
- 1Git常见问题记录:Git 管理代码开发中敲git status时,会发现有很多untracked files文件该怎么办?_untracked files怎么处理
- 2js获取指定时间范围内指定间隔天数的所有日期_js通过开始时间和结束时间、间隔时间计算出中间的所有日期
- 3sql数据库的csv导入报错:Columns in table defination are 11, columns in file are 14:sjsysc-hh405-zbhx783w
- 4数据库之MHA高可用集群部署及故障切换_mha4mysql
- 5身份证识别系统(安卓)
- 6鸿蒙样例项目部署到真机上时出现No signature is configured. Configure a signature by referring to the following link.
- 7移动云智能算力调度平台,谱写算力互联互通新篇章
- 8python计算bmi指数_python 练习题:计算的BMI指数,并根据BMI指数条件选择
- 9Python爬虫学习( 二 )——会话和Cookies_蜘蛛抓取会读取网站cookie
- 10yolov8---predict实验_yolov8 predict
python之文件操作、对.txt文本文件的操作(读、写、修改、复制、合并)、对json文本文件的操作、json字符串与字典的相互转换。_python 操作txt
赞
踩
注意:本篇所讲的文件操作,都是对后缀为.txt、.json文件进行的操作。
1、json其实就是一个文件的格式,像.txt一样,json也是一个纯文本文件。与.txt不同的是,json常用来存放有键值对的数据,写法上像python中的字典一样,但与字典不同的是,字典是一个数据类型,且字典在定义的时候,字典里面的字符串用单引号或者双引号都可以。而json是文件的一种格式。 文件的后缀为:.json 。json文件在编写时候,里面的字符串只能用双引号,否则报错。
2、所谓json字符串,定义的时候,就是在json文件的内容外面加上一对单引号。用print输出它的时候,字符串用的是双引号。
3、json字符串与python中的字典这个数据类型之间的转化:
(1)loads() :将json字符串转换成字典格式。
(2)dumps(): 将字典格式转换成json字符串格式。
技巧:要区分是json字符串还是字典,看print结果中,键值对里的字符串的引号就知道了,如果是双引号,那就是json字符串,如果是单引号那就是字典。
4、with open和open的区别:总的来说,with open就比open少写了一个文件关闭的代码,其它都一样。
with open是open的一种简化的写法,使用with open,不需要写close关闭文件,系统自动就会关文件。而open不行,操作完文件,最后一步一定要写close,否则,代码不会报错,但这个文件会一直占用资源。
- #法1
- file = open(r"D:\测试\文件读写练习\a.txt", "r")
- txt = file.read()
- print(txt)
- file.close() # 关闭文件,这步一定要写,不写会占用资源
-
- 结果:
- 111
- 222
- 333
- 444
-
-
- # 法2
- with open(r"D:\测试\文件读写练习\a.txt", "r") as f:
- txt = f.read()
- print(txt)
- 结果:
- 111
- 222
- 333
- 444

一、文件的概念及种类
1、所谓文件就是用来保存数据的,这样数据就可以长期的保存下来,等到以后需要的时候再去用。
2、文件的种类:文本文件和二进制文件。
(1)文本文件:就是可以使用文本编辑软件打开的文件(也可以叫查看),这样的文件就是文本文件。
例如:python的源代码、txt文本文件、json文本文件。这些都能用文本编辑软件打开,比如:用记事本打开。
注意:doc、excel这些不属于文本文件。
这里讲解的文本文件都说的是:以.txt、.py、.json后缀结尾的文本文件。
(2)二进制文件
比如:图片、视频、音频。
这种文件不能用文本编辑软件打开。
二、文件操作流程、操作文件的套路
第一步:打开文件。——open
第二步:操作文件,比如:读、写、追加写。 ——read、write
读:将文件的内容读入内存。
写:把内容写入文件。
第三步:关闭文件。 ——close
三、操作文件的函数和方法
一共一个函数、三个方法。分别是:open函数、read方法、write方法、close方法。
1、open——打开文件
