
- 1做软件测试,就得去大厂!
- 2Rasa中文聊天机器人开发指南(2):NLU篇_rasa中文文档
- 3《基于音频和文本的多模态语音情感识别的TensorFlow实现》的项目(写的很人性化的哦!)_基于tensorflow的语音情绪分析与运用的研究意义
- 4B端界面设计:页面分类设计_页面结构设计,功能划分
- 5介绍一下gpt模型的原理_gpt原理
- 6芒果YOLOv8改进10:特征融合Neck篇:改进特征融合网络 BiFPN 结构,融合更多有效特征_concat_bifpn yolov8
- 7深入解析《企业级数据架构》:HDFS、Yarn、Hive、HBase与Spark的核心应用_数据仓库 hive hdfs
- 8ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices论文学习
- 9mxnet学习笔记(二)——训练器Trainer()函数详解_gluon.trainer
- 10可视化模型:深度学习中的 Grad-CAM 指南_gcn grad-cam
PaddleOCR学习 —— 环境配置与上手使用
赞
踩
1. PaddleOCR简介
PaddleOCR支持多种OCR相关前沿算法,在此基础上打造产业级特色模型PP-OCR、PP-Structure和PP-ChatOCR,并打通数据生产、模型训练、压缩、预测部署全流程。
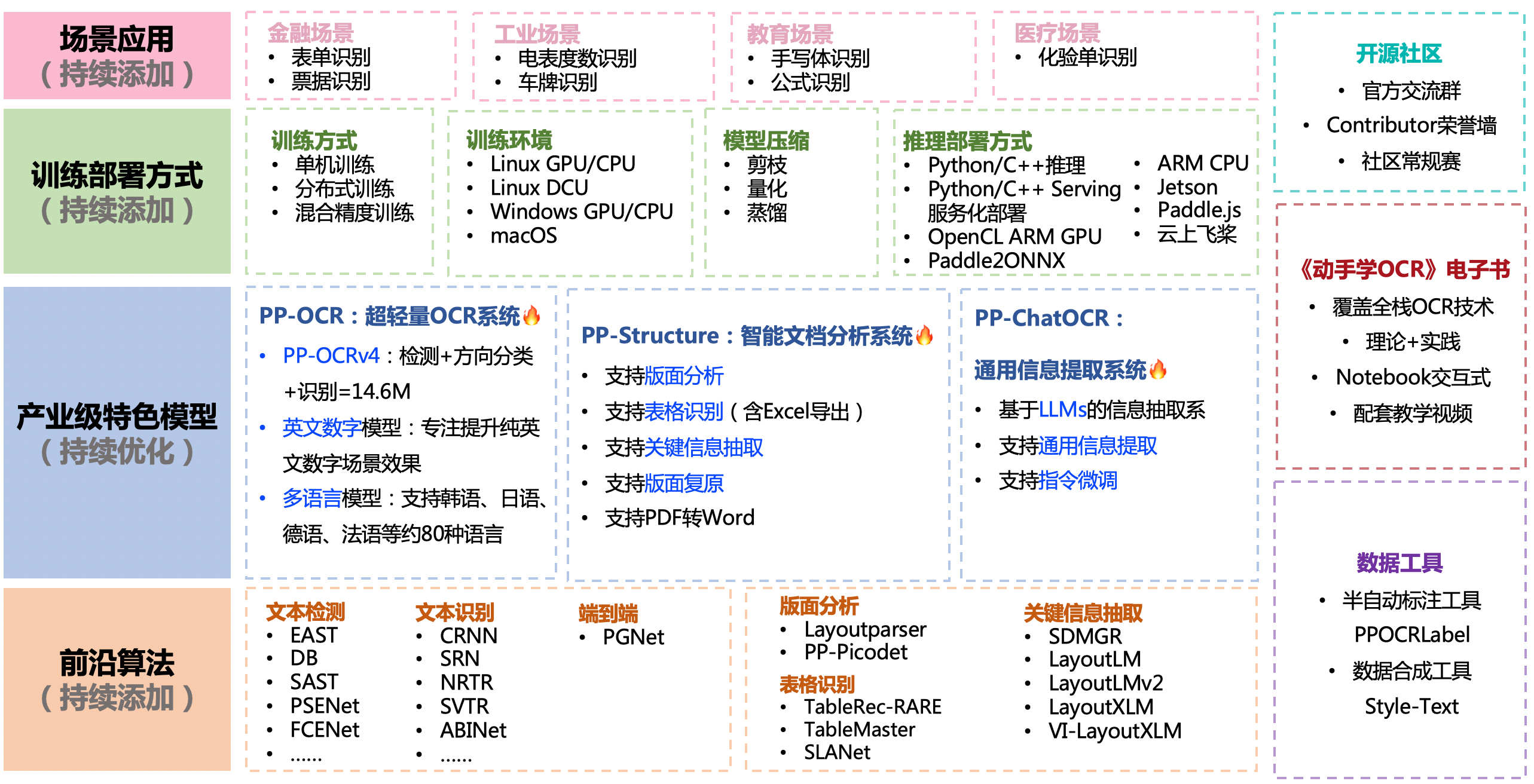
PaddleOCR产品体系
1. PP-OCR(文字识别)
2. PP-Structure(面板分析,表格提取,关键信息抽取,面板复原)
3. PP-ChatOCR(融合LLM+OCR的通用文本图像智能分析系统)
4. 其他(半自动标注工具PPOCRLabel,以及一些OCR数据集等)
PaddleOCR官方仓库
2. 环境配置
首先下载安装Anaconda,方便配置独立的Python环境。然后打开Anaconda Prompt输入以下命令创建一个新环境用于PaddleOCR的学习:
- # 在命令行输入以下命令,创建名为paddle_env的环境
- # 此处为加速下载,使用清华源
- conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # 这是一行命令
这里采用的Python版本为3.8,是此时的PaddleOCR(release 2.7)官方推荐的版本。请去官方的项目仓库中查看文档,以选择最适合当下发行版的Python版本。
然后安装PaddlePaddle,这是PaddleOCR的基础依赖,无论使用PP-OCR还是PP-Structure,都需要先安装此依赖。
如果使用GPU运算且安装了CUDA 9或CUDA 10,使用以下命令安装:
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple如果仅使用CPU进行运算,使用以下命令安装:
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple最后,安装PaddleOCR的whl包:
pip3 install "paddleocr>=2.6.0.3"(PS:具体的版本还请参照当下官方文档推荐的版本)
3. 上手使用——以PP-Structure为例
在基础配置完成后,就可以选择感兴趣的模型进行训练、推理等工作了。这里以PP-Structure为例,来介绍PaddleOCR的基本使用。
PP-Structure包括了以下功能:
1. 图像方向分类
2. 面板分析
3. 表格提取
4. 关键信息抽取(语义实体识别SER、关系抽取RE)
5. 面板复原
3.1 基础功能使用
图像方向分类、面板分析、表格提取和版面复原都被封装在了PPStructure类中,直接使用此类即可完成这四项任务。
- import os
- import cv2
- from paddleocr import PPStructure,draw_structure_result,save_structure_res
-
- table_engine = PPStructure(show_log=True, image_orientation=True)
-
- # 输出识别结果的目录
- save_folder = './output'
-
- # 输入图像的目录
- img_path = 'ppstructure/docs/table/1.png'
-
- # 读取图像
- img = cv2.imread(img_path)
-
- # 识别图像
