
- 1【Super Resolution】超分辨率——SRGAN_userwarning: discrepancy between trainable weights
- 2【SpringCloud-1】注册中心-Eureka_注册中心,springcloud
- 3Android studio计算器
- 4逻辑卷的创建、扩容、缩容,以及raid0/5的创建_逻辑卷缩容
- 5yolov5的工业缺陷检测_yolov5缺陷检测
- 6命令注入漏洞(Command Injection)_system漏洞
- 7JAVA面试大全之基础篇
- 8AIGC内容分享(三十):推荐四本人工智能和AIGC相关的书籍_aigc书籍推荐
- 9什么是命令注入?其原理是什么?_命令注入漏洞攻击原理
- 10CSDN的会员等级和推荐卡规则_csdn达到什么等级才能推广公众号
HanLP 自然语言处理使用总结
赞
踩
一、HanLP
HanLP 是一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。内部算法经过工业界和学术界考验,配套书籍《自然语言处理入门》已经出版。目前,基于深度学习的HanLP 2.x已正式发布,次世代最先进的NLP技术,支持包括简繁中英日俄法德在内的104种语言上的联合任务。
本文参考官方GitHub:https://github.com/hankcs/HanLP/tree/1.x
目前 HanLP 提供了下面功能:
- 中文分词
- 词性标注
- 命名实体识别
- 关键词提取
- 自动摘要
- 短语提取
- 拼音转换
- 多音字、声母、韵母、声调
- 简繁转换
- 简繁分歧词(简体、繁体、臺灣正體、香港繁體)
- 文本推荐
- 语义推荐、拼音推荐、字词推荐
- 依存句法分析
- 文本分类
- 文本聚类
- KMeans、Repeated Bisection、自动推断聚类数目k
- word2vec
- 词向量训练、加载、词语相似度计算、语义运算、查询、KMeans聚类
- 文档语义相似度计算
- 语料库工具
- 部分默认模型训练自小型语料库,鼓励用户自行训练。所有模块提供训练接口,语料可参考98年人民日报语料库。
在提供丰富功能的同时,HanLP内部模块坚持低耦合、模型坚持惰性加载、服务坚持静态提供、词典坚持明文发布,使用非常方便。默认模型训练自全世界最大规模的中文语料库,同时自带一些语料处理工具,帮助用户训练自己的模型。
二、Java Maven项目环境准备
首先新建一个普通 Maven 项目,在 pom 中增加依赖:
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.8.3</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
此时即可使用基本功能(除由字构词、依存句法分析外的全部功能)。如果需要使用全部功能还需下载词典和模型,下载地址:
将下载后的data目录,拷贝至项目的 resources 目录下:
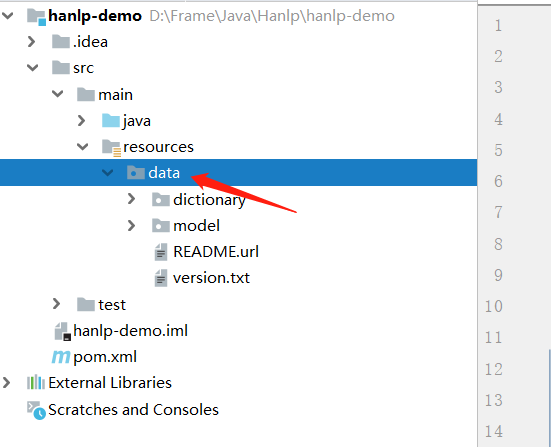
其中数据分为词典和模型,其中词典是词法分析必需的,模型是句法分析必需的,用户可以自行增删替换,如果不需要句法分析等功能的话,随时可以删除model文件夹。
下面还需要进行 HanLP 的配置,可以下载官方的配置模板:
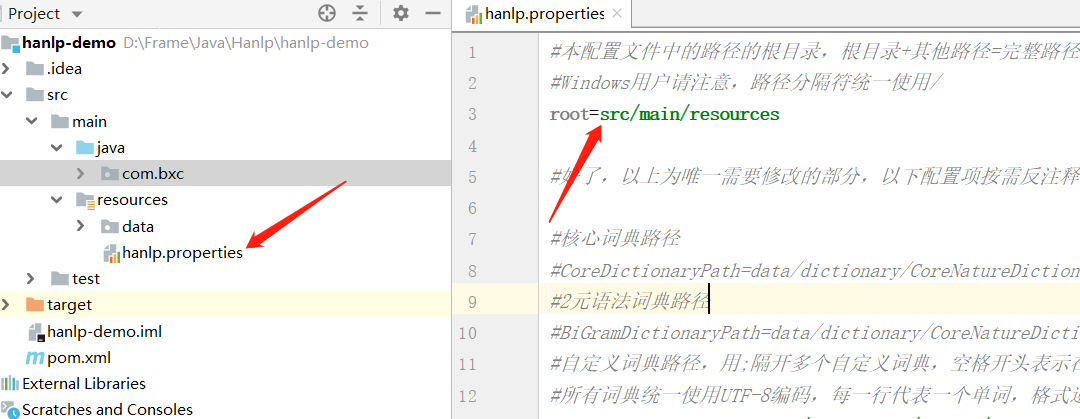
下载解压后,jar 包上面已经通过 Maven 引入,只需将hanlp.properties文件拷贝至 resources 目录下,并修改下面配置:
root=src/main/resources
- 1
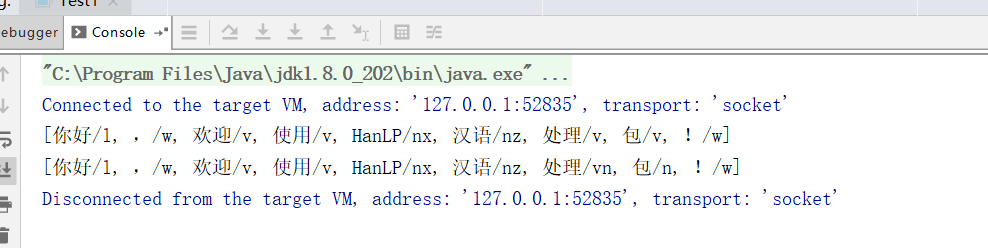
编写测试程序,测试环境:
public class Test1 {
public static void main(String[] args) {
String text = "你好,欢迎使用HanLP汉语处理包!";
//标准分词
System.out.println(HanLP.segment(text));
//nlp 分词
System.out.println(NLPTokenizer.segment(text));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
成功拿到结果便环境正常:
三、HanLP 使用
1. 基础分词
础分词,基础分词只进行基本NGram分词,不识别命名实体,不使用用户词典,分词后会带有词性,词性的标注集放在了文章最后:
public class DemoBasicTokenizer
{
public static void main(String[] args)
{
String text = "程序员(英文Programmer)是从事程序开发、维护的专业人员。" +
"一般将程序员分为程序设计人员和程序编码人员," +
"但两者的界限并不非常清楚,特别是在中国。" +
"软件从业人员分为初级程序员、高级程序员、系统" +
"分析员和项目经理四大类。";
System.out.println(BasicTokenizer.segment(text));
// 测试分词速度,让大家对HanLP的性能有一个直观的认识
long start = System.currentTimeMillis();
int pressure = 100000;
for (int i = 0; i < pressure; ++i)
{
BasicTokenizer.segment(text);
}
double costTime = (System.currentTimeMillis() - start) / (double) 1000;
System.out.printf("BasicTokenizer分词速度:%.2f字每秒\n", text.length() * pressure / costTime);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