负责打开文件,并返回文件对象。而read、write、close都是通过文件对象来调用。
open打开文件的几种方式:
(1)不加b只打开文本文件
r——只读
w——只写
a——追加写
(2)加b打开二进制文件。
rb——用二进制方式打开,只读
wb——用二进制方式打开,只写
ab——用二进制方式打开,追加写
2、read——读取文件
如果文件存在,正常读取,如果不存在报错。
(1)read()—— 一次性读取文件所有内容。返回的是一个字符串,也就是说,read是把整个文件内容读成一个字符串。然后加载到内存。弊端:如果文件太大,会特别占用内存。因此可以按行读取。
(2)readline()——按行读取文件内容、一次读一行,如果多次调用,就会依次一行一行往下读。每调用一次readline(),内部的文件指针就会向下一行移动,这样,就能实现按行读取了。readline()读到文件末尾,也就是把文件所有内容读完了,就会返回"",里面啥都没有。所以,想看readline()把文件读完没有,可以用if判断readline()返回的内容是不是"",如果是则说明读完了。
(3)readlines()——也是一次性读取文件所有内容、一次性读取文件的所有行,但返回的是一个列表。也就是说,列表中的每一个成员就是文件中的每一行。文件有多少行,列表就有多少成员。当遍历列表时,效果跟用readline 一样。
3、close——关闭文件
4、代码演示:读、写、修改、复制、合并
(1)读文件
例如:D盘下,有文件【文件操作练习.txt】内容为:你好Python。现在把它全部读出来。
- # 1、打开文件
- file = open(r"D:\文件操作练习.txt", "r", encoding="utf8") # r、R把\的转义字符,变成普通字符
- # 2、读取文件内容
- txt = file.read()
- print(txt) # 把读到的内容显示出来、显示文件内容
- # 3、关闭文件
- file.close()
-
- 结果:
- 你好Python。
注意:无论是读文件还是写文件,只要有汉字,都要加 encoding="utf8",否则显示乱码、报错。
安全起见最好的办法就是无论是什么操作,都加上。
(2)写文件
例如:把【hello你好】写到上面那个文件里。
注意:写文件时,如果文件不存在,那就创建,如果存在,w就是覆盖文件内容,a就是追加写,两种方式分别进行演示。
第一种:w覆盖写,写完之后会把原来的内容覆盖掉。
- file = open(r"D:\文件操作练习.txt", "w", encoding="utf8") # w覆盖写
- file.write("hello你好")
- file.close()
- file = open(r"D:\文件操作练习.txt", "r", encoding="utf8") # 验证是不是已经写进去了
- txt = file.read() # 或者直接把文件打开看
- print(txt)
- file.close()
-
- 结果:
- hello你好
第二种:a追加写,在原来内容的后面写。
- # 如果文件不存在就创建,如果文件存在就追加,每执行一次就追加一次
- file = open(r"D:\文件操作练习.txt", "a", encoding='utf8')
- file.write("今天星期一")
- file.close()
- file = open(r"D:\文件操作练习.txt", "r", encoding="utf8") # 读文件
- txt = file.read()
- print(txt)
- file.close()
-
- 结果:
- 你好Python。今天星期一
如果前面、后面想加换行,就加\n。
例如,在【你好python】后面空一行再写【今天星期一】。
- file = open(r"D:\文件操作练习.txt", "a", encoding='utf8')
- file.write("\n\n今天星期一") # 两个\n表示空两行再写。
-
- file.close()
- file = open(r"D:\文件操作练习.txt", "r", encoding="utf8")
- txt = file.read()
- print(txt)
- file.close()
- 结果:
- 你好Python。
-
- 今天星期一
file.write("\n\n今天星期一") # 两个\n表示空两行再写。就是说,你要写的话是紧跟之前内容后面写,现在,加一个换行,说明敲一个回车,也就是另起一行写,再敲一个回车,那就再另起一行。
例如:另起一行写【今天星期一】。
