
热门标签
热门文章
- 1antd upload 文件上传状态控制 与from 表单数据绑定 问题记录_antd的upload组件上传excel文件放在form表单提交拿不到文件
- 2输入正整数n求出前1-n整数和_编写一个程序,输入一个正整数n,输出前n个自然数之和。
- 3网页常见布局案例解析+代码_简单页面布局代码
- 4【循环神经网络系列】三、GRU_使用gru神经网络的结构
- 5python小波包分解_小波分解和小波包分解
- 6互联网大厂面经分享_值得买科技公司面试
- 7一、列表简介(1)_列表中必须有元素,不能为空,这句话对不对
- 8Mysql ERROR 1040: Too many connections连接数满_connect error (1040) too many connections
- 9oracle 复制工具类,oracle 常用工具类及函数
- 10flask各种版本的项目,终端命令运行方式的实现
当前位置: article > 正文
【大数据存储】实验1 Hadoop伪分布式安装
作者:羊村懒王 | 2024-04-05 19:39:50
赞
踩
【大数据存储】实验1 Hadoop伪分布式安装
实验1 Hadoop伪分布式安装
- 下载安装虚拟机软件Vmware,下载Ubuntu镜像文件,安装Ubuntu虚拟机
- 在Ubuntu系统中创建用户
已有用户prx17

更新APT,安装vim
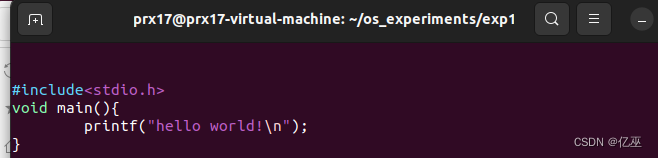
使用vim创建并编辑一个文件
vim hello.c
(按o键进入编辑模式)
源程序
#include<stdio.h>
void main(){
printf("hello world!\n");
}
点击esc退出编辑模式,输入:wq,保存并退出文件
Ls查看文件
安装SSH并配置SSH无密码登录
![]()
使用ssh localhost登录
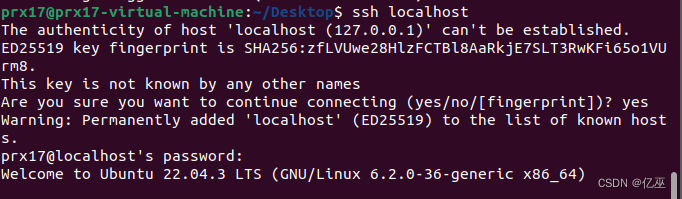
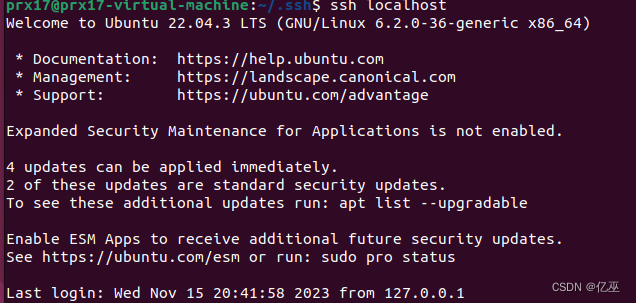
配置无密码登录

完成无密码登录
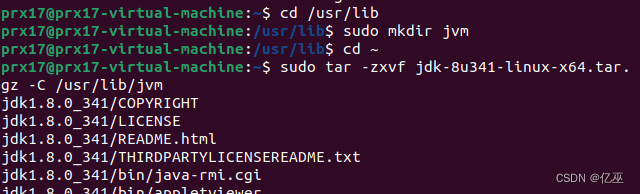
安装Java环境
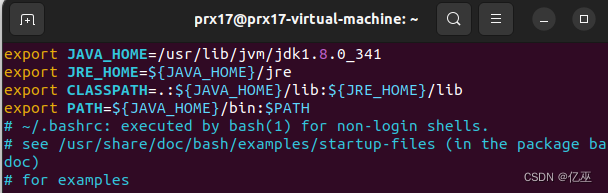
配置环境
检查是否安装成功

