
- 1postcss安装和使用(详细)
- 25 种常见的 Linux 打包类型:tar、gzip、bzip2、zip 、 7z_linux文件打包
- 3华为鸿蒙javascript,第一个华为鸿蒙app跑起来了
- 4Java -枚举的使用_java枚举的使用
- 5仓库管理系统/课程设计/ASP.NET/_.net 后端 仓库管理模版页面布局
- 6python汽车大数据分析可视化系统【计算机毕业设计】大数据 (含源码)建议收藏_ps d:\毕业设计\车辆大屏可视化> python manage.py startapp myap
- 7计算机开启蓝牙网络,怎么打开电脑蓝牙功能(笔记本电脑蓝牙怎么开)
- 8MLP(多层神经网络)介绍_mlp算法分布式
- 9微信小程序对接微信支付详细教程_微信小程序接入微信支付
- 10华为ensp配置vrrp
RabbitMQ + SpringCloud使用及避坑(大章)_springcloud+nacos+rabbitmq
赞
踩
RabbitMQ 的开发语言是Erlang,它的源码阅读起来学习成本太高了,所以这里就不详细看了,本次主要是结合springCloud 的项目来真正使用RabbitMQ 的几种交换器,还有一些业务场景的模拟,最主要的还是避坑。
为什么说是避坑呢,因为项目中加入了RabbitMQ 后会导致代码的复杂提高、可用性降低,同时因为rabbitMQ 一些本身的设计,就很容易出现比如:消息丢失、重复消费、一致性等问题,这些问题没办法从rabbitMQ 本身的配置或者代码下手,上面也说了rabbitMQ 底层语言是Erlang,所以也很难根据源码流程扎到问题的解决方案,只能人为的去做对应的机制补偿或控制。
认识MQ
老套路,先说基础概念,下面的内容大部分来源百度,小部分来源是我的见解,这里主要还是一个整理。
先说什么是MQ,MQ 也就是消息队列中间件,是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。
目前使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ,消息中间件到底该如何使用,何时使用这是一个问题,胡乱地使用消息中间件增加了系统的复杂度,如果用不好消息中间件还不如不用。
现在市面上,也就是大部分的招聘信息中提到最多的三个MQ:RabbitMQ、Kafka、RocketMQ。这个三个MQ 之间的适用场景不一样,同时也不是可以相互替代的产品,这也导致它们之间的技术选型逻辑是不一样的。
技术选型
RabbitMQ 的本身的一些缺陷:
- erlang开发,对消息堆积的支持并不好,当大量消息积压的时候,会导致RabbitMQ 的性能急剧下降。每秒钟可以处理几万到十几万条消息。
- 同时消息处理顺序最多只能做到 非严格有序性。
- 还有一点就是消息在通过交换器给到队列之后,没有消费者绑定对应队列的话,消息会丢失,但是可以用死信队列保存,或者存储到MangoDB 中。
优点:社区庞大、问题决绝方案非常多、相关文档也很全面,部署起来也非常简单,消息传递微秒级,可控制消息重复消费问题。
适用范围:中小型企业项目,并发吞吐量峰值低于万级,业务方面允许少量数据丢失。
RocketMQ 的缺点相对来说比较少,它属于站在了前辈的肩膀上起来的,它的性能非常强大,最有力的证明就是每年的淘宝双十一,也因为它是后起之秀,它的社区相对来说没有那么庞大,文档也没有那么丰富,但是它的开发语言是java 的,源码阅读起来成本不高,但是它本身的API 完备性较低,首次部署的难度也较大。
再说说它的优点:
- java开发,面向互联网集群化功能丰富,对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,每秒钟大概能处理几十万条消息。
- 同时支持集群部署,单机吞吐量虽然只有万级,但是集群后吞吐量会急剧提升,同时阿里本身也提供了RocketMQ 的集群部署服务器,极大的减小了中小型企业的部署难度过高问题。
