
- 1Pytorch:制作自己的数据集并实现图像分类三部曲_index = np.random.permutation(len(all_imgs_path))
- 2mainfestPlaceholders配置不同的变量的妙用_manifestplaceholders meta
- 3extern 与 #define 使用说明_extern可以声明define吗
- 4破解Boot Camp限制!苹果用U盘装Win7_win7安装bootcamp异常
- 5Flutter使用WebSockets
- 6注册成为harmonyos开发者并安装DevEco Studio 3.0 Beta2 for HarmonyOS_harmonyos deveco注册界面
- 7微信支付, 小程序,公众号, 商户号 需要进行的配置_微信小程序配置接口白名单
- 8【拓展】对比ios系统与Android系统_android和ios区别
- 9clone、new_tensor 等张量复制操作_new_tensor() 函数
- 10内蒙古职高计算机专业可以考哪些大学,我是内蒙古的考生,今年高考考了349分,我读计算机专业,能考一个什么学校,仅限内蒙古地区...
LangChain应用全解析
赞
踩
从公众号转载,关注微信公众号掌握更多技术动态

---------------------------------------------------------------
一、Langchain基础
1.Langchain简介
(1)替换模型
from langchain.prompts import ChatPromptTemplatechat = ChatOpenAI(temperature=0)使用代理ip
llm = ChatOpenAI(model_name="gpt-3.5-turbo", max_tokens=2048, temperature=0.5,openai_api_key=api_key,openai_api_base='https://api.openai-proxy.com/v1')(2)LangChain的主要模块
chains和Agents两个模块是LangChain的亮点
-
Prompt Templates:支持自定义Prompt工程的快速实现以及和LLMs的对接;
-
LLMs:提供基于OpenAI API封装好的大模型,包含常见的OpenAI大模型,也支持自定义大模型的封装;
-
Utils:大模型常见的植入能力的封装,比如搜索引擎、Python编译器、Bash编译器、数据库等等;
-
Chains:大模型针对一系列任务的顺序执行逻辑链;
-
Agents:通常Utils中的能力、Chains中的各种逻辑链都会封装成一个个工具(Tools)供Agents进行智能化调用;
(3)LangChain中的组件
-
Models模型:各种类型的模型和模型集成,比如GPT-4;LangChain 中的模型主要分为三类:
-
LLM(大型语言模型):这些模型将文本字符串作为输入并返回文本字符串作为输出。它们是许多语言模型应用程序的支柱。
-
聊天模型( Chat Model):聊天模型由语言模型支持,但具有更结构化的 API。他们将聊天消息列表作为输入并返回聊天消息。这使得管理对话历史记录和维护上下文变得容易。
-
文本嵌入模型(Text Embedding Models):这些模型将文本作为输入并返回表示文本嵌入的浮点列表。这些嵌入可用于文档检索、聚类和相似性比较等任务。
-
-
Prompts提示:包括提示管理、提示优化和提示序列化,目前只支持字符形式的提示;
-
Memory记忆:用来保存和模型交互时的上下文状态;模型是无状态的,不保存上一次交互时的数据,回想一下OpenAI的API服务,它是没有上下文概念的,而chatGPT是额外实现了上下文功能。为了提供上下文的功能,LangChain提供了记忆组件,用来在对话过程中存储数据。
-
Indexes索引:用来结构化文档,以便和模型交
-
Chains链:一系列对各种组件的调用,就是将其他各个独立的组件串联起来
-
Agents智能体:决定模型采取哪些行动,执行并且观察流程,直到完成为止
(4)LangChain作用
LLM模型本身是不支持多轮对话的,比如ChatGPT,他是在GPT-3.5的基础上额外加了Memory,才得以实现多轮对话的能力;
那么,除此之外,我们还能叠加什么能力呢:
-
代码执行能力:计算复杂数学问题;
-
搜索引擎能力:提高模型回答内容的时效性;
-
数据库检索能力:实现自定义数据的分析、总结;
LangChain是一个能够让LLMs快速的落地的部署框架,相当于给你的LLM套上了一层盔甲,构建属于你自己的AI产品;
2.构造prompt模板
LangChain还提供了提示模版用于一些常用场景。比如summarization, Question answering, or connect to sql databases, or connect to different APIs. 通过使用LongChain内置的提示模版,你可以快速建立自己的大模型应用,而不需要花时间去设计和构造提示。
在以前我们需要通过f字符串把Python表达式的值进行格式化。
prompt = f"""Translate the text \that is delimited by triple backticks into a style that is {style}.text: ```{customer_email}```"""(1)构造提示模版字符串
template_string = """Translate the text \that is delimited by triple backticks \into a style that is {style}. \text: ```{text}```"""(2)构造LangChain提示模版
我们调用ChatPromptTemplatee.from_template()函数将上面的提示模版字符template_string转换为提示模版prompt_template
from langchain.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_template(template_string)可以看出,prompt_template有两个输入变量:style和text

(3)使用模版得到客户消息提示
langchain提示模版prompt_template需要两个输入变量: style 和 text。这里分别对应
-
customer_style: 我们想要的顾客邮件风格
-
customer_email: 顾客的原始邮件文本
customer_style = """American English \in a calm and respectful tone"""customer_email = """Arrr, I be fuming that me blender lid \flew off and splattered me kitchen walls \with smoothie! And to make matters worse, \the warranty don't cover the cost of \cleaning up me kitchen. I need yer help \right now, matey!"""对于给定的customer_style和customer_email, 我们可以使用提示模版prompt_template的format_messages方法生成想要的客户消息customer_messages。customer_messages = prompt_template.format_messages( style=customer_style, text=customer_email)print(type(customer_messages))print(type(customer_messages[0]))可以看出customer_messages变量类型为列表(list),而列表里的元素变量类型为langchain自定义消息(langchain.schema.HumanMessage)
(4)调用chat模型
到目前为止,是不用LangChain也可以实现的内容。
customer_response = chat(customer_messages)print(customer_response.content)(5)使用模板更换prompt
service_reply = """Hey there customer, \the warranty does not cover \cleaning expenses for your kitchen \because it's your fault that \you misused your blender \by forgetting to put the lid on before \starting the blender. \Tough luck! See ya!"""
service_style_pirate = """\ a polite tone \that speaks in English Pirate\"""
service_messages = prompt_template.format_messages( style=service_style_pirate, text=service_reply)
print(service_messages[0].content)(6)调用chat模型转换回复消息风格
service_response = chat(service_messages)print(service_response.content)3.输出解析器
期望输出
{ "gift": False, "delivery_days": 5, "price_value": "pretty affordable!"}信息
customer_review = """\This leaf blower is pretty amazing. It has four settings:\candle blower, gentle breeze, windy city, and tornado. \It arrived in two days, just in time for my wife's \anniversary present. \I think my wife liked it so much she was speechless. \So far I've been the only one using it, and I've been \using it every other morning to clear the leaves on our lawn. \It's slightly more expensive than the other leaf blowers \out there, but I think it's worth it for the extra features."""(1)传统方式
①构造提示模版字符串
review_template = """\For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? \Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the product \to arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,\and output them as a comma separated Python list.
Format the output as JSON with the following keys:giftdelivery_daysprice_value
text: {text}"""②构造langchain提示模版
from langchain.prompts import ChatPromptTemplateprompt_template = ChatPromptTemplate.from_template(review_template)print(prompt_template)③使用模版得到提示消息
messages = prompt_template.format_messages(text=customer_review)④调用chat模型提取信息
chat = ChatOpenAI(temperature=0)response = chat(messages)print(response.content)
此时输出的内容虽然看起来是个json,但是其实是一个字符串
(2)使用langchain输出解析器
①构造提示模版字符串
review_template_2 = """\For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? \Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the product\to arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,\and output them as a comma separated Python list.
text: {text}
{format_instructions}"""②构造langchain提示模版
prompt = ChatPromptTemplate.from_template(template=review_template_2)③构造输出解析器
from langchain.output_parsers import ResponseSchemafrom langchain.output_parsers import StructuredOutputParser
gift_schema = ResponseSchema(name="gift", description="Was the item purchased\ as a gift for someone else? \ Answer True if yes,\ False if not or unknown.")
delivery_days_schema = ResponseSchema(name="delivery_days", description="How many days\ did it take for the product\ to arrive? If this \ information is not found,\ output -1.")
price_value_schema = ResponseSchema(name="price_value", description="Extract any\ sentences about the value or \ price, and output them as a \ comma separated Python list.")
response_schemas = [gift_schema, delivery_days_schema, price_value_schema]output_parser = StructuredOutputParser.from_response_schemas(response_schemas)format_instructions = output_parser.get_format_instructions()print(format_instructions)④使用模版得到提示消息
messages = prompt.format_messages(text=customer_review, format_instructions=format_instructions)print(messages[0].content)⑤ 调用chat模型提取信息
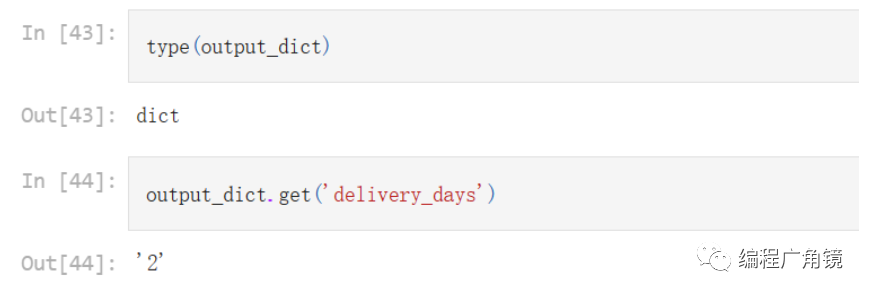
response = chat(messages)print(response.content)⑥使用输出解析器解析输出
output_dict = output_parser.parse(response.content)print(output_dict){'gift': True, 'delivery_days': 2, 'price_value': ["It's slightly more expensive than the other leaf blowers out there, but I think it's worth it for the extra features."]}output_dict类型为字典(dict), 可直接使用get方法。这样的输出更方便下游任务的处理。
二、链式调用LangChain——LLMChain
LLMChain 能够帮助我们链式地调用一系列命令,这里面既包含直接调用 OpenAI 的 API,也包括调用其他外部接口,或者自己实现的 Python 代码。但是这一连串的调用,还只是完成一个小任务。
1.LLMChain应用
(1)使用 LLMChain 进行链式调用
import openai, osfrom langchain.prompts import PromptTemplatefrom langchain.llms import OpenAIfrom langchain.chains import LLMChain
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
llm = OpenAI(model_name="text-davinci-003", max_tokens=2048, temperature=0.5)
en_to_zh_prompt = PromptTemplate( template="请把下面这句话翻译成英文:\n\n {question}?", input_variables=["question"])
question_prompt = PromptTemplate( template = "{english_question}", input_variables=["english_question"])
zh_to_cn_prompt = PromptTemplate( input_variables=["english_answer"], template="请把下面这一段翻译成中文:\n\n{english_answer}?",)
question_translate_chain = LLMChain(llm=llm, prompt=en_to_zh_prompt, output_key="english_question")english = question_translate_chain.run(question="请你作为一个机器学习的专家,介绍一下CNN的原理。")print(english)
qa_chain = LLMChain(llm=llm, prompt=question_prompt, output_key="english_answer")english_answer = qa_chain.run(english_question=english)print(english_answer)
answer_translate_chain = LLMChain(llm=llm, prompt=zh_to_cn_prompt)answer = answer_translate_chain.run(english_answer=english_answer)print(answer)Please explain the principles of CNN as an expert in Machine Learning.
