
- 1华为官方鸿蒙模拟器使用方法_鸿蒙next模拟器
- 22023年AI十大展望:GPT-4领衔大模型变革,谷歌拉响警报,训练数据告急_人工智能未来十大趋势
- 3LLM时代,数据为王,19个开源数据集下载网站汇总_开源数据集网站
- 4shp格式详解(一)_shp文件中有成像时间?
- 5leaflet 点聚合(点击后散开)
- 6vscode开发常用的工具栏选项,查看源码技巧以及【vscode常用的快捷键】_vscode如何查看vue3项目源码
- 7明天就是5.20,这几个c语言表白代码发给你喜欢的女生,要是还没有女朋友直接来找我!!!_发给女朋友的代码怎么运行
- 8安卓系统如何升级为鸿蒙系统,4部荣耀手机可升为鸿蒙系统,有你的手机吗?花粉的春天来了!...
- 9人工智能之ChatGPT专题|ChatGPT 算法原理_chat gpt人工智能培训
- 10Windows C++程序崩溃时自动生成 dump文件_windwos 崩溃堆栈
3原理+1揭秘,将Sora拉下神坛
赞
踩
(偶得半日闲,码字于甲辰年元宵,鞭炮声声入耳。原创声明:欢迎转载,需注明出处。)
毕业以来,一直深心认同校训“求是创新”。从事这个行业,见到太多把概念神化,然后不能落地的事。小则浪费点刷手机时间,大则误导很多决策者和创业者方向。
如今,Sora也是,短短两周,在某些自媒体专家嘴里已经成为“可以改变世界的里程碑”,甚至是“标志着通用人工智能AGI的实现”。改变世界??AGI??这两个词,连OpenAI自家的新闻和论文,也只敢吹吹说打了个基础。甚至有专家疾呼,这标志着我国AI落后一个级别。
我的天,不行了,该说话了。
这些情况愈演愈烈,让我明白,需要有人清醒的扔出一个石子,抛砖引玉,期待更多的行业高人来以正视听。
那么,这些夸大或误读的根源来自于哪里呢?
我的朋友和我说了这些话,和现在媒体中报道的说法很相似。
根源就在这里:他觉得Sora的能力让人惊叹。影片很高清,Sora生成的各个场景,包含海水、雪中小狗、眼镜上的反射影像等等,可以吻合常识、吻合物理规律。好些人惊叹的是,它对物理世界的很多描绘符合我们常识里对世界知识的认知。也有人赞叹,看Sora不要看表面的东西,要看背后它能真正理解我们对这个世界的物理定律的隐含。
这一点怎么做到的?但似乎,它确实做到了。那些绒毛、雪花、波浪,完全跳过了之前CG实现的种种难关,降维打击,对世界理解一步到位。
问题就在这里了,我们以为Sora已经聪明到:
可以理解整个世界和诸多物理细节,常识及定律
并有无穷的创意
直接超越物理渲染,做出1080p的影片,现在就能满足我们各行各业的应用。
事实上,No,No,No。用大白话说下结论:
从原理上,Sora只会两件事,“抄”和“猜”。
Sora从来都未曾真正理解世界和物理法则、甚至逻辑,它也不关心,只关心概率。
这在第二节会从它的底层原理Transformer+Diffusion简单直白的说明。
那为什么Sora如此惊艳?高清?稳定?秘诀在哪里。
有明面上的三大优势,见第三节。
但在“稳定”这一点上,确实OpenAI也藏了个心机没有说,目前我好像是第一个说出来的,哈哈。看第三节最后一点。
Sora只是量变,离质变还差很远。
所以Sora的错误率和局限,超出你的想象。当下能看到落地应用的靠谱玩法有3个。
差距远远小于部门国内外媒体的夸大,别自己吓自己。
AI竞争才到中场而已,弯道超车的机会存在着。
国外一些清醒的学者,也清楚的表达了自己的意见和分析。如下图Yann LeCun(ACM图灵奖得主,纽约大学教授。Meta首席人工智能科学家)针对Sora的评论。大意是:
让我在这里澄清一个巨大的误解。从提示文字,生成看起来相当逼真的视频,并不意味着,这个系统理解物理世界。生成一个视频,和基于世界模型的因果预测,大不相同。目前这种生成式的方向,代价高昂,可能还有更好的法子。
(原文AI翻译附在文末)

一、用AI魔法破除魔法
Sora所生成的影片真的理解和模拟了真实世界么? 我们看一下,Garbor用Google的Gemini Ultra 1.5 pro分析一下Sora做出来的影片,一下子发现了大堆的不合情理的地方:

Gemini Ultra 1.5不客气的,对抢了自己风头的Sora提出了批评:
这日本雪景街道视频可能是一个由人工智能生成的。其中几个不一致之处:
1.雪虽然下得很大,但樱花仍然盛开。樱花通常在春天开放,那时气候温暖,不会下雪。
2.雪以非常均匀的方式下落,这并不是雪在现实生活中通常下落的方式。
3. 视频中的人们没有穿任何冬季衣服,即使雪下得很大。总的来说,视频在视觉上很吸引人,但这些不一致之处表明它并非真实生活场景。
事实上,我们人类更加挑剔,这段视频的一开始,两位行人的身高已经高过房檐了,然后迅速诡异的缩小。这已经是足以翻车的硬伤了。Sora也完全承认这一点,所以也给出了漂浮的椅子等bug视频。然而,只要仔细看看,即使是放出来的好的样例中,也有诸多硬伤:雪中小狗,也有凭空出现的背景狗头。更不用说,吹不灭的蜡烛,和静止不动的火苗。
下面这段小视频,更可以完整的展示,Sora其实不懂得流体规律、破碎轨迹和重力影响。那么高清,又有什么用呢?

让我们做一个合格的行业思考者,回到Sora其实并不聪明的现实,了解一下它蠢萌蠢萌的原理。
二、3个原理,明了Sora时好时坏的背后原因
Sora的官方文章,基本上在强调如何生成视频,以及其中的难度和优势。没有介绍Sora生成的步骤和原理。
步骤
简单而言,从一段文本生成视频,大约经过如下几步。
第一步,语义理解 (基于GPT,和DALLE一样)
第二步,生成图像 (基于Diffusion)
第三步,通过图像序列生成视频 (基于Diffusion,Transformer在时空小块图像上做:这儿有一个小秘密,见第四节)
听起来很高大上,用大白话解释一下整个过程。
Sora原理大白话
(声明:以下是向非专业读者解释的,就好比对你们的女朋友解释。别和专业性对上,只能大概意思一致即可。)
如下大白话说一下原理:Sora实际上,主要就是靠“抄”+“猜”。
一、准备工作
在用文字生成视频之前,得让Sora搞清楚哪些文字对应哪些视频。为什么?因为它根本不懂。只能靠人告诉他哪些词,对应着哪些视频。所以,要搞来巨量海量超量的视频,让Sora记住。一个巨巨...巨大的视频库。
(怎么记住呢,告诉Sora一堆词来描绘里面的内容,再把画面割成一块块,一帧帧。扔给这个孩子,自己去联想这一堆词和这一些时空碎块的联想。)
二、开始通过文字生成视频了
写一段文字,Sora会靠它老大GPT详细解释给他听。我们也许就写了“散步在夜晚东京街道上”,GPT要发挥想象力,联想出一堆词和关联“高楼”、“繁华夜景”、等等。它联想力越丰富,Sora能关联到的时空碎块就越多越准。
Diffusion此时作为一个画师,上场了,他根据关键词特征值对应的可能性概率,在视频库到处翻,看看抄哪一个碎块比较像,看哪个像,就猜对应的下一笔要落在什么地方。重复很多步。
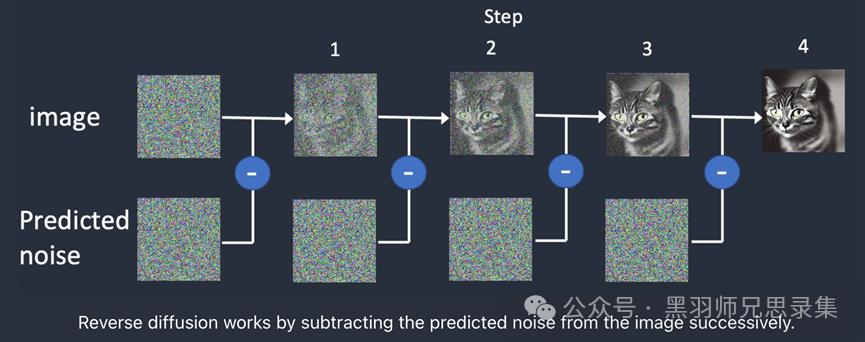
通过Diffusion和Transformer共同联想,死记硬背,从巨大视频库里生拉硬拽,配合着一点点小秘方(见第四节),把这些一张张碎块拼成图,再拼接成一个序列,每秒播放几十张,视频就出来了。
所以啊,Sora是靠着“抄”人类喂给它的巨大的视频素材库,根据提示词的分解和联想,“猜”哪个关联大,就用哪个来画出来。