- 可用性非常高,支持分布式。
- 消息理论上不会丢失。
- 消息重复消费的问题,RocketMQ 这里不算是优点,因为它本身不做处理,也就说可以重复消费,但是可以业务端或者引入别的中间件来控制消息重复的问题。
适用范围:大型或者并发吞吐量峰值大于万级的企业项目,同时企业有相关的技术大佬最好,业务和吞吐量方面没有限制,注意开发过程中避免一些mq 的常见问题避坑就行。
Kafka 严格来说不单单是MQ,MQ 只是kafka 的一个功能,它不太适合在线业务场景。通常来说都是用kafka 来做日志管理和大数据管理,RocketMQ 设计的时候借鉴了很多kafka 的设计。
kafka 优点和缺点都很明显,它是由Scala开发,面向日志功能丰富,性能最高。当你的业务场景中,每秒钟消息数量没有那么多的时候,Kafka 的时延反而会比较高。所以Kafka 不太适合在线业务场景。
适用范围:kafka 一般在企业中是结合ES、Kibana 来做ELK 技术栈的,用于构建一个强大的日志分析平台。
MQ的作用
说完目前市面上比较热门的三种MQ 之后,回到MQ 本身。MQ 本身最需要做的就是三件事:解耦、异步、削峰。
这三件事现在分开说明一下:
解耦:字面的意思,解除代码的耦合,多模块之间调用的时候,代码耦合度会根据模块的数量成倍增长,如果其中的业务复杂度还很高的话,最后呈现出来的代码可读性和重复可用率会非常低。
当代码耦合度过高时,就需要一些中间件来实现解耦的操作,比如:RabbitMQ、openFeign 等,它们能帮助我们将模块和模块之间的调用转为别的方式调用。
当然如果只是为了解耦,而在项目中引入MQ 中间件的话,完全没有必要,因为别的中间件也能做到,同时也不会提到项目的复杂度。
异步:在刚刚入行的时候,这个应该就已经接触过了,异步处理业务,节约响应时间,提高用户体验,当然还是那句话,如果只是解耦或者异步的原因就引入MQ 中间件的话,得不偿失。异步的处理不一定要MQ,还有java 的线程、线程池等等。
削峰:在生产环境中,用户的访问量不可能是一成不变的,每一天每一个时间段的用户访问量都是呈变化趋势的,有时访问量高达上万,有时可能就只有几百,甚至几个,比如凌晨之后,那么削峰的意义就是削去峰值,当访问量达到上万时,我的服务器的业务处理肯定反应不过来,这里就需要将复杂的业务处理放在后面来做,当前峰值时间段只做简单业务,为的就是快速响应,同时将请求发给MQ,MQ 再慢慢的去消费处理复杂的业务逻辑。
削峰还有一个对应的名词:填谷,当访问量过了峰值后,就会慢慢的进入谷底,然后再迎来下一个峰值,然而我们已经在峰值的时候,将请求放到了MQ 中,目的是为了快速响应,只做了简单的业务处理,复杂的业务是放在MQ 中慢慢消费的,MQ 也就是在谷底时间进行了快速消费,也就是说的填谷。
其中削峰填谷说白了就是为了将每个时间段的不平均的请求访问量,尽量的做到时间段的平均。同时削峰填谷也是MQ 最主要的作用。
使用MQ经常遇到的坑
在正式使用RabbitMQ 之前,我们还需要了解使用MQ 会遇到哪些坑,这样在使用RabbitMQ 的时候,我们才能知道应该怎么避开这些坑。
面试的时候如果是问到MQ,面试官一般都是先问:MQ使用后可能会出现什么问题呢?可以先浅谈三个方面:
- 增加了系统的复杂度:因为一个系统引入了MQ 之后会造成系统的复杂性的提升,复杂性提升后,增加MQ 的维护成本
- 降低的系统的可用性:复杂性的提升意味这系统可用性的降低,因为MQ 一旦出现问题就会造成系统出现问题。
- 一致性问题:因为MQ 是异步处理消息,需要处理类似于消息丢失以及重复消费的问题,一旦处理不好就会造成重复消费问题。
消息堆积
使用MQ 中间件,我们首先要考虑到的就是消息堆积问题。
消息堆积的出现原因说的简单一点就是:生产者投递消息的速率 > 消费者消费的速率,两者速率完全不匹配的时候,就会导致消息会堆积在mq 服务器端中,没有及时的被消费者消费,所以就会产生消息堆积的问题。
比如:多台生产者服务器,对应一台消费者服务器,或者消费者业务逻辑过于复杂,导致前一条消息还没有消费完,后面就已经生产了多条消息。
