
- 1基于SpringBoot + Vue实现单个文件上传(带上Token和其它表单信息)的前后端完整过程_springboot vue 导入excel时如果传递 authorization
- 2计算机体系结构:VLIW
- 3基于Python的抽取式文本自动摘要的实现
- 4【郑益慧】模拟电子技术:6.BJT特性曲线共射_为使npn型管和pnp型管工作在放大状态
- 5java 权重 分配_一种按权重分配的Java算法
- 6android 通过包名启动activity,查看Android应用包名、Activity的几个方法
- 7什么是「最小二乘法」
- 8C2000ware介绍
- 9时序预测 | Matlab基于BiTCN-LSTM双向时间卷积长短期记忆神经网络时间序列预测
- 10Linux Centos7内网服务器离线升级openssh9.3_centos7升级openssh9.3
ES6学习笔记6 函数的扩展_es6 函数的扩展
赞
踩
函数参数的默认值
ES6可以为函数的参数提供默认值,直接写在参数定义的后面即可
function log(x, y = 'World') {
console.log(x, y);
}
log('Hello') // Hello World
log('Hello', 'China') // Hello China
log('Hello', '') // Hello- 1
- 2
- 3
- 4
- 5
- 6
- 7
参数变量时默认声明的,所以不能用let和const重复声明。在使用参数默认值时,函数不能有同名参数。
function foo(x = 5) {
let x = 1; // error
const x = 2; // error
}- 1
- 2
- 3
- 4
若函数默认值是一个表达式或函数时,则其是惰性求值的,只有当使用到默认值时,才计算表达式的值
let x = 99;
function foo(p = x + 1) {
console.log(p);
}
foo() // 100
x = 100;
foo() // 101- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上述代码在第二次调用foo函数时,重新计算了参数p的默认值
与解构赋值默认值结合使用
参数默认值可以和解构赋值默认值联合起来使用
function foo({x, y = 5} = {}) {
console.log(x, y);
}
foo() // undefined 5- 1
- 2
- 3
- 4
- 5
上述函数,当不传入参数时,函数foo的参数将默认为一个空对象,此时y的值为undefined,因此自动采取默认值5
// 写法一
function m1({x = 0, y = 0} = {}) {
return [x, y];
}
// 写法二
function m2({x, y} = { x: 0, y: 0 }) {
return [x, y];
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
写法1中,函数的默认参数是一个空对象,x和y的默认值都为0。这意味着,无论函数有没有传入参数,x和y总是有值,其不可能为undefined
写法2中,函数的默认参数是一个对象,而x和y没有默认值,这导致当函数的参数为空对象或{x:undefined, y:undefined}时,x和y会为undefined
参数默认值的位置
定义了默认值的函数参数应该为函数的尾参数,否则无法省略该参数而不省略其后参数,除非显示输入undefined
// 例一
function f(x = 1, y) {
return [x, y];
}
f() // [1, undefined]
f(2) // [2, undefined])
f(, 1) // 报错
f(undefined, 1) // [1, 1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
函数的length属性
指定了默认值以后,函数的length属性将返回没有指定默认值参数的个数,但rest参数不会计入length属性,同时,如果默认值参数不是尾参数,那么位于该默认值参数之后的参数也不计入length属性
(function (a) {}).length // 1
(function (a = 5) {}).length // 0
(function (a, b, c = 5) {}).length // 2- 1
- 2
- 3
(function(...args) {}).length // 0
(function (a = 0, b, c) {}).length // 0- 1
- 2
作用域
一旦设置了参数的默认值,函数进行声明初始化时,参数会形成一个单独的作用域(context)。等到初始化结束,这个作用域就会消失。这种语法行为,在不设置参数默认值时,是不会出现的。
var x = 1;
function f(x, y = x) {
console.log(y);
}
f(2) // 2- 1
- 2
- 3
- 4
- 5
- 6
- 7
上述代码中,调用函数f时,参数形成了一个单独的作用域,在这个作用域中,默认值变量x指向函数的第一个参数x,而不是全局变量的x,所以输出是2
let x = 1;
function f(y = x) {
let x = 2;
console.log(y);
}
f() // 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
上面代码中,函数f调用时,参数y = x形成一个单独的作用域。这个作用域里面,变量x本身没有定义,所以指向外层的全局变量x。函数调用时,函数体内部的局部变量x影响不到默认值变量x(注:经过火狐浏览器加traceur转换测试,变量x并没有指向外部的全局变量x,最终y的值为undefined)
var x = 1;
function foo(x, y = function() { x = 2; }) {
var x = 3;
y();
console.log(x);
}
foo() // 3
x // 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在函数foo参数形成的作用域中,首先声明了变量x,然后声明了变量y,y的默认值是一个匿名函数。这个匿名函数内部的变量x,指向同一个作用域的第一个参数x。在foo函数的内部,又声明了一个内部变量x,该变量与第一个参数x由于不是同一个作用域,所以不是同一个变量,因此执行y后,内部变量x和外部全局变量x的值都没变。(经过火狐浏览器加traceur转换测试,foo函数返回值为2,并不是3。当把var改为let时,出现重复定义变量x错误)