A Convolutional Neural Network (CNN) is a type of deep learning algorithm that is used to analyze visual imagery. It is modeled after the structure of the human visual cortex and is composed of multiple layers of neurons that process and extract features from an image. The main principle behind a CNN is that it uses convolutional layers to detect patterns in an image. Each convolutional layer is comprised of a set of filters that detect specific features in an image. These filters are then used to extract features from the image and create a feature map. The feature map is then passed through a pooling layer which reduces the size of the feature map and helps to identify the most important features in the image. Finally, the feature map is passed through a fully-connected layer which classifies the image and outputs the result.
卷积神经网络(CNN)是一种深度学习算法,用于分析视觉图像。它模仿人类视觉皮层的结构,由多层神经元组成,可以处理和提取图像中的特征。CNN的主要原理是使用卷积层来检测图像中的模式。每个卷积层由一组滤波器组成,可以检测图像中的特定特征。然后使用这些滤波器从图像中提取特征,并创建特征图。然后,将特征图通过池化层传递,该层可以减小特征图的大小,并有助于识别图像中最重要的特征。最后,将特征图传递给完全连接的层,该层将对图像进行分类,并输出结果。-
LLM,也就是我们使用哪个大语言模型,来回答我们提出的问题。在这里,我们还是使用 OpenAIChat,也就是最新放出来的 gpt-3.5-turbo 模型。
-
PromptTemplate 它可以定义一个提示语模版,里面能够定义一些可以动态替换的变量。比如,代码里的 question_prompt 这个模版里,我们就定义了一个叫做 question 的变量,因为我们每次问的问题都会不一样。事实上,llamd-index 里面的 PromptTemplate 就是对 Langchain 的 PromptTemplate 做了一层简单的封装。
-
主角 LLMChain,它的构造函数接收一个 LLM 和一个 PromptTemplate 作为参数。构造完成之后,可以直接调用里面的 run 方法,将 PromptTemplate 需要的变量,用 K=>V 对的形式传入进去。返回的结果,就是 LLM 给我们的答案。
不过如果看上面这段代码,我们似乎只是对 OpenAI 的 API 做了一层封装而已。我们构建了 3 个 LLMChain,然后按照顺序调用,每次拿到答案之后,再作为输入,交给下一个 LLM 调用。感觉好像更麻烦了,没有减少什么工作量呀?
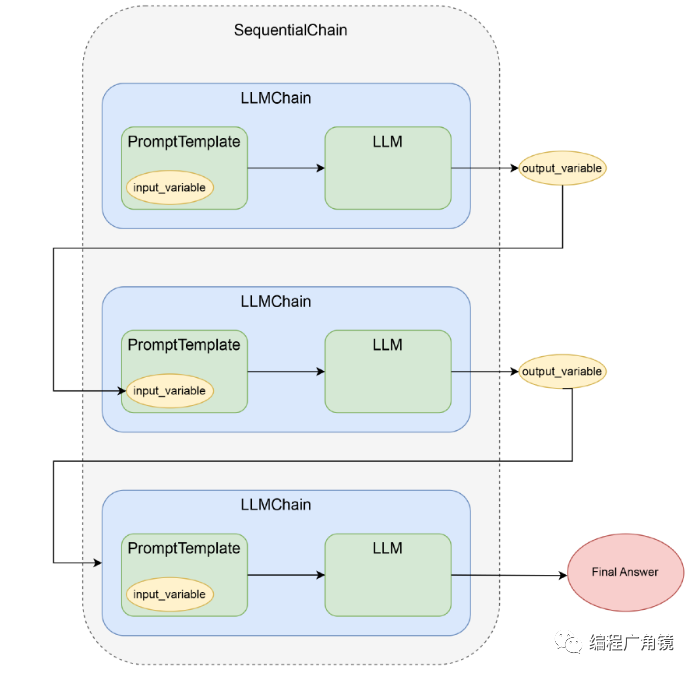
这是因为我们还没有真正用上 LLMChain 的“链式调用”功能,而用这个功能,只需要加上一行小小的代码。我们用一个叫做 SimpleSequentialChain 的 LLMChain 类,把我们要按照顺序依次调用的三个 LLMChain 放在一个数组里,传给这个类的构造函数。
然后对于这个对象,我们调用 run 方法,把我们用中文问的问题交给它。这个时候,这个 SimpleSequentialChain,就会按照顺序开始调用 chains 这个数组参数里面包含的其他 LLMChain。并且,每一次调用的结果,会存储在这个 Chain 构造时定义的 output_key 参数里。而下一个调用的 LLMChain,里面模版内的变量如果有和之前的 output_key 名字相同的,就会用 output_key 里存入的内容替换掉模版内变量所在的占位符。
import openai, osfrom langchain.prompts import PromptTemplatefrom langchain.llms import OpenAIfrom langchain.chains import LLMChainfrom langchain.chains import SimpleSequentialChain
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
llm = OpenAI(model_name="text-davinci-003", max_tokens=2048, temperature=0.5)
en_to_zh_prompt = PromptTemplate( template="请把下面这句话翻译成英文:\n\n {question}?", input_variables=["question"])
question_prompt = PromptTemplate( template = "{english_question}", input_variables=["english_question"])
zh_to_cn_prompt = PromptTemplate( input_variables=["english_answer"], template="请把下面这一段翻译成中文:\n\n{english_answer}?",)
question_translate_chain = LLMChain(llm=llm, prompt=en_to_zh_prompt, output_key="english_question")qa_chain = LLMChain(llm=llm, prompt=question_prompt, output_key="english_answer")answer_translate_chain = LLMChain(llm=llm, prompt=zh_to_cn_prompt)
chinese_qa_chain = SimpleSequentialChain( chains=[question_translate_chain, qa_chain, answer_translate_chain], input_key="question", verbose=True)answer = chinese_qa_chain.run(question="请你作为一个机器学习的专家,介绍一下CNN的原理。")print(answer)> Entering new SimpleSequentialChain chain...
Please introduce the principle of CNN as an expert in machine learning.
Convolutional Neural Networks (CNNs) are a type of artificial neural network used in machine learning. They are designed to recognize patterns in images and other data by applying convolutional filters to the input data. The filters are designed to detect certain features in the input data, such as lines, edges, and shapes. The layers in a CNN are arranged in a hierarchical structure, with each layer progressively detecting more complex features in the data. The output of a CNN is usually a classification or a probability of a certain class. CNNs are used in a variety of applications, including image recognition, natural language processing, and medical image analysis.
卷积神经网络(CNN)是一种应用于机器学习的人工神经网络。它们被设计用来通过对输入数据应用卷积滤波器来识别图像和其他数据中的模式。这些滤波器被设计用来检测输入数据中的某些特征,如线条、边缘和形状。CNN中的层次排列在一个层次结构中,每一层逐步检测出数据中越来越复杂的特征。CNN的输出通常是一个分类或某一类的概率。CNN应用于各种各样的应用,包括图像识别、自然语言处理和医学图像分析。
> Finished chain.
卷积神经网络(CNN)是一种应用于机器学习的人工神经网络。它们被设计用来通过对输入数据应用卷积滤波器来识别图像和其他数据中的模式。这些滤波器被设计用来检测输入数据中的某些特征,如线条、边缘和形状。CNN中的层次排列在一个层次结构中,每一层逐步检测出数据中越来越复杂的特征。CNN的输出通常是一个分类或某一类的概率。CNN应用于各种各样的应用,包括图像识别、自然语言处理和医学图像分析。
Process finished with exit code 0在使用这样的链式调用的时候,有一点需要注意,就是一个 LLMChain 里,所使用的 PromptTemplate 里的输入参数,之前必须在 LLMChain 里,通过 output_key 定义过。不然,这个变量没有值,程序就会报错。
(2)支持多个变量输入的链式调用
import openai, osfrom langchain.prompts import PromptTemplatefrom langchain.llms import OpenAIfrom langchain.chains import LLMChainfrom langchain.chains import SimpleSequentialChain
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
llm = OpenAI(model_name="text-davinci-003", max_tokens=2048, temperature=0.5)
from langchain.chains import SequentialChain
q1_prompt = PromptTemplate( input_variables=["year1"], template="{year1}年的欧冠联赛的冠军是哪支球队,只说球队名称。")q2_prompt = PromptTemplate( input_variables=["year2"], template="{year2}年的欧冠联赛的冠军是哪支球队,只说球队名称。")q3_prompt = PromptTemplate( input_variables=["team1", "team2"], template="{team1}和{team2}哪只球队获得欧冠的次数多一些?")chain1 = LLMChain(llm=llm, prompt=q1_prompt, output_key="team1")chain2 = LLMChain(llm=llm, prompt=q2_prompt, output_key="team2")chain3 = LLMChain(llm=llm, prompt=q3_prompt)
sequential_chain = SequentialChain(chains=[chain1, chain2, chain3], input_variables=["year1", "year2"], verbose=True)answer = sequential_chain.run(year1=2000, year2=2010)print(answer)(3)通过 Langchain 实现自动化撰写单元测试
import openai, osfrom langchain.prompts import PromptTemplatefrom langchain.llms import OpenAIfrom langchain.chains import LLMChainfrom langchain.chains import SequentialChain
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
llm = OpenAI(model_name="text-davinci-003", max_tokens=2048, temperature=0.5)
def write_unit_test(function_to_test, unit_test_package = "pytest"): # 解释源代码的步骤 explain_code = """"# How to write great unit tests with {unit_test_package}
In this advanced tutorial for experts, we'll use Python 3.10 and `{unit_test_package}` to write a suite of unit tests to verify the behavior of the following function. ```python {function_to_test} ```
Before writing any unit tests, let's review what each element of the function is doing exactly and what the author's intentions may have been. - First,"""
explain_code_template = PromptTemplate( input_variables=["unit_test_package", "function_to_test"], template=explain_code ) explain_code_llm = OpenAI(model_name="text-davinci-002", temperature=0.4, max_tokens=1000, top_p=1, stop=["\n\n", "\n\t\n", "\n \n"]) explain_code_step = LLMChain(llm=explain_code_llm, prompt=explain_code_template, output_key="code_explaination")
# 创建测试计划示例的步骤 test_plan = """ A good unit test suite should aim to: - Test the function's behavior for a wide range of possible inputs - Test edge cases that the author may not have foreseen - Take advantage of the features of `{unit_test_package}` to make the tests easy to write and maintain - Be easy to read and understand, with clean code and descriptive names - Be deterministic, so that the tests always pass or fail in the same way
`{unit_test_package}` has many convenient features that make it easy to write and maintain unit tests. We'll use them to write unit tests for the function above.
