
- 1Spring Boot框架的过滤器(Filters)和拦截器(Interceptors)使用
- 2MATLAB的rvctools工具箱熟悉运动学【机械臂机器人示例】_startup_rvc
- 3关于操作系统_blackberry 操作系统 发展
- 4Android Kotlin知识汇总(三)Kotlin 协程
- 5大预言模型——ChatGPT,Claude3、Sora、等技术
- 6C++进行代码加速、多线程等知识点。pthread、openomp进行多线程加速、SSE进行加速
- 7hive之拉链表实现过程及剖析_hive拉链表的实现过程
- 8Sora学习笔记 Sora技术原理解析_sora原理 csdn
- 9Linux 文件系统只读_linux 只读文件系统
- 10【爬虫】使用selenium爬取网易云音乐热歌榜_爬虫网易音乐排行榜的信息
常见的时间序列预测模型python实战汇总_小样本时间序列预测模型
赞
踩
最完整的时间序列分析和预测(含实例及代码):https://mp.weixin.qq.com/s/D7v7tfSGnoAqJNvfqGpTQA
1 时间序列与时间序列分析
在生产和科学研究中,对某一个或者一组变量
ARIMA 模型对时间序列的要求是平稳型。因此,当你得到一个非平稳的时间序列时,首先要做的即是做时间序列的差分,直到得到一个平稳时间序列。如果你对时间序列做d次差分才能得到一个平稳序列,那么可以使用ARIMA(p,d,q)模型,其中d是差分次数。
fig = plt.figure(figsize=(12,8))
ax1= fig.add_subplot(111)
diff1 = dta.diff(1)
diff1.plot(ax=ax1)
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
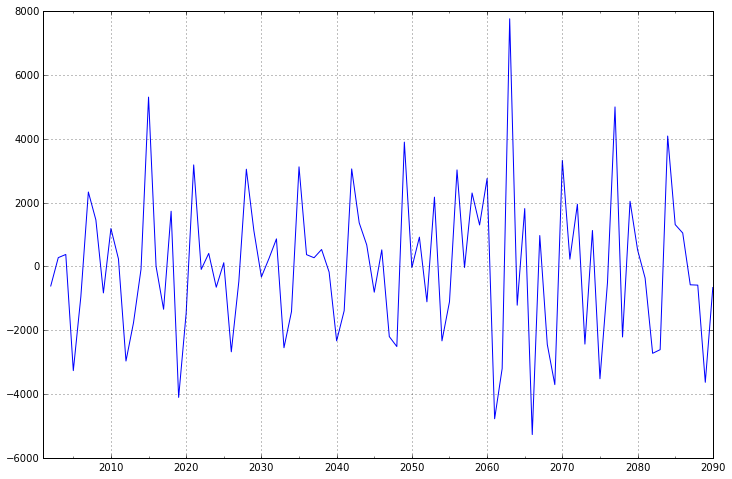
一阶差分的时间序列的均值和方差已经基本平稳,不过我们还是可以比较一下二阶差分的效果
fig = plt.figure(figsize=(12,8))
ax2= fig.add_subplot(111)
diff2 = dta.diff(2)
diff2.plot(ax=ax2)
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
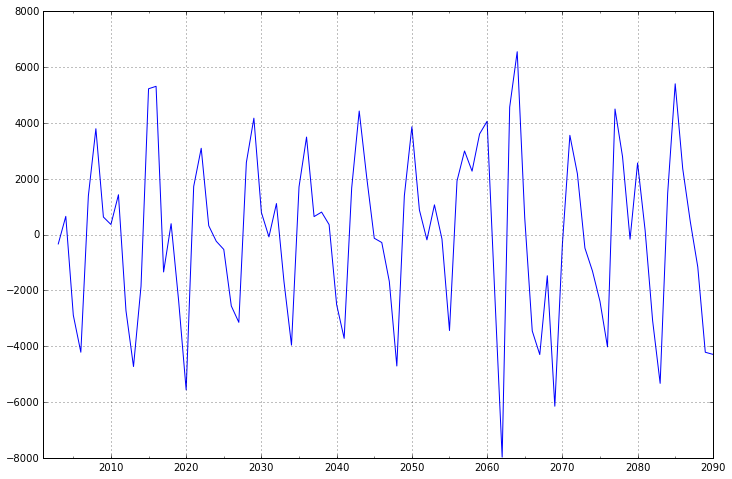
可以看出二阶差分后的时间序列与一阶差分相差不大,并且二者随着时间推移,时间序列的均值和方差保持不变。因此可以将差分次数d设置为1。
其实还有针对平稳的检验,叫“ADF单位根平稳型检验”,以后再更。
3.3 合适的。
第一步我们要先检查平稳时间序列的自相关图和偏自相关图。 dta= dta.diff(1)#我们已经知道要使用一阶差分的时间序列,之前判断差分的程序可以注释掉
fig = plt.figure(figsize=(12,8))