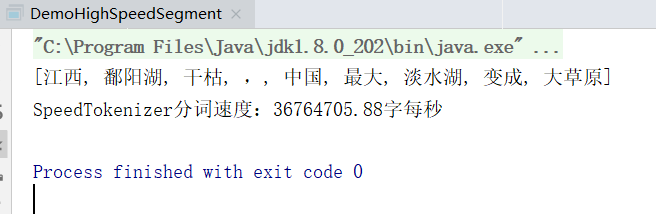
2. 极速分词
基于DoubleArrayTrie实现的词典正向最长分词,适用于“高吞吐量”“精度一般”的场合
public class DemoHighSpeedSegment
{
public static void main(String[] args)
{
String text = "江西鄱阳湖干枯,中国最大淡水湖变成大草原";
HanLP.Config.ShowTermNature = false;
System.out.println(SpeedTokenizer.segment(text));
long start = System.currentTimeMillis();
int pressure = 1000000;
for (int i = 0; i < pressure; ++i)
{
SpeedTokenizer.segment(text);
}
double costTime = (System.currentTimeMillis() - start) / (double)1000;
System.out.printf("SpeedTokenizer分词速度:%.2f字每秒\n", text.length() * pressure / costTime);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3. 标准分词
public class DemoSegment
{
public static void main(String[] args)
{
String[] testCase = new String[]{
"商品和服务",
"当下雨天地面积水分外严重",
"结婚的和尚未结婚的确实在干扰分词啊",
"买水果然后来世博园最后去世博会",
"中国的首都是北京",
"欢迎新老师生前来就餐",
"工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作",
"随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。",
};
for (String sentence : testCase)
{
//对StandardTokenizer.segment的包装
List<Term> termList = HanLP.segment(sentence);
System.out.println(termList);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

4. CRF词法分词
自1.6.6版起模型格式不兼容旧版:CRF模型为对数线性模型,通过复用结构化感知机的维特比解码算法,效率提高10倍。
public class DemoCRFLexicalAnalyzer
{
public static void main(String[] args) throws IOException
{
CRFLexicalAnalyzer analyzer = new CRFLexicalAnalyzer();
String[] tests = new String[]{
"商品和服务",
"上海华安工业(集团)公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观",
"微软公司於1975年由比爾·蓋茲和保羅·艾倫創立,18年啟動以智慧雲端、前端為導向的大改組。" // 支持繁体中文
};
for (String sentence : tests)
{
System.out.println(analyzer.seg(sentence));
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

5. NLP分词
更精准的中文分词、词性标注与命名实体识别。语料库规模决定实际效果,面向生产环境的语料库应当在千万字量级。
词性标注可以使用 Sentence#translateLabels() 转为中文显示:
public class DemoNLPSegment extends TestUtility
{
public static void main(String[] args)
{
NLPTokenizer.ANALYZER.enableCustomDictionary(false); // 中文分词≠词典,不用词典照样分词。
System.out.println(NLPTokenizer.segment("我新造一个词叫幻想乡你能识别并正确标注词性吗?")); // “正确”是副形词。
// 注意观察下面两个“希望”的词性、两个“晚霞”的词性
System.out.println(NLPTokenizer.analyze("我的希望是希望张晚霞的背影被晚霞映红").translateLabels());
System.out.println(NLPTokenizer.analyze("支援臺灣正體香港繁體:微软公司於1975年由比爾·蓋茲和保羅·艾倫創立。"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