For this particular function, we'll want our unit tests to handle the following diverse scenarios (and under each scenario, we include a few examples as sub-bullets): -""" test_plan_template = PromptTemplate( input_variables=["unit_test_package", "function_to_test", "code_explaination"], template= explain_code + "{code_explaination}" + test_plan ) test_plan_llm = OpenAI(model_name="text-davinci-002", temperature=0.4, max_tokens=1000, top_p=1, stop=["\n\n", "\n\t\n", "\n \n"]) test_plan_step = LLMChain(llm=test_plan_llm, prompt=test_plan_template, output_key="test_plan")
# 撰写测试代码的步骤 starter_comment = "Below, each test case is represented by a tuple passed to the @pytest.mark.parametrize decorator" prompt_to_generate_the_unit_test = """
Before going into the individual tests, let's first look at the complete suite of unit tests as a cohesive whole. We've added helpful comments to explain what each line does.```pythonimport {unit_test_package} # used for our unit tests
{function_to_test}
#{starter_comment}"""
unit_test_template = PromptTemplate( input_variables=["unit_test_package", "function_to_test", "code_explaination", "test_plan", "starter_comment"], template= explain_code + "{code_explaination}" + test_plan + "{test_plan}" + prompt_to_generate_the_unit_test ) unit_test_llm = OpenAI(model_name="text-davinci-002", temperature=0.4, max_tokens=1000, stop="```") unit_test_step = LLMChain(llm=unit_test_llm, prompt=unit_test_template, output_key="unit_test")
sequential_chain = SequentialChain(chains=[explain_code_step, test_plan_step, unit_test_step], input_variables=["unit_test_package", "function_to_test", "starter_comment"], verbose=True) answer = sequential_chain.run(unit_test_package=unit_test_package, function_to_test=function_to_test, starter_comment=starter_comment) return f"""#{starter_comment}""" + answer
code = """def format_time(seconds): minutes, seconds = divmod(seconds, 60) hours, minutes = divmod(minutes, 60) if hours > 0: return f"{hours}h{minutes}min{seconds}s" elif minutes > 0: return f"{minutes}min{seconds}s" else: return f"{seconds}s""""
import ast
def write_unit_test_automatically(code, retry=3): unit_test_code = write_unit_test(code) all_code = code + unit_test_code tried = 0 while tried < retry: try: ast.parse(all_code) return all_code except SyntaxError as e: print(f"Syntax error in generated code: {e}") all_code = code + write_unit_test(code) tried += 1
print(write_unit_test_automatically(code))我们把解释代码、生成测试计划,以及最终生成测试代码,变成了三个 LLMChain。每一步的输入,都来自上一步的输出。这个输入既包括上一步的 Prompt Template 和这一步的 Prompt Template 的组合,也包括过程中的一些变量,这些变量是上一步执行的结果作为输入变量传递进来的。最终,我们可以使用 SequentialChain 来自动地按照这三个步骤,执行 OpenAI 的 API 调用。
这整个过程通过 write_unit_test 这个函数给封装起来了。对于重试,我们则是通过一个 while 循环来调用 write_unit_test。拿到的结果和输入的代码拼装在一起,交给 AST 库做解析。如果解析通不过,则重试整个单元测试生成的过程,直到达到我们最大的重试次数为止。
LangChain 的这个分多个步骤调用 OpenAI 模型的能力,能够帮助我们通过 AI 完成复杂的任务,并且将整个任务的完成过程定义成了一个固定的流程模版。在下一讲里,我们还会进一步看到,通过这样一个链式组合多个 LLMChain 的方法,如何完成更复杂并且更具有现实意义的工作。
2.深入使用LLMChain
(1)解决 AI 数理能力的难题
虽然 ChatGPT 回答各种问题的时候都像模像样的,但是一到计算三位数乘法的时候就露馅儿了。感觉它只是快速估计了一个数字,而不是真的准确计算了。我们可以使用链式调用的方式解决该问题。
import openai, osfrom langchain.prompts import PromptTemplatefrom langchain.llms import OpenAIfrom langchain.chains import LLMChain
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
llm = OpenAI(model_name="text-davinci-003", max_tokens=2048, temperature=0.5)
multiply_by_python_prompt = PromptTemplate(template="请写一段Python代码,计算{question}?", input_variables=["question"])math_chain = LLMChain(llm=llm, prompt=multiply_by_python_prompt, output_key="answer")answer_code = math_chain.run({"question": "352乘以493"})
from langchain.utilities import PythonREPLpython_repl = PythonREPL()result = python_repl.run(answer_code)print(result)可以看到,LangChain 里面内置了一个 utilities 的包,里面包含了 PythonREPL 这个类,可以实现对 Python 解释器的调用。如果你去翻看一下对应代码的源码的话,它其实就是简单地调用了一下系统自带的 exec 方法,来执行 Python 代码。utilities 里面还有很多其他的类,能够实现很多功能,比如可以直接运行 Bash 脚本,调用 Google Search 的 API 等等。
所以,对于这些工具能力,LangChain 也把它们封装成了 LLMChain 的形式。比如刚才的数学计算问题,是一个先生成 Python 脚本,再调用 Python 解释器的过程,LangChain 就把这个过程封装成了一个叫做 LLMMathChain 的 LLMChain。不需要自己去生成代码,再调用 PythonREPL,只要直接调用 LLMMathChain,它就会在背后把这一切都给做好。
from langchain import LLMMathChain
llm_math = LLMMathChain(llm=llm, verbose=True)result = llm_math.run("请计算一下352乘以493是多少?")print(result)LangChain 也把前面讲过的 utilities 包里面的很多功能,都封装成了 Utility Chains。比如,SQLDatabaseChain 可以直接根据你的数据库生成 SQL,然后获取数据,LLMRequestsChain 可以通过 API 调用外部系统,获得想要的答案。
(2)通过 RequestsChain 获取实时外部信息
一种为 AI 引入外部知识的方法了,那就是计算这些外部知识的 Embedding,然后作为索引先保存下来。但是,这只适用于处理那些预先准备好会被问到的知识,比如一本书、一篇论文。这些东西,内容多但是固定,也不存在时效性问题,我们可以提前索引好,而且用户问的问题往往也有很强的相似性。
但是,对于时效性强的问题,这个方法不太适用,因为我们可能没有必要不停地更新索引。比如,你想要知道实时的天气情况,我们不太可能把全球所有城市最新的天气信息每隔几分钟都索引一遍。这个时候,我们可以使用 LLMRequestsChain,通过一个 HTTP 请求来得到问题的答案。最简单粗暴的一个办法,就是直接通过一个 HTTP 请求来问一下 Google。
import openai, osfrom langchain.prompts import PromptTemplatefrom langchain.llms import OpenAIfrom langchain.chains import LLMChain
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
from langchain.chains import LLMRequestsChain
template = """在 >>> 和 <<< 直接是来自Google的原始搜索结果.请把对于问题 '{query}' 的答案从里面提取出来,如果里面没有相关信息的话就说 "找不到"请使用如下格式:Extracted:<answer or "找不到">>>> {requests_result} <<<Extracted:"""
PROMPT = PromptTemplate( input_variables=["query", "requests_result"], template=template,)requests_chain = LLMRequestsChain(llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=PROMPT))question = "今天上海的天气怎么样?"inputs = { "query": question, "url": "https://www.google.com/search?q=" + question.replace(" ", "+")}result=requests_chain(inputs)print(result)print(result['output'])-
首先,因为我们是简单粗暴地搜索 Google。但是我们想要的是一个有价值的天气信息,而不是整个网页。所以,我们还需要通过 ChatGPT 把网页搜索结果里面的答案给找出来。所以我们定义了一个 PromptTemplate,通过一段提示语,让 OpenAI 为我们在搜索结果里面,找出问题的答案,而不是去拿原始的 HTML 页面。
-
然后,我们使用了 LLMRequestsChain,并且把刚才 PromptTemplate 构造的一个普通的 LLMChain,作为构造函数的一个参数,传给 LLMRequestsChain,帮助我们在搜索之后处理搜索结果。
-
对应的搜索词,通过 query 这个参数传入,对应的原始搜索结果,则会默认放到 requests_results 里。而通过我们自己定义的 PromptTemplate 抽取出来的最终答案,则会放到 output 这个输出参数里面。
(3)通过 TransformationChain 转换数据格式
有了实时的外部数据,我们就又有很多做应用的创意了。比如说,我们可以根据气温来推荐大家穿什么衣服。我们可以要求如果最低温度低于 0 度,就要推荐用户去穿羽绒服。或者,根据是否下雨来决定要不要提醒用户出门带伞。
在现在的返回结果里,天气信息(天气、温度、风力)只是一段文本,而不是可以直接获取的 JSON 格式。当然,我们可以在 LLMChain 里面再链式地调用一次 OpenAI 的接口,把这段文本转换成 JSON 格式。但是,这样做的话,一来还要消耗更多的 Token、花更多的钱,二来这也会进一步增加程序需要运行的时间,毕竟一次往返的网络请求也是很慢的。这里的文本格式其实很简单,我们完全可以通过简单的字符串处理完成解析。
import redef parse_weather_info(weather_info: str) -> dict: # 将天气信息拆分成不同部分 parts = weather_info.split('; ')
# 解析天气 weather = parts[0].strip()
# 解析温度范围,并提取最小和最大温度 temperature_range = parts[1].strip().replace('℃', '').split('~') temperature_min = int(temperature_range[0]) temperature_max = int(temperature_range[1])
# 解析风向和风力 wind_parts = parts[2].split(' ') wind_direction = wind_parts[0].strip() wind_force = wind_parts[1].strip()
# 返回解析后的天气信息字典 weather_dict = { 'weather': weather, 'temperature_min': temperature_min, 'temperature_max': temperature_max, 'wind_direction': wind_direction, 'wind_force': wind_force }
return weather_dict