ax1=fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta,lags=40,ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta,lags=40,ax=ax2)
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
dta= dta.diff(1)#我们已经知道要使用一阶差分的时间序列,之前判断差分的程序可以注释掉
fig = plt.figure(figsize=(12,8))
ax1=fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta,lags=40,ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta,lags=40,ax=ax2)
其中lags 表示滞后的阶数,以上分别得到acf 图和pacf 图
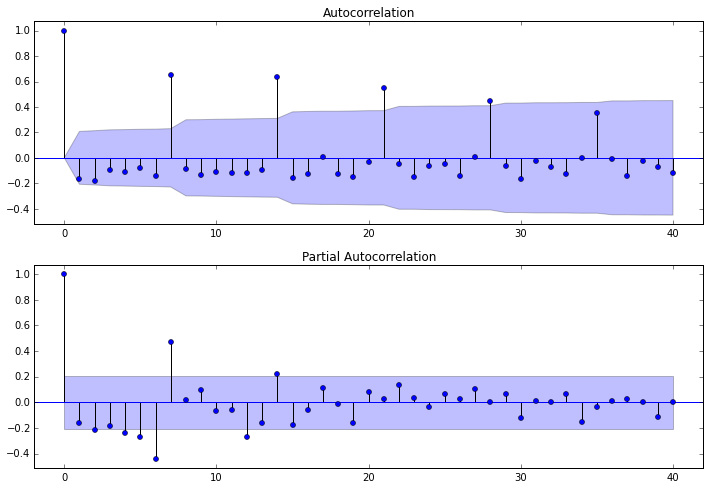
通过两图观察得到:
* 自相关图显示滞后有三个阶超出了置信边界;
* 偏相关图显示在滞后1至7阶(lags 1,2,…,7)时的偏自相关系数超出了置信边界,从lag 7之后偏自相关系数值缩小至0
则有以下模型可以供选择:
1. ARMA(0,1)模型:即自相关图在滞后1阶之后缩小为0,且偏自相关缩小至0,则是一个阶数q=1的移动平均模型;
2. ARMA(7,0)模型:即偏自相关图在滞后7阶之后缩小为0,且自相关缩小至0,则是一个阶层p=3的自回归模型;
3. ARMA(7,1)模型:即使得自相关和偏自相关都缩小至零。则是一个混合模型。
4. …还可以有其他供选择的模型
现在有以上这么多可供选择的模型,我们通常采用ARMA模型的AIC法则。我们知道:增加自由参数的数目提高了拟合的优良性,AIC鼓励数据拟合的优良性但是尽量避免出现过度拟合(Overfitting)的情况。所以优先考虑的模型应是AIC值最小的那一个。赤池信息准则的方法是寻找可以最好地解释数据但包含最少自由参数的模型。不仅仅包括AIC准则,目前选择模型常用如下准则:
* AIC=-2 ln(L) + 2 k 中文名字:赤池信息量 akaike information criterion
* BIC=-2 ln(L) + ln(n)*k 中文名字:贝叶斯信息量 bayesian information criterion
* HQ=-2 ln(L) + ln(ln(n))*k hannan-quinn criterion
构造这些统计量所遵循的统计思想是一致的,就是在考虑拟合残差的同时,依自变量个数施加“惩罚”。但要注意的是,这些准则不能说明某一个模型的精确度,也即是说,对于三个模型A,B,C,我们能够判断出C模型是最好的,但不能保证C模型能够很好地刻画数据,因为有可能三个模型都是糟糕的。
arma_mod20 = sm.tsa.ARMA(dta,(7,0)).fit()
