
热门标签
热门文章
- 1Python使用PaddleOCR本地进行视频字幕识别_paddleocr python
- 2如何在CentOS使用Docker搭建Rsshub服务并实现无公网IP远程访问
- 3工业互联网平台核心技术之六:安全技术_dcs属于互联网平台嘛
- 4Keras深度学习实战(34)——构建聊天机器人_用keras训练对话机器人
- 5c++常用输出函数详解_c++打印输出语句
- 6CV最新论文|4月1日 arXiv更新论文合集
- 7JSON解析的三种方式
- 8GPT引领前沿与应用突破之GPT4科研实践技术与AI绘图_gpt4-作数学的图
- 9AI大模型学习:理论、实践与未来展望_ai大模型技术进展学习心得
- 10命名实体识别NER & 如何使用BERT实现_bert ner
当前位置: article > 正文
LCQMC 相似度数据集预处理(分句)_lcqmc数据集
作者:羊村懒王 | 2024-03-25 02:30:46
赞
踩
lcqmc数据集
原始数据集样式
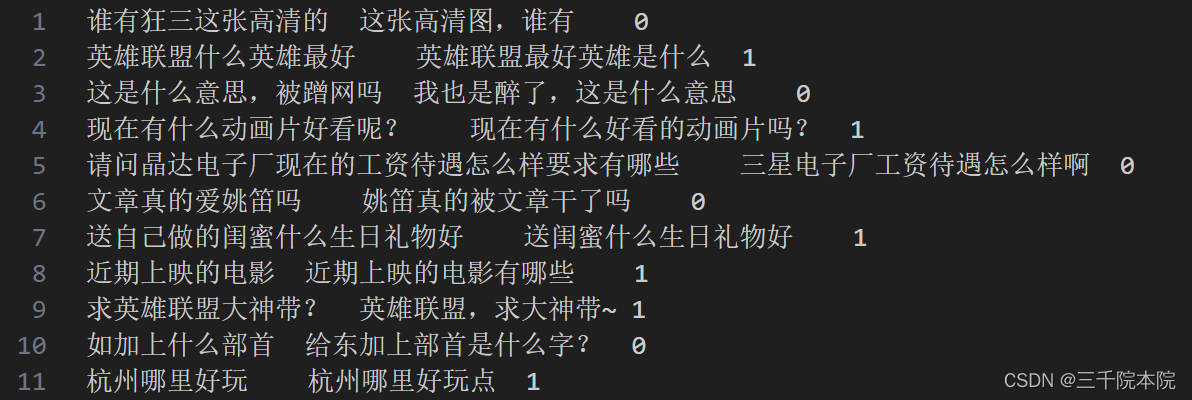 处理后的结果
处理后的结果

代码实现
# 读取数据,指定'r'读取,指定目录(data/LCQMC.test.data原始文件目录) sentence_list = [line.strip() for line in open('data/LCQMC.test.data', "r", encoding='utf-8').readlines()] # 循环并处理每条数据 new_list = [] for count in sentence_list: # 获取分割下标 index = count.find(' ') new_list.append(count[:index]) # 成功输出 # print(new_list) # 打开需要写入的文件, 指定'w'写入,指定目录(需要写入的新文件目录 data/LCQMC.txt) f = open("data/LCQMC.txt","w") # 遍历每一条数据并写入 for new_count in new_list: f.write(new_count) # 写入一条之后换行 f.write('\n') # 关闭文件 f.close

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/306409
推荐阅读
相关标签