6. 索引分词
public class DemoIndexSegment
{
public static void main(String[] args)
{
List<Term> termList = IndexTokenizer.segment("主副食品");
for (Term term : termList)
{
System.out.println(term + " [" + term.offset + ":" + (term.offset + term.word.length()) + "]");
}
System.out.println("\n最细颗粒度切分:");
IndexTokenizer.SEGMENT.enableIndexMode(1);
termList = IndexTokenizer.segment("主副食品");
for (Term term : termList)
{
System.out.println(term + " [" + term.offset + ":" + (term.offset + term.word.length()) + "]");
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

7. 多线程并行分词
由于HanLP的任何分词器都是线程安全的,所以用户只需调用一个配置接口就可以启用任何分词器的并行化
public class DemoMultithreadingSegment
{
public static void main(String[] args) throws IOException
{
Segment segment = new CRFLexicalAnalyzer(HanLP.Config.CRFCWSModelPath).enableCustomDictionary(false); // CRF分词器效果好,速度慢,并行化之后可以提高一些速度
String text = "程序员(英文Programmer)是从事程序开发、维护的专业人员。" +
"一般将程序员分为程序设计人员和程序编码人员," +
"但两者的界限并不非常清楚,特别是在中国。" +
"软件从业人员分为初级程序员、高级程序员、系统" +
"分析员和项目经理四大类。";
HanLP.Config.ShowTermNature = false;
System.out.println(segment.seg(text));
int pressure = 10000;
StringBuilder sbBigText = new StringBuilder(text.length() * pressure);
for (int i = 0; i < pressure; i++)
{
sbBigText.append(text);
}
text = sbBigText.toString();
System.gc();
long start;
double costTime;
// 测个速度
segment.enableMultithreading(false);
start = System.currentTimeMillis();
segment.seg(text);
costTime = (System.currentTimeMillis() - start) / (double) 1000;
System.out.printf("单线程分词速度:%.2f字每秒\n", text.length() / costTime);
System.gc();
segment.enableMultithreading(true); // 或者 segment.enableMultithreading(4);
start = System.currentTimeMillis();
segment.seg(text);
costTime = (System.currentTimeMillis() - start) / (double) 1000;
System.out.printf("多线程分词速度:%.2f字每秒\n", text.length() / costTime);
System.gc();
// Note:
// 内部的并行化机制可以对1万字以上的大文本开启多线程分词
// 另一方面,HanLP中的任何Segment本身都是线程安全的。
// 你可以开10个线程用同一个CRFSegment对象切分任意文本,不需要任何线程同步的措施,每个线程都可以得到正确的结果。
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46

8. AhoCorasickDoubleArrayTrie 分词
AhoCorasickDoubleArrayTrieSegment要求用户必须提供自己的词典路径
准备词典:
微观经济学
继续教育
循环经济
- 1
- 2
- 3
public class DemoUseAhoCorasickDoubleArrayTrieSegment {
public static void main(String[] args) throws IOException {
AhoCorasickDoubleArrayTrieSegment segment = new AhoCorasickDoubleArrayTrieSegment("data/dictionary/custom/my.txt");
System.out.println(segment.seg("微观经济学继续教育循环经济"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6

9. 繁体中文分词
public class DemoTraditionalChineseSegment
{
public static void main(String[] args)
{
List<Term> termList = TraditionalChineseTokenizer.segment("大衛貝克漢不僅僅是名著名球員,球場以外,其妻為前" +
"辣妹合唱團成員維多利亞·碧咸,亦由於他擁有" +
"突出外表、百變髮型及正面的形象,以至自己" +
"品牌的男士香水等商品,及長期擔任運動品牌" +
"Adidas的代言人,因此對大眾傳播媒介和時尚界" +
"等方面都具很大的影響力,在足球圈外所獲得的" +
"認受程度可謂前所未見。");
System.out.println(termList);
termList = TraditionalChineseTokenizer.segment("(中央社記者黃巧雯台北20日電)外需不振,影響接單動能,經濟部今天公布7月外銷訂單金額362.9億美元,年減5%," +
"連續4個月衰退,減幅較6月縮小。1040820\n");
System.out.println(termList);
termList = TraditionalChineseTokenizer.segment("中央社记者黄巧雯台北20日电");
System.out.println(termList);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