注意的是:rabbitMQ 在消费者,将消息消费成功之后,消息会被立即删除。 kafka 或者rocketmq 消息消费如果成功的话,消息是不会立即被删除。
至于在使用rabbitMQ 的时候,如果消息已经被交换器写到了队列中,而且这个时候没有对应的消费者,消息是不会堆积的,是直接被丢弃了。(注意:这里说的是队列没有被消费者绑定的情况,不是说消费者在消费上一条消息,没有时间消费当前消息)
消息对接-如何避坑
两条思路:提高单个消费者的消费能力,加快消费速度,或者增加消费者,实现集群;还有就是批处理,减少网络传输次数。
重复消费
重复消费分为两个方面:
- 生产者重复生产,消费者消费了两条同样的消息;
- 生产者只生产了单条消息,消费者重复消费,有可能是消费者业务逻辑报错,但是部分数据没有回滚,然后失败消息又回到了队列中,消息这再次拉取消费,也有可能网络原因导致发送方与以及接收方消息重试。
重复消费的问题在各个MQ 的中间件中是不可能避免的,只能用另外容错或者别的机制来控制,没办法从根本上消除。
重复消费-如何避坑
其实最简单的方式就是引入另外的中间件,比如:Redis。
当生产者在发送消息是查询一次Redis 的,如果已经存在就不发送给MQ 了,如果不存在就将一个唯一键存进去,然后将唯一键封装到请求中发到MQ。
当消费者进行消费的时候,也就是拉取到MQ 中的消息,并解析出唯一键之后,再去用唯一键去查询Redis,如果Redis 中存在,就进行具体的业务逻辑处理,最后处理完成之后,再将Redis 中的唯一键删除,反之不存在的时候,就不走业务逻辑即可。
这个方法的好处就是不会出现分布式集群服务之后,消息对不上或者并发问题,坏处也就是依赖Redis,如果Redis 出现问题,MQ 也就出现问题了。
消息顺序性
继续就是:消息的顺序行问题。这个问题也很好理解,有一些业务场景需要有一定的执行先后顺序,比如:生产者发送了三条消息给MQ 服务器,然后由MQ 分别给到三个不同的业务消费者消费,虽然生产者生产消息的时候,是有先后顺序的,但是不同消费者去分别消费这三个消息的时候,有很大可能是没有顺序的。
实例说下,现在这个三个消费者分别是:订单、支付、短信,按照业务逻辑说,应该是订单的业务先结束后,才执行支付的逻辑,最后才是短信的发送逻辑,但是生产者虽然按照订单、支付、短信的顺序生产了三个消息给到MQ 服务器,但是消费者消费的时候,可能是短信先消费了,因为短信的业务逻辑相对来说简单,当访问处于峰值时,消息短暂堆积,很有可能是短信的消费者先消费完,导致先执行。
消息顺序性大部分情况下都可以用业务或者代码逻辑来解决,这个问题并不会对MQ 的使用有特别大的影响,但是需要注意就行。
消息顺序性-如何避坑
消息顺序性如果不通过业务逻辑或者代码逻辑来解决的话,单靠各个MQ 中间件自己来解决的话,目前只有rocketMQ 能够支持 严格有序,其余MQ 最多能支持到非严格有序。
具体的是实现做法就是:用单线程去绑定消费者,三个消息同时由同一个消费者消费,注意这里的消费者是不能集群的,集群了就不会有序了。
实现延时消息
这个延时消息就不会坑了,是一种比较容易出错的业务场景,比如:叮咚买菜的下单、携程的购票、京东的订单支付、淘票票的在线购座等等,都是一种延迟消息的实现。
具体的实现方式推荐几种:
- 数据库轮询:通常是在小型项目中使用,即通过一个线程定时的去扫描数据库,通过订单时间来判断是否有超时的订单,然后进行update 或delete 等操作;(不推荐,对服务器内存消耗太大,而且频繁查询数据库,数据库损耗极大)
- JDK的延迟队列:利用JDK 自带的DelayQueue 来实现,这是一个无界阻塞队列,该队列只有在延迟期满的时候才能从中获取元素,放入DelayQueue 中的对象,是必须实现Delayed 接口的;(不推荐,还是对服务内存消耗太大,容易oom,代码复杂度也高)
- netty时间轮算法:这个就比较复杂了,具体的一两句也解释不清楚,有兴趣的可以自己去看下;(还是不推荐,理由还是消耗服务器内容,容易oom,但是对比JDK的延迟队列,代码复杂度能有效降低)