- file = open(r"D:\文件操作练习.txt", "a", encoding='utf8')
- file.write("\n今天星期一") # 前面加\n,说明在新的一行写
-
- file.close()
- file = open(r"D:\文件操作练习.txt", "r", encoding="utf8")
- txt = file.read()
- print(txt)
- file.close()
- 结果:
- 你好Python。
- 今天星期一
(3)修改文件
思路:先用r方式把【文件操作练习.txt】的内容读出来,因为read读出来是字符串,所以可以用字符串的replace方法进行替换,并将替换后的结果保存到一个变量里,关闭文件,用w方式再次打开那个文件,把变量写进去即可。
例如:把【Python】改为【word】。法1,不加判断。
- file = open(R"D:\文件操作练习.txt", "r", encoding="utf8")
- txt = file.read()
- a = txt.replace("Python", "word") # read默认内容读出来是字符串格式
- file.close() # 这一步必须关闭
- file = open(r"D:\文件操作练习.txt", "w", encoding='utf8')
- file.write(a) # 把修改后的a写入文件
- file.close()
-
- # 看下改好了没有
- file = open(R"D:\文件操作练习.txt", "r", encoding="utf8")
- txt = file.read()
- print(txt)
- file.close()
- 结果:
- 你好word。
法2 加判断
- file = open(r"D:\文件操作练习.txt", "r", encoding="utf8")
- txt = file.read()
- file.close()
- if "Python" in txt: # 先判断下有没有,有的话再改
- s = txt.replace("Python", "word")
- file = open(r"D:\文件操作练习.txt", "w", encoding="utf8")
- file.write(s)
- file.close()
- # 看下改好了没有
- file = open(R"D:\文件操作练习.txt", "r", encoding="utf8")
- txt = file.read()
- print(txt)
- file.close()
- 结果:
- 你好word。
(4)复制文件
例如:把文件a.txt复制为b.txt。
思路:把a.txt打开,读取里面所有内容,然后用w方式把b.txt打开,把内容写入。
把【文件操作练习.txt】复制到其它位置。比如,这里是把文件复制到同目录下的【文件操作练习1.txt】。如果想复制到其它位置,改路径即可,文件名也可以不用改。
例如,把上一步操作的【你好word。】复制到同目录下的【文件操作练习1.txt】里。
- file = open(r"D:\文件操作练习.txt", "r", encoding="utf8")
- txt = file.read()
- file.close()
- file = open(r"D:\文件操作练习1.txt", "w", encoding='utf8')
- file.write(txt)
- file.close()
-
- # 验证看下复制进去没有
- file = open(r"D:\文件操作练习1.txt", "r", encoding="utf8")
- txt = file.read()
- print(txt)
- file.close()
- 结果:
- 你好word。
(5)合并文件
例如,把文件a.txt和b.txt合并为c.txt。
思路:把a.txt内容读出来,存到变量a,把b.txt内容读出来,存到变量b,然后把a+b的结果写入c.txt。
例如:a.txt、b.txt内容分别是:
- # a.txt 内容
- 111
- 222
- 333
- 444
-
- # b.txt 内容
- 你好
合并到c.txt
- file = open(r"D:\测试\文件读写练习\a.txt", "r", encoding="utf8")
- a = file.read() # 将a.txt读出来的内容存到变量a
- file.close()
- file = open(r"D:\测试\文件读写练习\b.txt", "r", encoding="utf8")