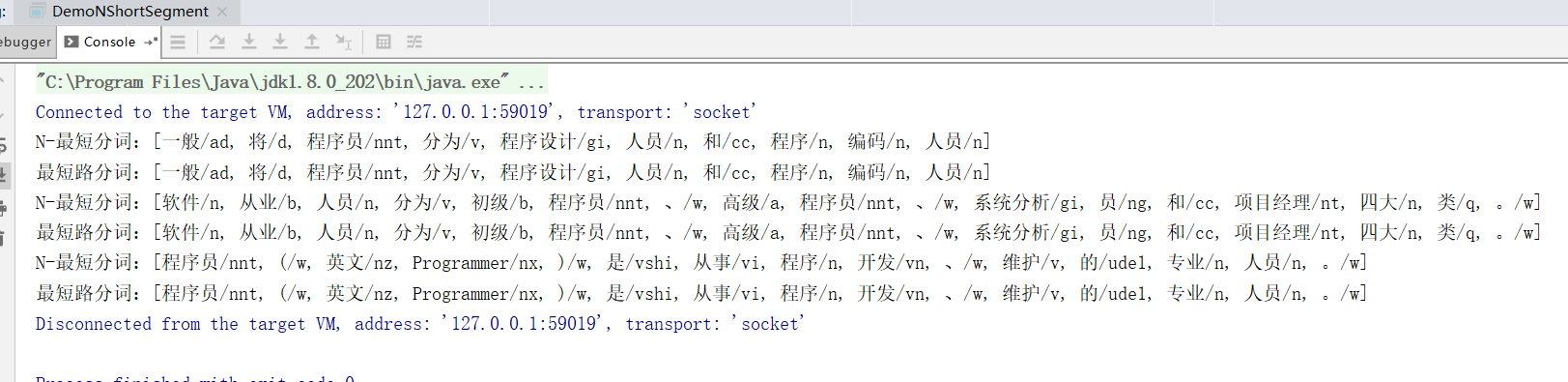
10. N最短路径分词
该分词器比最短路分词器慢,但是效果稍微好一些,对命名实体识别能力更强
public class DemoNShortSegment
{
public static void main(String[] args)
{
Segment nShortSegment = new NShortSegment().enableCustomDictionary(false).enablePlaceRecognize(true).enableOrganizationRecognize(true);
Segment shortestSegment = new ViterbiSegment().enableCustomDictionary(false).enablePlaceRecognize(true).enableOrganizationRecognize(true);
String[] testCase = new String[]{
"一般将程序员分为程序设计人员和程序编码人员",
"软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。",
"程序员(英文Programmer)是从事程序开发、维护的专业人员。",
};
for (String sentence : testCase)
{
System.out.println("N-最短分词:" + nShortSegment.seg(sentence) + "\n最短路分词:" + shortestSegment.seg(sentence));
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
11. 自定义词性,以及往词典中插入自定义词性的词语
public class DemoCustomNature
{
public static void main(String[] args)
{
// 对于系统中已有的词性,可以直接获取
Nature pcNature = Nature.fromString("n");
System.out.println(pcNature);
// 此时系统中没有"电脑品牌"这个词性
pcNature = Nature.fromString("电脑品牌");
System.out.println(pcNature);
// 我们可以动态添加一个
pcNature = Nature.create("电脑品牌");
System.out.println(pcNature);
// 可以将它赋予到某个词语
LexiconUtility.setAttribute("苹果电脑", pcNature);
// 或者
LexiconUtility.setAttribute("苹果电脑", "电脑品牌 1000");
// 它们将在分词结果中生效
List<Term> termList = HanLP.segment("苹果电脑可以运行开源阿尔法狗代码吗");
System.out.println(termList);
// 还可以直接插入到用户词典
CustomDictionary.insert("阿尔法狗", "科技名词 1024");
StandardTokenizer.SEGMENT.enablePartOfSpeechTagging(true); // 依然支持隐马词性标注
termList = HanLP.segment("苹果电脑可以运行开源阿尔法狗代码吗");
System.out.println(termList);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

12. 关键词提取
public class DemoKeyword
{
public static void main(String[] args)
{
String content = "程序员(英文Programmer)是从事程序开发、维护的专业人员。" +
"一般将程序员分为程序设计人员和程序编码人员," +
"但两者的界限并不非常清楚,特别是在中国。" +
"软件从业人员分为初级程序员、高级程序员、系统" +
"分析员和项目经理四大类。";
List<String> keywordList = HanLP.extractKeyword(content, 5);
System.out.println(keywordList);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

13. 自动摘要
public class DemoSummary
{
public static void main(String[] args)
{
String document = "水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露," +
"根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标," +
"有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批," +
"严格地进行水资源论证和取水许可的批准。";
List<String> sentenceList = HanLP.extractSummary(document, 3);
System.out.println(sentenceList);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

14.自动去除停用词、自动断句的分词器
public class DemoNotionalTokenizer
{
public static void main(String[] args)
{
String text = "小区居民有的反对喂养流浪猫,而有的居民却赞成喂养这些小宝贝";
// 自动去除停用词
System.out.println(NotionalTokenizer.segment(text)); // 停用词典位于data/dictionary/stopwords.txt,可以自行修改
// 自动断句+去除停用词
for (List<Term> sentence : NotionalTokenizer.seg2sentence(text))
{
System.out.println(sentence);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

15. 机构名识别
public class DemoOrganizationRecognition
{
public static void main(String[] args)
{
String[] testCase = new String[]{
"我在上海林原科技有限公司兼职工作,",
"我经常在台川喜宴餐厅吃饭,",
"偶尔去开元地中海影城看电影。",
"不用词典,福哈生态工程有限公司是动态识别的结果。",
};
Segment segment = HanLP.newSegment().enableCustomDictionary(false).enableOrganizationRecognize(true);
for (String sentence : testCase)
{
List<Term> termList = segment.seg(sentence);
termList.forEach(t->{
if (Nature.nt == t.nature){
System.out.println(t.word);
}
});
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