# 示例weather_info = "小雨; 10℃~15℃; 东北风 风力4-5级"weather_dict = parse_weather_info(weather_info)print(weather_dict)这里实现了一个 parse_weather_info 函数,可以把前面 LLMRequestsChain 的输出结果,解析成一个 dict。不过,我们能不能更进一步,把这个解析的逻辑,也传到 LLMChain 的链式调用的最后呢?答案当然是可以的。对于这样的要求,Langchain 里面也有一个专门的解决方案,叫做 TransformChain,也就是做格式转换。
from langchain.chains import TransformChain, SequentialChain
def transform_func(inputs: dict) -> dict: text = inputs["output"] return {"weather_info" : parse_weather_info(text)}
transformation_chain = TransformChain(input_variables=["output"], output_variables=["weather_info"], transform=transform_func)
final_chain = SequentialChain(chains=[requests_chain, transformation_chain], input_variables=["query", "url"], output_variables=["weather_info"])final_result = final_chain.run(inputs)print(final_result){'weather': '小雨', 'temperature': {'min': 10, 'max': 15}, 'wind': {'direction': '东北风', 'level': '风力4-5级'}}-
先定义了一个 transform_func,对前面的 parse_weather_info 函数做了一下简单的封装。它的输入,是整个 LLMChain 里,执行到 TransformChain 之前的整个输出结果的 dict。我们前面看到整个 LLMRequestsChain 里面的天气信息的文本内容,是通过 output 这个 key 拿到的,所以这里我们也是先通过它来拿到天气信息的文本内容,再调用 parse_weather_info 解析,并且把结果输出到 weather_info 这个字段里。
-
然后,我们就定义了一个 TransformChain,里面的输入参数就是 output,输出参数就是 weather_info。
-
最后用 SequentialChain,将前面的 LLMRequestsChain 和这里的 TransformChain 串联到一起,变成一个新的叫做 final_chain 的 LLMChain。
(4)通过 VectorDBQA 来实现先搜索再回复的能力
我们预先把资料库索引好,然后每次用户来问问题的时候,都是先到这个资料库里搜索,再把问题和答案一并交给 AI,让它去组织语言回答。
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import FAISSfrom langchain.text_splitter import SpacyTextSplitterfrom langchain import OpenAI, VectorDBQAfrom langchain.document_loaders import TextLoader
llm = OpenAI(temperature=0)loader = TextLoader('./data/ecommerce_faq.txt')documents = loader.load()text_splitter = SpacyTextSplitter(chunk_size=256, pipeline="zh_core_web_sm")texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()docsearch = FAISS.from_documents(texts, embeddings)
faq_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=docsearch, verbose=True)注:上面的代码创建了一个基于 FAISS 进行向量存储的 docsearch 的索引,以及基于这个索引的 VectorDBQA 这个 LLMChain。
我们通过一个 TextLoader 把文件加载进来,还通过 SpacyTextSplitter 给文本分段,确保每个分出来的 Document 都是一个完整的句子。因为我们这里的文档是电商 FAQ 的内容,都比较短小精悍,所以我们设置的 chunk_size 只有 256。然后,我们定义了使用 OpenAIEmbeddings 来给文档创建 Embedding,通过 FAISS 把它存储成一个 VectorStore。最后,我们通过 VectorDBQA 的 from_chain_type 定义了一个 LLM。对应的 FAQ 内容,我是请 ChatGPT 为我编造之后放在了 ecommerce_faq.txt 这个文件里。
三、Langchain里的“记忆力”
我们很多时候还是希望用一个互动聊天的过程,来完成整个任务。这样就需要记住以前的对话,当使用 LangChain 中的记忆组件时,他可以帮助保存和管理历史聊天消息,以及构建关于特定实体的知识。这些组件可以跨多轮对话存储信息,并允许在对话期间跟踪特定信息和上下文。
LangChain 提供了多种记忆类型,包括:
-
ConversationBufferMemory:对话缓存记忆
-
ConversationBufferWindowMemory:对话缓存窗口记忆
-
Entity Memory
-
Conversation Knowledge Graph Memory
-
ConversationSummaryMemory
-
ConversationSummaryBufferMemory:对话摘要缓存记忆
-
ConversationTokenBufferMemory:对话令牌缓存记忆
-
VectorStore-Backed Memory
缓冲区记忆允许保留最近的聊天消息,摘要记忆则提供了对整个对话的摘要。实体记忆则允许在多轮对话中保留有关特定实体的信息。
这些记忆组件都是模块化的,可与其他组件组合使用,从而增强机器人的对话管理能力。Memory(记忆)模块可以通过简单的API调用来访问和更新,允许开发人员更轻松地实现对话历史记录的管理和维护。
1.BufferWindow,滑动窗口记忆
这个基于一个固定长度的滑动窗口的“记忆”功能,被直接内置在 LangChain 里面了。在 Langchain 里,把对于整个对话过程的上下文叫做 Memory。任何一个 LLMChain,我们都可以给它加上一个 Memory,来让它记住最近的对话上下文。
随着对话变得越来越长,所需的内存量也变得非常长。将大量的tokens发送到LLM的成本,也会变得更加昂贵,这也就是为什么API的调用费用,通常是基于它需要处理的tokens数量而收费的。
针对以上问题,LangChain也提供了几种方便的memory来保存历史对话。其中,对话缓存窗口记忆只保留一个窗口大小的对话缓存区窗口记忆。它只使用最近的n次交互。这可以用于保持最近交互的滑动窗口,以便缓冲区不会过大
from langchain import PromptTemplate, LLMChain, OpenAIfrom langchain.memory import ConversationBufferWindowMemoryimport openai, os
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
template = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:1. 你的回答必须是中文2. 回答限制在100个字以内
{chat_history}Human: {human_input}Chatbot:"""
prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template)memory = ConversationBufferWindowMemory(memory_key="chat_history", k=3)llm_chain = LLMChain( llm=OpenAI(), prompt=prompt, memory=memory, verbose=True)llm_chain.predict(human_input="你是谁?")
llm_chain.predict(human_input="鱼香肉丝怎么做?")llm_chain.predict(human_input="那宫保鸡丁呢?")llm_chain.predict(human_input="我问你的第一句话是什么?")(1)memory.buffer
memory.buffer存储了当前为止所有的对话信息
(2)打印历史消息
可以直接调用 memory 的 load_memory_variables 方法,它会直接返回 memory 里实际记住的对话内容。
memory.load_memory_variables({}){'chat_history': 'Human: 那宫保鸡丁呢?\nAI: 宫保鸡丁是一道经典的中国家常菜,需要准备鸡肉、花生米、干辣椒、葱、姜、蒜、料酒、盐、糖、胡椒粉、鸡精和醋。将鸡肉切成小块,放入盐水中浸泡,把其他食材切成小块,将花生米放入油锅中炸,再加入鸡肉和其他食材,炒至入味即可。\nHuman: 我问你的第一句话是什么?\nAI: 你是谁?\nHuman: 我问你的第一句话是什么?\nAI: 你问我的第一句话是“鱼香肉丝怎么做?”'}(3)添加指定的输入输出内容到记忆缓存区
memory = ConversationBufferMemory() #新建一个空的对话缓存记忆
memory.save_context({"input": "Hi"}, #向缓存区添加指定对话的输入输出 {"output": "What's up"})
print(memory.buffer) #查看缓存区结果2.SummaryMemory,把小结作为历史记忆
使用 BufferWindow 这样的滑动窗口有一个坏处,就是几轮对话之后,AI 就把一开始聊的内容给忘了。遇到这种情况,可以让 AI 去总结一下前面几轮对话的内容。这样,我们就不怕对话轮数太多或者太长了。同样的,Langchain 也提供了一个 ConversationSummaryMemory,可以实现这样的功能
-
第一个是对于我们定义的 ConversationSummaryMemory,它的构造函数也接受一个 LLM 对象。这个对象会专门用来生成历史对话的小结,是可以和对话本身使用的 LLM 对象不同的。
-
第二个是这次我们没有使用 LLMChain 这个对象,而是用了封装好的 ConversationChain。用 ConversationChain 的话,其实我们是可以不用自己定义 PromptTemplate 来维护历史聊天记录的,但是为了使用中文的 PromptTemplate,我们在这里还是自定义了对应的 Prompt。
from langchain import PromptTemplate, LLMChain, OpenAIfrom langchain.memory import ConversationBufferWindowMemoryimport openai, os
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
from langchain.chains import ConversationChainfrom langchain.memory import ConversationSummaryMemoryllm = OpenAI(temperature=0)memory = ConversationSummaryMemory(llm=OpenAI())
prompt_template = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:1. 你的回答必须是中文2. 回答限制在100个字以内
{history}Human: {input}AI:"""prompt = PromptTemplate( input_variables=["history", "input"], template=prompt_template)conversation_with_summary = ConversationChain( llm=llm, memory=memory, prompt=prompt, verbose=True)conversation_with_summary.predict(input="你好")> Entering new ConversationChain chain...Prompt after formatting:你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:1. 你的回答必须是中文2. 回答限制在100个字以内
Human: 你好AI:> Finished chain.' 你好,我可以帮你做菜。我会根据你的口味和喜好,结合当地的食材,制作出美味可口的菜肴。我会尽力做出最好的菜肴,让你满意。'在我们打开了 ConversationChain 的 Verbose 模式,然后再次询问 AI 第二个问题的时候,你可以看到,在 Verbose 的信息里面,没有历史聊天记录,而是多了一段对之前聊天内容的英文小结。
conversation_with_summary.predict(input="鱼香肉丝怎么做?")> Entering new ConversationChain chain...Prompt after formatting:你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:1. 你的回答必须是中文2. 回答限制在100个字以内
The human greeted the AI and the AI responded that it can help cook by combining local ingredients and tailor the meal to the human's tastes and preferences. It promised to make the best dishes possible to the human's satisfaction.Human: 鱼香肉丝怎么做?AI:> Finished chain.
