
热门标签
热门文章
- 1se linux安卓,SELinux开关
- 2Mac M1芯片安装 MySQL_brew bundle dump
- 3对NovelAI的关键词的探索记录_novelai反向提示词
- 4Android绘图(一)基础篇_android 画图
- 5Android 多渠道打包的几种方式_android 根据已有apk打渠道包
- 6IDEA安装、配置及使用教程_idea csdn
- 7PyTorch实战案例(一)——利用PyTorch实现线性回归算法(基础)_pytorch教程实践案例
- 8AIGC:导航网站精选_aigc.cc/
- 9iOS 腾讯Pag动画框架-实现PagView的截图功能
- 10Entity Framework Core系列教程-24-使用存储过程_entityframeworkcore executereader 默认是否支持存储过程
当前位置: article > 正文
机器学习——神经网络压缩
作者:羊村懒王 | 2024-03-21 22:28:40
赞
踩
机器学习——神经网络压缩
神经网络压缩
需要部署,设备内存和计算能力有限,需要进行模型压缩,在设备上运行的好处是低延迟,隐私性。

目录

不考虑硬件问题,只考虑通过软件算法优化。
修剪网络
参数过多或者没有用的参数,可以将其剪掉。

先训练一个最大的网络模型,衡量评估每个参数的重要性,
- 看权重的绝对值
- 评估神经元的重要性,可以将其修剪掉
修剪后能力会降低一点,并想办法将性能变好一点,对小模型进行微调
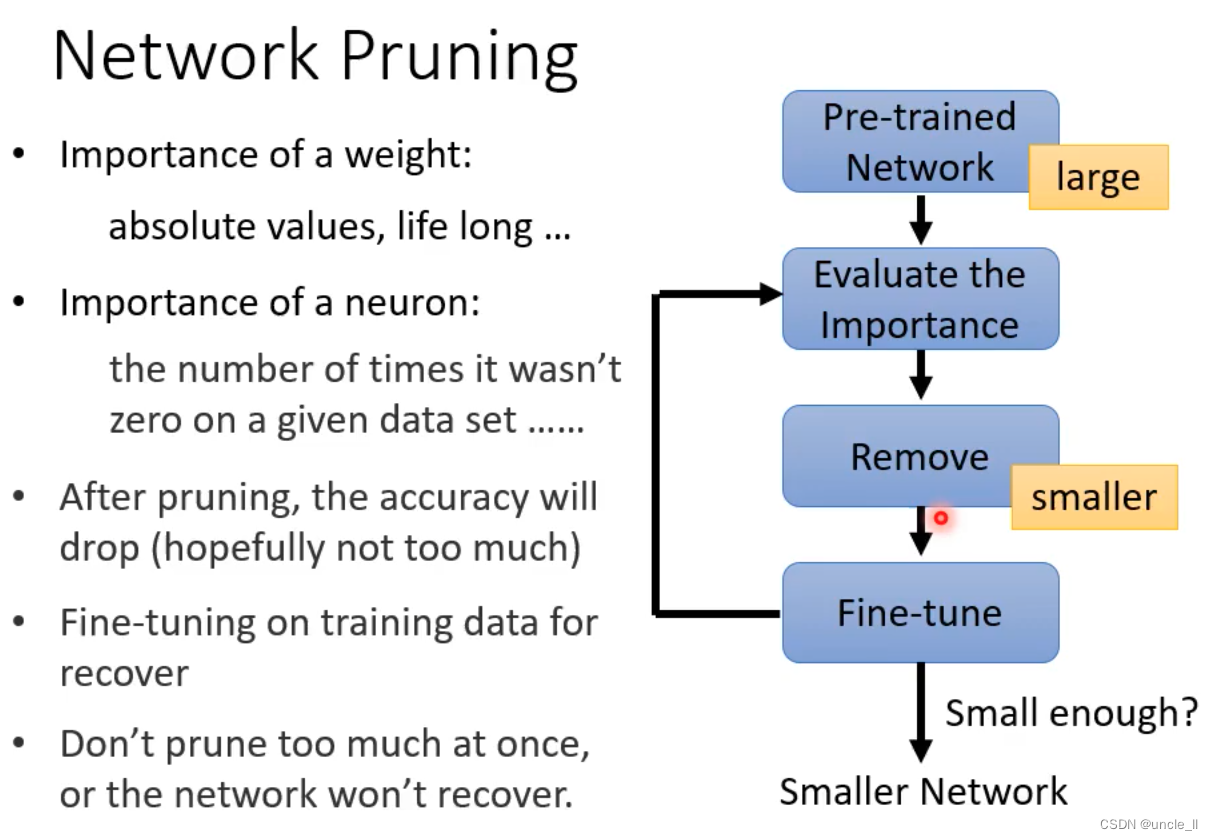
- 不要一次性剪掉大量参数
- 动了元气性能不太行
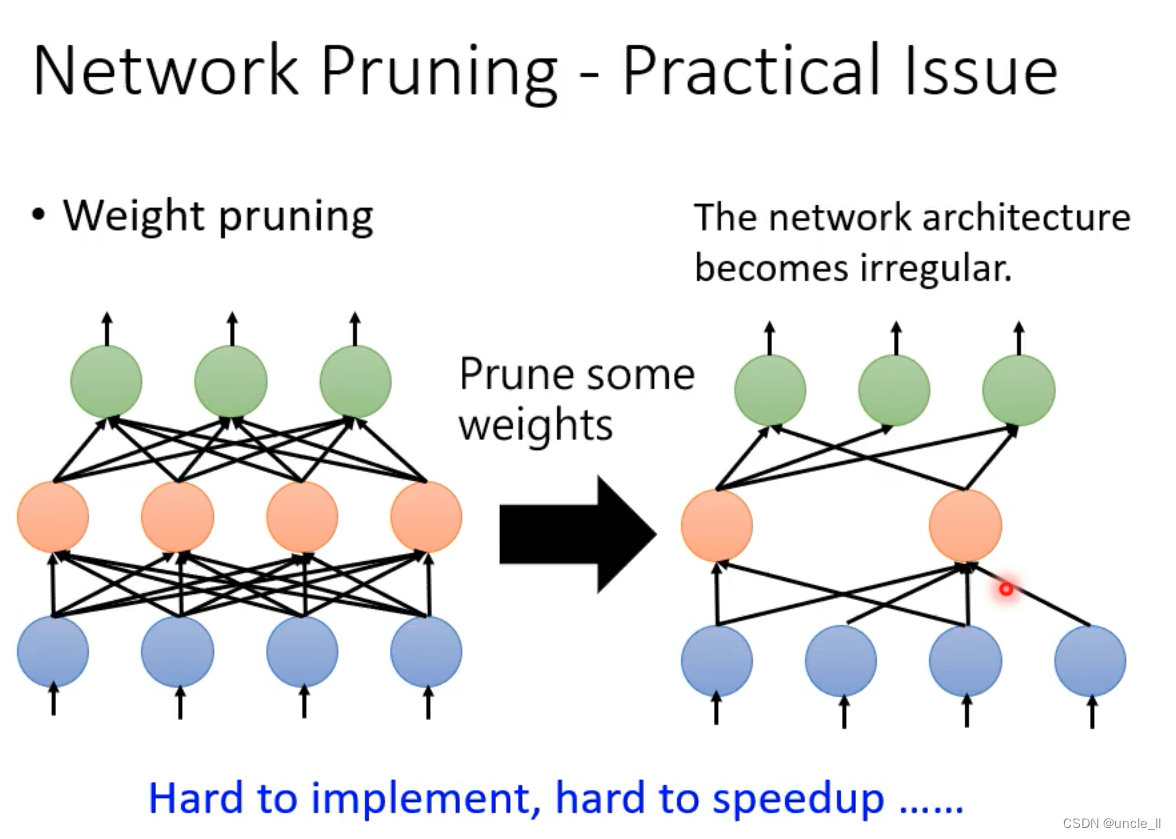
如果剪掉后,进行空缺的话导致无法进行GPU加速,一般将其值设置为0
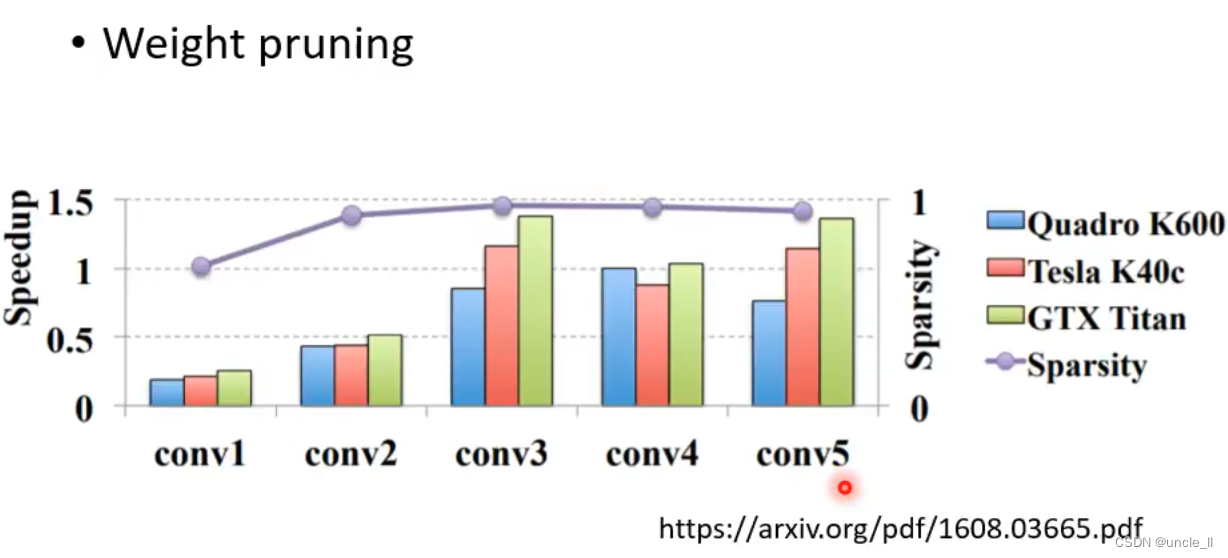
速度大于1是加速,小于1是降速。
从上述看到对权重进行修剪,加速的效果不理想。
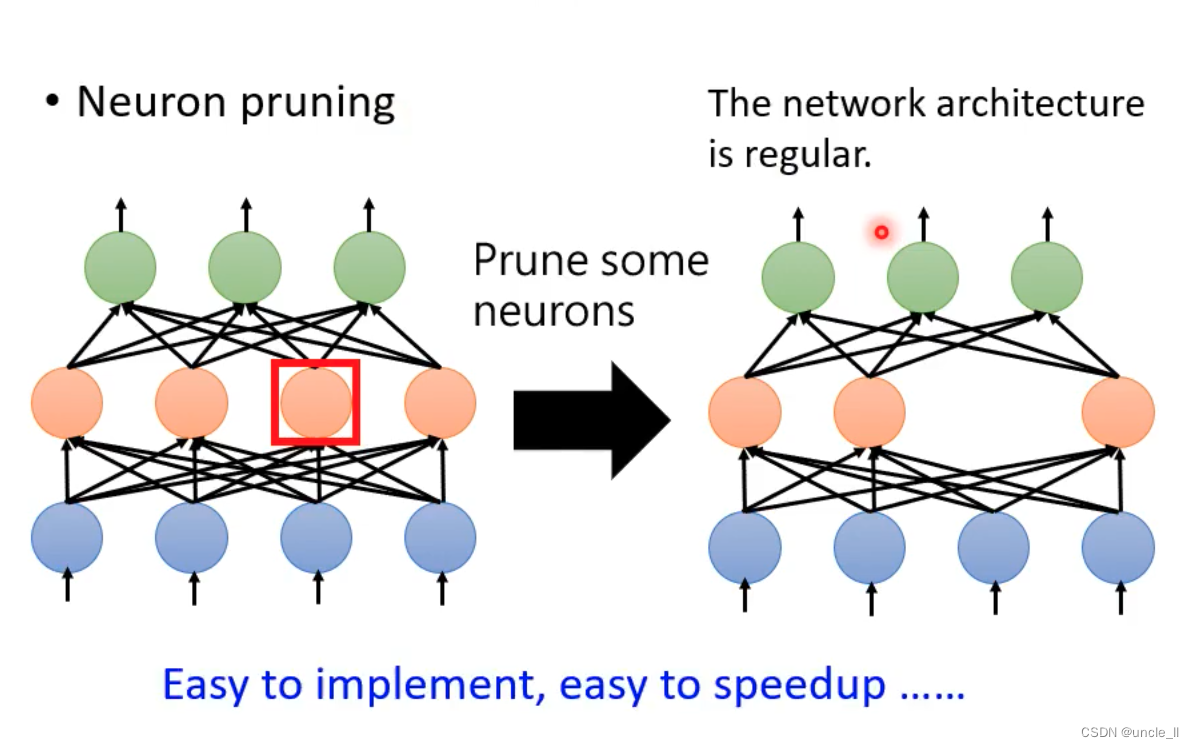