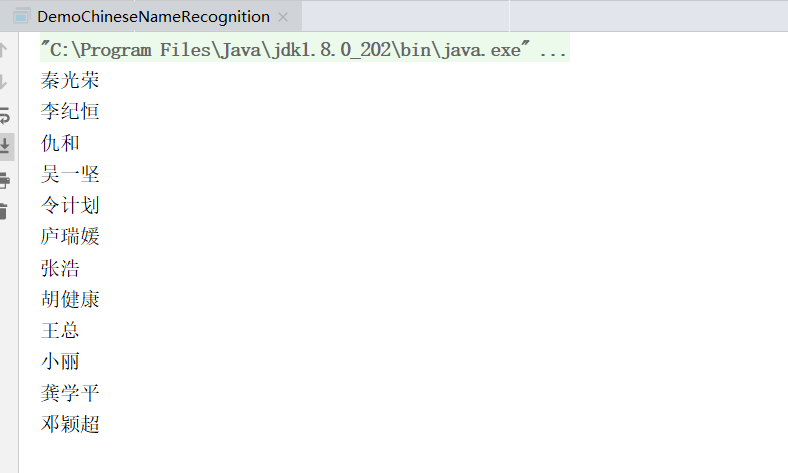
16. 中国人名识别
public class DemoChineseNameRecognition {
public static void main(String[] args) {
String[] testCase = new String[]{
"签约仪式前,秦光荣、李纪恒、仇和等一同会见了参加签约的企业家。",
"陕西首富吴一坚被带走 与令计划妻子有交集",
"凯瑟琳和露西(庐瑞媛),跟她们的哥哥们有一些不同。",
"张浩和胡健康复员回家了",
"王总和小丽结婚了",
"龚学平等领导说,邓颖超生前杜绝超生",
};
Segment segment = HanLP.newSegment().enableNameRecognize(true);
for (String sentence : testCase) {
List<Term> termList = segment.seg(sentence);
termList.forEach(t -> {
if (Nature.nr == t.nature) {
System.out.println(t.word);
}
});
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
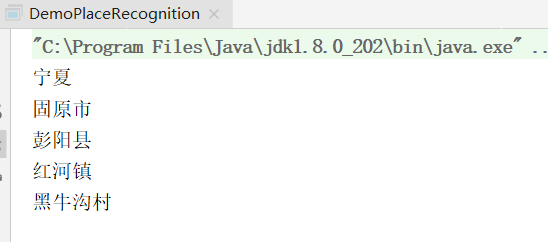
17. 地名识别
public class DemoPlaceRecognition
{
public static void main(String[] args)
{
String[] testCase = new String[]{
"蓝翔给宁夏固原市彭阳县红河镇黑牛沟村捐赠了挖掘机",
};
Segment segment = HanLP.newSegment().enablePlaceRecognize(true);
for (String sentence : testCase)
{
List<Term> termList = segment.seg(sentence);
termList.forEach(t->{
if (Nature.ns == t.nature){
System.out.println(t.word);
}
});
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
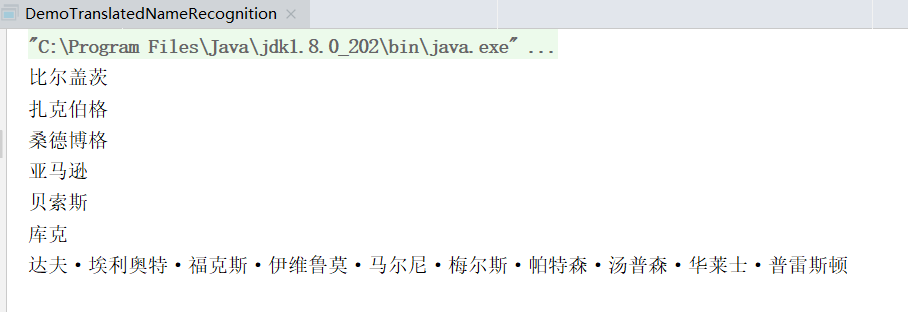
18. 音译人名识别
public class DemoTranslatedNameRecognition
{
public static void main(String[] args)
{
String[] testCase = new String[]{
"一桶冰水当头倒下,微软的比尔盖茨、Facebook的扎克伯格跟桑德博格、亚马逊的贝索斯、苹果的库克全都不惜湿身入镜,这些硅谷的科技人,飞蛾扑火似地牺牲演出,其实全为了慈善。",
"世界上最长的姓名是简森·乔伊·亚历山大·比基·卡利斯勒·达夫·埃利奥特·福克斯·伊维鲁莫·马尔尼·梅尔斯·帕特森·汤普森·华莱士·普雷斯顿。",
};
Segment segment = HanLP.newSegment().enableTranslatedNameRecognize(true);
for (String sentence : testCase)
{
List<Term> termList = segment.seg(sentence);
termList.forEach(t->{
if (Nature.nrf == t.nature){
System.out.println(t.word);
}
});
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
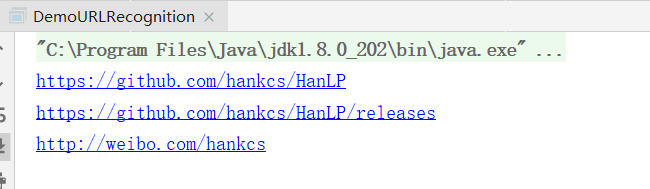
19. URL识别
public class DemoURLRecognition
{
public static void main(String[] args)
{
String text =
"HanLP的项目地址是https://github.com/hankcs/HanLP," +
"发布地址是https://github.com/hankcs/HanLP/releases," +
"我有时候会在www.hankcs.com上面发布一些消息," +
"我的微博是http://weibo.com/hankcs/,会同步推送hankcs.com的新闻。";
List<Term> termList = URLTokenizer.segment(text);
for (Term term : termList)
{
if (term.nature == Nature.xu)
System.out.println(term.word);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
20. 汉字转拼音
public class DemoPinyin
{
public static void main(String[] args)
{
String text = "重载不是重任!";
List<Pinyin> pinyinList = HanLP.convertToPinyinList(text);
System.out.print("原文,");
for (char c : text.toCharArray())
{
System.out.printf("%c,", c);
}
System.out.println();
System.out.print("拼音(数字音调),");
for (Pinyin pinyin : pinyinList)
{
System.out.printf("%s,", pinyin);
}
System.out.println();
System.out.print("拼音(符号音调),");
for (Pinyin pinyin : pinyinList)
{
System.out.printf("%s,", pinyin.getPinyinWithToneMark());
}
System.out.println();
System.out.print("拼音(无音调),");
for (Pinyin pinyin : pinyinList)
{
System.out.printf("%s,", pinyin.getPinyinWithoutTone());
}
System.out.println();
System.out.print("声调,");
for (Pinyin pinyin : pinyinList)
{
System.out.printf("%s,", pinyin.getTone());
}
System.out.println();
System.out.print("声母,");
for (Pinyin pinyin : pinyinList)
{
System.out.printf("%s,", pinyin.getShengmu());
}
System.out.println();
System.out.print("韵母,");
for (Pinyin pinyin : pinyinList)
{
System.out.printf("%s,", pinyin.getYunmu());
}
System.out.println();
System.out.print("输入法头,");
for (Pinyin pinyin : pinyinList)
{
System.out.printf("%s,", pinyin.getHead());
}
System.out.println();
// 拼音转换可选保留无拼音的原字符
System.out.println(HanLP.convertToPinyinString("截至2012年,", " ", true));
System.out.println(HanLP.convertToPinyinString("截至2012年,", " ", false));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67