' 鱼香肉丝是一道经典的家常菜,需要准备肉丝、葱姜蒜、鱼香调料、豆瓣酱、醋、糖、盐等调料,先将肉丝用盐、料酒、胡椒粉腌制,然后炒锅里放入葱姜蒜爆香,加入肉丝翻炒,加入鱼香调料、豆瓣酱、醋、糖等调料,最后放入少许水煮熟即可。'3.两者结合,使用 SummaryBufferMemory
虽然 SummaryMemory 可以支持更长的对话轮数,但是它也有一个缺点,就是即使是最近几轮的对话,记录的也不是精确的内容。当你问“上一轮我问的问题是什么?”的时候,它其实没法给出准确的回答。不过,相信你也想到了,我们把 BufferMemory 和 SummaryMemory 结合一下不就好了吗?没错,LangChain 里还真提供了一个这样的解决方案,就叫做 ConversationSummaryBufferMemory。
from langchain import PromptTemplate, LLMChain, OpenAIfrom langchain.memory import ConversationBufferWindowMemoryimport openai, os
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
from langchain import PromptTemplatefrom langchain.chains import ConversationChainfrom langchain.memory import ConversationSummaryBufferMemoryfrom langchain.llms import OpenAI
SUMMARIZER_TEMPLATE = """请将以下内容逐步概括所提供的对话内容,并将新的概括添加到之前的概括中,形成新的概括。
EXAMPLECurrent summary:Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量。
New lines of conversation:Human:为什么你认为人工智能是一种积极的力量?AI:因为人工智能将帮助人类发挥他们的潜能。
New summary:Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量,因为它将帮助人类发挥他们的潜能。END OF EXAMPLE
Current summary:{summary}
New lines of conversation:{new_lines}
New summary:"""
SUMMARY_PROMPT = PromptTemplate( input_variables=["summary", "new_lines"], template=SUMMARIZER_TEMPLATE)
memory = ConversationSummaryBufferMemory(llm=OpenAI(), prompt=SUMMARY_PROMPT, max_token_limit=256)
CHEF_TEMPLATE = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:1. 你的回答必须是中文。2. 对于做菜步骤的回答尽量详细一些。
{history}Human: {input}AI:"""CHEF_PROMPT = PromptTemplate( input_variables=["history", "input"], template=CHEF_TEMPLATE)
conversation_with_summary = ConversationChain( llm=OpenAI(model_name="text-davinci-003", stop="\n\n", max_tokens=2048, temperature=0.5), prompt=CHEF_PROMPT, memory=memory, verbose=True)answer = conversation_with_summary.predict(input="你是谁?")print(answer)定义了一个 ConversationSummaryBufferMemory,在这个 Memory 的构造函数里面,我们指定了使用的 LLM、提示语,以及一个 max_token_limit 参数。max_token_limit 参数,其实就是告诉我们,当对话的长度到多长之后,我们就应该调用 LLM 去把文本内容小结一下。
随着对话轮数的增加,Token 数量超过了前面的 max_token_limit 。于是 SummaryBufferMemory 就会触发,对前面的对话进行小结,也就会出现一个 System 的信息部分,里面是聊天历史的小结,而后面完整记录的实际对话轮数就变少了。我们先问鱼香肉丝怎么做,Verbose 的信息里还是显示历史的聊天记录。
answer = conversation_with_summary.predict(input="请问鱼香肉丝怎么做?")print(answer)> Entering new ConversationChain chain...Prompt after formatting:你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:1. 你的回答必须是中文。2. 对于做菜步骤的回答尽量详细一些。Human: 你是谁?AI: 我是一个中国厨师,您有什么可以问我的关于做菜的问题吗?Human: 请问鱼香肉丝怎么做?AI:> Finished chain. 鱼香肉丝是一道很受欢迎的中国菜,准备材料有:猪肉、木耳、胡萝卜、葱姜蒜、花椒、八角、辣椒、料酒、糖、盐、醋、麻油、香油。做法步骤如下:1. 将猪肉切成薄片,用料酒、盐、糖、醋、麻油抓匀;2. 将木耳洗净,切碎;3. 将胡萝卜切丝;4. 将葱姜蒜切碎;5. 将花椒、八角、辣椒放入油锅中炸熟;6. 将葱姜蒜炒香;7. 加入猪肉片翻炒;8. 加入木耳、胡萝卜丝、花椒、八角、辣椒翻炒;9. 加入盐、糖、醋、麻油、香油调味;10. 加入水煮熟,即可出锅。等到我们再问蚝油牛肉,前面的对话就被小结到 System 下面去了。
answer = conversation_with_summary.predict(input="那蚝油牛肉呢?")print(answer)> Entering new ConversationChain chain...Prompt after formatting:你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:1. 你的回答必须是中文。2. 对于做菜步骤的回答尽量详细一些。System: Human询问AI是谁,AI回答自己是一个中国厨师,并问Human是否有关于做菜的问题。Human问AI如何做出鱼香肉丝,AI回答准备材料有猪肉、木耳、胡萝卜、葱姜蒜、花椒、八角、辣椒、料酒、糖、盐、醋、麻油、香油,做法步骤是将猪肉切成薄片,用料酒、盐、糖、醋、麻油抓匀,木耳Human: 那蚝油牛肉呢?AI:> Finished chain. 准备材料有牛肉、葱、姜、蒜、蚝油、料酒、醋、糖、盐、香油,做法步骤是先将牛肉切成薄片,用料酒、盐、糖、醋、麻油抓匀,然后将葱、姜、蒜切碎,加入蚝油拌匀,最后加入香油搅拌均匀即可。当然,在你实际使用 SummaryBufferMemory 的时候,并不需要把各个 Prompt 都改成自定义的中文版本。用默认的英文 Prompt 就足够了。因为在 Verbose 信息里出现的 System 信息并不会在实际的对话进行过程中显示给用户。这部分提示,只要 AI 自己能够理解就足够了。当然,你也可以根据实际对话的效果,来改写自己需要的提示语。
不过,在运行程序的过程里,你应该可以感觉到现在程序跑得有点儿慢。这是因为我们使用 ConversationSummaryBufferMemory 很多时候要调用多次 OpenAI 的 API。在字数超过 max_token_limit 的时候,需要额外调用一次 API 来做小结。而且这样做,对应的 Token 数量消耗也是不少的。所以,不是所有的任务,都适合通过调用一次 ChatGPT 的 API 来解决。很多时候,你还是可以多思考是否可以用 UtilityChain 和 TransformChain 来解决问题。
4.让 AI 记住点有用的信息
我们不仅可以在整个对话过程里,使用我们的 Memory 功能。如果你之前已经有了一系列的历史对话,我们也可以通过 Memory 提供的 save_context 接口,把历史聊天记录灌进去。然后基于这个 Memory 让 AI 接着和用户对话。比如下面我们就把一组电商客服历史对话记录给了 SummaryBufferMemory。
from langchain import PromptTemplate, LLMChain, OpenAIfrom langchain import PromptTemplatefrom langchain.chains import ConversationChainfrom langchain.memory import ConversationSummaryBufferMemoryfrom langchain.llms import OpenAIimport openai, osfrom langchain.memory.prompt import SUMMARY_PROMPT
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
memory = ConversationSummaryBufferMemory(llm=OpenAI(), prompt=SUMMARY_PROMPT, max_token_limit=40)memory.save_context( {"input": "你好"}, {"ouput": "你好,我是客服李四,有什么我可以帮助您的么"})memory.save_context( {"input": "我叫张三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货"}, {"ouput": "好的,您稍等,我先为您查询一下您的订单"})print(memory.load_memory_variables({})){'history': 'System: \nHuman和AI打招呼,AI介绍自己是客服李四,问Human有什么可以帮助的。Human提供订单号和邮箱地址,AI表示会为其查询订单状态。'}注:为了演示方便,我设置了一个很小的 max_token_limit,但是这个问题在大的 max_token_limit 下,面对上下文比较多的会话一样会有问题。
通过调用 memory.load_memory_variables 方法,我们发现 AI 对整段对话做了小结。但是这个小结有个问题,就是它并没有提取到我们最关注的信息,比如用户的订单号、用户的邮箱。只有有了这些信息,AI 才能够去查询订单,拿到结果然后回答用户的问题。
以前在还没有 ChatGPT 的时代,在客服聊天机器人这样的领域,我们会通过命名实体识别的方式,把邮箱、订单号之类的关键信息提取出来。在有了 ChatGPT 这样的大语言模型之后,我们还是应该这样做。不过我们不是让专门的命名实体识别的算法做,而是直接让 ChatGPT 帮我们做。Langchain 也内置了一个 EntityMemory 的封装,让 AI 自动帮我们提取这样的信息。
from langchain.chains import ConversationChainfrom langchain.memory import ConversationEntityMemoryfrom langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
entityMemory = ConversationEntityMemory(llm=llm)conversation = ConversationChain( llm=llm, verbose=True, prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE, memory=entityMemory)
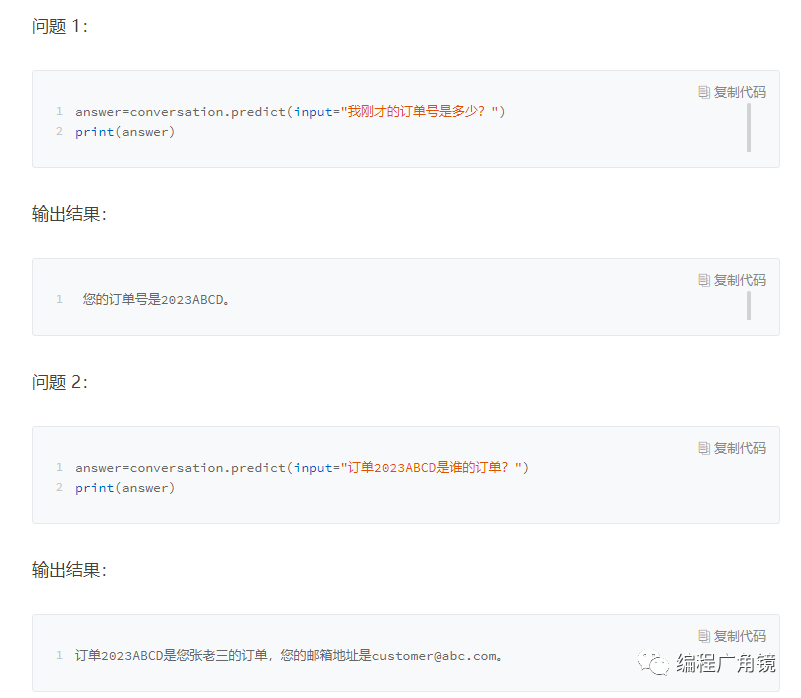
answer=conversation.predict(input="我叫张老三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货")print(answer)> Entering new ConversationChain chain...Prompt after formatting:You are an assistant to a human, powered by a large language model trained by OpenAI.You are designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, you are able to generate human-like text based on the input you receive, allowing you to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.You are constantly learning and improving, and your capabilities are constantly evolving. You are able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. You have access to some personalized information provided by the human in the Context section below. Additionally, you are able to generate your own text based on the input you receive, allowing you to engage in discussions and provide explanations and descriptions on a wide range of topics.Overall, you are a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether the human needs help with a specific question or just wants to have a conversation about a particular topic, you are here to assist.Context:{'张老三': '', '2023ABCD': '', 'customer@abc.com': ''}Current conversation:Last line:Human: 我叫张老三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货You:> Finished chain. 您好,张老三,我很抱歉你没有收到货。我们会尽快核实订单信息,并尽快给您处理,请您耐心等待,如果有任何疑问,欢迎您随时联系我们。我们还是使用 ConversationChain,只是这一次,我们指定使用 EntityMemory。可以看到,在 Verbose 的日志里面,整个对话的提示语,多了一个叫做 Context 的部分,里面包含了刚才用户提供的姓名、订单号和邮箱。
进一步,我们把 memory 里面存储的东西打印出来。
print(conversation.memory.entity_store.store)输出结果:{'张老三': '张老三是一位订单号为2023ABCD、邮箱地址为customer@abc.com的客户。', '2023ABCD': '2023ABCD is an order placed by customer@abc.com that has not been received after more than ten days.', 'customer@abc.com': 'Email address of Zhang Lao San, who placed an order with Order Number 2023ABCD, but has not received the goods more than ten days later.'}可以看到,EntityMemory 里面不仅存储了这些命名实体的名字,也对应的把命名实体所关联的上下文记录了下来。这个时候,如果我们再通过对话来询问相关的问题,AI 也能够答上来。
事实上,我们不仅可以把这些 Memory 放在内存里面,还可以进一步把它们存放在 Redis 这样的外部存储里面。这样即使我们的服务进程消失了,这些“记忆”也不会丢失
四、LangChain做决策
1.Router Chain(路由链)
一个相当常见但基本的操作是根据输入将其路由到一条链,具体取决于该输入到底是什么。如果你有多个子链,每个子链都专门用于特定类型的输入,那么可以组成一个路由链,它首先决定将它传递给哪个子链,然后将它传递给那个链。
路由器由两个组件组成:
-
路由器链本身(负责选择要调用的下一个链)
-
destination_chains:路由器链可以路由到的链
(1)定义提示模板
