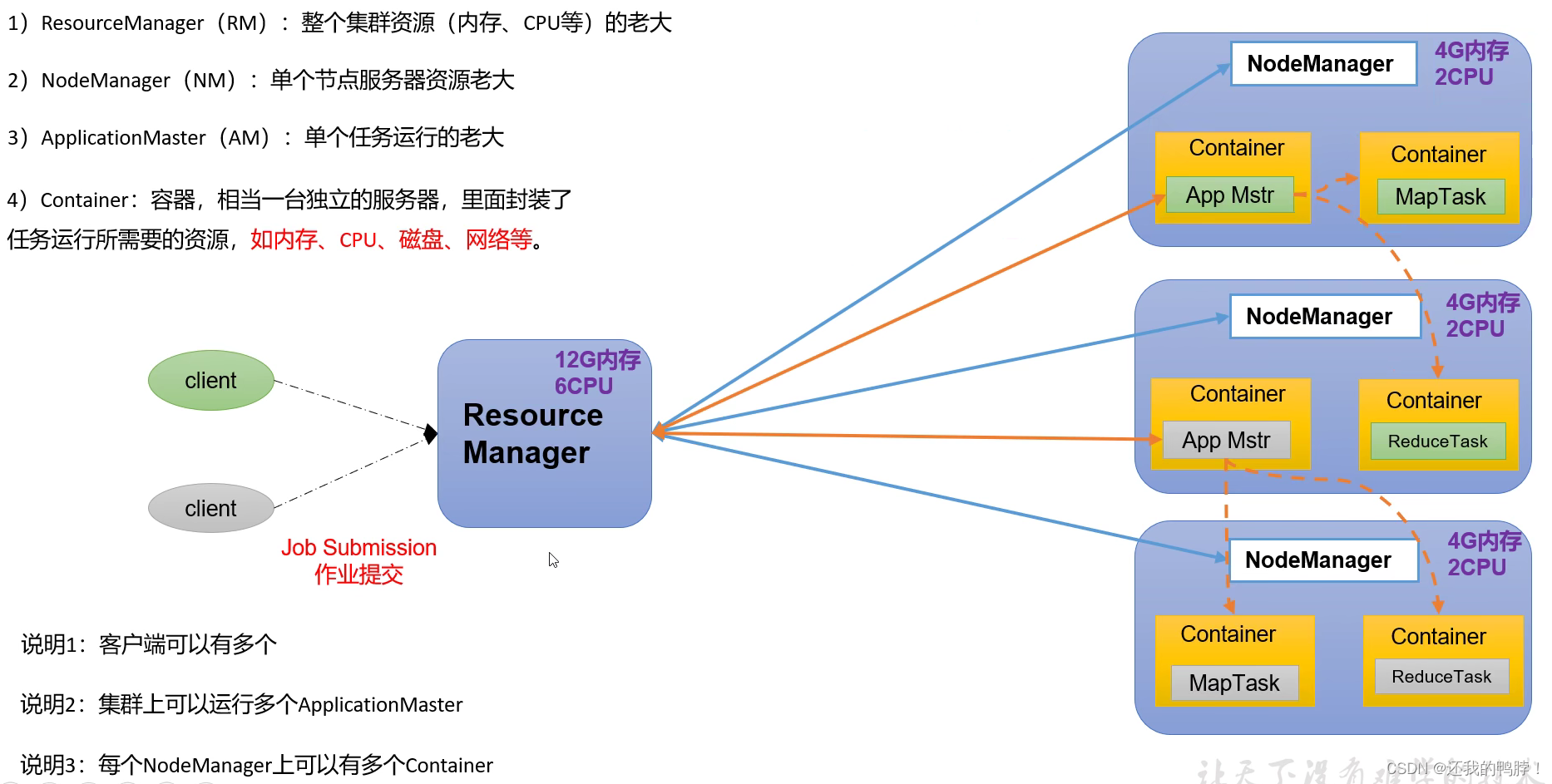
yarn架构概述
资源管理器,=【RM】Resource Manager(整个集群的资源管理)+【NM】NodeManager(单节点资源管理)
每一个NM里面有container,作为一个容器,其中有独立服务器包含内存、CPU、磁盘等,其中有AM(ApplicationMaster)管理单个任务,使得任务完成后可以自动回收
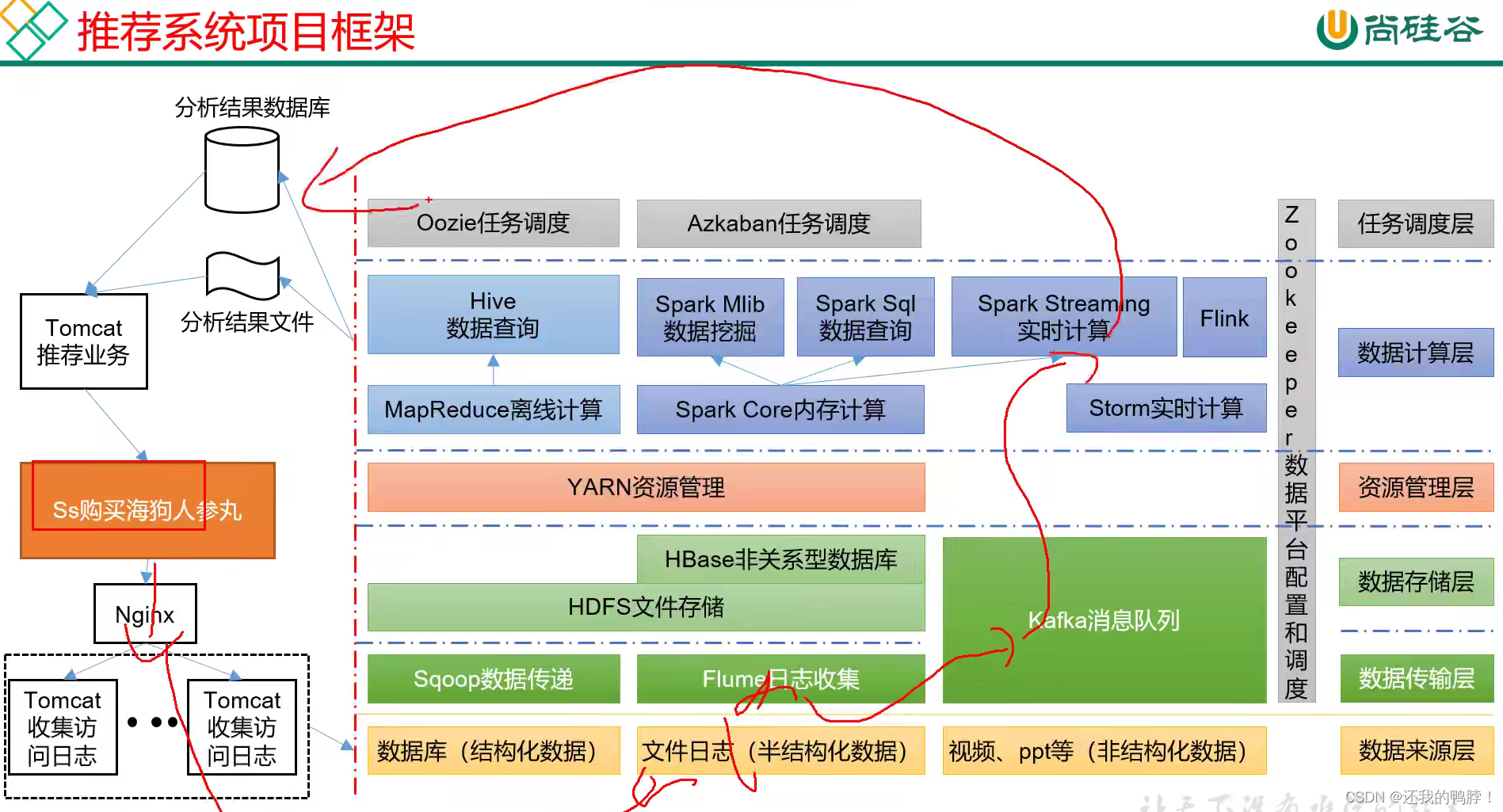
大数据生态体系
【1】数据的收集:结构化(结构化数据传递Sqoop)+半结构化(半结构化数据-日志收集Flume)+非结构化(非结构化数据-视频PPT消息队列Kafka)
【2】数据的存储:HDFS,Hbase(重点针对非关系型数据库)
【3】数据的计算:
离线计算:1、MapReduce-hive;2、Spark-Spark Milb+Spark Sql
实时计算:1、Spark Streaming;2、Flink(重点内容);3、Storm(不咋用了)
【4】任务调度:Oozie,Azkaban决定任务什么时候执行、先后的调度器
zookeeper数据平台配置与调度
【5】业务模型 ,以数据库或者分析文件形式产出