21. 拼音转汉字
public class DemoPinyinToChinese
{
public static void main(String[] args)
{
StringDictionary dictionary = new StringDictionary("=");
dictionary.load(HanLP.Config.PinyinDictionaryPath);
TreeMap<String, Set<String>> map = new TreeMap<String, Set<String>>();
for (Map.Entry<String, String> entry : dictionary.entrySet())
{
String pinyins = entry.getValue().replaceAll("[\\d,]", "");
Set<String> words = map.get(pinyins);
if (words == null)
{
words = new TreeSet<String>();
map.put(pinyins, words);
}
words.add(entry.getKey());
}
Set<String> words = new TreeSet<String>();
words.add("绿色");
words.add("滤色");
map.put("lvse", words);
// 1.5.2及以下版本
AhoCorasickDoubleArrayTrie<Set<String>> trie = new AhoCorasickDoubleArrayTrie<Set<String>>();
trie.build(map);
System.out.println(CommonAhoCorasickSegmentUtil.segment("renmenrenweiyalujiangbujianlvse", trie));
// 1.5.3及以上版本
CommonAhoCorasickDoubleArrayTrieSegment<Set<String>> segment = new CommonAhoCorasickDoubleArrayTrieSegment<Set<String>>(map);
System.out.println(segment.segment("renmenrenweiyalujiangbujianlvse"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33

22. 文本推荐
句子级别,从一系列句子中挑出与输入句子最相似的那一个
public class DemoSuggester
{
public static void main(String[] args)
{
Suggester suggester = new Suggester();
String[] titleArray =
(
"威廉王子发表演说 呼吁保护野生动物\n" +
"魅惑天后许佳慧不爱“预谋” 独唱《许某某》\n" +
"《时代》年度人物最终入围名单出炉 普京马云入选\n" +
"“黑格比”横扫菲:菲吸取“海燕”经验及早疏散\n" +
"英报告说空气污染带来“公共健康危机”"
).split("\\n");
for (String title : titleArray)
{
suggester.addSentence(title);
}
System.out.println(suggester.suggest("陈述", 2)); // 语义
System.out.println(suggester.suggest("危机公关", 1)); // 字符
System.out.println(suggester.suggest("mayun", 1)); // 拼音
System.out.println(suggester.suggest("徐家汇", 1)); // 拼音
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

