
- 1pyhanlp 命名实体识别
- 2Dify:三分钟搞定 小白也能定制自己的 AI 原生应用_dify入门
- 3AI大模型学习:引领智能时代的新篇章
- 4嵌入式linux/鸿蒙开发板(IMX6ULL)开发(三)配置网络环境_realtek usb fe family controller
- 5基于小波变换的医学图像分割_基于小波分解的语义分割
- 6LLaMA-Factory+qwen多轮对话微调
- 7NLP学习笔记——情感分析一 (简介)_nlp情感分析
- 8python图书馆管理系统_基于py的图书馆管理系统
- 9springboot前后端分离项目配置https接口(ssl证书)_ssl证书springboot后端需要配置吗csdn
- 10Python创建自己的聊天机器人_python智能客服机器人代码
AIGC——ComfyUI使用SDXL双模型的工作流(附件SDXL模型下载)
赞
踩
SDXL算法概述
SDXL(Stable Diffusion XL)是Stable Diffusion公司发布的一款图像生成大模型。在以往的模型基础上,SDXL进行了极大的升级,其base模型参数数量达到了35亿,refiner模型参数数量达到了66亿。SDXL与之前的版本最大的不同之处在于它由base基础模型和refiner优化模型两个模型构成,使得用户可以在base模型的基础上再利用优化模型进行绘画,从而更有针对性地优化图像质量。
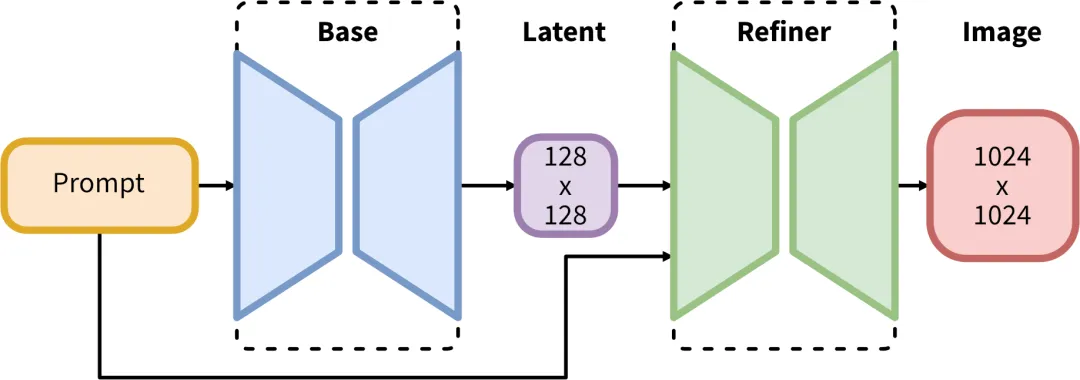
在这里,第一个模型被称为基础模型(base model)。而第二个模型则是细化模型,它在基础模型生成的图像基础上进一步细化图像的细节。细化模型与基础模型采用相同的VAE潜在扩散模型,但在训练时仅使用较低的噪声水平。在推断时,仅使用细化模型的图像生成能力。对于一个提示,首先使用基础模型生成潜在表示,然后给这个潜在表示添加一定的噪声(通过扩散过程),并使用细化模型进行去噪。通过这种重新添加和去除噪声的过程,图像的局部细节会有所提升。
级联细化模型实际上相当于一种模型集成策略,这种策略在文本生成图像领域已经得到了应用。例如,NVIDIA在《eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers》中提出了集成不同的扩散模型来提升生成质量。另外,利用潜在扩散的图像生成来提升质量也已经得到了应用,例如Stable Diffusion web UI中的high res fix就是基于图像生成来实现的(结合超分辨率模型)。
细化模型和基础模型在结构上有一定的不同,其UNet结构如下图所示,细化模型采用4个阶段,第一个阶段同样采用没有注意力的DownBlock2D,网络的特征维度为384,而基础模型为320。此外,细化模型的注意力模块中的transformer block数量均设置为4。细化模型的参数量为2.3B,略小于基础模型。
另外,细化模型的文本编码器仅使用了OpenCLIP ViT-bigG,同样提取倒数第二层特征和池化文本嵌入。与基础模型相同,细化模型也使用了大小和裁剪条件,此外还增加了图像的艺术评分(aesthetic-score)作为条件,处理方式与之前相同。细化模型可能没有采用多尺度微调,因此没有引入目标尺寸作为条件(细化模型仅用于图像生成,可以直接适应各种尺度)。
SDXL的优缺点
优点
- 更大的体积和分辨率:SDXL的容量相比之前版本大幅增加,支持基于1024*1024的高清图片进行训练,这使得生成的图像更加清晰、细节更加丰富。
- 更智能的文字和语言识别:SDXL可以直接生成带有文字的图片,用户可以使用特定的句式来生成带有文字的图片。
1 girl is wearing a helmetthe helmet with the words"SDXL" written on it,

- 同时,SDXL对自然语言的识别能力也得到了提升,不再需要加入大量质量关键词,只需很少的语句就能生成高质量的图片。
A girl with red hair is doing her homework,

- 更好的人体结构:SDXL在人体结构方面有了更精细的控制,一定程度上解决了面部变形和多余肢体等问题。
A solitary, beautiful woman stands gracefully, waiting with an anxious expression on her face,

- 更多的绘画风格:SDXL支持在同一个模型中绘制各种风格的图像,包括照片风格、动漫风格、数字艺术风格、漫画书风格、折纸风格、线条风格、工艺黏土风格、3D模型风格、像素风格等等。
缺点
内存需求更大,对显卡显存的需求也随之增加。SDXL要求至少8GB的显存才能运行,要想流畅使用则需要超过12GB,相比之下,之前的SD1.5对显存的需求较低,最低要求仅为4GB。这也解释了为什么对于一些用户来说,使用SDXL需要配置较高的电脑硬件,而高端显卡的价格也相对较高。
SDXL的ComfyUI工作流搭建

模型与工作流下载
链接:https://pan.baidu.com/s/1gb6iybzyq71XGumTrguj8w
提取码:byyk
感兴趣可加入:566929147 企鹅群一起学习讨论