当你说“可乐波浪里的小船时”,它压根不懂“波浪”是怎样的流体物理,只是从库中找到这样的片段,再结合上“可乐”这个词所对应的视频碎块,通过Diffusion混在一块的。
所以,严格说,只是像素层面的混合,背后的抽象原理、物理法则、食物常识它是完全不理的。这也是图灵奖获得者前面的批评所指出的。
这样,Sora时好时坏的原因找到了,调教它的路子也出来了
简而言之,能找得到,有的“抄”,大概率能生成的好。如果能抄的素材特别多,那么描述的越准,那么Sora“猜”的范围就越小,画的也就越精准。
如果你描述的一段话,恰好和它要“抄”的视频库里某些素材段很一致。那么太好了,Sora猜的舒服轻松只要小改几笔。生成的视频那基本上,从规律到细节都没跑了,挺好的,挺真的。好比,你早背好了几篇小作文,考试时恰好蒙到了一篇,那小改改直接就出来了。
所以,Sora那个东京夜街头散步,以及那个猫猫抓主人,甚至小改改的红毛线帽高清视频,为什么质量那么高,大概也应该明白了吧?啊?这不是作弊么?er......还是改了几笔的。
突然有人说,不对哦?那个海豚骑自行车,不可能有这样的视频啊,那为什么能做出来呢?
这就涉及到Sora记东西,和我们人记得可不一样。我们记得是整个画面和逻辑,就是图灵学者说的抽象层。而Sora记得只是碎片的特征值,鬼知道他们怎么联想的。简单而言,只要能生成静态图混合的,视频混合就没有问题。这和MJ和Stable Diffusion生成混合图的原理一致。虽然,现实生活中没有海豚骑车。但是海豚和骑车,这两个词所能联想的素材还是很多的,混合一大抄就好。这样的视频,对Sora是容易的。
那如果没有对应的词呢?那就靠Sora老大GPT来发挥联想力了,看他如何解释这个新词。
比如,你说“生成一个阿凡达爬行的视频”。
假定,视频库里没有阿凡达这个词,且和阿凡达对应的视频片段。那么,就看GPT怎么解释了,如果它解释成“蓝皮肤+人形+爬行地上”,那Sora只能出来个蓝皮肤的人,在地上趴着。
如果GPT勤快点,根据自己的庞大的联想库,详细解释成,“蓝皮肤+身高2米+有猫尾巴+像人+面部像猫和人脸结合体+无毛+有小斑点+长发脏辫+蓝色树丫上+爬行...”,那么Diffusion就能基于人、猫、蓝色皮肤等等对应的素材,一边猜一边拼,画出一个接近阿凡达爬行的真实片段
所以,调教Sora出好视频的关键技巧,也就出来了。
不断精调提示词(Prompt),当然你可以把工作丢给GPT去细化联想。但如果你要越来越细的把控出品的品质,就要让Prompt尽可能的详细,精准。Prompt越详细,就能缩小Sora猜的范围,做的越好。
但是,同理不同的Prompt,也会限制Sora能抄的范围。如果你的视频是比较日常的,或者正好是Sora库中涵盖的,那么大概率能得到不错的结果。
三、那为什么Sora这么强,比Pika等要好那么多?3个优势+1个揭密
理解了Sora的原理,自然就明白了为什么Sora会比Pika强很多很多。
Sora实际上对于Pika等,只是量变,都是差不多的技术和原理,没有质变。(除去那个小秘密外)
但几乎达到了近似质变的效果了。原因在于:
优势一,视频预训练库的量大质优
大力出奇迹,是OpenAI的基因。
到底花了多少钱在高质量的视频素材上,搜集了多少的视频库,只有OpenAI自己知道。但可以肯定的是,远远不是Pika等创业团队所能比的。
记得多,才能抄的好,混得妙。
甚至,现在的视频量已经不能满足OpenAI的需求了。已经被爆料,OpenAI的视频库,大量使用了UE5生成的视频来做补充和训练。我们看到的赛车那个视频就是。