var x = 1;
function foo(x, y = function() { x = 2; }) {
x = 3;
y();
console.log(x);
}
foo() // 2
x // 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果将var x = 3的var去除,函数foo的内部变量x就指向第一个参数x,与匿名函数内部的x是一致的,所以最后输出的就是2,而外层的全局变量x依然不受影响。
为什么实际测试结果和书上结果不同呢?,原来是转换过程中traceur的错误,Babel也有同样的问题,以上代码在chrome中运行就和书上一样了
实际上,当定义在全局,带有默认参数的函数声明,在函数运行时共产生至少3个作用域,如下:
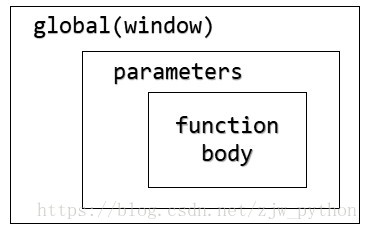
因此,如果默认参数引用了函数作用域外部的变量,同时函数内部有同名的变量存在的话,那么实际所使用的变量应该是外部的变量,而不是函数内部的。
https://segmentfault.com/q/1010000015237136
rest参数
ES6 引入 rest 参数(形式为...变量名),用于获取函数的多余参数,这样就不需要使用arguments对象了。rest 参数搭配的变量是一个数组,该变量将多余的参数放入数组中。注意,rest 参数之后不能再有其他参数(即只能是最后一个参数),否则会报错。
function add(...values) {
let sum = 0;
for (var val of values) {
sum += val;
}
return sum;
}
add(2, 5, 3) // 10- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
严格模式
只要函数参数使用了默认值、解构赋值、或者扩展运算符,那么函数内部就不能显式设定为严格模式,否则会报错。
有两种方法可以规避这种限制。第一种是设定全局的严格模式,而不是在函数内部。
'use strict';
function doSomething(a, b = a) {
// code
}
- 1
- 2
- 3
- 4
- 5
- 6
第二种方法就是将函数包在一个无参数的立即执行函数中
const doSomething = (function(){
'use strict';
return function(value = 42) {
return value;
};
}());- 1
- 2
- 3
- 4
- 5
- 6
name属性
ES6的name属性会返回实际的函数名。Function构造函数返回的函数实例,name属性的值为anonymous。bind返回的函数,name属性值会加上bound前缀。
var f = function(){};
f.name //"f"- 1
- 2
- 3
(new Function).name // "anonymous"- 1
function foo() {};
foo.bind({}).name // "bound foo"- 1
- 2
箭头函数
箭头函数使用(=>)定义
var 函数名 = 参数名 => 返回值;- 1
var f = v => v;
//等同于
var f = function(v){
return v;
};- 1
- 2
- 3
- 4
- 5
- 6
如果不需要参数或有多个参数,要使用圆括号
var f = () => 5;
var sum = (num1,num2) => num1+num2;- 1
- 2
- 3
如果函数的代码多于一条,就必须使用大括号将其括起来,并使用retun语句
var sum = (num1, num2) => { return num1 + num2; }
- 1
- 2
如果函数返回一个对象,那么必须用圆括号将其括起来
let getTempItem = id => ({ id: id, name: "Temp" });- 1
箭头函数可以简化回调函数
[1,2,3].map(x => x * x);- 1
箭头函数有以下几点注意事项:
- 函数体内的
this对象就是定义时所在的对象,而不是调用时所在的对象 - 不可以作为构造函数
- 不可以使用
arguments对象 - 不可以使用yield命令,因此箭头函数不能用作 Generator 函数
function foo() {
setTimeout(() => {
console.log('id:', this.id);
}, 100);
}
var id = 21;
foo.call({ id: 42 });
// id: 42- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
上述代码中,在foo函数中定义了一个延时调用函数,其实际执行时间为100ms之后,此时foo已经执行完毕,如果是普通函数就应该返回21,因为延时函数执行时,this值为window。但由于使用了箭头函数,使其this值总是指向函数定义生效时所在对象
还记得下面的类似例子吗?在ES5中,使用bind函数解决了this绑定问题,此时,只需使用箭头函数即可
https://blog.csdn.net/zjw_python/article/details/80109580
var handler = {
id: '123456',
init: function() {
document.addEventListener('click',
event => this.doSomething(event.type), false);
},
doSomething: function(type) {
console.log('Handling ' + type + ' for ' + this.id);
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
实际上,箭头函数自身没有自己的this,导致其内部的this就是外层代码块的this
// ES6
function foo() {
setTimeout(() => {
console.log('id:', this.id);
}, 100);
}
// ES5
function foo() {
var _this = this;
setTimeout(function () {
console.log('id:', _this.id);
}, 100);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
除了this,以下三个变量在箭头函数之中也是不存在的,它们都指向外层函数的对应变量:arguments、super、new.target。因此,由于箭头函数没有自己的this,所以当然也就不能用call()、apply()、bind()这些方法去改变this的指向