- 对网络进行修剪,只是改输入输出的dim,在torch里面好实现,gpu也好加速。

- 先训练大模型,再训练小模型达到相同性能,那为什么不直接训小模型呢?
- 原因是大模型更好训练,小模型难训练
- 大乐透假说
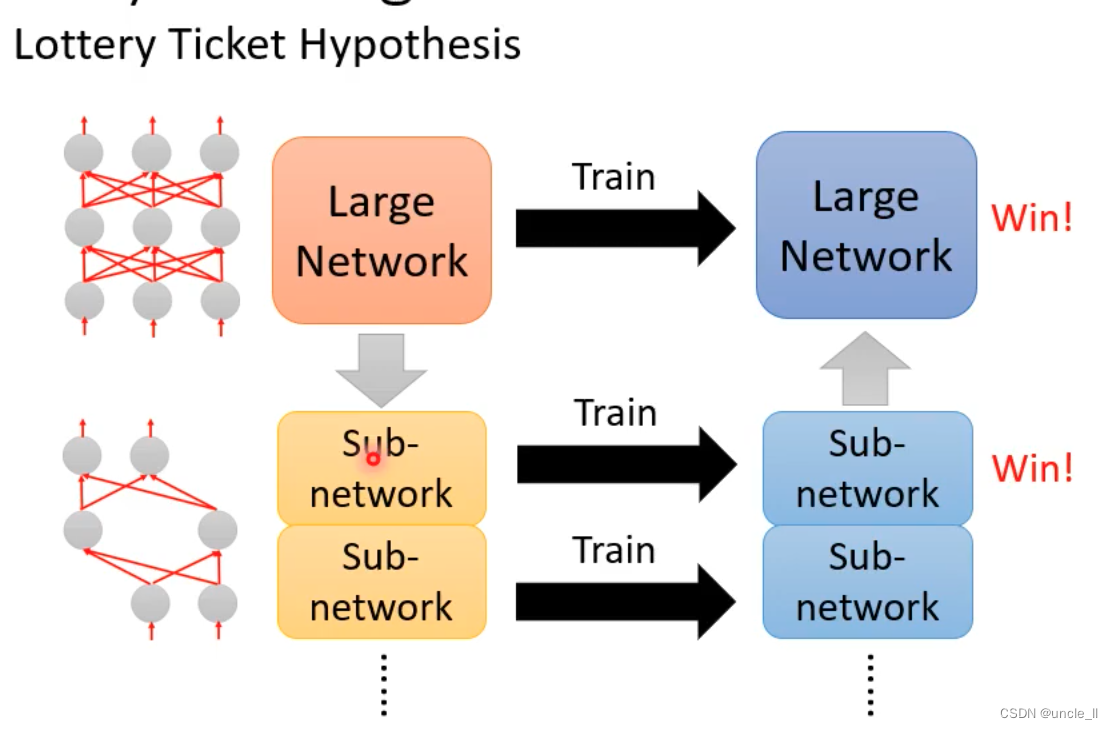
一个大的模型可以看作是很多个小模型的集合,只要里面有一个成功,大的模型也就成功了,跟买大乐透一样,买的彩票越多,越有可能中奖。
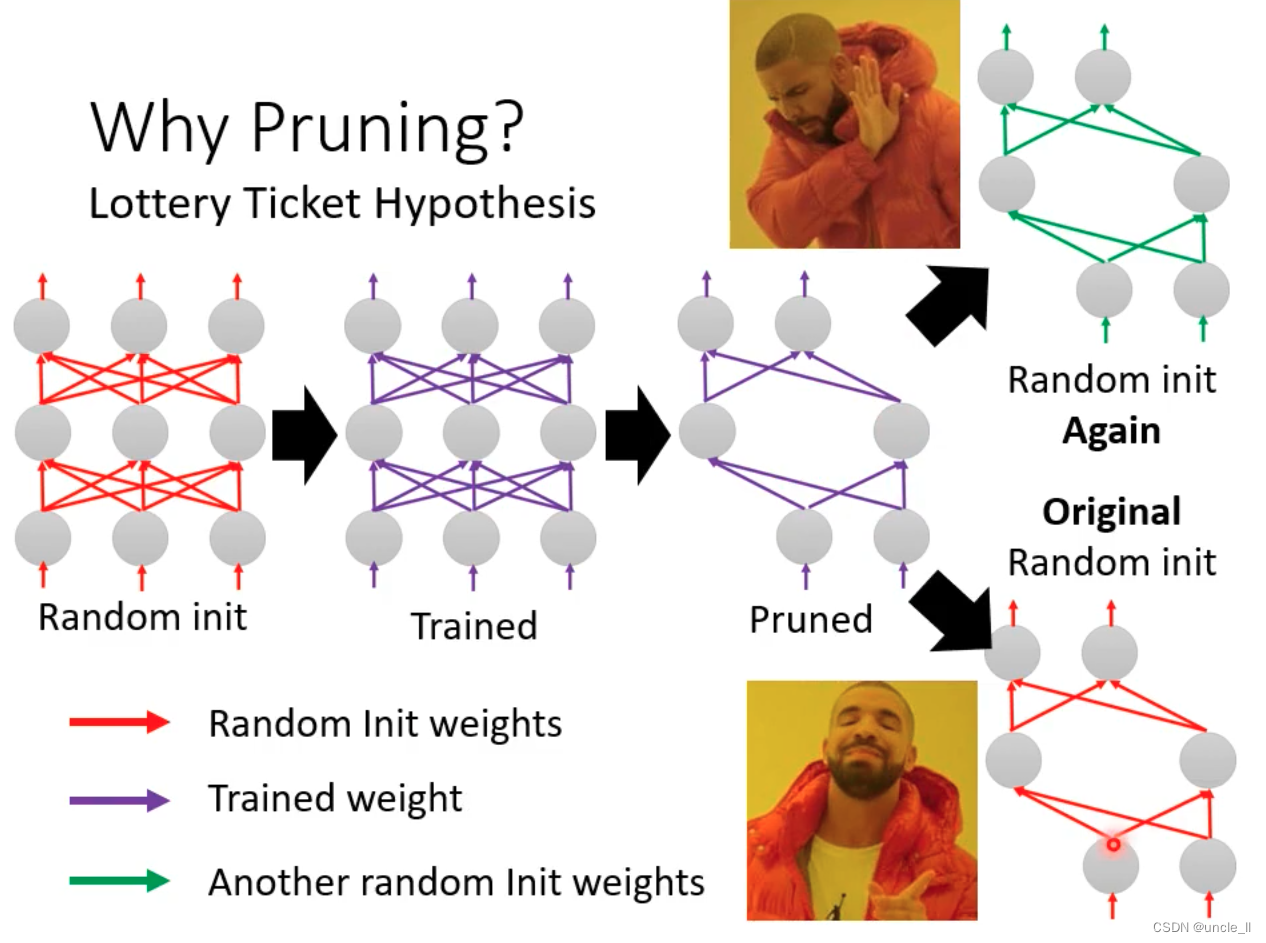
- 基于大模型得到的参数,更有可能得到好的初始化参数,在这个基础上继续微调,有很大概率得到好的结果。

- 权重的正负号很重要。
- 跟雕像一样,只是把多余的东西拿掉。
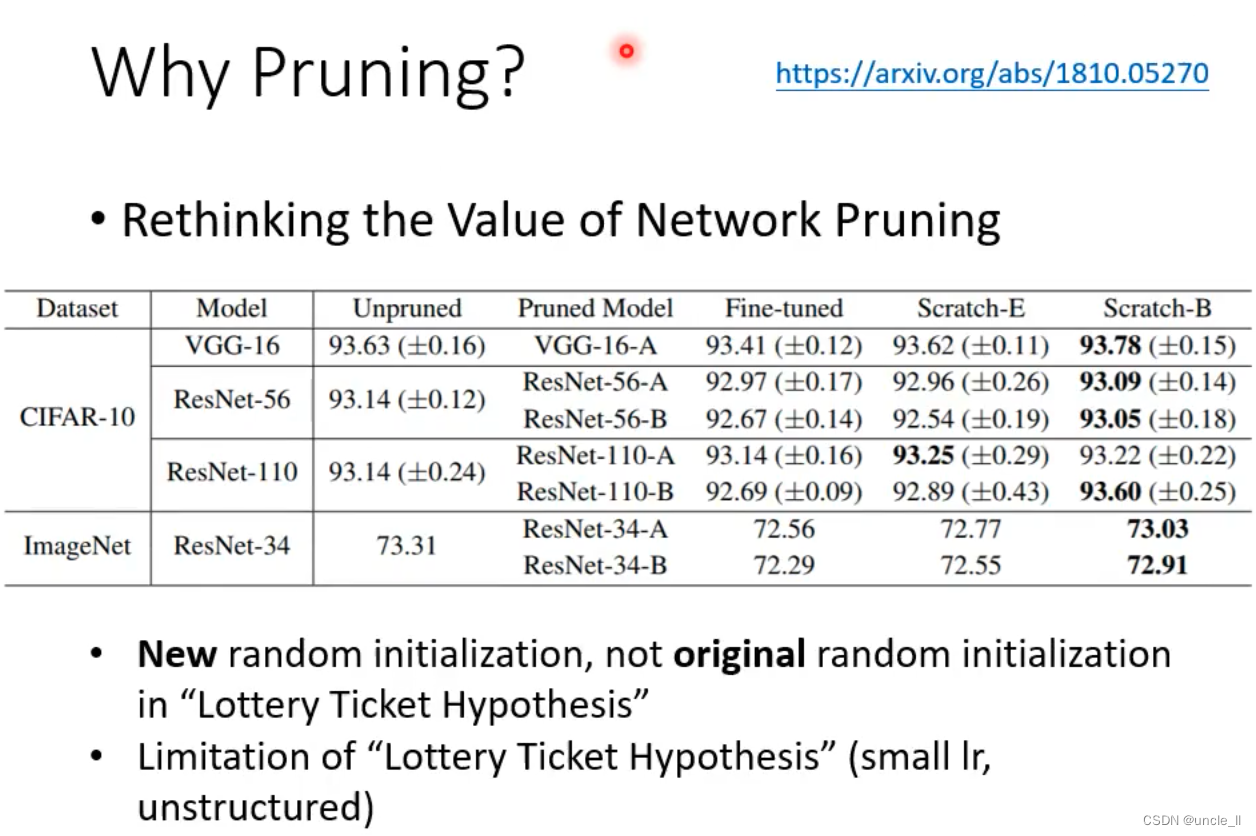
- 这篇文章打脸大乐透文章
- 将epoch设置多一点,小模型也能得到好的结果。
知识蒸馏
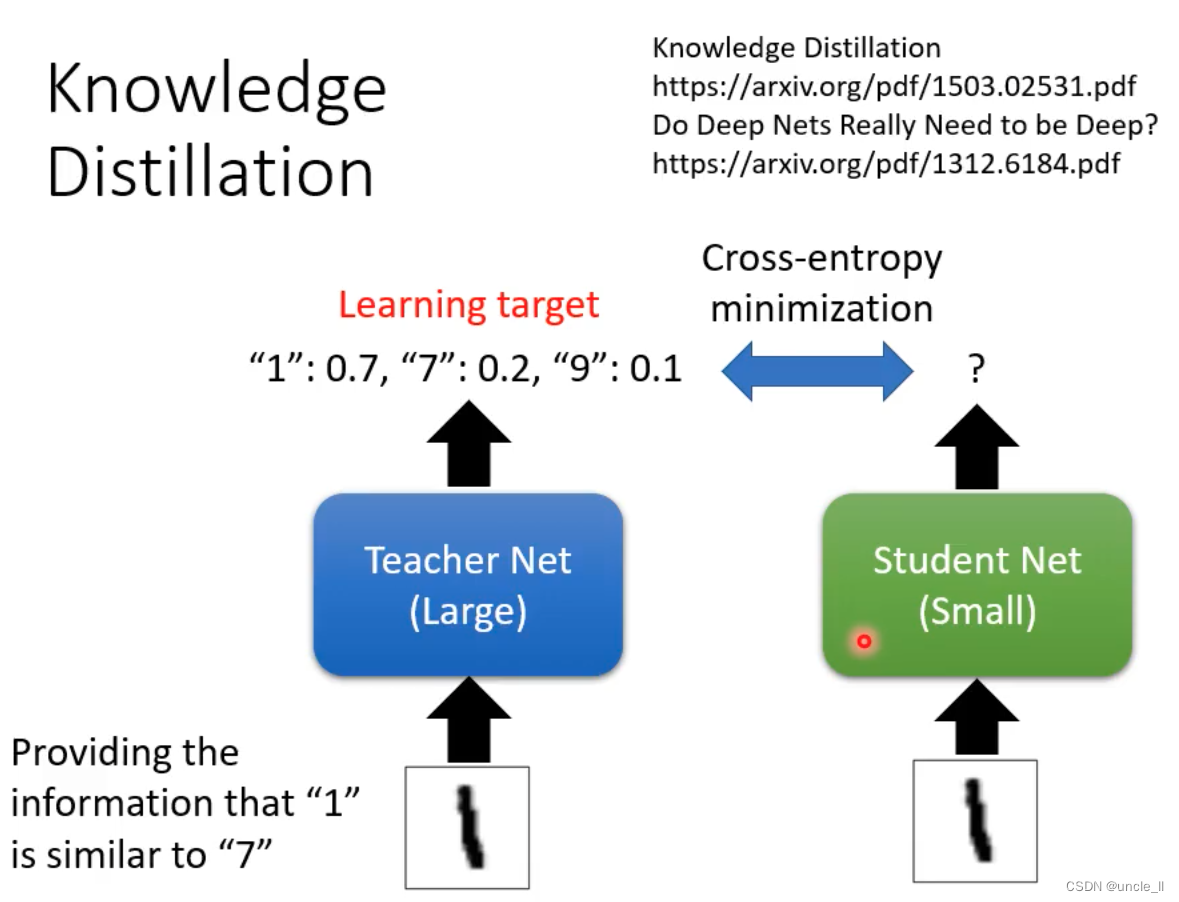