甚至,我们可以看到一些证据,Pika、Runway、Stable Video和Sora有时候会撞车:都使用了同一个素材加到库中。那么使用一样类似的关键词,可能就能调出一模一样的元素。
证据如下,Garbor兄使用东京赏樱的提示词,在Pika、Runway、Stable Video和Sora上一起跑,你会看到:天呐,怎么右边的房子和远处的背景完全一样,构图也类似,哈哈。
大家一起抄作业,一起穿帮了。

优势二、算力多,采样步骤多,更精细。
这张图说明了,不同采样和计算步骤后,通过同一个视频库“猜”的步骤越多,加的东西越细,效果越好。做32倍运算的效果,就明显好于4倍的效果。
还是大力出奇迹,OpenAI不变的配方和味道。
那么请问,Pika等创业公司能有多少张GPU卡呢?
Sora能土豪的用32倍,1080p,渲染1分钟的视频。创业公司能用多少,4倍,360p,4-8秒,已经足够把钱烧光了...
画面精致度怎么比?时长怎么比?不公平。
 (图片来源:OpenAI)
(图片来源:OpenAI)
优势三、GPT解释力更强,提示词(Prompt)表现更好
前面说了,对一段提示词或提示句子,GPT能展开的联想和丰富度,是决定了Sora抄什么,能猜多准的。
OpenAI的GPT能力天下第一,开源模型无能撼动。
所以,不幸的是,Pika等创业公司大多还是要依靠OpenAI的GPT能力。
那么,问题来了,亲儿子能用的,一定胜过外部客户能用到的深度和广度。
第二个点,就是外部公司的视频库和GPT联想能力不能首尾配对;但是Sora可以啊,GPT是自家的,视频库也是自家的,两者直接关联的精准度以及调取的效率,完全是外部客户不能比的。
一个揭秘、为什么Sora图像的稳定性、连续性明显好
这是黑羽师兄的独家发现哦,目前内外网都没听人提到过。:)
我们看到的是Sora在保持画面物体固定、部分主体稳定性、乃至旋转等都能很好的稳定展现。这个已经远远超过当前Pika、Stable Video等纯粹基于Diffusion模型所能带来的能力了。
Diffusion的不稳定性通病,在Pika等产品中已经表现无疑。
Sora和他们完全不在一个层次上,稳定性很好。已经不能完全用数据和算力来解释了。那么,一定是采用了一个能增强连续性的技术。
不知道大家还记得这个DragGAN工具么?通过一张图,就可以实现不同主体的各种动作。
它采用的就是GAN(对抗式生成网络技术),这个可以大幅度的预测和生成下一张图。这个技术的原理,和Diffusion不同,这位画师训练自己的方法是,平时每画下一笔,都和原图对一对,如果自己画的对,就给自己打高分。就这样不断磨练自己的技术。对于GAN,我在2021年就有所接触和运用,一直对它能"借真修假”的本事,念念不忘。
这样的技术,岂不是特别适合结合视频来生成每一帧不同主体微妙的变换。更关键的是,GAN在一些场景下的因果推理能力,是比Transformer、Diffusion都好的。
我仔细观察了不同Sora范例的旋转和下一步变化,猜测大概率使用了GAN技术的结合。后面又读到了,它论文有些话强调连续性和模拟上,也给了我一些信心,证明我的想法可能是对的。
直到,我找到了Sora团队的人员简历和分工,看到了实锤证据。他们人数并不多,大部分是Diffusion和Transformer的工程师,有些是从DALLE过来的。但有一位核心人员,很有意思,各位看官,请看:GAN的高手。
 (图片来源:量子位)
(图片来源:量子位)
看来,Sora已经找到了一些方法和方式,将GAN的优势和Transformer,以及Diffusion结合起来。这真是一个非常不错的进展。不管他们采用了什么新名词DiT,就是不提GAN;但本质的原理在这里,GAN闪闪发光。
Sora既然没那么神,那么可以用在哪里?
