
热门标签
热门文章
- 1模电学习笔记(3)_模电中ubq和ubeq
- 2当运行深度学习网络出现cuda out of memory错误:_cuda oom
- 3Kafka科普系列 | 什么是LSO?_kafka lso
- 4[回忆]2007年的GDNT研发广东北电辞职信._广东北电通信设备有限公司
- 5Solidity实现智能合约——Solidity高级理论(三)_智能合约& 线上 ide 实现 solidity 合约
- 6【2023】kafka入门学习与使用(kafka-2)
- 7手把手做一个公众号GPT智能客服(七)GPT 接入微信机器人_gpt接入企业微信客服
- 8NLP-预训练模型:综述【基础:BERT】【预训练任务优化:ERNIE、SpanBERT】【训练方法优化:RoBERTa、T5】【模型结构优化:XLNet、ALBERT、ELECTRA】【模型轻量化】_t5, roberta, albert,bert,transformer,macbert区别
- 9python列表求平均值函数_计算给定列表中所有元素的平均值(定义一个函数)
- 10PyTorch深度学习入门笔记(八)神经网络的基本骨架 nn.Module的使用_class net(torch.nn.module)
当前位置: article > 正文
【xinference】(4):在autodl上,使用xinference部署sd-turbo模型,可以根据文本生成图片,在RTX3080-20G上耗时1分钟,占用显存11G_3080ti跑sd
作者:羊村懒王 | 2024-04-05 02:47:24
赞
踩
3080ti跑sd
1,视频地址
https://www.bilibili.com/video/BV1kp421d7eE/
【xinference】(4):在autodl上,使用xinference部署sd-turbo模型,可以根据文本生成图片,在RTX3080-20G上耗时1分钟
2,关于sdxl-turbo
https://hf-mirror.com/stabilityai/sd-turbo
SD-Turbo是基于SD 2.1架构的蒸馏模型。
2,sd-turbo下载模型
https://inference.readthedocs.io/zh-cn/latest/models/builtin/image/index.html
xinference launch --model-name sd-turbo --model-type image
- 1
下载进度:
sd_turbo.safetensors: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 5.21G/5.21G [04:51<00:00, 14.8MB/s]
model.fp16.safetensors: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 681M/681M [06:24<00:00, 1.73MB/s]
Fetching 22 files: 50%|█████████████████████████████████████████████████ | 11/22 [06:37<07:19, 39.95s/it]
model.fp16.safetensors: 69%|█████████████████████████████████████████████████████████████▋ | 467M/681M [04:36<01:46, 2.01MB/s]
model.fp16.safetensors: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 681M/681M [06:24<00:00, 2.09MB/s]
- 1
- 2
- 3
- 4
- 5
3,然后就可以测试图片了
https://inference.readthedocs.io/zh-cn/latest/user_guide/client_api.html#id3
python3 测试代码:
from xinference.client import Client
client = Client("http://127.0.0.1:9997")
model = client.get_model("sd-turbo")
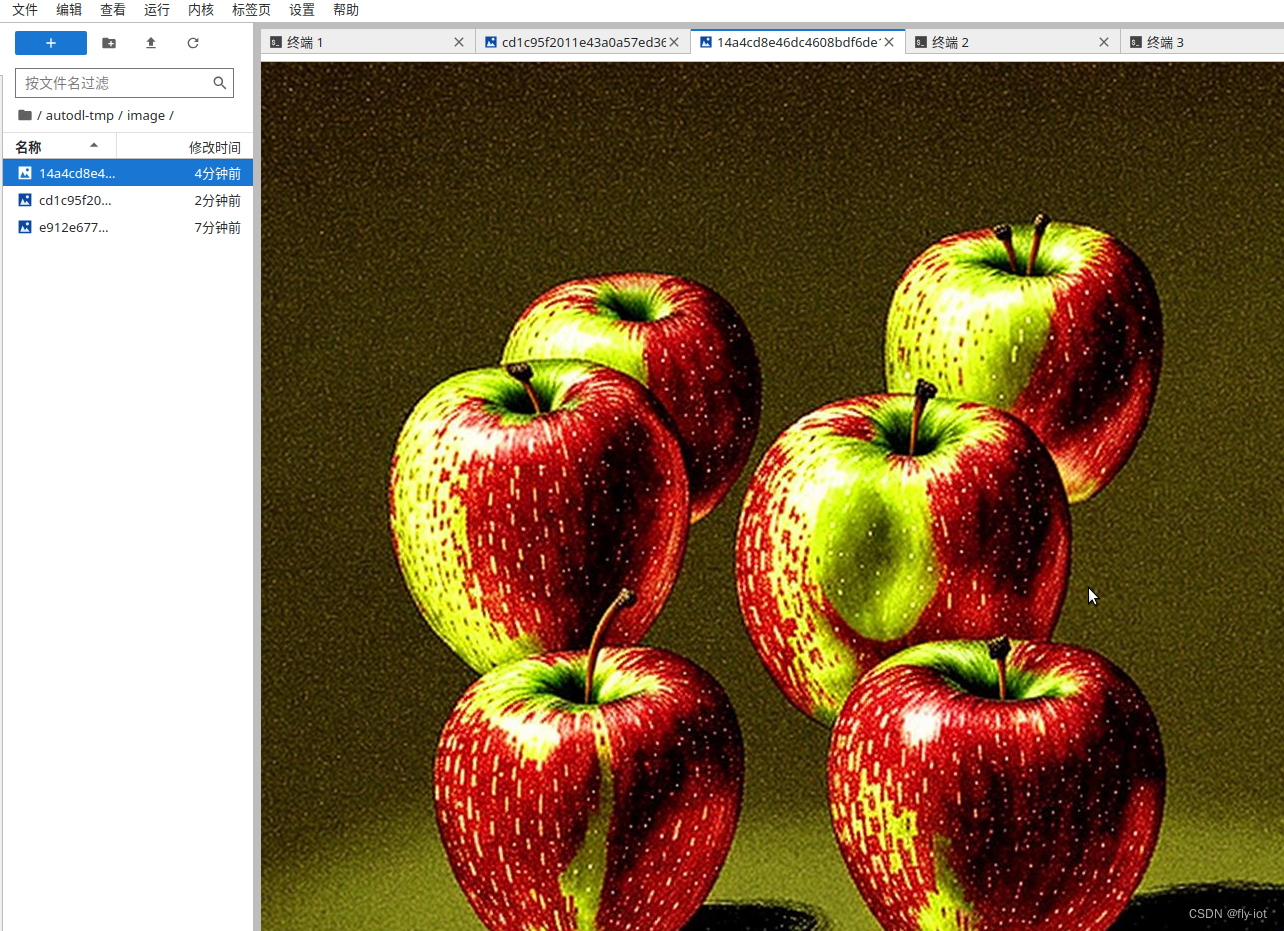
input_text = "an apple"
out = model.text_to_image(input_text)
print(out)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
生成图片:
4,总结
效果上还是不错的,可以画出苹果的细节。
但是还是粗糙点,确实因为模型比较小。速度还是不错的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/362801
推荐阅读
相关标签