- b = file.read() # 将b.txt读出来的内容存到变量b
- file.close()
- file = open(r"D:\测试\文件读写练习\c.txt", "a", encoding='utf8') # 注意a或者w
- file.write(a + b) # 因为都是字符串所有可以使用+拼接
- file.close()
-
- # 验证写进去没有
- file = open(r"D:\测试\文件读写练习\c.txt", "r", encoding="utf8")
- txt = file.read()
- print(txt)
- file.close()
- 结果:
- 111
- 222
- 333
- 444你好
注意:如果不是字符串可以分别写入。
file.write(a)
file.write(b)
(6)readline()方法演示
例如: 通过readline(),来读取a.txt文件的所有内容。
- file = open(r"D:\测试\文件读写练习\a.txt", "r", encoding="utf8")
- while True: # 因为不知道文件有多少行,所以可以写个人造死循环
- txt = file.readline()
- if txt == "": # 如果readline已经读取到文件最后,就会读不出来内容了,所以返回的就会是""
- break # 使用break来退出这个人造死循环
- print(txt, end="")
- file.close()
- 结果:
- 111
- 222
- 333
- 444
- 进程已结束,退出代码 0
例如:只显示偶数行的内容。
思路:只读方式打开文件,做一个循环来读取所有行,然后在循环开始的时候做一个计数器,用来判断行数是奇数还是偶数,如果是偶数就输出,如果是奇数就不输出,每执行一次循环,计数器就+1。
- file = open(r"D:\测试\文件读写练习\a.txt", "r", encoding="utf8")
- index = 1 # 对行数进行计数
- while True: # 做一个循环用来读取所有行
- txt = file.readline() # 按行读取
- if txt == "":
- break
- if index % 2 == 0:
- print(txt, end="")
- index += 1
- file.close()
- 结果:
- 222
- 444
- 进程已结束,退出代码 0
(7)readlines()代码演示
例如:读取a.txt。
- # a.txt的内容为:
- 111
- 222
- 333
- 444
- file = open(r"D:\测试\文件读写练习\a.txt", "r")
- list1 = file.readlines()
- print(list1)
- file.close()
- 结果:
- ['111\n', '222\n', '333\n', '444']
-
- 进程已结束,退出代码 0
当然,既然是列表那就可以遍历。那么这样就跟用readline效果一样了。
- file = open(r"D:\测试\文件读写练习\a.txt", "r")
- list1 = file.readlines()
- for i in list1:
- print(i, end="")
- file.close()
- 结果:
- 111
- 222
- 333
- 444
- 进程已结束,退出代码 0
(8)求文件当中的最值及两者之差。
当一个文件的每一行内容都是整数时候,可以求这个文件的最大值、最小值、最大与最小的差值。
例如:文件a.txt内容如下:求该文件中的最值之间的差值。
- 111
- 222
- 333
- 444
- # 法1,用readline
- # 思路:先定义一个空列表,然后循环的一行行读取内容,
- # 把每行的内容都转化为int型,添加到空列表里,然后再对这个列表求最值。
- file = open(r"D:\测试\文件读写练习\a.txt", "r")
- list1 = []
- while True:
- txt = file.readline() # 按行读取
- if txt == "":
- break
- list1.append(int(txt)) # 把每个成员都转化为整型后添加到空列表里
- file.close()
- print(max(list1)-min(list1))
- 结果:
- 333
-
- # 法2,用readlines————不推荐
- # 思路:直接就把所有内容读完,返回列表,再对列表求最值,然后再转化为int