让学生的输出与老师的输出尽可能相近,哪怕老师的模型输出是错误的。

teacher不仅是一个模型,可以是多个模型的集成。模型集成在打比赛的时候用的多,但是实际中考虑性能问题不太行,因此可以使用知识蒸馏使得学生模型也能得到相近的性能。
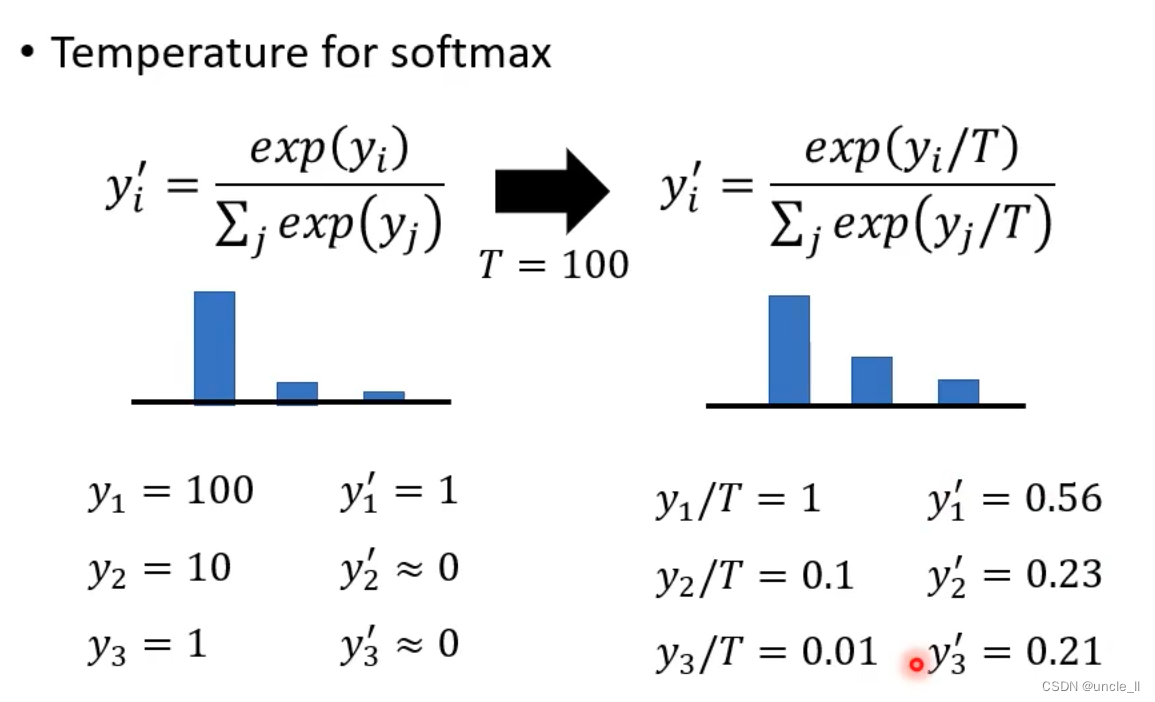
对softmax进行修改,增加一个温度参数T,把比较集中的分布变得更加平滑一点,对分类结果不会有影响,但是每个类别得到的分数会比较平滑平均
参数量化

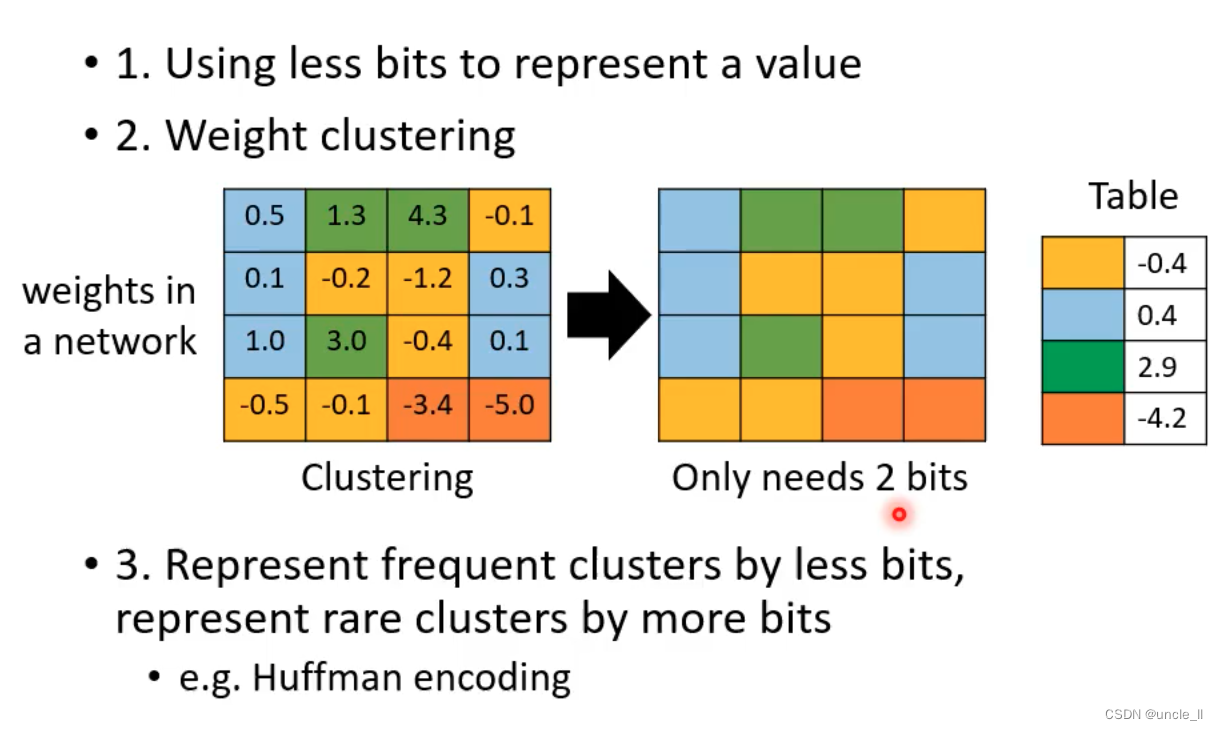
- 使用更小的bit来表示值,以降低存储占用
- 权重聚类,使用一类来表示该类的所有值
- 常见的用少量的bit,少见的用多一点的bit
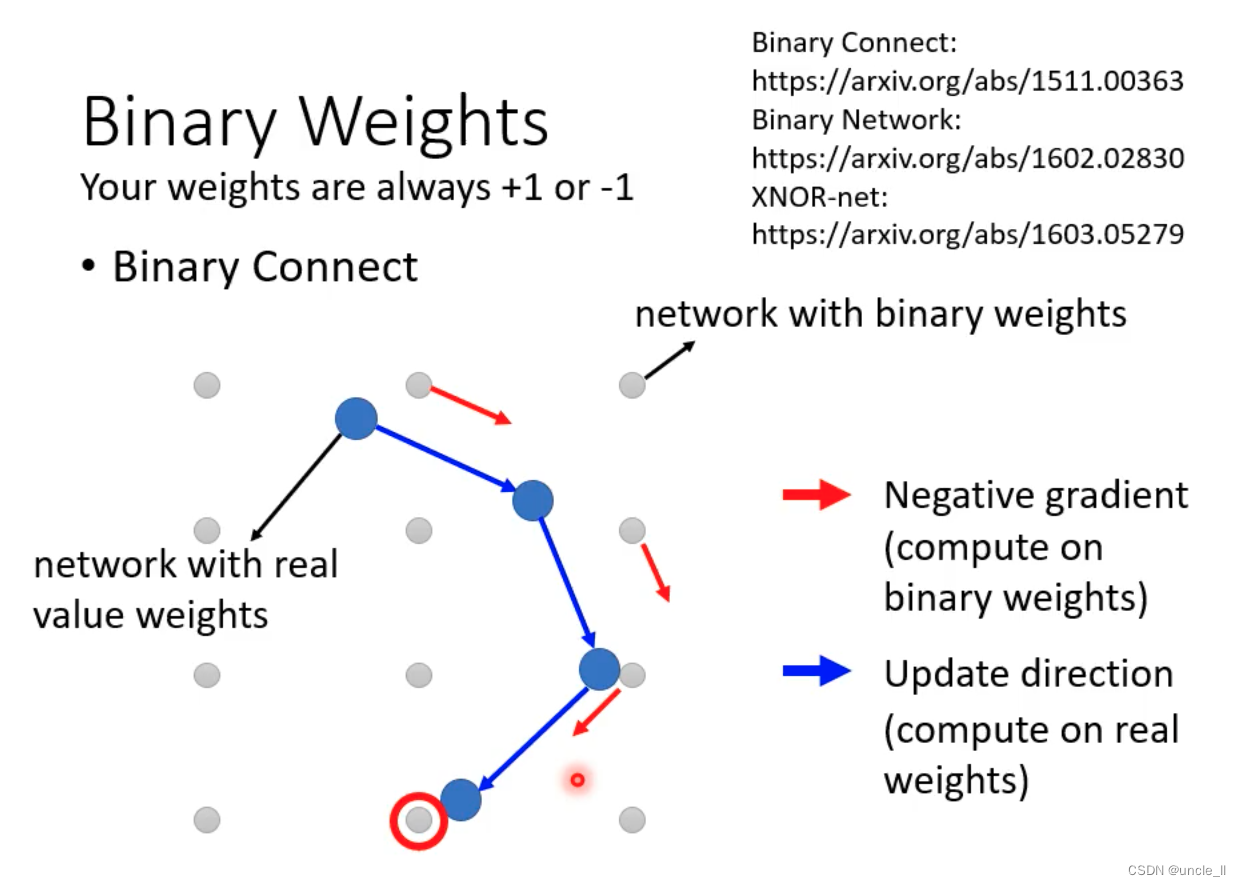
使用二元值代替
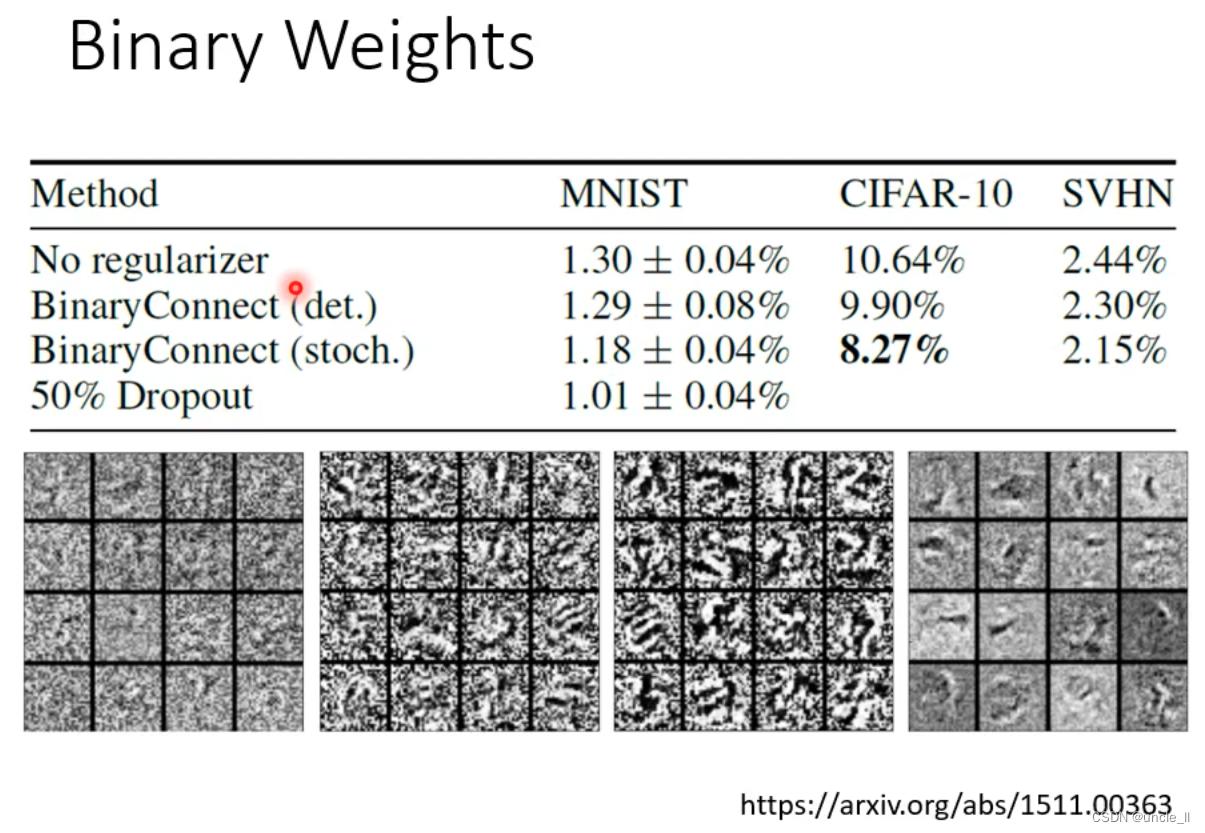
- 可以防止overfit
- bit减少是不是引入了噪声,进而效果好呢?