print(arma_mod20.aic,arma_mod20.bic,arma_mod20.hqic)
arma_mod30 = sm.tsa.ARMA(dta,(0,1)).fit()
print(arma_mod30.aic,arma_mod30.bic,arma_mod30.hqic)
arma_mod40 = sm.tsa.ARMA(dta,(7,1)).fit()
print(arma_mod40.aic,arma_mod40.bic,arma_mod40.hqic)
arma_mod50 = sm.tsa.ARMA(dta,(8,0)).fit()
print(arma_mod50.aic,arma_mod50.bic,arma_mod50.hqic)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
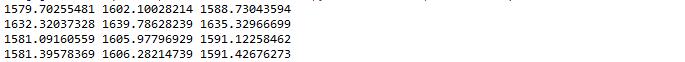
可以看到ARMA(7,0)的aic,bic,hqic均最小,因此是最佳模型。
3.4 模型检验
在指数平滑模型下,观察ARIMA模型的残差是否是平均值为0且方差为常数的正态分布(服从零均值、方差不变的正态分布),同时也要观察连续残差是否(自)相关。
3.4.1 我们对ARMA(7,0)模型所产生的残差做自相关图
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(resid.values.squeeze(), lags=40, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(resid, lags=40, ax=ax2)
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
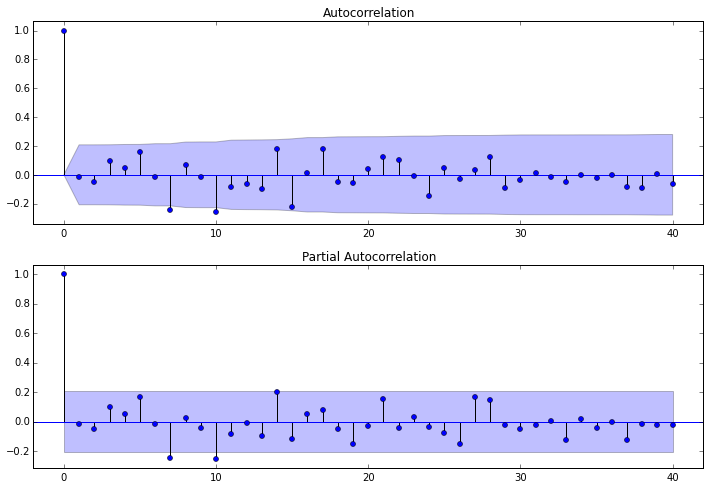
3.4.2 做D-W检验
德宾-沃森(Durbin-Watson)检验。德宾-沃森检验,简称D-W检验,是目前检验自相关性最常用的方法,但它只使用于检验一阶自相关性。因为自相关系数ρ的值介于-1和1之间,所以 0≤DW≤4。并且DW=O=>ρ=1 即存在正自相关性
DW=4<=>ρ=-1 即存在负自相关性
DW=2<=>ρ=0 即不存在(一阶)自相关性
因此,当DW值显著的接近于O或4时,则存在自相关性,而接近于2时,则不存在(一阶)自相关性。这样只要知道DW统计量的概率分布,在给定的显著水平下,根据临界值的位置就可以对原假设H0进行检验。
print(sm.stats.durbin_watson(arma_mod20.resid.values))
- 1
- 1
检验结果是2.02424743723,说明不存在自相关性。
3.4.3 观察是否符合正态分布
这里使用QQ图,它用于直观验证一组数据是否来自某个分布,或者验证某两组数据是否来自同一(族)分布。在教学和软件中常用的是检验数据是否来自于正态分布。QQ图细节,下次再更。
resid = arma_mod20.resid#残差