- RabbitMQ:以采用RabbitMQ 的死信队列来实现延时队列,RabbitMQ 可以针对Queue 和Message 设置 xmessage-tt,来控制消息的生存时间,如果超时,则消息变为dead letter,dead letter 会被投递到死信交换器,然后通过死信队列将消息发送出去。
- RocketMQ:它本身就可以实现18个等级的消息延时,但是不可以实现任意时间的消息延时,使用RocketMQ 的延时消息只需要按照正常消息发送,并指定延时等级即可,简单高效,并且这个延时时间可以在RocketMQ 的配置参数中进行配置。
其实上面的第四点和第五点都可以归为使用消息队列来实现的,不同就是使用的中间件产品不一样而已,不过具体的实现还是要具体的项目来分析,不能一概而论,不能可能为了实现一个延时消息,就添加一个RabbitMQ 中间件,或者将RabbitMQ 换成RocketMQ。
小结
大体的MQ 的内容基本就是上面这些,目前市面上比较好用的三款MQ 也要结合实际来做技术选型,它们不是相互替代的关系,而是互补的,还有就是使用MQ 的时候的一些坑,能避则避,可以的话,尽量不要在技术团队不成熟的时候,贸然在项目中添加MQ 中间件。
认识RabbitMQ
说完MQ,我们在浅谈一下本次的主角RabbitMQ。
RabbitMQ 也就是MQ 的其中一种中间件,MQ 会出现的问题,RabbitMQ 或多或少的都会出现,这里就不再赘述上面说的一些MQ 使用中的问题了,主要说说RabbitMQ 的一些自己的概念。
模型架构及重要概念
先看下模型架构,RabbitMQ 与AMQP 遵循相同的模型架构:
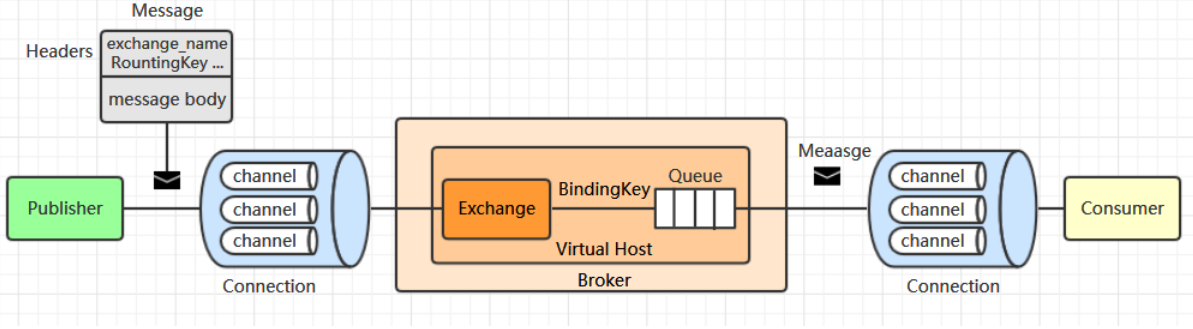
从模型架构中我们可以提取一些相关的概念:
- Publisher:生产者,消息的开始及来源,负责生产消息并将其投递到指定的交换器上。
- Message:消息,由消息头和消息体组成,消息头用于存储与消息相关的元数据:如目标交换器的名字 (exchange_name) 路由键 (RountingKey) 和其他可选配置 (properties) 信息。消息体为实际需要传递的数据。
- Exchange:交换器,负责接收来自生产者的消息,并将消息路由到一个或者多个队列中,如果路由不到,则返回给生产者或者直接丢弃,这取决于交换器的 mandatory 属性:为 true,返回给生产者,为 false,丢弃。
- BindingKey:交换器与队列通过 BindingKey 建立绑定关系。
- Routingkey:基于交换器类型的规则相匹配时,消息被路由到对应的队列中,这里和上面的BindingKey 是一对概念,Routingkey 是设置规则的名词,BindingKey 是规则本身,它们是一同存在的。
- Queue:队列,每个消息都会被投入到一个或多个队列。
- Consumer:消费者,就是接受消息的程序,同时RabbitMQ 提供了消息确认机制 (messageacknowledgement),并通过 autoAck 参数来进行控制:
true 时,此时消息发送出去 (写入TCP套接字) 后就认为消费成功,而不管消费者是否真正消费到这些消息,这种模式可以提高吞吐量,但会存在数据丢失的风险。
false 时,需要用户在数据处理完成后进行手动确认,只有用户手动确认完成后,RabbitMQ 才认为这条消息已经被成功处理,这可以保证数据的可靠性投递,但会降低系统的吞吐量。 - Connection:用于传递消息的 TCP 连接。
- Channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
- Virtual Host:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
- Broker:简单来说就是消息队列服务器实体。
安装和使用