箭头函数内部还可以使用箭头函数,形成多重嵌套
//下面函数在列表中的指定位置插入项
let insert = (value) => ({into: (array) => ({after: (afterValue) => {
array.splice(array.indexOf(afterValue) + 1, 0, value);
return array;
}})});
insert(2).into([1, 3]).after(1); //[1, 2, 3]- 1
- 2
- 3
- 4
- 5
- 6
- 7
第一个insert函数,接受要插入的值value,返回一个具有into方法的对象,into方法是一个箭头函数,接受一个数列参数,返回一个具有after方法的对象,after方法接受一个插入的位置,执行插入操作,并最终返回结果数列。
双冒号运算符
ES7有个提案提出使用双冒号::,作为函数绑定运算符,用来取代call、apply、bind调用。双冒号左边是一个对象,右边是一个函数。该运算符会自动将左边的对象,作为上下文环境(即this对象),绑定到右边的函数上面。
foo::bar;
// 等同于
bar.bind(foo);
foo::bar(...arguments);
// 等同于
bar.apply(foo, arguments);
const hasOwnProperty = Object.prototype.hasOwnProperty;
function hasOwn(obj, key) {
return obj::hasOwnProperty(key);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
如果双冒号左边为空,右边是一个对象的方法,则等于将该方法绑定在该对象上面
var method = obj::obj.foo;
// 等同于
var method = ::obj.foo;- 1
- 2
- 3
尾调用优化
尾调用,指某个函数最后一步是调用另一个函数*,其不一定出现在函数尾部,但一定是函数的最后一步操作,否则不是尾调用
function f(x){
return g(x);
}
- 1
- 2
- 3
- 4
我们知道,函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
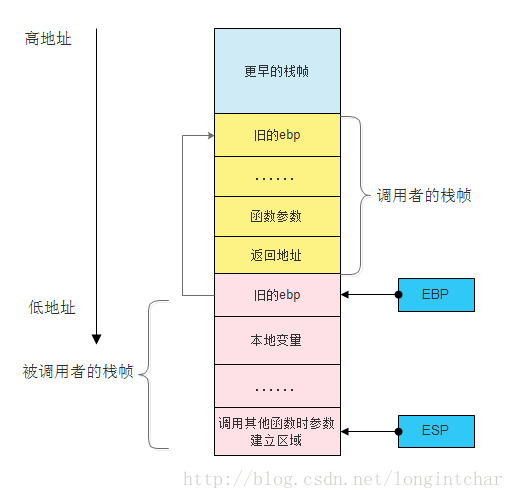
如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。这就是“尾调用优化”的意义。
尾递归
函数调用自身,称为递归。如果尾调用自身,就称为尾递归
递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误。
结合函数参数的默认值,我们可以将非尾递归函数改写为尾递归
function Fibonacci (n) {
if ( n <= 1 ) {return 1};
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
Fibonacci(10) // 89
Fibonacci(100) // 堆栈溢出
Fibonacci(500) // 堆栈溢出- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
改写后
function Fibonacci2 (n , ac1 = 1 , ac2 = 1) {
if( n <= 1 ) {return ac2};
return Fibonacci2 (n - 1, ac2, ac1 + ac2);
}
Fibonacci2(100) // 573147844013817200000
Fibonacci2(1000) // 7.0330367711422765e+208
Fibonacci2(10000) // Infinity- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
尾递归优化的实现
ES6的尾调用优化只在严格模式下开启,正常模式是无效的。在正常模式下,需要自己实现尾递归,即采用循环换掉递归
function tco(f) { //将递归转化为循环
var value;
var active = false;
var accumulated = [];
return function accumulator() {
accumulated.push(arguments); //将参数推入
if (!active) {
active = true;
while (accumulated.length) {
value = f.apply(this, accumulated.shift());
}
active = false;
return value;
}
};
}
var sum = tco(function(x, y) {
if (y > 0) {
return sum(x + 1, y - 1)
}
else {
return x
}
});
sum(1, 100000)
// 100001
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
上述代码中,原本的sum函数是一个利用递归,实现x值不断递增的函数。经过tco函数改造后,sum函数就成为了accumulator()函数。第一次运行时,active为false,参数1和10000被推入数组,进入accumulator函数的if分支,弹出参数,调用sum函数,返回accumulator(2,9999),第二次执行时,active为true,参数2和9999被推入数组,没有进入accumulator函数if分支,active变为false,返回value为undefined。但此时由于新的参数被推入了数组,因此第一次运行时的while语句继续循环,弹出参数,返回accumulator(3,9998),这样不断循环,直至y小于0,最终返回结果。这样就很巧妙地将“递归”改成了“循环”,而后一轮的参数会取代前一轮的参数,保证了调用栈只有一层。

尾逗号
ES2017 允许函数的最后一个参数有尾逗号(trailing comma),样的规定也使得,函数参数与数组和对象的尾逗号规则,保持一致了
function clownsEverywhere(
param1,
param2,
) { /* ... */ }
clownsEverywhere(
'foo',
'bar',
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