结构设计
depthwise separable convolution
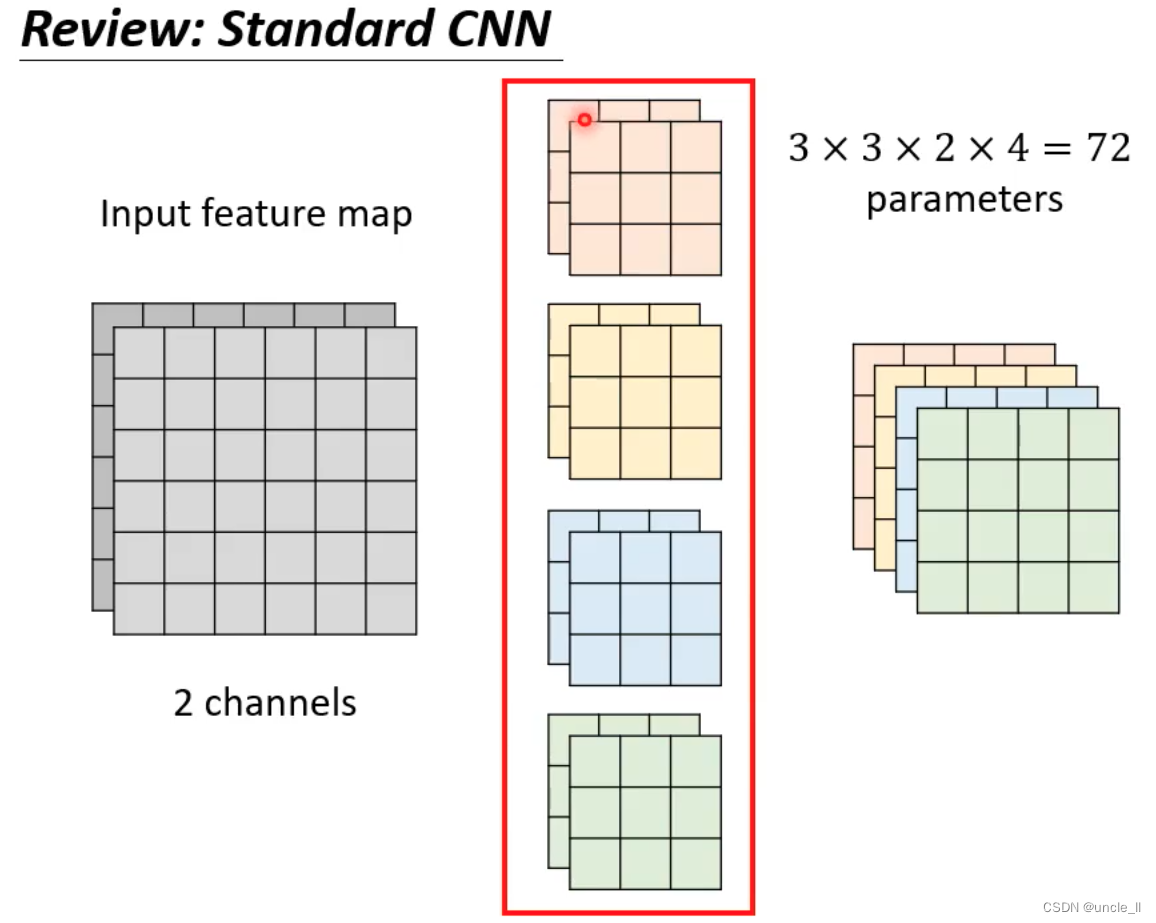
传统的cnn 每个通道都要进行卷积,参数量大。
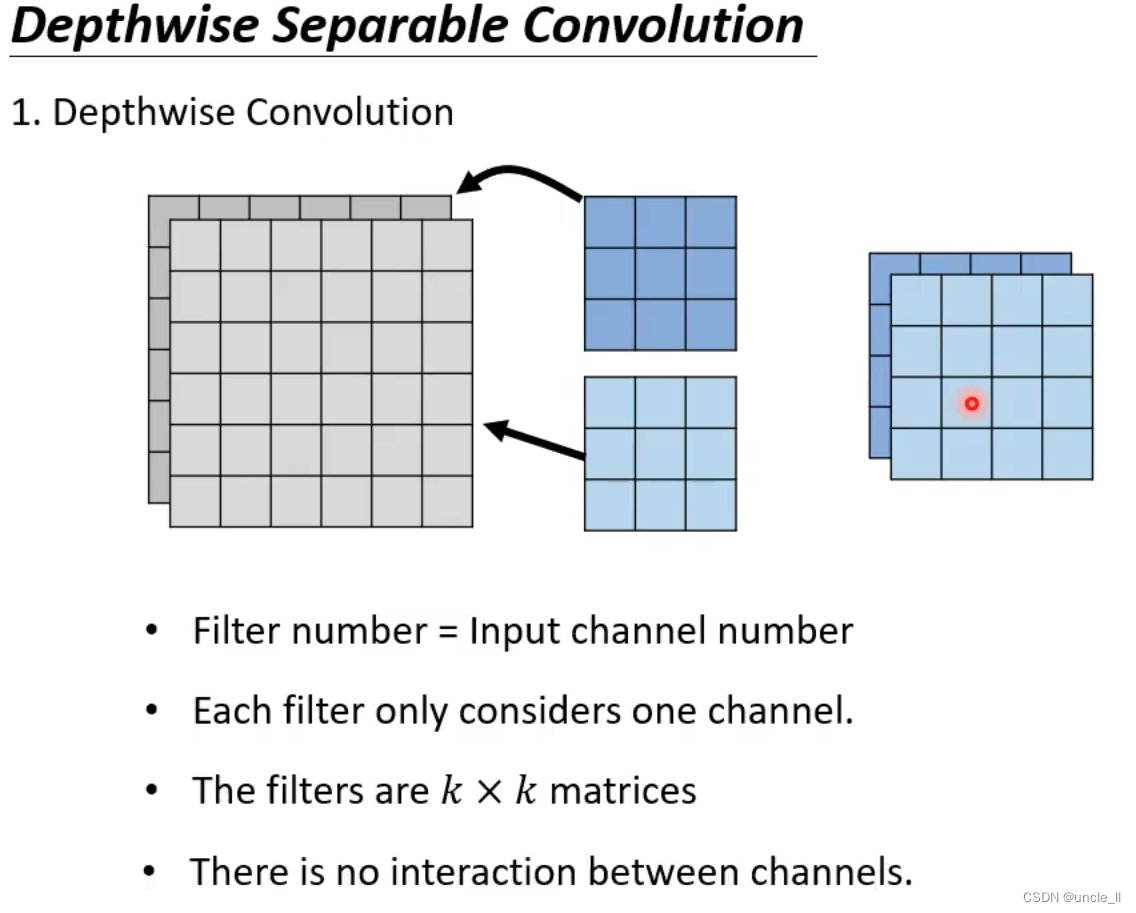
- depthwise的滤波器格式等于输入的channel数量
- 每个滤波器只负责自己那个channel
- 问题是通道之间没有交互
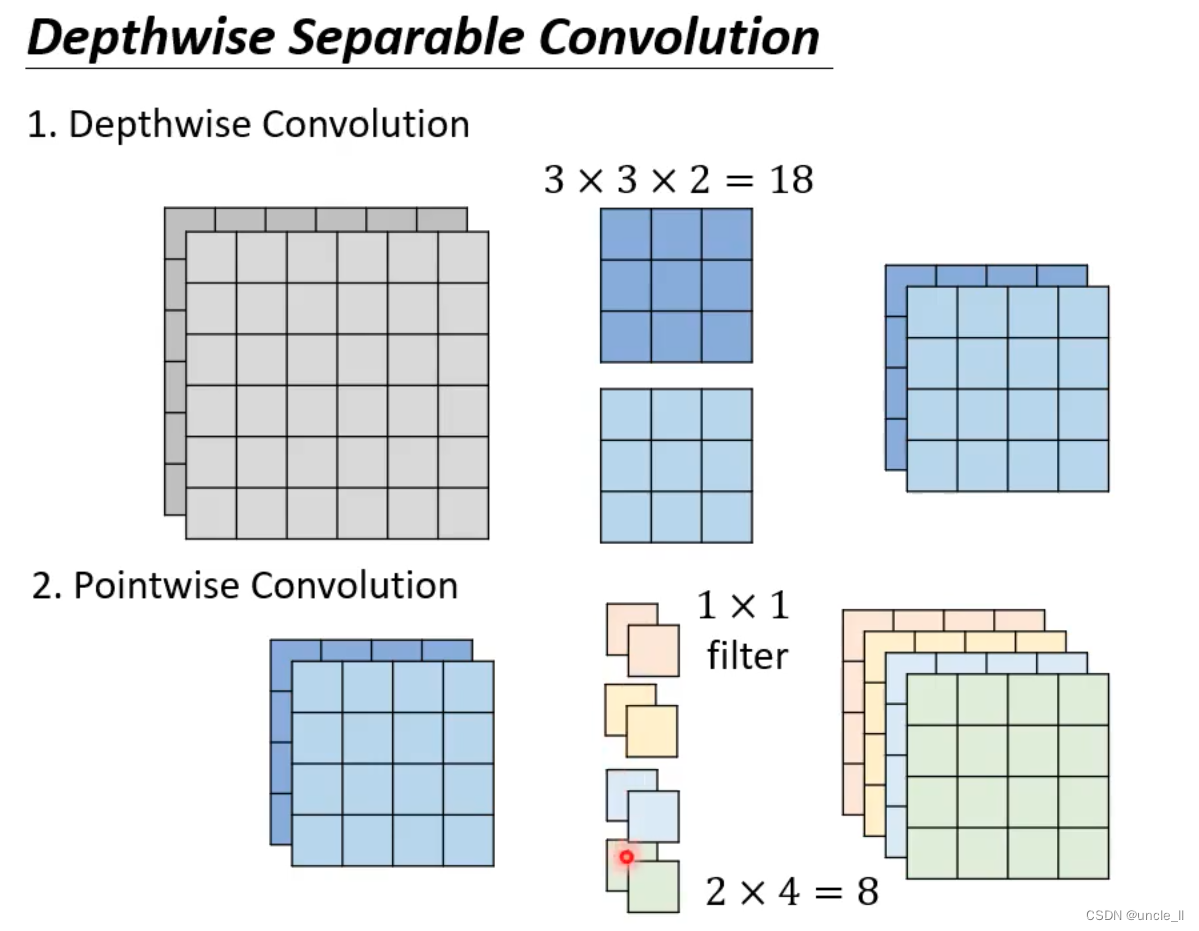