#第一个提示适合回答物理问题physics_template = """You are a very smart physics professor. \You are great at answering questions about physics in a concise\and easy to understand manner. \When you don't know the answer to a question you admit\that you don't know.
Here is a question:{input}"""
#第二个提示适合回答数学问题math_template = """You are a very good mathematician. \You are great at answering math questions. \You are so good because you are able to break down \hard problems into their component parts, answer the component parts, and then put them together\to answer the broader question.
Here is a question:{input}"""
#第三个适合回答历史问题history_template = """You are a very good historian. \You have an excellent knowledge of and understanding of people,\events and contexts from a range of historical periods. \You have the ability to think, reflect, debate, discuss and \evaluate the past. You have a respect for historical evidence\and the ability to make use of it to support your explanations \and judgements.
Here is a question:{input}"""
#第四个适合回答计算机问题computerscience_template = """ You are a successful computer scientist.\You have a passion for creativity, collaboration,\forward-thinking, confidence, strong problem-solving capabilities,\understanding of theories and algorithms, and excellent communication \skills. You are great at answering coding questions. \You are so good because you know how to solve a problem by \describing the solution in imperative steps \that a machine can easily interpret and you know how to \choose a solution that has a good balance between \time complexity and space complexity.
Here is a question:{input}"""首先需要定义这些提示模板,在我们拥有了这些提示模板后,可以为每个模板命名,然后提供描述。例如,第一个物理学的描述适合回答关于物理学的问题,这些信息将传递给路由链,然后由路由链决定何时使用此子链。prompt_infos = [ { "name": "physics", "description": "Good for answering questions about physics", "prompt_template": physics_template }, { "name": "math", "description": "Good for answering math questions", "prompt_template": math_template }, { "name": "History", "description": "Good for answering history questions", "prompt_template": history_template }, { "name": "computer science", "description": "Good for answering computer science questions", "prompt_template": computerscience_template }](2)导入相关的包
from langchain.chains.router import MultiPromptChain #导入多提示链from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParserfrom langchain.prompts import PromptTemplate(3)定义语言模型
OPENAI_API_KEY = "********" #"填入你的专属的API key"llm = ChatOpenAI(temperature=0,openai_api_key=OPENAI_API_KEY)(4)LLMRouterChain
在这里,我们需要一个多提示链。这是一种特定类型的链,用于在多个不同的提示模板之间进行路由。但是,这只是你可以路由的一种类型。你也可以在任何类型的链之间进行路由。这里我们要实现的几个类是LLM路由器链。这个类本身使用语言模型来在不同的子链之间进行路由。这就是上面提供的描述和名称将被使用的地方。
2.Langchain 里面的中介与特工:Agent
Agent 翻译成中文,有两个意思。一个叫做代理人,比如在美国你买房子、租房子,都要通过 Real Estate Agent,也就是“房产代理”,其实就是我们这里说的“中介”。另一个意思,叫做“特工”,这是指 Agent 是有自主行动能力的,它可以根据你提出的要求,直接使用提供的工具采取行动。它不只是做完选择题就完事儿了,而是直接拿起选中的工具进行下一步的行动。Langchain 的 Agent 其实这两个意思都包含
(1)案例演示
from langchain.agents import initialize_agent, Toolfrom langchain.llms import OpenAI
llm = OpenAI(temperature=0)
def search_order(input: str) -> str: return "订单状态:已发货;发货日期:2023-01-01;预计送达时间:2023-01-10"
def recommend_product(input: str) -> str: return "红色连衣裙"
def faq(intput: str) -> str: return "7天无理由退货"
tools = [ Tool( name = "Search Order",func=search_order, description="useful for when you need to answer questions about customers orders" ), Tool(name="Recommend Product", func=recommend_product, description="useful for when you need to answer questions about product recommendations" ), Tool(name="FAQ", func=faq, description="useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc." )]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)-
首先,我们定义了三个函数,分别叫做 search_order、recommend_product 以及 faq。它们的输入都是一个字符串,输出是我们写好的对于问题的回答。
-
然后,我们针对这三个函数,创建了一个 Tool 对象的数组,把这三个函数分别封装在了三个 Tool 对象里面。每一个 Tool 的对象,在函数之外,还定义了一个名字,并且定义了 Tool 的 description。这个 description 就是告诉 AI,这个 Tool 是干什么用的。就像这一讲一开始的那个例子一样,AI 会根据问题以及这些描述来做选择题。
-
最后,我们创建了一个 agent 对象,指定它会用哪些 Tools、LLM 对象以及 agent 的类型。在 agent 的类型这里,我们选择了 zero-shot-react-description。这里的 zero-shot 就是指我们在课程一开始就讲过的“零样本分类”,也就是不给 AI 任何例子,直接让它根据自己的推理能力来做决策。而 react description,指的是根据你对于 Tool 的描述(description)进行推理(Reasoning)并采取行动(Action)。
在有了这个 agent 之后,我们不妨尝试一下,直接对着这个 Agent,来重新问一遍刚才的三个问题。
agent=AgentType.OPENAI_FUNCTIONS,
问题一
question = "我想买一件衣服,但是不知道哪个款式好看,你能帮我推荐一下吗?"result = agent.run(question)print(result)
> Entering new AgentExecutor chain... I need to recommend a product.Action: Recommend ProductAction Input: ClothesObservation: 红色连衣裙Thought: I now know the final answer.Final Answer: 我推荐红色连衣裙。问题二
question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?"result = agent.run(question)print(result)
> Entering new AgentExecutor chain... I need to find out the status of the orderAction: Search OrderAction Input: 2022ABCDEObservation: 订单状态:已发货;发货日期:2023-01-01;预计送达时间:2023-01-10Thought: I now know the final answerFinal Answer: 您的订单 2022ABCDE 已发货,预计将于2023-01-10送达。> Finished chain.您的订单 2022ABCDE 已发货,预计将于2023-01-10送达。问题三
question = "请问你们的货,能送到三亚吗?大概需要几天?"result = agent.run(question)print(result)> Entering new AgentExecutor chain... I need to find out the shipping policy and delivery timeAction: FAQAction Input: Shipping policy and delivery timeObservation: 7天无理由退货Thought: I need to find out the delivery timeAction: FAQAction Input: Delivery timeObservation: 7天无理由退货Thought: I need to find out if we can deliver to SanyaAction: FAQAction Input: Delivery to SanyaObservation: 7天无理由退货Thought: I now know the final answerFinal Answer: 我们可以把货送到三亚,大概需要7天。> Finished chain.我们可以把货送到三亚,大概需要7天。在这些回答中我们可以发现两个问题
-
第一个,是 Agent 每一步的操作,可以分成 5 个步骤,分别是 Action、Action Input、Observation、Thought,最后输出一个 Final Answer。
-
Action,就是根据用户的输入,选择应该选取哪一个 Tool,然后行动。
-
Action Input,就是根据需要使用的 Tool,从用户的输入里提取出相关的内容,可以输入到 Tool 里面。
-
Oberservation,就是观察通过使用 Tool 得到的一个输出结果。
-
Thought,就是再看一眼用户的输入,判断一下该怎么做。
-
Final Answer,就是 Thought 在看到 Obersavation 之后,给出的最终输出。
-
-
第二个,就是我们最后那个“货需要几天送到三亚”的问题,没有遵循上面的 5 个步骤,而是在第 4 步 Thought 之后,重新回到了 Action。并且在这样反复三次之后,才不得已强行回答了问题。但是给出的答案,其实并不一定准确,因为我们的回答里面并没有说能不能送到三亚。
(2)initialize_agent参数
agent= initialize_agent( tools, #第二步加载的工具 llm, #第一步初始化的模型 agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, #代理类型 handle_parsing_errors=True, #处理解析错误 verbose = True #输出中间步骤)-
agent: 代理类型。这里使用的是AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION。其中CHAT代表代理模型为针对对话优化的模型,REACT代表针对REACT设计的提示模版。
-
zero-shot-react-description:该代理使用ReAct框架仅根据工具的描述来确定要使用哪个工具,可以提供任意数量的工具。要求为每个工具提供一个描述。
-
react-docstore:该代理使用ReAct框架与文档存储(docstore)进行交互。必须提供两个工具:一个搜索工具和一个查找工具(它们必须确切地命名为Search和Lookup)。搜索工具应该用于搜索文档,而查找工具应该在最近找到的文档中查找术语。该代理等同于原始的ReAct论文,特别是维基百科的示例。
-
self-ask-with-search:该代理使用一个名为Intermediate Answer的单一工具。这个工具应该能够查找问题的事实性答案。这个代理等同于原始的自问自答(self-ask)与搜索论文,其中提供了作为工具的谷歌搜索API。
-
conversational-react-description:该代理旨在用于对话设置中。提示让代理在对话中变得有帮助。它使用ReAct框架来决定使用哪个工具,并使用内存来记住之前的对话互动。
-
structured-chat-zero-shot-react-description: 在对话中可以使用任意的工具,并且能够记住对话的上下文。
-
-
handle_parsing_errors: 是否处理解析错误。当发生解析错误时,将错误信息返回给大模型,让其进行纠正。
-
verbose: 是否输出中间步骤结果。
(3)Tools加载
Tools可以使用自定义也可以使用现有的。
-
llm-math 工具结合语言模型和计算器用以进行数学计算
-
wikipedia工具通过API连接到wikipedia进行搜索查询。
tools = load_tools( ["llm-math","wikipedia"], llm=llm #第一步初始化的模型 )
自定义tool时我们需要给函数加上非常详细的文档字符串, 使得代理知道在什么情况下、如何使用该函数/工具。tool函数装饰器可以应用用于任何函数,将函数转化为LongChain工具,使其成为代理可调用的工具。
@tooldef time(text: str) -> str: """Returns todays date, use this for any \ questions related to knowing todays date. \ The input should always be an empty string, \ and this function will always return todays \ date - any date mathmatics should occur \ outside this function.""" return str(date.today())(4)通过 max_iterations 限制重试次数