- file = open(r"D:\测试\文件读写练习\a.txt", "r")
- list1 = file.readlines() # 读取所有内容,返回一个列表,列表的成员是文本文件的每一行内容
- print(int(max(list1)) - int(min(list1)))
- file.close()
- 结果:
- 333
-
使用法2需要注意的问题:对字符串求最值时候,要注意,这种方法只适用于,字符串的所有成员每个数字都不一样。如果一样,结果就不对了。例如:
d.txt文件内容如下:
- 1
- 11
- 2
- 23
- 223
现在要给它求最值。
- file = open(r"D:\测试\文件读写练习\d.txt", "r")
- list1 = file.readlines()
- print(max(list1), end="")
- print(type(max(list1)))
- print(min(list1), end="")
-
- print(int(max(list1)) - int(min(list1)))
-
- 结果:
- 23
- <class 'str'>
- 1
- 22
显然,这个结果不对,因为,从d.txt中可以看到,最大值应该是223,最小值是1,差值是223-1=222,但是这里却给出了23,原因是,首先读取文件之后,列表中的每个成员是字符串类型,而字符串中的数字又有相同的地方。例如23和223,它们在比较大小的时候,是先比较第一个字符,如果相同,就比较第二个字符,哪个字符的ascii码大哪个字符就大,所以这里在比较到第二个字符时,3>2,就会返回23 。
所以不推荐法2 。安全的做法就是像法1一样,先把每个成员转为整型,再求最值。
- file = open(r"D:\测试\文件读写练习\d.txt", "r")
- list1 = []
- while True:
- txt = file.readline() # 按行读取
- if txt == "":
- break
- list1.append(int(txt)) # 把每个成员都转化为整型后添加到空列表里
- file.close()
- print(max(list1) - min(list1))
- 结果:
- 222
再比如,更简单的解释。
- list1 = [2, 10, 3] # 列表的每个成员是int型
- list2 = ["2", "10", "3"] # 列表的每个成员是str型
- print(max(list1), min(list1))
- print(max(list2), min(list2))
- 结果:
- 10 2
- 3 10
小结:如果长得像数字的字符串进行比较大小的话,比较的原理就是,先比较字符串中的每一个字符,谁的ascii值大谁就大。
解析:
- file = open(r"D:\测试\文件读写练习\a.txt", "r")
- list1 = file.readlines() # 读取所有内容,返回一个列表,列表的成员是文本文件的每一行内容
- print(list1) # ['111\n', '222\n', '333\n', '444']
- print(type(list1[0])) # 查看列表第一个成员的数据类型
- file.close()
-
- 结果:
- ['111\n', '222\n', '333\n', '444']
- <class 'str'>
-
- # 也就是说,列表中的每个成员都是字符串类型,字符串求最值是根据ascii码。
- # 而这里,,我们想求的是整数的最值,所以需要把字符串类型转化为int型。
四、json文本文件含义、语法规则
1、json的含义
首先,json其实就是一个文件的格式,像.txt一样,json也是一个纯文本文件。与.txt不同的是,json常用来存放有键值对的数据,写法上像python中的字典一样,但与字典不同的是,字典是一个数据类型,而json是文件的一种格式。 文件的后缀为:.json,除此之外,字典中,字符串可以用单引号或者双引号括起来,而json文件中,字符串只能用双引号。
json全称:JavaScript Object Notation。
json的特点:
(1)它是纯文本文件,常用来定义数据。
(2)具有清晰的层级结构,方便阅读
2、json文件的语法规则
(1)大括号保存对象,中括号保存数组。(python中叫列表,java里叫数组)。
(2)对象、数组可以相互嵌套。
(3)数据采用键值对表示,多个数据之间用逗号分隔,最后一个数据后面不写逗号。
键值对的值可以是:
(1)数字(int、float)——不用引号。