可以先加一个pointwise convolution,然后再进行depthwise convolution;
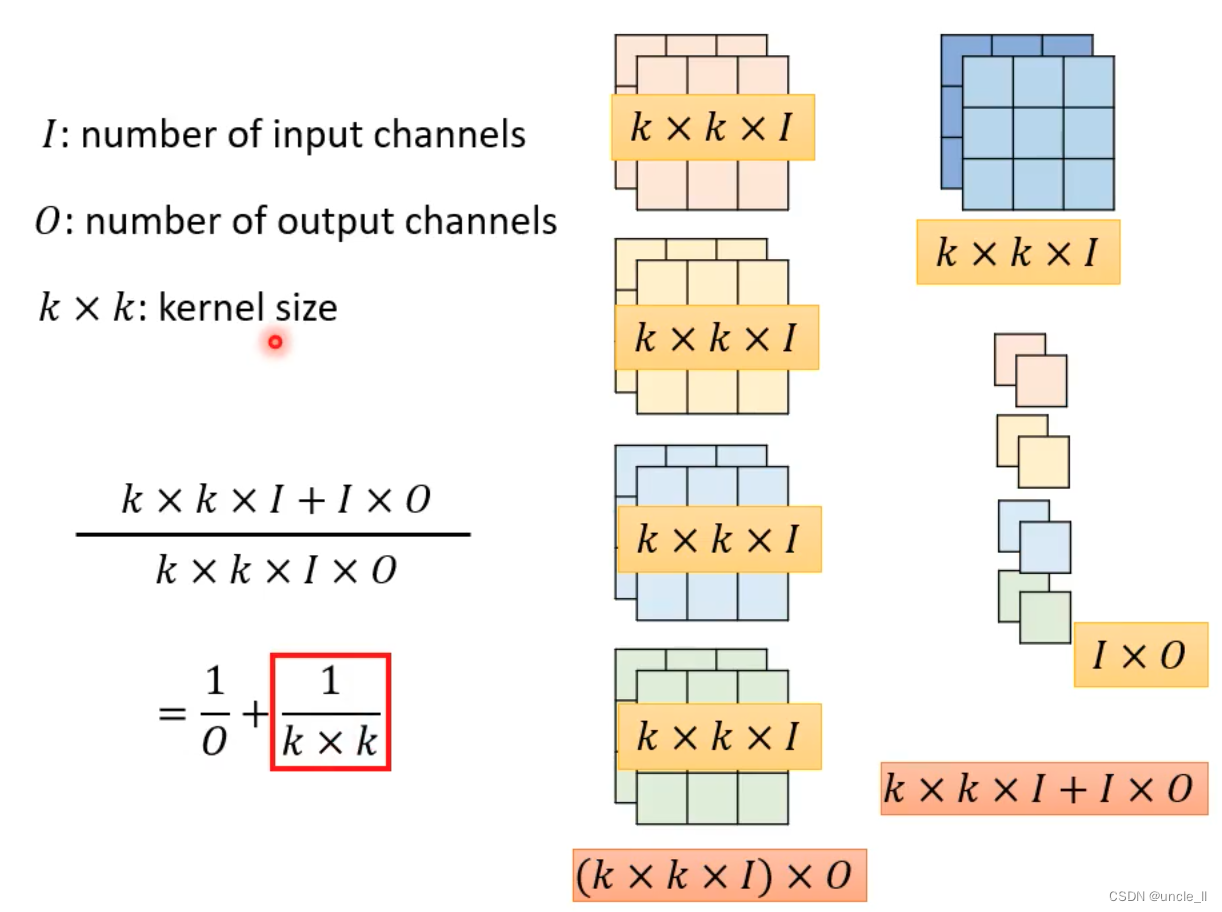
- 参数约变为原先的 1 / k 2 1/{k^2} 1/k2
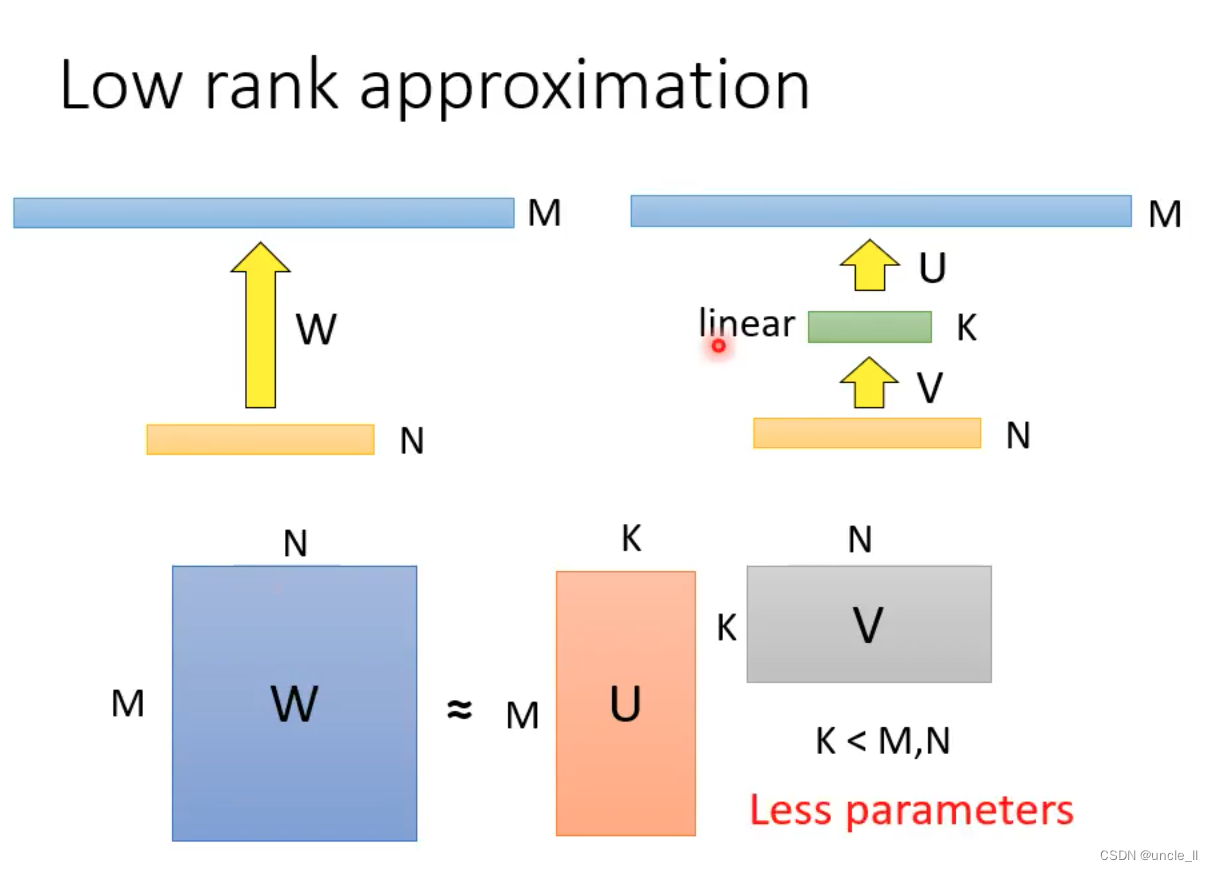
- 把一层变成两层,类似于矩阵连续相乘,中间可操作空间大,以减少维度计算。
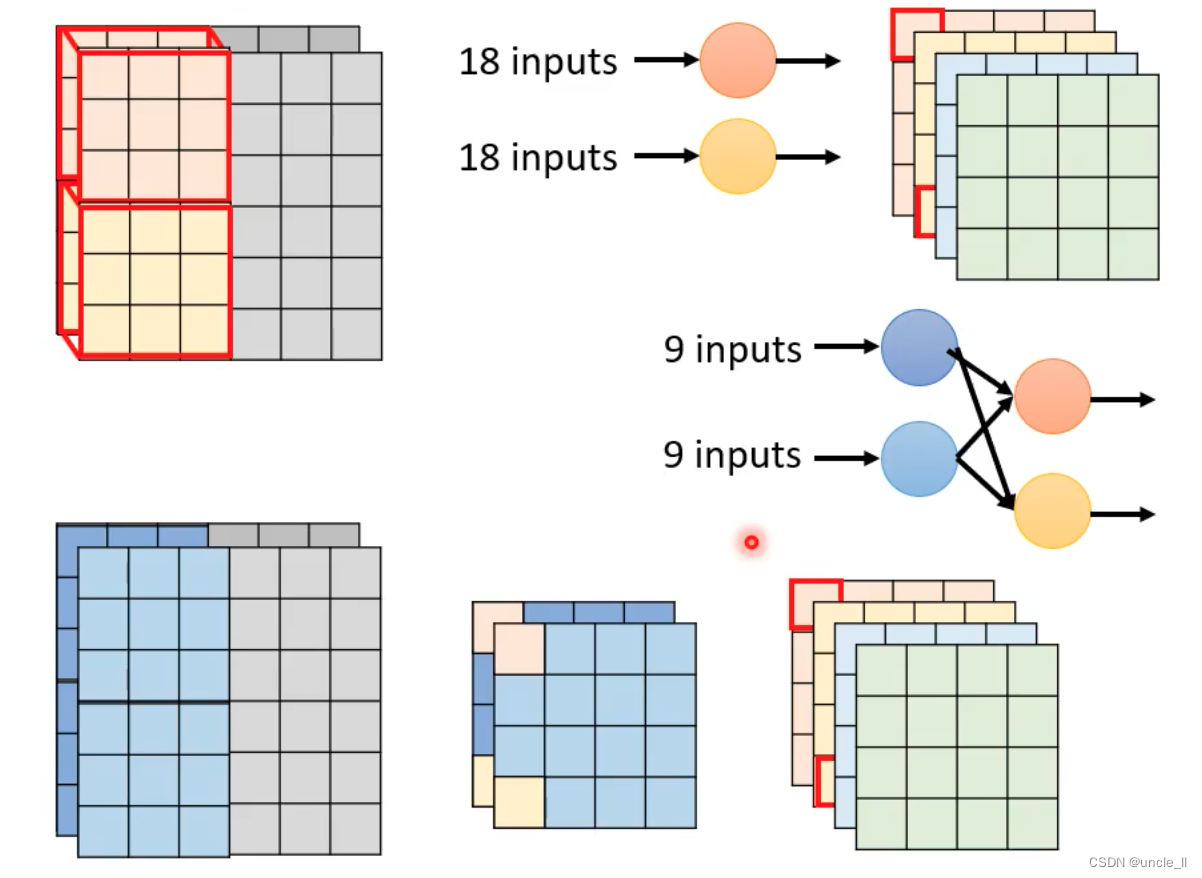