正常来说MQ之类的中间件是直接安装在服务器本机上的,因为一般情况下中间件的服务基本都不会变动,没有必要安装到docker 上面,反而安装到docker 上面会增加性能损耗,就算是docker 技术已经非常成熟,还是一样会有损耗,并且容器中的配置和维护要比服务器本机上操作要复杂,反而安装在服务器本机上面会更好的利用宿主机的资源,有更好的性能表现。
我这里因为是自己的项目,不在乎性能的损耗,更在乎的是服务器上的安装和卸载软件的方便,所以就直接上docker 就行,具体情况还是要具体分析,不能一味地套用。
创建一个docker compose 的docker-composer.yaml 的文件,然后用docker-compose up -d 命令运行就可以,如果文件名称是不是docker-compose.yml 的话,用docker-compose -f 文件路径/文件名称 up -d 命令运行也可以,结束并杀死容器的命令也很简单,将上面命令的up -d 换成down 即可,容器如果启动失败就换成logs 去看日志。(如果docker 还是很熟悉的朋友,可以移步去我的docker 类型的文章中先了解一下,我的博客地址:www.liwqtm.cn/hexo)
下面看下具体的docker-compose.yml 的文件内容:
version: '3.8'
services:
rabbitmq:
image: rabbitmq:3.9.7-management
container_name: rabbitmq
ports:
- "5672:5672"
- "15672:15672"
volumes:
- /app/mq/rabbitMQ/data:/var/lib/rabbitmq
- /app/mq/rabbitMQ/logs:/var/log/rabbitmq
environment:
RABBITMQ_ERLANG_COOKIE: "supersecretcookie"
RABBITMQ_DEFAULT_USER: "***"
RABBITMQ_DEFAULT_PASS: "***"
networks:
- liwq-tm
networks:
liwq-tm:
external: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
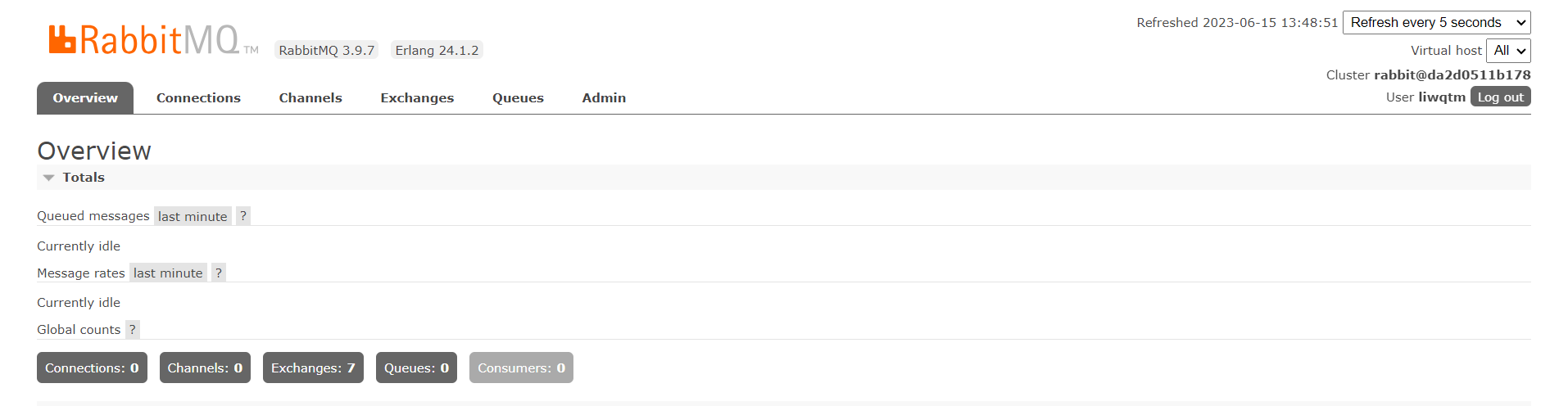
运行上面的docker-compose.yaml 文件,基本就能启动rabbitMQ 了,但是注意先创建数据和日志挂载目录,然后记得赋予root 的读写权限。当运行命令docker ps -a 能看到下面图片中的这段,就是运行成功了,然后可以通过地址来访问管理页面了。

管理页面地址: http://localhost:15672/(服务器上运行的话,将localhost 修改掉),用上面都docker-compose 文件中设置的用户名和密码登录,进来之后就是下面图片中的这个页面,这个就表示rabbitMQ 已经正式启动成功了。
交换器
交换器的具体详细内容,在下面会结合代码详细看下,现在先了解一下基本的概念,RabbitMQ 的交换器官方给出的概念是四种:直连、扇形、主题、头交换器等。
先看下这些交换器之间的区别:
- 直连交换器:最简单的交换器类型,它会根据 Routing Key 直接将消息路由到对应的队列中。
- 扇形交换器:它会将消息发送到所有与之绑定的队列中,不关心 Routing Key。
- 主题交换器:它的 Routing Key 是由用点号分隔的单词组成的字符串,可以根据通配符匹配的规则向多个队列发送消息。
- 头交换器:它会根据消息中的 Header 信息来将消息路由到对应的队列中,与 Routing Key 和队列名字无关。
但是还有一种默认交换(Default Exchange),它是一种比较特殊的交换器,它没有名称,也没有绑定关系。当你使用它时,你只需要将消息发送到一个指定的队列,RabbitMQ 会默认将这个队列绑定到名叫 “”(空字符串)的默认交换器上,并根据队列的名称将消息路由到指定的队列中。这种方式适合在简单的场景下使用,例如只需要将消息发送到一个队列中,不需要进行多个队列之间的路由。