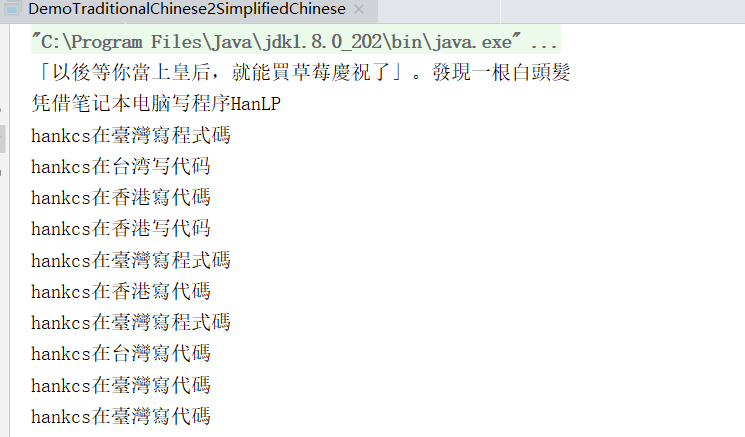
23. 简繁体字转换
public class DemoTraditionalChinese2SimplifiedChinese
{
public static void main(String[] args)
{
System.out.println(HanLP.convertToTraditionalChinese("“以后等你当上皇后,就能买草莓庆祝了”。发现一根白头发"));
System.out.println(HanLP.convertToSimplifiedChinese("憑藉筆記簿型電腦寫程式HanLP"));
// 简体转台湾繁体
System.out.println(HanLP.s2tw("hankcs在台湾写代码"));
// 台湾繁体转简体
System.out.println(HanLP.tw2s("hankcs在臺灣寫程式碼"));
// 简体转香港繁体
System.out.println(HanLP.s2hk("hankcs在香港写代码"));
// 香港繁体转简体
System.out.println(HanLP.hk2s("hankcs在香港寫代碼"));
// 香港繁体转台湾繁体
System.out.println(HanLP.hk2tw("hankcs在臺灣寫代碼"));
// 台湾繁体转香港繁体
System.out.println(HanLP.tw2hk("hankcs在香港寫程式碼"));
// 香港/台湾繁体和HanLP标准繁体的互转
System.out.println(HanLP.t2tw("hankcs在臺灣寫代碼"));
System.out.println(HanLP.t2hk("hankcs在臺灣寫代碼"));
System.out.println(HanLP.tw2t("hankcs在臺灣寫程式碼"));
System.out.println(HanLP.hk2t("hankcs在台灣寫代碼"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
24. 短语提取
public class DemoPhraseExtractor
{
public static void main(String[] args)
{
String text = "算法工程师\n" +
"算法(Algorithm)是一系列解决问题的清晰指令,也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。" +
"如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、" +
"空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。算法工程师就是利用算法处理事物的人。\n" +
"\n" +
"1职位简介\n" +
"算法工程师是一个非常高端的职位;\n" +
"专业要求:计算机、电子、通信、数学等相关专业;\n" +
"学历要求:本科及其以上的学历,大多数是硕士学历及其以上;\n" +
"语言要求:英语要求是熟练,基本上能阅读国外专业书刊;\n" +
"必须掌握计算机相关知识,熟练使用仿真工具MATLAB等,必须会一门编程语言。\n" +
"\n" +
"2研究方向\n" +
"视频算法工程师、图像处理算法工程师、音频算法工程师 通信基带算法工程师\n" +
"\n" +
"3目前国内外状况\n" +
"目前国内从事算法研究的工程师不少,但是高级算法工程师却很少,是一个非常紧缺的专业工程师。" +
"算法工程师根据研究领域来分主要有音频/视频算法处理、图像技术方面的二维信息算法处理和通信物理层、" +
"雷达信号处理、生物医学信号处理等领域的一维信息算法处理。\n" +
"在计算机音视频和图形图像技术等二维信息算法处理方面目前比较先进的视频处理算法:机器视觉成为此类算法研究的核心;" +
"另外还有2D转3D算法(2D-to-3D conversion),去隔行算法(de-interlacing),运动估计运动补偿算法" +
"(Motion estimation/Motion Compensation),去噪算法(Noise Reduction),缩放算法(scaling)," +
"锐化处理算法(Sharpness),超分辨率算法(Super Resolution),手势识别(gesture recognition),人脸识别(face recognition)。\n" +
"在通信物理层等一维信息领域目前常用的算法:无线领域的RRM、RTT,传送领域的调制解调、信道均衡、信号检测、网络优化、信号分解等。\n" +
"另外数据挖掘、互联网搜索算法也成为当今的热门方向。\n" +
"算法工程师逐渐往人工智能方向发展。";
List<String> phraseList = HanLP.extractPhrase(text, 5);
System.out.println(phraseList);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34

25. 聚类
public class DemoTextClustering
{
public static void main(String[] args)
{
ClusterAnalyzer<String> analyzer = new ClusterAnalyzer<String>();
analyzer.addDocument("赵一", "流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 蓝调, 蓝调, 蓝调, 蓝调, 蓝调, 蓝调, 摇滚, 摇滚, 摇滚, 摇滚");
analyzer.addDocument("钱二", "爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲");
analyzer.addDocument("张三", "古典, 古典, 古典, 古典, 民谣, 民谣, 民谣, 民谣");
analyzer.addDocument("李四", "爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 金属, 金属, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲");
analyzer.addDocument("王五", "流行, 流行, 流行, 流行, 摇滚, 摇滚, 摇滚, 嘻哈, 嘻哈, 嘻哈");
analyzer.addDocument("马六", "古典, 古典, 古典, 古典, 古典, 古典, 古典, 古典, 摇滚");
System.out.println(analyzer.kmeans(3));
System.out.println(analyzer.repeatedBisection(3));
System.out.println(analyzer.repeatedBisection(1.0)); // 自动判断聚类数量k
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