(2)字符串。——要用双引号引起来,必须是双引号
(3)布尔值true、false,注意必须是小写。
(4)值为空值时,写null——注意是小写。
(5)数组或对象,数组的话写在中括号里,对象的话写在大括号里。
小结:所有数据用大括号括起来,大括号里面写键值对,字符串用双引号,对象用大括号,列表用中括号,数字直接写,对象数组可以相互嵌套。此外,小写的null、小写的true、false。
例如:下面这张图片就是一个json文件。
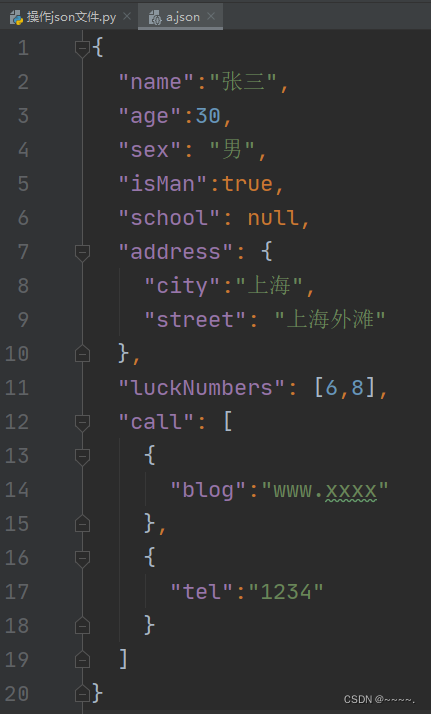
五、对json文本文件的操作——读取、写入、修改
1、json文件的创建
在Pycharm中,新建—》文件,然后起个文件名.json,回车即可。
2、读取json文件
第一步:导入json模块。
第二步:打开json文件。
第三步:调用json模块的load方法,进行读取。
第四步:关闭文件。
例如:读取上面的a.json文件。这个案例中的a.json文件跟下面代码的python文件在同一级。
注意:如果俩不在同一级,a.json需要写上绝对或者相对路径,否则找不到这个a.json文件。
- import json
-
- file = open("a.json", "r", encoding="utf8") # json中有中文,要指定字符集为utf8
- data = json.load(file) # 调用json模块中的load方法,读取文件内容
- file.close()
- print(data) # 输出内容
- print(type(data)) # 查看内容是什么格式
-
- 结果:
-
- {'name': '张三', 'age': 30, 'sex': '男', 'isMan': True, 'school': None, 'address': {'city': '上海', 'street': '上海外滩'}, 'luckNumbers': [6, 8], 'call': [{'blog': 'www.xxxx'}, {'tel': '1234'}]}
- <class 'dict'>
当然也可以使用with open打开文件,结果也是一样的,只是不用再写关闭文件的那行代码。
- import json
-
- with open("a.json", "r", encoding="utf8") as f:
- data = json.load(f)
- print(data)
- 结果:
- {'name': '张三', 'age': 30, 'sex': '男', 'isMan': True, 'school': None, 'address': {'city': '上海', 'street': '上海外滩'}, 'luckNumbers': [6, 8], 'call': [{'blog': 'www.xxxx'}, {'tel': '1234'}]}
既然读取出来的内容是字典,那么就能对字典进行遍历。
- import json
-
-
- with open("a.json", "r", encoding="utf8") as f:
- data = json.load(f)
- # print(data)
- # print(type(data))
-
- for i in data:
- print(i, data[i]) # 遍历键值对,字典可以通过【字典名[键]】的方式来取值。
-
- 结果:
- name 张三
- age 30
- sex 男
- isMan True
- school None
- address {'city': '上海', 'street': '上海外滩'}
- luckNumbers [6, 8]
- call [{'blog': 'www.xxxx'}, {'tel': '1234'}]
3、写入json文件
第一步:导入json模块。
第二步:用只写的方式打开json文件,注意编码方式是utf8。
第三步:用dump方法把字典写入到json文件里。注意:如果有中文要加ensure_ascii=False表示中文不转义。
第四步:关闭文件。
注意:写的时候只能是w模式,不能是a模式。
例如:
- import json
-
- dict1 = {"name": "张三", "age": 18, "sex": "男"}
- file = open("data.json", "w", encoding="utf8") # 如果没有data.json将会自动创建,如果有则覆盖(因为是w模式)
- json.dump(dict1, file, ensure_ascii=False) # ensure_ascii=False表示中文不转义
