
- 1利用Trim/discard挂载rbd块设备
- 2NLP——文本分类模型(二)_文本二分类模型
- 3区块链媒体套餐:精益求精链游媒体宣发推广7个关键细节分享-华媒舍
- 4自定义消息传递_wxwidget 的on_message
- 5归并排序示例:小和问题_归并排序 计算左侧小于当前元素的个数
- 6利用timetz()函数获取pandas.Timestamp的时分秒
- 7国内GitHub无法连接的解决方法大全_github无法直连
- 8牛客网刷题-重排链表_将给定的单链表l:l0→l1→l2→…→ln-2→ln-1→ln 重新排序为:l0→ln→l1→ln
- 9华为OD机试 - 分割均衡字符串(Java & JS & Python & C & C++)_分割均衡字符串华为od
- 10大数据分析报告--微博舆情分析_微博舆情数据分析
BN(Batch Normalization 批量归一化)_批归一化bn
赞
踩
BN(Batch Normalization 批量归一化)
BN(批量归一化)算法在DL中出现的频率很高,因为对于提升模型收敛速度来说具有非常好的效果。
本文将通过以下三个点来理解Batch Normalization。
一、什么是BN
我们在训练模型的时候希望训练集训练出来的模型在通过测试集时能够拥有和训练时一样的效果,为此,有这样一个假设,即训练集数据和测试集数据是满足相同分布的,这个叫做IID(独立同分布假设),就是随机变量相互独立互不影响且具有相同的分布形状和相同的分布参数,也就是训练集数据和测试集数据中的样本变量分布得范围是相同的。
而BN的作用就是保证深度神经网络在训练过程中每层的输入值分布相同。
但是,对于深度学习这种包含很多隐层的网络结构,训练时,每层的参数都是在不断变化的,所以每个隐层都会面临covariate shift(对于一个可以学习的模型来说,它的输入值分布总是在变,那么该模型就不能稳定的学习规律,学不好本该学到的内容,而是还要花费一部分精力去研究输入值分布是如何变化的。就好比一个孩子一会学这一会学那,最后都学不好。)的问题,也就是在训练过程中,隐层的输入分布总是变来变去,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情,而covariate shift问题只发生在输入层。
故BatchNorm的基本思想就是让每个隐层节点的激活输入分布固定下来从而避免了“Internal Covariate Shift”的问题。
期初,在图像处理中对输入图像做白化(Whiten)操作(就是对输入数据分布变换到0均值,单位方差的正态分布)可以加快神经网络的收敛速度。于是BN作者就某个隐层的神经元是下一层的输入,提出了对每个隐层都做白化的想法。可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
二、为什么要用BN
我们知道模型训练过程中最重要的一步就是梯度更新,常用的方法就是Mini-Batch SGD,它更新方向准确且速度快,但是它调参麻烦啊,选择合适的学习率会花费很多时间,于是BN就可以帮助Mini-Batch SGD改变它的缺点。
随着神经网络深度加深,虽然精度得到了明显的提升,但是网络收敛的速度越来越慢,是因为深层神经网络在做非线性变换(relu/sigmoid)前的激活输入值(就是那个x=WU+B,U是输入)在训练过程中的分布逐渐发生偏移或者变动,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这种激活输入值分布的变动导致了后向传播时低层神经网络的梯度逐渐消失,致使网络训练耗时长。实际上,在深度学习中,一直在解决的问题就是精度和速度,而BN就是提升网络训练速度的一个方法。正如前面说到的,它是通过一定的规范化手段(白化操作),把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正太分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域(不是极限区域),这样输入所产生的小变化会导致损失函数较大的变化,即会让梯度变大,从而学习收敛速度快,避免了梯度消失的问题,最终加快训练时速度。
简单概括就是:对于每个隐层神经元,在非线性函数映射后把逐渐向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域(不会导致梯度消失的区域)。
由于梯度始终保持在比较大的状态,所以对神经网络的参数调整效率比较高,就是说向损失函数最优值迈动的步子大,即收敛速度快, 至此,问题不就解决了吗?
以sigmoid函数为例:
首先,下图为一张标准的正太分布图(均值为0,方差为1)
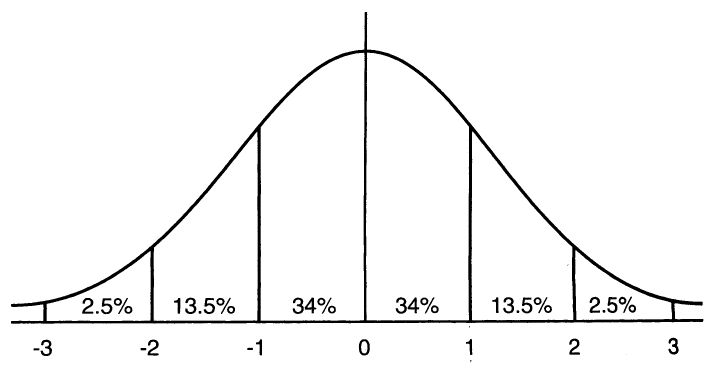
该图表示在一个标准差范围内,有64%的概率,x的值会落在[-1,1]的范围内;在两个标准差范围内,即95%的概率,x的值落在了[-2,2]的范围内。
接着,下图为sigmoid(x)函数图形:

我们知道,激活值x=WU+B,U是真正的输入,x是某个神经元的激活值,假设没有经过BN调整前的x的正态分布其均值是-6,方差是1,那么在两个标准差内,95%的值落在了[-8,-4]之间,那么对应的在此区间内,Sigmoid(x)函数的值明显接近于0,这是典型的梯度饱和区,在这个区域里梯度变化很慢甚至会消失,可以看到图中曲线几乎与x轴平行,当sigmoid(x)取值接近0或者接近于1的时候对应导数函数取值也接近于0。
现假设经过BN后,均值是0,方差是1,即标准的正态分布就有95%的x值落在了[-2,2]区间内,从图中可以看到,该区间内sigmoid(x)函数接近于线性变换的区域,即上面说到的x产生的小变化会导致非线性函数值较大的变化,也即梯度变化较大(梯度非饱和区)。所以说经过BN后,大部分激活值落在了非线性函数的线性区内,该区域内对应的导数远离导数(梯度)饱和区,从而加速了训练收敛过程。
三、如何使用BN
在训练和推理阶段BN的操作是不同的。
训练阶段的BatchNorm
要对每个隐层神经元的激活值做BN,可以看做是在每个隐层后又加了BN层,该层位于X=WU+B激活值获得之后,非线性函数(relu/sigmoid)变换之前。
对于Mini-Batch SGD来说,一次训练过程里面包含m个训练实例,其具体BN操作就是对于隐层内每个神经元的激活值进行如下变换:

即某个神经元对应的原始的激活x(k)通过减去mini-Batch内m个实例的激活值x求得的均值E(x)并除以求得的方差Var(x)来进行转换。其中x(k)是当前层某个神经元的激活x=WU+B,U是上层神经元的输出。
所以说这个变换就是将某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把激活值尽可能的往非线性变换的线性区拉动,增大导数值,增强反向传播信息能力,加快训练收敛速度。
但是把隐层的神经元都通过BN,也就是把值都往线性区拉动,那么就跟把非线性函数替换成线性函数效果相同了,对于深层网络来说线性函数是没有意义的,无论在网络中加多少个线性函数,都和加一个效果是相同的,因而才有了非线性函数,它使得深层神经网络的表达能力更强,学习到更多的特征。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),即每个神经元增加了两个调节参数scale和shift,这两个参数是通过训练学习得到的,用来对变换后的激活反变换,使得网络表达能力增强,意思是通过scale和shift可以把x从标准正态分布左移或者由移一点且长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样就等价于非线性函数的值从线性区又往非线性区拉,当然应该不是全拉回去,这样等于没BN这个操作了,而是应该找到了一个线性和非线性的较好平衡点,既能拥有非线性的较强表达能力,又能避免过于靠近非线性区而使得网络收敛速度太慢。
下面是对变换后的激活进行如下的scale和shift的反变换操作:
![]()
综上,BN其具体操作流程:

清晰明了,在一个Batch内,求均值——求方差——BN——反变换。
推理阶段的BatchNorm
BN在训练的时候可以根据Mini-Batch里的若干训练实例进行激活数值调整,但是在推理(inference)的过程中,由于输入就只有一个实例,看不到Mini-Batch其它实例,那么就无法根据实例集合求出的均值和方差。于是在推理阶段,可以用从所有训练实例中获得的统计量(均值和方差)来代替Mini-Batch里面m个训练实例获得的统计量,即全局的统计量。如何求得?
只要把每个Mini-Batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局统计量,即:

有了均值和方差,每个隐层神经元也已经有对应训练好的Scaling参数和Shift参数,就可以在推导的时候对每个神经元的激活数据计算BN进行变换了,在推理过程中采取如下方式:
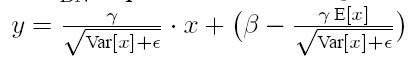
这个公式其实和训练时:
![]()
是等价的。