元宵节有空,一口气码了这么多字,实在写不动了。简单说说吧,如果点赞的人多,我再单独发文说说Sora和典型行业的结合玩法。
之前,看到很多人说这个行业也可以用,那个行业也可以用。
对不起,不可能!只有不需要严谨的视频输出的行业,是可以使用的。
但凡,想用它来生成连续的视频成品,都要付出巨大的努力。
Prompt提示词的运用门槛,会高出你的想象。这将成为一个专业分工。不会专业的Prompt,只依靠Sora的GPT自我发挥。那么,请做好抽奖的准备,可能要生成很多很多次,才有一次抽到好作品。时间怎么办?
商业运用上直接用基本不可能,但是可以间接使用。
第一个用法是,可以用它来生成创意素材。通过剪辑和局部使用,做出自己的成品。对于自媒体行业是一大利好。
第二个用法是,特别适合用来生成概念片和内部讨论稿,极大的加快创意沟通的效率。
第三个用法是,利用它的连续性,结合一些3D工具,快速建模。这个已经有人在做了,但效果还待改进。推荐大家看看B站UP主设计师的AI工具箱的Sora建模实践, 调试的好,是个路子。
结语和展望
作为一个在虚拟空间和人工智能行业的创业者,我特别喜欢看到像Sora这样能带起一波浪潮的技术应用。但是,我又深深地为我们每次过于神化一些新技术,感到担忧。
每个技术都有它适合的应用场景和toB、toC刚需,要切合实际,求是创新才对。现在,人云亦云者多,入泥入水者少;缺乏深度的行业思考者。
Sora才刚刚起步,不要捧杀了它。更不乱吹一气,灭了国内AI技术同仁自己的威风,我们的大模型底层进展还不错的。这些应用领域,弯道超车的机会存在着:不仅在算法、软件上;硬件也存在。
从来就没有万灵药,哪怕是现在的ChatGPT也是一样,它的幻觉问题一日不解决,谁敢放心的把严谨的工作交给它。
(关于ChatGPT的应用局限和行业落地应用方式,还有弯道超车的机会点;如果大家感兴趣的多,后面有空再写,一同探讨。这也是我在新年开设这个黑羽师兄Blog的原因,交志同道合的朋友。前沿行业一起探索,需要深度的思考者互相激发,也需要一起呐喊出来,正本清源。)
Sora,也许正站在量变引起质变的十字路口上。但也有可能,它的路线是错的。后来而上的抽象式理解模型,或者真正AGI会让它看起来非常可笑、笨重和成本高昂。这么多伟大的可能性,都在涌现。这真是个不错的时代。
附录:Yann LeCun(ACM图灵奖得主,纽约大学教授。Meta首席人工智能科学家)推文的AI翻译,翻译质量一般般:
让我在这里澄清一个巨大的误解。从提示句子生成看起来相当逼真的视频,并不意味着系统理解物理世界。生成和基于世界模型的因果预测大不相同。可能的视频空间非常大,视频生成系统只需产出一个样本即可成功。真实视频可能续集的空间要小得多,生成其中一块代表性的内容是一个更艰巨的任务,尤其是在基于某个行动条件下。而且,生成这些续集不仅成本高昂,而且完全没有意义。生成那些续集的抽象表示,消除场景中与我们可能想采取的任何行动无关的细节,这才更受欢迎。这正是JEPA(联合嵌入预测架构)背后的全部要点,它不是生成性的,并且在表示空间内做出预测。我们在VICReg、I-JEPA、V-JEPA上的工作,以及其他人的工作表明,与重建像素的生成式架构(如变分自编码器、掩蔽自编码器、去噪自编码器等)相比,联合嵌入架构对视觉输入产生了更好的表示。在未对主干网络进行微调的情况下,将学到的表示作为输入,用于训练下游任务的监督头时,联合嵌入胜过生成式。https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/