fig = plt.figure(figsize=(12,8))
ax = fig.add_subplot(111)
fig = qqplot(resid, line='q', ax=ax, fit=True)
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
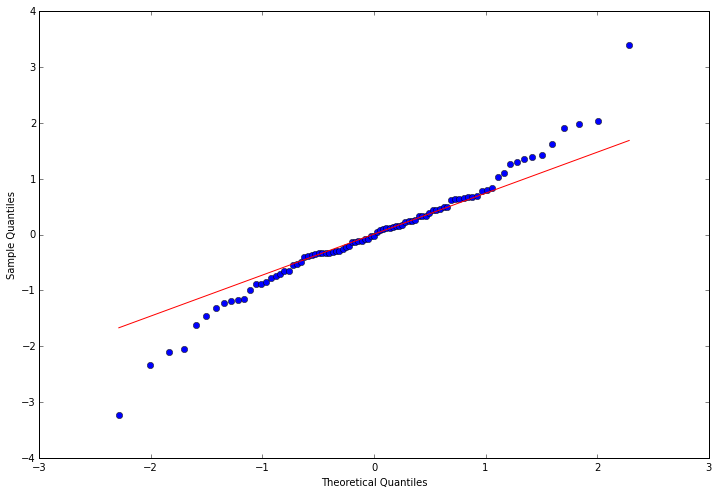
3.4.4 Ljung-Box检验
Ljung-Box test是对randomness的检验,或者说是对时间序列是否存在滞后相关的一种统计检验。对于滞后相关的检验,我们常常采用的方法还包括计算ACF和PCAF并观察其图像,但是无论是ACF还是PACF都仅仅考虑是否存在某一特定滞后阶数的相关。LB检验则是基于一系列滞后阶数,判断序列总体的相关性或者说随机性是否存在。
时间序列中一个最基本的模型就是高斯白噪声序列。而对于ARIMA模型,其残差被假定为高斯白噪声序列,所以当我们用ARIMA模型去拟合数据时,拟合后我们要对残差的估计序列进行LB检验,判断其是否是高斯白噪声,如果不是,那么就说明ARIMA模型也许并不是一个适合样本的模型。
r,q,p = sm.tsa.acf(resid.values.squeeze(), qstat=True)
data = np.c_[range(1,41), r[1:], q, p]
table = pd.DataFrame(data, columns=['lag', "AC", "Q", "Prob(>Q)"])
print(table.set_index('lag'))
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
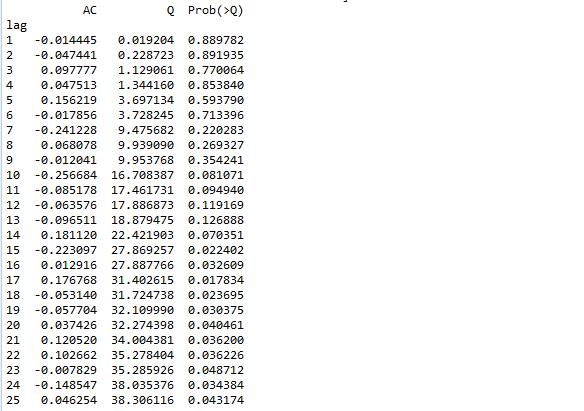
检验的结果就是看最后一列前十二行的检验概率(一般观察滞后1~12阶),如果检验概率小于给定的显著性水平,比如0.05、0.10等就拒绝原假设,其原假设是相关系数为零。就结果来看,如果取显著性水平为0.05,那么相关系数与零没有显著差异,即为白噪声序列。
3.5 模型预测
模型确定之后,就可以开始进行预测了,我们对未来十年的数据进行预测。
predict_sunspots = arma_mod20.predict('2090', '2100', dynamic=True)
print(predict_sunspots)
fig, ax = plt.subplots(figsize=(12, 8))
ax = dta.ix['2001':].plot(ax=ax)
predict_sunspots.plot(ax=ax)
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
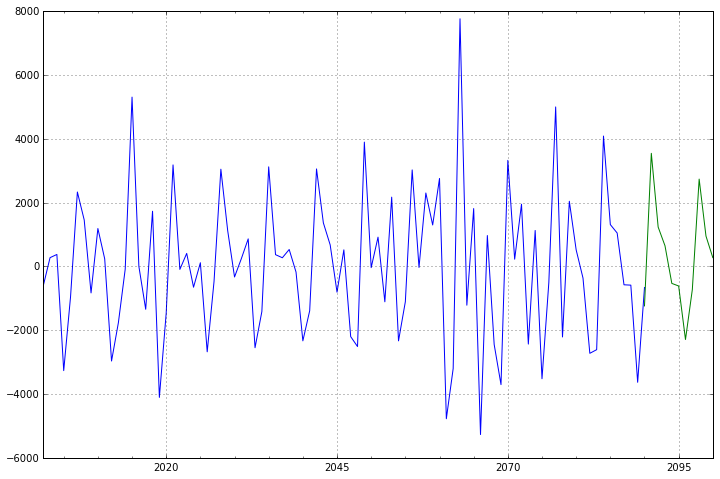
前面90个数据为测试数据,最后10个为预测数据;从图形来,预测结果较为合理。至此,本案例的时间序列分析也就结束了。

