
- 1测试需求分析流程
- 2WebDav多平台挂载详细方法(Linux+Windows+IOS)_webdav挂载
- 3使用Anaconda创建Python虚拟环境并在Pycharm项目中调用该环境_pycharm怎么用anaconda的环境
- 4为什么全网 都在说 iOS 开发不行了 ?_为什么 ios 教程 那么少
- 5《大道至简》改名记_大道至简,给所有人看的编程书
- 6图像拼接融合质量的客观评价指标——matlab实现MSE、均值误差、RMSE、SNR、PSNR,SSIM,熵值计算_图像拼接的指标
- 7解码自然语言处理之 Transformers
- 8Windows Azure 虚拟机的IP地址操作
- 9MySQL查询和更新时的锁表机制分析_数据库 改的同时查询会锁表嘛
- 10Java基于微信小程序高校体育场管理小程序
【域自适应】Dual Path Learning for Domain Adaptation of Semantic Segmentation_uda域自适应
赞
踩
摘要
语义分割的域自适应能够减轻对大规模像素级标注的需求。近年来,结合图像到图像转换的自监督学习(SSL)在自适应分割中显示出很好的效果。最常见的做法是执行 SSL 和图像转换以很好地对齐单个域(源或目标)。然而,在这种单域范式中,图像转换带来的视觉不一致可能会影响后续的学习。在本文中,基于在源域和目标域执行的域自适应框架在图像转换和SSL方面几乎是互补的这一观察结果,我们提出了一种新的双路径学习(DPL)框架来缓解视觉不一致。具体地说,DPL 包含两个互补和交互式的单域适应管道,分别在源域和目标域对齐。DPL的推理非常简单,只使用了目标领域中的一个分割模型。提出了双路径图像平移、双路径自适应分割等新技术,使两条路径以交互方式相互促进。模型效果SOTA。代码和模型可从以下网址获得:https://github.com/royee182/DPL
1.介绍
在语义分割监督学习中需要密集的像素级注释,费力又耗时。为了避免这项艰巨的任务,研究人员试图利用计算机生成的注释,在合成的、具有照片真实感的大规模数据集(GTA5和SYNTHIA)上训练语义分割模型。然而,由于跨域的差异,这些训练好的模型在真实数据集(如Cityscapes)上进行测试时,通常会经历显著的性能下降。因此,无监督域自适应(UDA)方法被广泛应用于调整富标签源数据(合成图像)和无标签目标数据(真实图像)之间的域迁移。
无监督域自适应分割中两种常用的范例是基于图像到图像转换的方法和基于自监督学习(SSL)的方法。基于图像到图像转换的方法最常见的做法是将合成数据从源域(域S)转换为目标域(域T),以减少不同域之间的的视觉差距。然后,对转换后的合成数据进行自适应分割训练。然而,仅将图像到图像的转换应用于域自适应任务,结果往往不能令人满意。其中一个主要因素是图像到图像的转换可能会无意中改变图像内容,导致原始图像和转换图像之间的视觉不一致。使用未修正的源图像真实标签对转换图像进行训练会引入干扰域自适应学习的噪声。
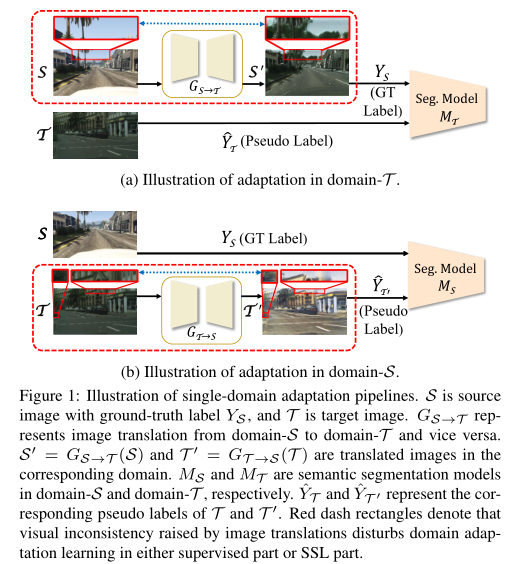
SSL和图像到图像转换的组合在UDA领域被证明非常有效。SSL利用训练好的分割模型为未标记的目标数据生成一组置信度较高的伪标签,然后将自适应分割训练分为两个并行部分,即有监督部分(对有真实标签的源数据进行训练)和SSL部分(对有伪标签的目标数据进行训练)。在这种范例中,最普遍的做法是执行自适应,以很好地对齐单个域,即源域(域S自适应)或目标域(域T自适应)。然而,域S和域T自适应严重依赖于图像到图像转换模型的质量,在这种模型中,会出现视觉不一致。对于域T自适应(如图1.(a)所示),视觉上的不一致导致了转换的源图像与未校正的真实标签之间的不对齐,从而干扰了监督部分。相反,域S自适应(如图1.(b)所示)避免了源图像上的图像转换,但同时引入了目标图像和相应的转换图像之间的视觉不一致性。未对齐图像生成的缺陷伪标签会干扰SSL部分。