- file.close()
- 结果:
-
- 进程已结束,退出代码 0
-
-
-
- # 法2 用with open
- import json
-
- dict1 = {"name": "张三", "age": 18, "sex": "男"}
- with open("data.json", "w", encoding="utf8") as f:
- json.dump(dict1, f, ensure_ascii=False)
-
- 结果同上。
然后看这个同级目录下data.json中有没有写入。结果如下,说明成功写入。
- # data.json中的内容
-
- {"name": "张三", "age": 18, "sex": "男"}
注意:json中不能追加写,会报错。
4、修改json文件中的数据。
例如:将上面data.json中的年龄改为30岁。
思路:先把内容读出来,读出来的结果是一个字典,然后通过【字典名[键]=值】的方式修改为30,最后再把字典写回到data.json里。
- import json
-
- file = open("data.json", "r", encoding="utf8")
- txt = json.load(file)
- txt["age"] = 30 # 修改字典中键的值
- print(txt) # 查看修改后的字典
- file.close()
- file = open("data.json", "w", encoding="utf8") # w 覆盖写,json中写只能用w
- json.dump(txt, file, ensure_ascii=False) # dump语法:dump(字典,写入哪个文件,中文不转义)
- file.close()
-
- 结果:
- {'name': '张三', 'age': 30, 'sex': '男'}
-
-
-
- # 用with open写
- import json
-
- with open(r"data.json", "r", encoding="utf8") as f:
- txt = json.load(f)
- txt["age"] = 30
- print(txt)
- with open(r"data.json", "w", encoding="utf8") as f:
- json.dump(txt, f, ensure_ascii=False)
-
- 结果同上。
5、操作json文件的时候要注意
(1)json文件的后缀一定是.json。
(2)json文件中,最后一个键值对后面不加逗号。
(3)如果项目中有json文件,那么新建的python文件起名字时候,一定不能叫json.py。
6、json字符串与字典的转换
(1)loads() :将json字符串转换成字典格式。
所谓json字符串,就是在json文件的内容外面加上一对单引号。
(2)dumps(): 将字典格式转换成json字符串格式。
这个就是将python中字典这个数据类型,转化成json字符串。
例如:loads()举例。将json字符串转为字典。
- import json
-
- str1 = '{"name":"张三","age":20,"sex":"男"}' # 这是一个json字符串
- # str1 = "{'name':'张三','age':20,'sex':'男'}" # 这是一个错误写法!json中的字符串必须用双引号
- print(str1)
- print(type(str1)) # 查看str1的数据类型
- print(json.loads(str1)) # loads将字符串转为字典
- print(type(json.loads(str1))) # 查看转化后的数据类型
-
- 结果:
- {"name":"张三","age":20,"sex":"男"}
- <class 'str'>
- {'name': '张三', 'age': 20, 'sex': '男'}
- <class 'dict'>
-
-
- # 注意:json文件中字符串只能用双引号,否则报错。
- str1 = "{'name':'张三','age':20,'sex':'男'}" # 这是一个错误写法!json中的字符串必须用双引号
- print(str1)
- print(type(str1)) # 查看str1的数据类型
- print(json.loads(str1)) # loads将字符串转为字典
- print(type(json.loads(str1))) # 查看转化后的数据类型
-
- 结果:报错!!