- result = table_engine(img)
-
- # 保存结果
- save_structure_res(result, save_folder, 'result')
-
- # 版面恢复
- from PIL import Image
-
- # 选择字体文件
- font_path = 'doc/fonts/simfang.ttf'
- image = Image.open(img_path).convert('RGB')
- im_show = draw_structure_result(image, result,font_path=font_path)
- im_show = Image.fromarray(im_show)
- im_show.save('result.jpg')

其中PPStructure在构造时可传入的参数包括:
- show_log:是否在控制台打印日志
- image_orientation:是否进行图像方向分类
- table:是否进行表格识别
- ocr:是否进行文字识别
- layout:是否进行版面识别
- recovery:是否进行版面恢复
通过设置这些参数,就可以控制PPStructure是否进行图像方向分类、面板分析、表格提取和版面复原这些任务。
在首次运行代码时,PPStructure类会自动下载所需的模型文件用于推理任务。
3.2 进阶功能使用
关键信息抽取的模型由于规模较大,其使用也较为复杂。
首先需要克隆完整的代码并安装依赖:
- git clone https://github.com/PaddlePaddle/PaddleOCR.git
- cd PaddleOCR
- pip install -r requirements.txt
- pip install -r ppstructure/kie/requirements.txt
- pip install paddleocr -U
如果要自己训练模型,还需准备数据集。这里我们只使用推理模型,来大致体验一下使用效果,因此直接下载训练好的RE和SER模型:
- wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_infer.tar && tar -xf ser_vi_layoutxlm_xfund_infer.tar
- wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_infer.tar && tar -xf re_vi_layoutxlm_xfund_infer.tar
这里使用wget下载模型,如果你的机器没有配置wget,也可以直接复制后面的网址在浏览器中打开即可下载。
下载的文件为.tar格式,请不要手动解压(因为需要解压两次)。直接使用tar命令解压模型即可。
准备好要识别的数据,在conda中cd到./PaddleOCR/ppstructure/kie目录,然后使用命令行来启动模型:
python predict_kie_token_ser_re.py --kie_algorithm=LayoutXLM --re_model_dir=../inference/re_vi_layoutxlm_xfund_infer --ser_model_dir=../inference/ser_vi_layoutxlm_xfund_infer --use_visual_backbone=False --image_dir=./docs/kie/input/zh_val_42.jpg --ser_dict_path=../train_data/XFUND/class_list_xfun.txt --vis_font_path=../doc/fonts/simfang.ttf --ocr_order_method="tb-yx"参数说明:
kie_algorithm:kie的算法
re_model_dir:RE模型的位置
ser_model_dir:SER模型的位置
image_dir:输入图像的位置
ser_dict_path:指定实体识别的类别的.txt文件,每行指定一种类别。XFUND数据集自带的类别文件为:
- OTHER
- QUESTION
- ANSWER
- HEADER
vis_font_path:识别结果可视化的字体
ocr_order_method:对OCR得到的实体进行排序的算法
识别结果会输出在output文件夹下。
4. 总结
本文介绍了PaddleOCR项目的上手使用,并以PP-Structure为例,用训练好的推理模型体验了该项目的使用。更深层次的客制化模型、训练模型等任务,还需在以后进行探索。