*

动态计算


期望网络能自己调整计算量,因为模型会跑到不同设备上。电量的多少也会对性能有影响。
自己调整深度
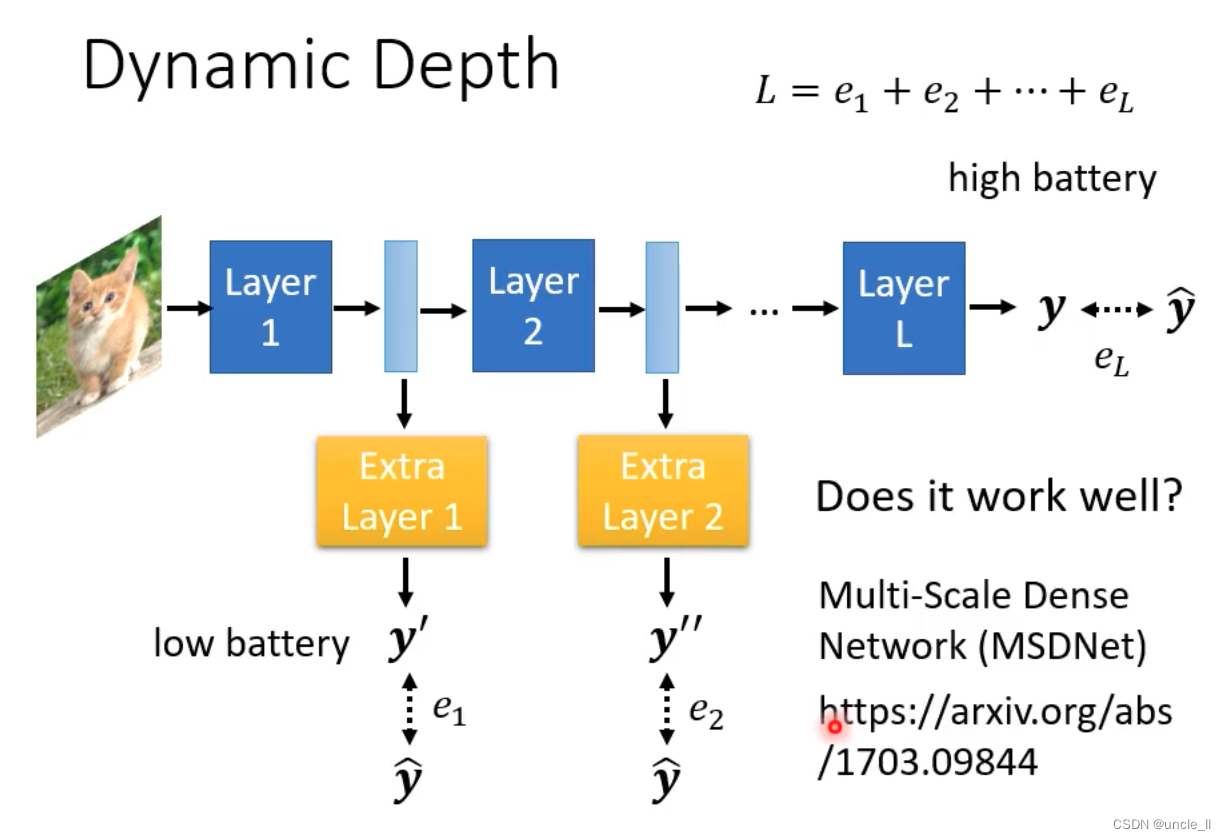
让每层的输出,与最终的输出之间的差距加起来作为最终的loss,优化该loss来动态调整深度。
自己调整宽度
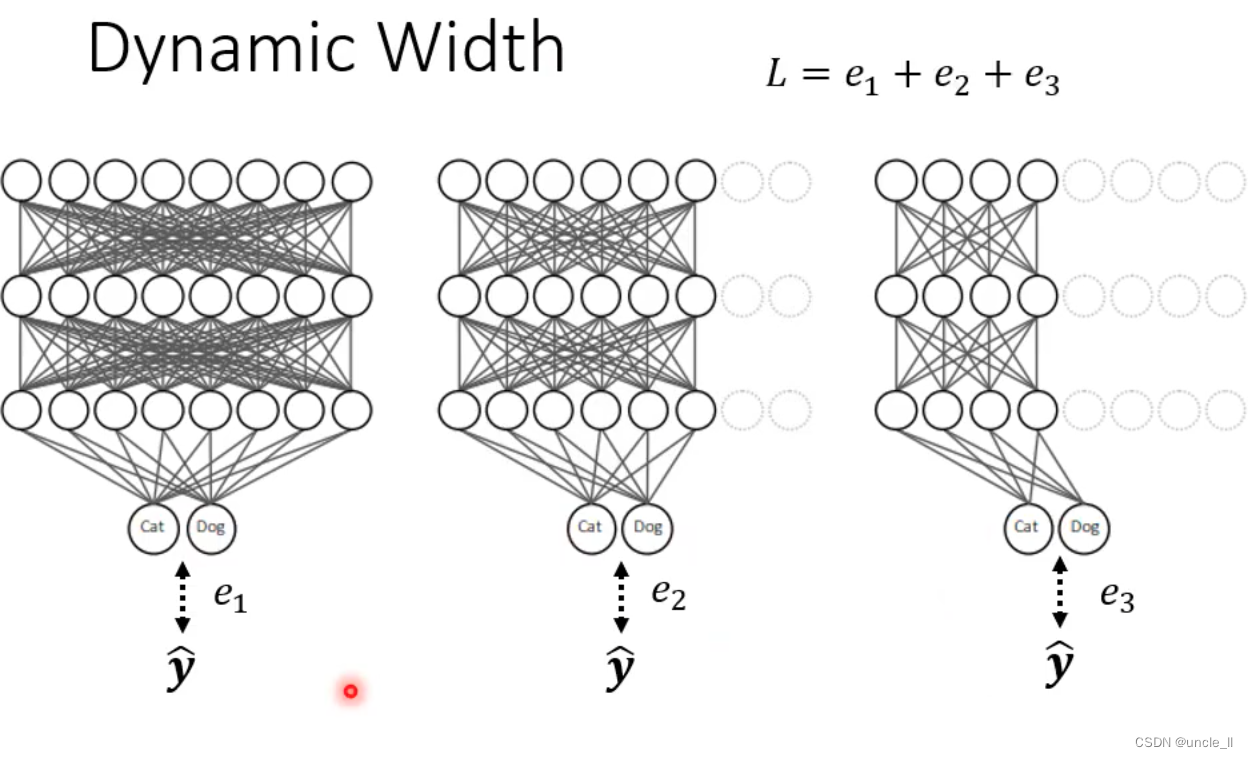
- 不同宽度的输出与最宽的输出之间的差距越小越好
- 同一个模型,只是不同的宽度