- {'name':'张三','age':20,'sex':'男'}
- <class 'str'>
- json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
注意:json中的数据如果是字符串只能用双引号引起来,这是json文件编写的规则,而字符串本身就是要用单引号或者双引号引起来,所有,这里的json字符串只能写成:外面单引号,里面字符串是双引号。
例如:dumps举例。将字典转为json字符串。
- import json
-
- # dict1 = {'name': '张三', 'age': 20, 'sex': '男'} # 这是一个字典
- # 或写成
- dict1 = {"name": "张三", "age": 20, "sex": "男"} # 这也是一个字典
- print(dict1)
- print(type(dict1))
- print(json.dumps(dict1, ensure_ascii=False)) # dumps:将字典转为json字符串
- print(type(json.dumps(dict1)))
-
- # 注意:使用dums时,有汉字时,要加ensure_ascii=False,防止汉字被转义
-
- 结果:
- {'name': '张三', 'age': 20, 'sex': '男'}
- <class 'dict'>
- {"name": "张三", "age": 20, "sex": "男"}
- <class 'str'>
-
-
- # 定义一个字典,字典里面的字符串用单引号双引号都可以。
!!!前方高能~~
小结:从print结果中可以得出这样一个结论:要区分是json字符串还是字典,看print结果中,键值对中字符串的引号就知道了,如果是双引号,那就是json字符串,如果是单引号那就是字典。
六、总结字典、json字符串
1、字典
定义的时候:字典里面的字符串用单引号、双引号都可以。
print输出的时候:里面的字符串用的是单引号。(或者说,键值对中的字符串用的是单引号。)
例如:定义一个字典,字典中的字符串,分别用双引号、单引号来进行演示。
法1:字典中的字符串用双引号。
- dict1 = {"name": "张三", "age": 20, "性别": "男"} # 定义一个字典
- print(type(dict1)) # 查看dict1是什么数据类型
- print(dict1) # 输出dict1
-
- 结果:
- <class 'dict'>
- {'name': '张三', 'age': 20, '性别': '男'}
-
- # 定义时候的双引号变成了单引号
法2:字典中的字符串用单引号。
- dict1 = {'name': '张三', 'age': 20, '性别': '男'} # 定义一个字典
- print(type(dict1))
- print(dict1)
-
- 结果:
- <class 'dict'>
- {'name': '张三', 'age': 20, '性别': '男'}
-
- # 定义时候的单引号还是单引号
小结:只要输出来的字符串用的是单引号那就一定是字典。
2、json字符串
(1)字符串:就是外面要打单引号或者双引号的东西,就叫字符串。或者说,用引号引起来的就叫字符串。
(2)json文件编写规范:如果数据是字符串类型,那么就要打双引号。
(2)json字符串:既要满足字符串的要求又要满足json文件规范,两者结合的结果就是:
定义的时候:外面用单引号,里面用双引号。
例如:str1 = '{"name": "张三", "age": 20, "性别": "男"}'
print输出的时候:里面的字符串是双引号。(或者说,键值对中的字符串用的是双引号。)
例如:
- str1 = '{"name": "张三", "age": 20, "性别": "男"}' # 外面单引号,里面双引号
- print(type(str1)) # 字符串都用了双引号,这个才符合json编写规则
- print(str1)
- 结果:
- <class 'str'>
- {"name": "张三", "age": 20, "性别": "男"} # 字符串输出是双引号
-
-
- # 对这个str1转为 字典
-
- import json
-
- str1 = '{"name": "张三", "age": 20, "性别": "男"}'
-
- print(json.loads(str1)) # loads:将json字符串转为字典
- print(type(json.loads(str1))) # 查看转化后的数据类型
- 结果:
- {'name': '张三', 'age': 20, '性别': '男'} # 单引号,说明是字典
- <class 'dict'>
例如:错误的写法,导致最终结果报错。
- str1 = "{'name': '张三', 'age': 20, '性别': '男'}" # 外面双引号,里面单引号
- print(type(str1)) # 说明这就不是json文件
- print(str1) # 因为json文件在写的时候,要求字符串要用双引号
-
- 结果:
- <class 'str'>
- {'name': '张三', 'age': 20, '性别': '男'}
-
-
- # 假如现在要对这个str1转为字典
-
-
- import json
- str1 = "{'name': '张三', 'age': 20, '性别': '男'}"
- print(json.loads(str1)) # loads:将字符串转为字典
- print(type(json.loads(str1))) # 查看转化后的数据类型
-
- 结果:报错!
- json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
-
-
- # 因为它都不是json文件,所以也就用不了loads这个方法了。