前面这个反复思考 3 次,其实是 Agent 本身的功能。因为实际很多逻辑处理,现在都是通过 AI 的大语言模型这个黑盒子自动进行的,有时候也不一定准。所以 AI 会在 Thought 的时候,看一下回答得是否靠谱,如果不靠谱的话,它会想一个办法重试。如果你希望 AI 不要不断重试,也不要强行回答,在觉得不靠谱的时候,试个一两次就停下来。那么,你在创建 Agent 的时候,设置 max_iterations 这个参数就好了。下面我们就把参数设置成 2,看看效果会是怎么样的。
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", max_iterations = 2, verbose=True)question = "请问你们的货,能送到三亚吗?大概需要几天?"result = agent.run(question)print("===")print(result)print("===")> Entering new AgentExecutor chain... I need to find out the shipping policyAction: FAQAction Input: Shipping policyObservation: 7天无理由退货Thought: I need to find out the shipping timeAction: FAQAction Input: Shipping timeObservation: 7天无理由退货Thought:> Finished chain.===Agent stopped due to max iterations.===这个时候,AI 重试了两次就不再重试。并且,也没有强行给出一个回答,而是告诉你,Agent 因为 max iterations 的设置而中止了。这样,你可以把 AI 回答不上来的问题,切换给人工客服回答。
(4)自定义tool(参数)
class TotalDeliverySchema(BaseModel): search_time: str = Field(description="Time-related keywords,与时间有关的关键词") city_name: str = Field(description="the city of china, 如果未识别到就为None", default=None) store_code_list: List[str | None] = Field(description="the code of store, like SHA001", default=[])
class TotalDeliveryAPI(APIBase):
def __init__(self, field_name=KPI_SUMMARY): super().__init__(field_name)
def run(self, search_time: str, city_name: str, store_code_list: List[str]): res = self._run(search_time, city_name, store_code_list, "ALL") return res
class TotalDeliveryTool(BaseTool): name = "total_delivery_business_situation" description = "get situation of total delivery, 即得到外送整体生意情况" args_schema: Type[BaseModel] = TotalDeliverySchema
def _run(self, search_time: str, city_name: str = None, store_code_list=None): res = TotalDeliveryAPI().run(search_time, city_name, store_code_list) return res
def _arun(self, search_time: str, city_name: str = None, store_code_list=None): raise NotImplementedError(f"{TotalDeliveryTool.name} does not support async")
from langchain.tools import BaseToolfrom typing import Unionfrom langchain.agents import initialize_agentfrom langchain.chat_models import ChatOpenAIfrom langchain.chains.conversation.memory import ConversationBufferWindowMemoryfrom typing import Optional
llm = ChatOpenAI(model_name="gpt-3.5-turbo", max_tokens=2048, temperature=0.5,openai_api_key='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',openai_api_base='https://api.openai-proxy.com/v1')
# initialize conversational memoryconversational_memory = ConversationBufferWindowMemory( memory_key='chat_history', k=5, return_messages=True)
tools = [MeituanExposureFallReason(),Proprietary(),TotalDeliverySales()]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
question = "帮我分析一下上海的昨日KPI?(请用中文回复)"result = agent.run(question)print(result)3.通过 VectorDBQA 让 Tool 支持问答
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import FAISSfrom langchain.text_splitter import SpacyTextSplitterfrom langchain import OpenAI, VectorDBQAfrom langchain.document_loaders import TextLoader
llm = OpenAI(temperature=0)loader = TextLoader('./data/ecommerce_faq.txt')documents = loader.load()text_splitter = SpacyTextSplitter(chunk_size=256, pipeline="zh_core_web_sm")texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()docsearch = FAISS.from_documents(texts, embeddings)
faq_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=docsearch, verbose=True)然后,把这 LLMChain 的 run 方法包装到一个 Tool 里面。from langchain.agents import tool
@tool("FAQ")def faq(intput: str) -> str: """"useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc.""" return faq_chain.run(intput)
tools = [ Tool( name = "Search Order",func=search_order, description="useful for when you need to answer questions about customers orders" ), Tool(name="Recommend Product", func=recommend_product, description="useful for when you need to answer questions about product recommendations" ), faq]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)这里,我们对 Tool 的写法做了一些小小的改变,使得代码更加容易维护了。我们通过 @tool 这个 Python 的 decorator 功能,将 FAQ 这个函数直接变成了 Tool 对象,这可以减少我们每次创建 Tools 的时候都要指定 name 和 description 的工作。question = "请问你们的货,能送到三亚吗?大概需要几天?"result = agent.run(question)print(result)> Entering new AgentExecutor chain... I need to find out the shipping policy and delivery time.Action: FAQAction Input: shipping policy and delivery time> Entering new VectorDBQA chain...> Finished chain.Observation: 一般情况下,大部分城市的订单在2-3个工作日内送达,偏远地区可能需要5-7个工作日。具体送货时间可能因订单商品、配送地址和物流公司而异。Thought: I now know the final answer.Final Answer: 一般情况下,大部分城市的订单在2-3个工作日内送达,偏远地区可能需要5-7个工作日。具体送货时间可能因订单商品、配送地址和物流公司而异。> Finished chain.一般情况下,大部分城市的订单在2-3个工作日内送达,偏远地区可能需要5-7个工作日。具体送货时间可能因订单商品、配送地址和物流公司而异。4.优化 Prompt,让 AI 不要胡思乱想
对于订单查询,使用向量检索就不太合适了,我们直接拿着订单号去数据库里查就好了。
import openai, osfrom langchain.agents import initialize_agentfrom langchain.agents import toolfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.document_loaders import CSVLoaderfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import FAISSfrom langchain.text_splitter import SpacyTextSplitterfrom langchain import OpenAI, VectorDBQAfrom langchain.document_loaders import TextLoaderimport json
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
llm = OpenAI(temperature=0)loader = TextLoader('data/ecommerce_faq.txt', encoding='utf-8')documents = loader.load()text_splitter = SpacyTextSplitter(chunk_size=256, pipeline="zh_core_web_sm")texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()docsearch = FAISS.from_documents(texts, embeddings)
faq_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=docsearch, verbose=True)
product_loader = CSVLoader('data/ecommerce_products.csv', encoding='utf-8')product_documents = product_loader.load()product_text_splitter = CharacterTextSplitter(chunk_size=1024, separator="\n")product_texts = product_text_splitter.split_documents(product_documents)product_search = FAISS.from_documents(product_texts, OpenAIEmbeddings())product_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=product_search, verbose=True)
@tool("FAQ")def faq(intput: str) -> str: """"useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc.""" return faq_chain.run(intput)
@tool("Recommend Product")def recommend_product(input: str) -> str: """"useful for when you need to search and recommend products and recommend it to the user""" return product_chain.run(input)
ORDER_1 = "20230101ABC"ORDER_2 = "20230101EFG"
ORDER_1_DETAIL = { "order_number": ORDER_1, "status": "已发货", "shipping_date" : "2023-01-03", "estimated_delivered_date": "2023-01-05",}
ORDER_2_DETAIL = { "order_number": ORDER_2, "status": "未发货", "shipping_date" : None, "estimated_delivered_date": None,}
@tool("Search Order")def search_order(input:str)->str: """useful for when you need to answer questions about customers orders""" if input.strip() == ORDER_1: return json.dumps(ORDER_1_DETAIL) elif input.strip() == ORDER_2: return json.dumps(ORDER_2_DETAIL) else: return f"对不起,根据{input}没有找到您的订单"
tools = [search_order,recommend_product, faq]agent = initialize_agent(tools, llm=OpenAI(temperature=0), agent="zero-shot-react-description", verbose=True)
question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?"answer = agent.run(question)print(answer)> Entering new AgentExecutor chain... I need to find out the status of the order.Action: Search OrderAction Input: 2022ABCDEObservation: 对不起,根据2022ABCDE没有找到您的订单Thought: I need to find out more information about the order.Action: Search OrderAction Input: 2022ABCDEObservation: 对不起,根据2022ABCDE没有找到您的订单Thought: I need to contact customer service for more information.Action: FAQAction Input: 订单查询> Entering new VectorDBQA chain...> Finished chain.Observation: 要查询订单,请登录您的帐户,然后点击“我的订单”页面。在此页面上,您可以查看所有订单及其当前状态。如果您没有帐户,请使用订单确认电子邮件中的链接创建一个帐户。如果您有任何问题,请联系客服。Thought: I now know the final answer.Final Answer: 要查询订单,请登录您的帐户,然后点击“我的订单”页面。在此页面上,您可以查看所有订单及其当前状态。如果您没有帐户,请使用订单确认电子邮件中的链接创建一个帐户。如果您有任何问题,请联系客服。> Finished chain.要查询订单,请登录您的帐户,然后点击“我的订单”页面。在此页面上,您可以查看所有订单及其当前状态。如果您没有帐户,请使用订单确认电子邮件中的链接创建一个帐户。如果您有任何问题,请联系客服。我们输入了一个不存在的订单号,我们原本期望,AI 能够告诉我们订单号找不到。但是,它却是在发现回复是找不到订单的时候,重复调用 OpenAI 的思考策略,并最终尝试从 FAQ 里拿一个查询订单的问题来敷衍用户。这并不是我们想要的,这也是以前很多“人工智障”类型的智能客服常常会遇到的问题,所以我们还是想个办法解决它。解决的方法也不复杂,我们只需要调整一下 search_order 这个 Tool 的提示语。通过这个提示语,Agent 会知道,这个工具就应该在找不到订单的时候,告诉用户找不到订单或者请它再次确认。这个时候,它就会根据这个答案去回复用户。下面是对应修改运行后的结果。import re