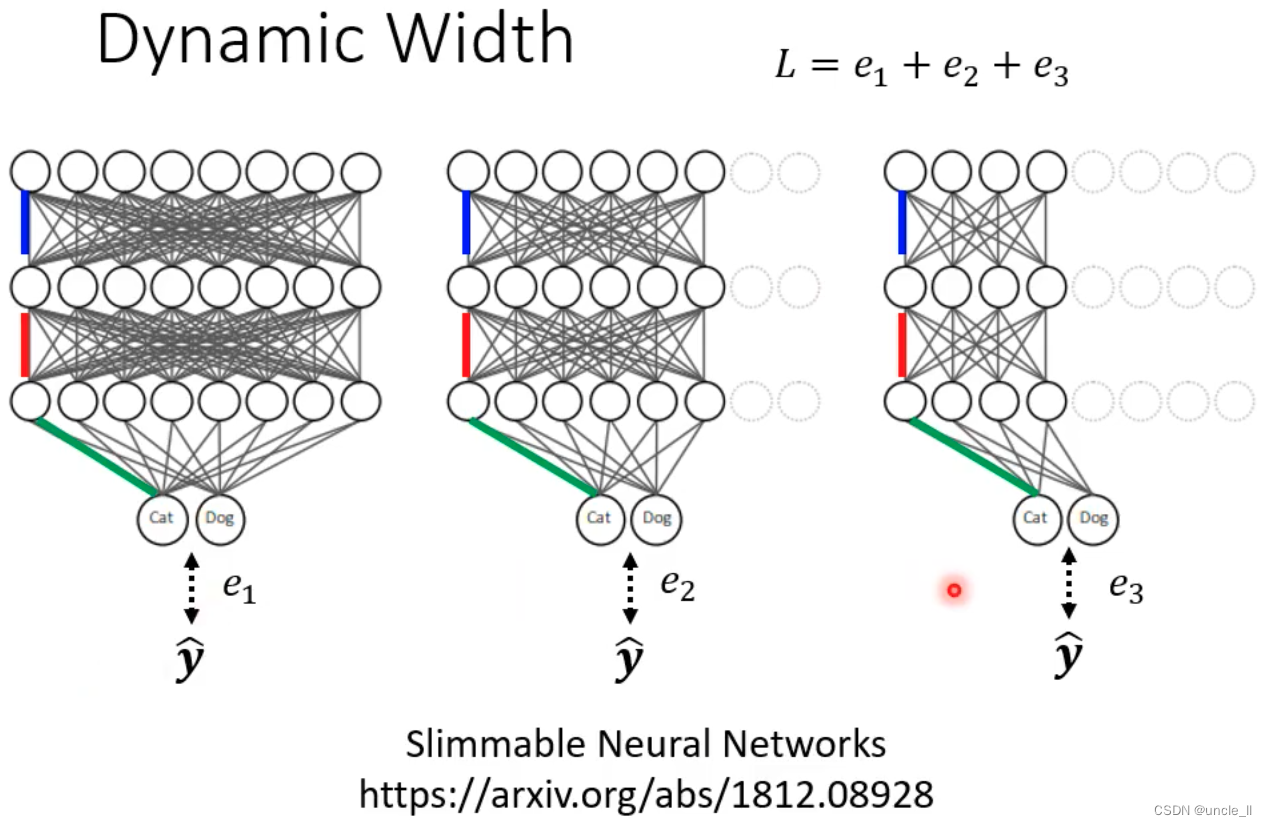
根据环境困难度自己决定深度和宽度
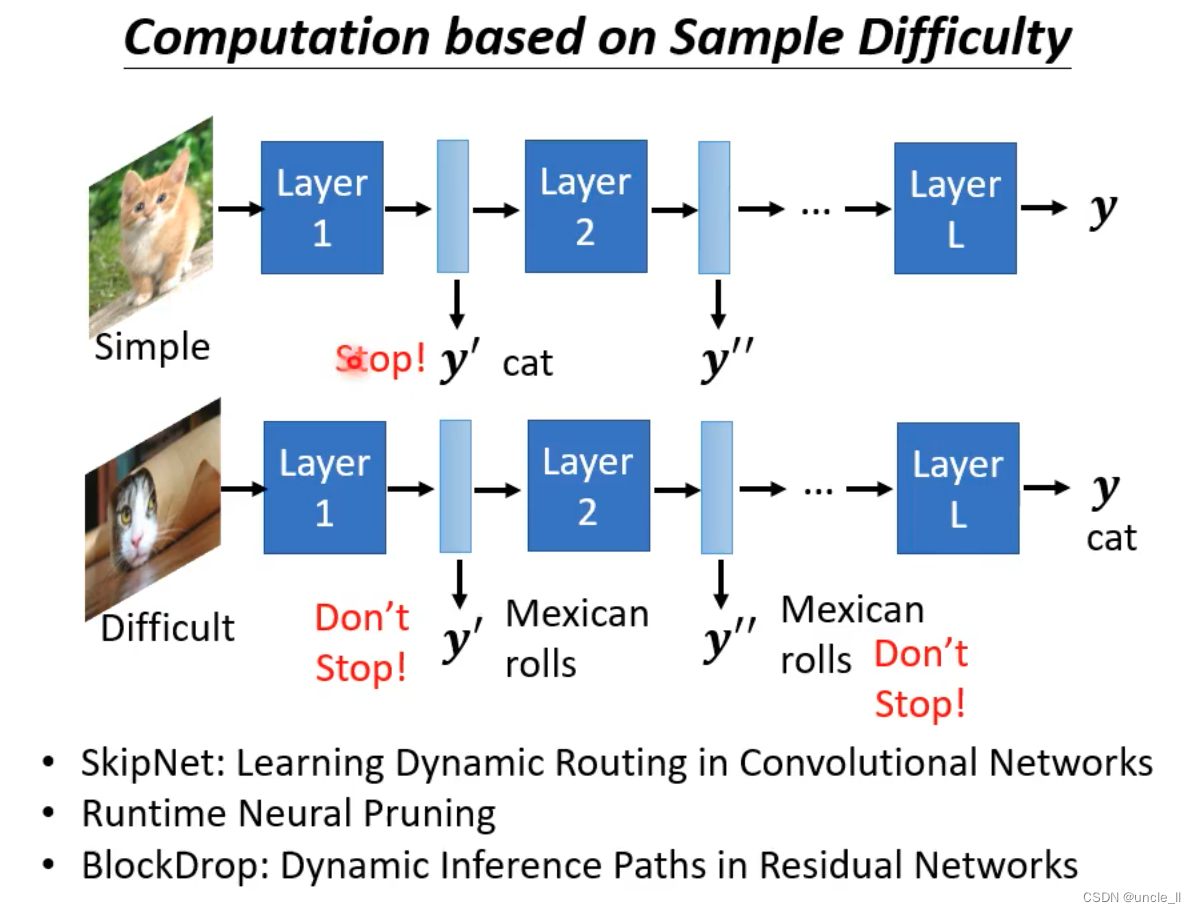
- 对于简单的样本,就使用浅层的输出即可
- 对于困难的样本,可以使用最终的输出
总结

- 上述技术不是互斥的,可以一起使用
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/283207
推荐阅读
相关标签