- 下载Hadoop并解压
解压缩hadoop安装包,给予用户prx17 hadoop文件权限,并检查hadoop是否安装成功

选择运行grep例子
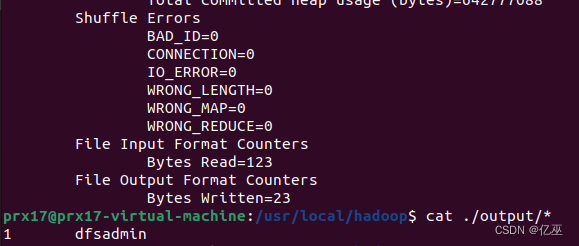
- Hadoop伪分布式安装(修改配置文件;
core-site.xml
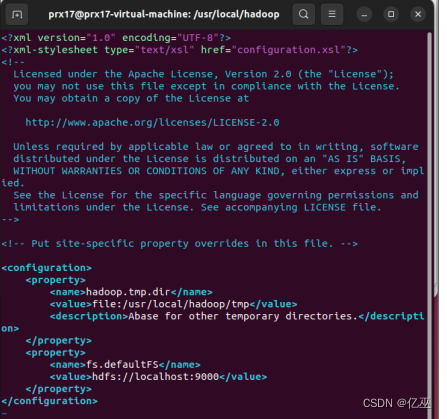
hdfs-site.xml

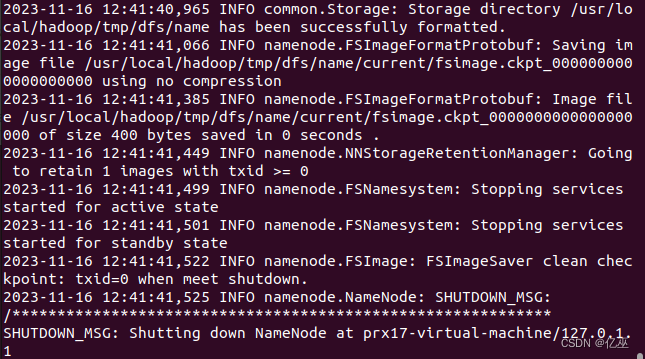
名称节点格式化;
./bin/hdfs namenode -format
“successfully formatted”的提示信息
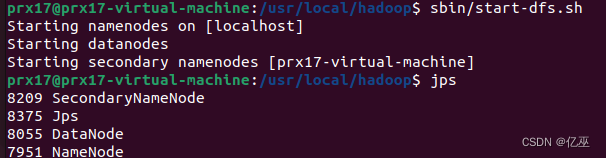
启动Hadoop,输入jps命令,查看是否启动成功
启动成功,也可以使用start-all.sh,但是伪分布式可以只使用dfs
Web http://localhost:9870查看hdfs信息
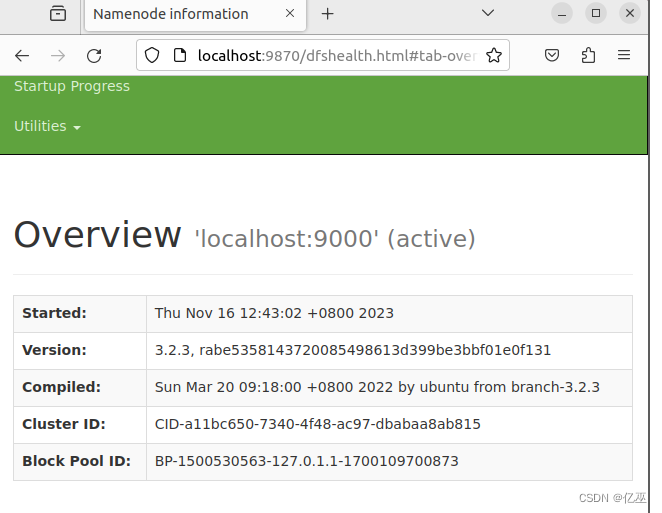
l
- 运行测试例子
创建用户目录
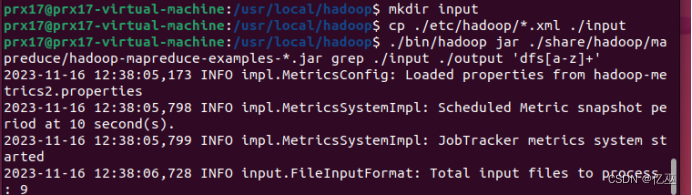
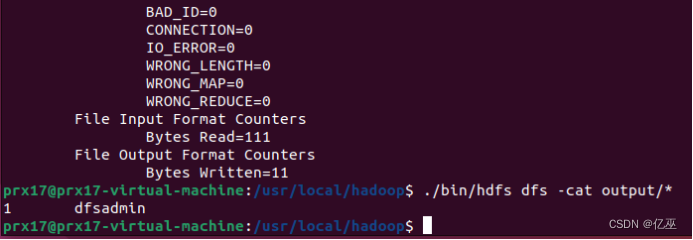
运行自带的grep程序
- 关闭Hadoop
./sbin/stop-dfs.s

心得体会:
在安装hadoop之后发生了查看hadoop version失败的问题,后来发现是安装路径添加错误。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/367617?site
推荐阅读
相关标签