四、HanLP词性标注集
| 标签 | 含义 |
|---|---|
| a | 形容词 |
| ad | 副形词 |
| ag | 形容词性语素 |
| al | 形容词性惯用语 |
| an | 名形词 |
| b | 区别词 |
| begin | 仅用于始##始 |
| bg | 区别语素 |
| bl | 区别词性惯用语 |
| c | 连词 |
| cc | 并列连词 |
| d | 副词 |
| dg | 辄,俱,复之类的副词 |
| dl | 连语 |
| e | 叹词 |
| end | 仅用于终##终 |
| f | 方位词 |
| g | 学术词汇 |
| gb | 生物相关词汇 |
| gbc | 生物类别 |
| gc | 化学相关词汇 |
| gg | 地理地质相关词汇 |
| gi | 计算机相关词汇 |
| gm | 数学相关词汇 |
| gp | 物理相关词汇 |
| h | 前缀 |
| i | 成语 |
| j | 简称略语 |
| k | 后缀 |
| l | 习用语 |
| m | 数词 |
| mg | 数语素 |
| Mg | 甲乙丙丁之类的数词 |
| mq | 数量词 |
| n | 名词 |
| nb | 生物名 |
| nba | 动物名 |
| nbc | 动物纲目 |
| nbp | 植物名 |
| nf | 食品,比如“薯片” |
| ng 名词性语素 | |
| nh | 医药疾病等健康相关名词 |
| nhd | 疾病 |
| nhm | 药品 |
| ni | 机构相关(不是独立机构名) |
| nic | 下属机构 |
| nis | 机构后缀 |
| nit | 教育相关机构 |
| nl | 名词性惯用语 |
| nm | 物品名 |
| nmc | 化学品名 |
| nn | 工作相关名词 |
| nnd | 职业 |
| nnt | 职务职称 |
| nr | 人名 |
| nr1 | 复姓 |
| nr2 | 蒙古姓名 |
| nrf | 音译人名 |
| nrj | 日语人名 |
| ns | 地名 |
| nsf | 音译地名 |
| nt | 机构团体名 |
| ntc | 公司名 |
| ntcb | 银行 |
| ntcf | 工厂 |
| ntch | 酒店宾馆 |
| nth | 医院 |
| nto | 政府机构 |
| nts 中小学 | |
| ntu | 大学 |
| nx | 字母专名 |
| nz | 其他专名 |
| o | 拟声词 |
| p | 介词 |
| pba | 介词“把” |
| pbei | 介词“被” |
| q | 量词 |
| qg | 量词语素 |
| qt | 时量词 |
| qv | 动量词 |
| r | 代词 |
| rg | 代词性语素 |
| Rg | 古汉语代词性语素 |
| rr | 人称代词 |
| ry | 疑问代词 |
| rys | 处所疑问代词 |
| ryt | 时间疑问代词 |
| ryv | 谓词性疑问代词 |
| rz | 指示代词 |
| rzs | 处所指示代词 |
| rzt | 时间指示代词 |
| rzv | 谓词性指示代词 |
| s | 处所词 |
| t | 时间词 |
| tg | 时间词性语素 |
| u | 助词 |
| ud | 助词 |
| ude1 | 的 底 |
| ude2 | 地 |
| ude3 | 得 |
| udeng | 等 等等 云云 |
| udh | 的话 |
| ug | 过 |
| uguo | 过 |
| uj | 助词 |
| ul | 连词 |
| ule | 了 喽 |
| ulian | 连 (“连小学生都会”) |
| uls | 来讲 来说 而言 说来 |
| usuo | 所 |
| uv | 连词 |
| uyy | 一样 一般 似的 般 |
| uz | 着 |
| uzhe | 着 |
| uzhi | 之 |
| v | 动词 |
| vd | 副动词 |
| vf | 趋向动词 |
| vg | 动词性语素 |
| vi | 不及物动词(内动词) |
| vl | 动词性惯用语 |
| vn | 名动词 |
| vshi | 动词“是” |
| vx | 形式动词 |
| vyou | 动词“有” |
| w | 标点符号 |
| wb | 百分号千分号,全角:% ‰ 半角:% |
| wd | 逗号,全角:, 半角:, |
| wf | 分号,全角:; 半角: ; |
| wh | 单位符号,全角:¥ $ £ ° ℃ 半角:$ |
| wj | 句号,全角:。 |
| wky | 右括号,全角:) 〕 ] } 》 】 〗 〉 半角: ) ] { > |
| wkz | 左括号,全角:( 〔 [ { 《 【 〖 〈 半角:( [ { < |
| wm | 冒号,全角:: 半角: : |
| wn | 顿号,全角:、 |
| wp | 破折号,全角:—— -- ——- 半角:— —- |
| ws | 省略号,全角:…… … |
| wt | 叹号,全角:! |
| ww | 问号,全角:? |
| wyy | 右引号,全角:” ’ 』 |
| wyz | 左引号,全角:“ ‘ 『 |
| x | 字符串 |
| xu | 网址URL |
| xx | 非语素字 |
| y | 语气词(delete yg) |
| yg | 语气语素 |
| z | 状态词 |
| zg | 状态词 |