注意,就两个训练部分而言,上述单域适应管道几乎是互补的,图像转换引起的视觉不一致干扰了域T适应中监督部分和域S适应中SSL部分的训练。相反,域T适应中的SSL部分和域S适应中的监督部分不受影响。人们自然会提出这样一个问题:我们能否将这两条互补的适应管道组合成一个单一的框架,以充分利用各自的优势,并使它们相互促进,我们提出了双路径学习框架,该框架考虑了来自相反域的两条管道,以缓解图像转换带来的视觉不一致。我们将框架中使用的两条路径分别命名为 Path-T(在域T中执行自适应)和 Path-S(在域S中执行自适应)。Path-S辅助Path-T从源数据学习精确监督,Path-T引导Path-S生成高质量的伪标签,这对 SSL 很重要。值得注意的是,Path-S和Path-T在我们的框架中不是两条独立的管道,两个路径之间的交互在整个训练过程中进行,这在我们的实验中被证明是有效的。整个系统形成一个闭环学习。训练完成后,我们只保留一个在目标域中对齐良好的单个分割模型进行测试,不需要额外的计算。这项工作的主要贡献总结如下:
- 我们提出了一种新的双路径学习(DPL)框架,用于语义分割的领域自适应。DPL在训练阶段采用了两个互补和交互的单域管道(即Path-T和Path-S)。在测试中,仅使用了一个在目标域中对齐良好的分割模型。DPL框架在典型场景中超过了最先进的方法。
- 我们提出了两个交互模块,使两条路径相互促进,即双路径图像转换和双路径自适应分割。
- 我们为分割模型引入了一种新的预热策略,这有助于在早期训练阶段进行自适应分割。
2.相关工作
域适应。域自适应的目的是纠正跨领域中的不匹配,并在测试时调整模型以实现更好的泛化。已经针对图像分类和目标检测提出了多种域自适应方法[28, 3, 33, 13]。本文主要研究语义分割的无监督领域自适应问题。
语义分割的域适应。语义分割需要大量的像素级标注训练数据,标注过程费时费力。降低标注成本的一个解决方案是在对真实数据集(如Cityscapes)进行测试之前,在合成数据集(如GTA5和SYNTHIA)上使用计算机生成的注释对分割网络进行训练。然而,虽然合成图像的外观与真实图像相似,但在布局、颜色和照明条件等方面仍然存在域差异,这往往会削弱模型的性能。域适应对于将合成数据集与真实数据集对齐是必要的。
基于对抗的方法在无监督 域自适应中得到了广泛的探索,它在图像级别或特征级别上对齐不同的域。图像级自适应将域自适应看作一个图像合成问题,旨在未配对的图像到图像转换模型的跨域上减少视觉差异(例如,照明和对象纹理)。然而,仅仅将图像转换应用于域适应任务,其性能往往不令人满意。一个原因是图像到图像的转换可能会无意中改变图像内容,并进一步干扰后续的分割训练。
近年来,自监督学习(SSL)在自适应分割方面显示出巨大的潜力。这些方法的关键原理是为目标图像生成一组伪标签,作为真实标签的近似值,然后利用带有伪标签的目标域数据更新分割模型。CRST是第一个将自训练引入自适应分割的工作,它还通过控制每个类别中选定的伪标签的比例来缓解类别不平衡问题。最近的TPLD提出了一种两阶段伪标签加密策略,以获得SSL的密集伪标签。
标签驱动的[41]执行目标到源的转换,并使用标签驱动的重构模块从相应的预测标签中重建源图像和目标图像。相比之下,BDL是一种双向学习框架,可以交替训练图像翻译和自适应分割。同时,BDL利用单域感知损失来保持视觉一致性。我们将在第3节中证明,与提出的双路径图像转换模块相比,这种设计是次优的。这两项工作表明,图像转换和SSL的结合可以促进自适应学习。与这些单域自适应方法不同,我们提出的双路径学习框架以交互方式集成了两个互补的单域管道,以解决视觉不一致性问题:
(1)利用在不同域中对齐的分割模型为图像转换提供跨域感知监督;
(2)结合源域和目标域的知识进行自我监督学习。
3.方法