// 注意下面未知是prompt信息,一定要有的@tool("Search Order")def search_order(input:str)->str: """一个帮助用户查询最新订单状态的工具,并且能处理以下情况: 1. 在用户没有输入订单号的时候,会询问用户订单号 2. 在用户输入的订单号查询不到的时候,会让用户二次确认订单号是否正确""" pattern = r"\d+[A-Z]+" match = re.search(pattern, input)
order_number = input if match: order_number = match.group(0) else: return "请问您的订单号是多少?" if order_number == ORDER_1: return json.dumps(ORDER_1_DETAIL) elif order_number == ORDER_2: return json.dumps(ORDER_2_DETAIL) else: return f"对不起,根据{input}没有找到您的订单"
tools = [search_order,recommend_product, faq]agent = initialize_agent(tools, llm=OpenAI(temperature=0), agent="zero-shot-react-description", verbose=True)
question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?"answer = agent.run(question)print(answer)> Entering new AgentExecutor chain... 我需要查询订单状态Action: Search OrderAction Input: 2022ABCDEObservation: 对不起,根据2022ABCDE没有找到您的订单Thought: 我需要再次确认订单号是否正确Action: Search OrderAction Input: 2022ABCDEObservation: 对不起,根据2022ABCDE没有找到您的订单Thought: 我现在知道最终答案Final Answer: 对不起,根据您输入的订单号2022ABCDE没有找到您的订单,请您再次确认订单号是否正确。> Finished chain.对不起,根据您输入的订单号2022ABCDE没有找到您的订单,请您再次确认订单号是否正确。5.通过多轮对话实现订单查询
我们的客服聊天机器人已经搞定了。但是,其实我们还有几个可以优化的空间。
-
我们应该支持多轮聊天。因为用户不一定是在第一轮提问的时候,就给出了自己的订单号。
-
我们其实可以直接让 Search Order 这个 Tool,回答用户的问题,没有必要再让 Agent 思考一遍。
import openai, osfrom langchain.agents import initialize_agentfrom langchain.agents import toolfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.document_loaders import CSVLoaderfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import FAISSfrom langchain.text_splitter import SpacyTextSplitterfrom langchain import OpenAI, VectorDBQA, PromptTemplate, LLMChainfrom langchain.document_loaders import TextLoaderimport json
openai.api_key = os.environ.get("OPENAI_API_KEY")proxy = { 'http': 'http://localhost:7890'}openai.proxy = proxy
llm = OpenAI(temperature=0)loader = TextLoader('data/ecommerce_faq.txt', encoding='utf-8')documents = loader.load()text_splitter = SpacyTextSplitter(chunk_size=256, pipeline="zh_core_web_sm")texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()docsearch = FAISS.from_documents(texts, embeddings)
faq_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=docsearch, verbose=True)
product_loader = CSVLoader('data/ecommerce_products.csv', encoding='utf-8')product_documents = product_loader.load()product_text_splitter = CharacterTextSplitter(chunk_size=1024, separator="\n")product_texts = product_text_splitter.split_documents(product_documents)product_search = FAISS.from_documents(product_texts, OpenAIEmbeddings())product_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=product_search, verbose=True)
@tool("FAQ")def faq(intput: str) -> str: """"useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc.""" return faq_chain.run(intput)
@tool("Recommend Product")def recommend_product(input: str) -> str: """"useful for when you need to search and recommend products and recommend it to the user""" return product_chain.run(input)
ORDER_1 = "20230101ABC"ORDER_2 = "20230101EFG"
ORDER_1_DETAIL = { "order_number": ORDER_1, "status": "已发货", "shipping_date" : "2023-01-03", "estimated_delivered_date": "2023-01-05",}
ORDER_2_DETAIL = { "order_number": ORDER_2, "status": "未发货", "shipping_date" : None, "estimated_delivered_date": None,}
import re
answer_order_info = PromptTemplate( template="请把下面的订单信息回复给用户:\n\n {order}?", input_variables=["order"])answer_order_llm = LLMChain(llm=OpenAI(temperature=0), prompt=answer_order_info)
@tool("Search Order", return_direct=True)def search_order(input:str)->str: """useful for when you need to answer questions about customers orders""" pattern = r"\d+[A-Z]+" match = re.search(pattern, input)
order_number = input if match: order_number = match.group(0) else: return "请问您的订单号是多少?" if order_number == ORDER_1: return answer_order_llm.run(json.dumps(ORDER_1_DETAIL)) elif order_number == ORDER_2: return answer_order_llm.run(json.dumps(ORDER_2_DETAIL)) else: return f"对不起,根据{input}没有找到您的订单"
from langchain.memory import ConversationBufferMemoryfrom langchain.chat_models import ChatOpenAI
tools = [search_order,recommend_product, faq]chatllm=ChatOpenAI(temperature=0)memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)conversation_agent = initialize_agent(tools, chatllm, agent="conversational-react-description", memory=memory, verbose=True)
question1 = "我有一张订单,一直没有收到,能麻烦帮我查一下吗?"answer1 = conversation_agent.run(question1)print(answer1)
question2 = "我的订单号是20230101ABC"answer2 = conversation_agent.run(question2)print(answer2)
question3 = "你们的退货政策是怎么样的?"answer3 = conversation_agent.run(question3)print(answer3)-
第一个改造还是在 Search Order 这个工具上的。首先,我们给这个 Tool 设置了一个参数,叫做 return_direct = True,这个参数是告诉 AI,在拿到这个工具的回复之后,不要再经过 Thought 那一步思考,直接把我们的回答给到用户就好了。设了这个参数之后,你就会发现 AI 不会在没有得到一个订单号的时候继续去反复思考,尝试使用工具,而是会直接去询问用户的订单号。伴随着这个修改,对于查询到的订单号,我们就不能直接返回一个 JSON 字符串了,而是通过 answer_order_llm 这个工具来组织语言文字。
-
第二个改造是我们使用的 Agent,我们把 Agent 换成了 converstional-react-description。这样我们就支持多轮对话了,同时我们也把对应的 LLM 换成了 ChatOpenAI,这样成本更低。并且,我们还需要为这个 Agent 设置一下 memory。
> Entering new AgentExecutor chain...Thought: Do I need to use a tool? YesAction: Search OrderAction Input: 我有一张订单,一直没有收到,能麻烦帮我查一下吗?Observation: 请问您的订单号是多少?
> Finished chain.请问您的订单号是多少?
> Entering new AgentExecutor chain...Thought: Do I need to use a tool? YesAction: Search OrderAction Input: 20230101ABCObservation:
您的订单号为20230101ABC,状态为已发货,发货日期为2023-01-03,预计到货日期为2023-01-05。
> Finished chain.
您的订单号为20230101ABC,状态为已发货,发货日期为2023-01-03,预计到货日期为2023-01-05。
Process finished with exit code 0重试# -*- coding: utf-8 -*-import randomimport openaifrom typing import Callable, Any, Optional
from langchain import OpenAIfrom langchain.callbacks.manager import CallbackManagerForLLMRunfrom openai.error import AuthenticationErrorfrom tenacity import ( before_sleep_log, retry, retry_if_exception_type, stop_after_attempt, wait_exponential,)from langchain.chat_models import ChatOpenAIimport logging
from conf.conf import OPENAI_API_KEY_ARR
logger = logging.getLogger(__name__)
class RetryChatOpenAI(ChatOpenAI):
use_open_key= ''
def _create_retry_decorator(self) -> Callable[[Any], Any]: min_seconds = 1 max_seconds = 30 # Wait 2^x * 1 second between each retry starting with # 4 seconds, then up to 10 seconds, then 10 seconds after wards return retry( reraise=True, stop=stop_after_attempt(self.max_retries), wait=wait_exponential(multiplier=1, min=min_seconds, max=max_seconds), retry=(retry_if_exception_type(openai.error.AuthenticationError) ), before_sleep=before_sleep_log(logger, logging.WARNING), )
def completion_with_retry(self, run_manager: Optional[CallbackManagerForLLMRun] = None, **kwargs: Any) -> Any: """Use tenacity to retry the completion call.""" retry_decorator = self._create_retry_decorator()
@retry_decorator def _completion_with_retry(**kwargs: Any) -> Any: # delete error key if self.use_open_key in OPENAI_API_KEY_ARR: OPENAI_API_KEY_ARR.remove(self.use_open_key)
if len(OPENAI_API_KEY_ARR) < 1: raise AuthenticationError("不存在有效的key") client=self.client random_item = random.randint(0, len(OPENAI_API_KEY_ARR)-1) self.use_open_key = OPENAI_API_KEY_ARR[random_item] print("user_key:"+self.use_open_key)
kwargs['api_key'] = self.use_open_key return self.client.create(**kwargs)
return _completion_with_retry(**kwargs)