给定具有像素级分割标签 Y S Y_S YS的源数据集 S S S(合成数据),以及没有标签的目标数据集 T T T(真实数据)。无监督域自适应(UDA)的目标是,仅通过使用 S , Y S , T S,Y_S,T S,YS,T,分割性能与在具有真实标签 Y T Y_T YT的 T T T上训练的模型一致。S和T之间的域差距使得网络很难一次学习到可转移的知识。

针对这一问题,我们提出了一种新型双路径学习框架DPL。如图2(a)所示,DPL由两条互补的交互路径组成:Path-S(在源域中进行自适应学习)和Path-T(在目标域中进行自适应学习)。如何让这两条路径中的一条向另一条路径提供正反馈是成功的关键。为了实现这一目标,我们提出了两个模块,即双路径图像平移(DPIT)和双路径自适应分割(DPAS)。DPIT 旨在不引入视觉不一致的情况下减少不同域之间的视觉差距。在我们的设计中,DPIT将两个单域分割模型中的一般非配对图像转换模型与双重感知监督相结合。请注意,任何未配对的图像转换模型都可以在DPIT中使用,我们使用CycleGAN作为我们的默认模型,因为它很受欢迎,并且它本身就提供双向图像转换。我们使用 T ′ = G T → S ( T ) T'=G_{T→S}(T) T′=GT→S(T)和 S ′ = G S → T ( S ) S'=G_{S→T}(S) S′=GS→T(S)来各自表示Path-S和Path-T中的图像。其中 G T → S G_{T→S} GT→S和 G S → T G_{S→T} GS→T是对应路径中的图像转换模型。DPAS利用DPIT转换后的图像和提出的双路径伪标签生成(DPPLG)模块为目标图像生成高质量的伪标签,然后利用源域传递的知识和目标域的隐式监督训练分割模型 M S M_S MS(Path-S)和 M T M_T MT(Path-T)。DPL的测试非常简单,我们只保留 M T M_T MT进行推理,如图2(b)所示。
DPL的训练过程包括单路热身和DPL训练两个阶段。DPL受益于初始化良好的 M S M_S MS和 M T M_T MT,因为DPIT和DPAS都依赖于分割模型的质量。一种简单而有效的预热策略可以加速DPL的收敛速度。在热身结束后,DPIT和DPAS将在DPL训练阶段依次进行训练。
在这部分,我们首先在 3.1 节中描述我们的热身策略。然后,我们介绍 DPL 的关键组件:3.2 节中的 DPIT 和 3.3 节中的 DPAS。接下来,我们在第 3.4 节中重新回顾和总结整个训练过程。最后,第 3.5 节介绍了 DPL 的测试管道。
3.1. Single Path Warm-up
DPIT 中的监督和 DPAS 中的伪标签生成依赖于分割模型的质量。为了加速 DPL 的收敛,需要对分割模型 M S M_S MS 和 M T M_T MT 进行预热过程。
M S M_S MS Warm-up。 通过使用带有真实标签 Y S Y_S YS的源数据集S, M S M_S MS热身可以很容易地以有监督的方式进行。
M T M_T MT Warm-up。 由于目标数据集中没有标签可以直接训练 M T M_T MT,因此很难以有监督方式训练 M T M_T MT。一个简单的想法是使用朴素的CycleGAN将源图像S转换为目标域,然后 M T M_T MT通过具有近似真实标签 Y S Y_S YS的转换图像 S ′ S' S′进行训练。不幸的是,朴素CycleGAN没有应用任何约束来保持 S S S和 S ′ S' S′之间的视觉一致性,即当S被转换为 S ′ S' S′时,视觉内容可能会发生改变。 S ′ S' S′和 Y S Y_S YS之间的错位会干扰 M T M_T MT的训练。
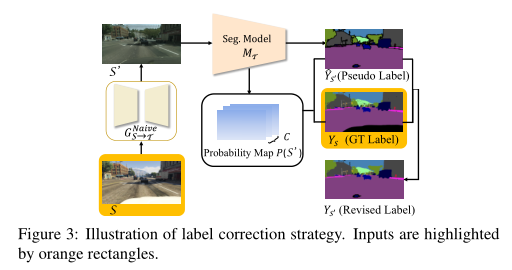
针对这个问题,我们提出了一种新的标签修正策略,见图3。核心是通过真实标签 Y S Y_S YS和分割预测 S ′ S' S′,给 S ′ S' S′找到一个修正的标签 Y S ′ Y_{S'} YS′。特别地,我们将 S ′ S' S′输入 M T M_T M