这些交换器中,我们最常用的还是直连、扇形和主题交换器,之后的代码中演示的也只有这三种,头交换器是根据消息中的 Header 信息来将消息路由到对应的队列中,与Routing Key 和队列名字无关,所以不推荐使用。
下面看下声明这些交换器的默认名称:
| Exchange type(交换器类型) | Default pre-declared names(预声明默认名称) |
|---|---|
| Direct exchange(直连交换器) | (Empty string) and amq.direct |
| Fanout exchange(扇形交换器) | amq.fanout |
| Topic exchange(主题交换器) | amq.topic |
| Headers exchange(头信息交换器) | amq.match (and amq.headers in RabbitMQ) |
RabbitMQ的简单使用
下面开始本次的主题,结合springCloud 项目来配置使用RabbitMQ,接下来先配置使用一下rabbitMQ 的几个常用交换器,最后再实现集中特殊的业务场景,比如延时队列之类的。
首先是在cloud 集成RabbitMQ 是有多种方法的,可以自己写原生,然后进行封装,最后在cloud 项目中引入封装项目的starter,还可以引入amqp 的starter,还可以用cloud 体系中的stream 中间件来集成实现。
我们这里先用amqp 来实现一下,首先引入对应的starter。这个项目中提供了一个RabbitTemplate 对象,我们在配置文件中配置好相关的rabbitMQ 连接信息之后,就可以直接使用了。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
- 1
- 2
- 3
- 4
再看下具体的配置信息,注意:rabbitmq 上级就是spring 不用写错地方了。
spring:
rabbitmq:
host: ****
port: 5672
username: ****
password: ****
# 选择虚拟主机名称,用于权限隔离
virtual-host: /
# 开启消息确认机制,能够确保消息被成功发送到RabbitMQ的队列中。
# 在上述配置中,指定为 correlated 表示使用关联模式来确认消息被成功接收到。
# 关联模式指的是一种高性能的消息确认方式,它通过确认标识来确保消息接收成功。
publisher-confirm-type: correlated
# 消息在未被队列收到的情况下返回。
# 表示开启消息退回机制,当消息无法路由到指定的队列时,RabbitMQ会将消息退回给生产者。
publisher-returns: true
# 表示定义了RabbitTemplate的相关配置,
# 这里指定了mandatory为true,表示强制所有发送到RabbitMQ的消息都必须被路由到某个队列中,否则就会退回给生产者。
template:
mandatory: true
# 是定义RabbitMQ监听器相关的配置,这里使用的是异步消息监听器简单模式下的配置项。
listener:
simple:
# 表示消息确认方式,这里指定为手动确认模式,
# 即消费者需要在处理完消息之后手动发送确认消息给RabbitMQ,
# 如果没有发送确认消息,RabbitMQ会默认消息处理失败,从而将该消息重新发送给其他消费者。
acknowledge-mode: manual
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
基本使用-生产者和消费者
接下来我们就是需要使用amqp 提供的RabbitTemplate 来实现生产者的调用,但是需要注意的是不能直接将RabbitTemplate 内容写到业务内容里面,我们这里需要封装一层,这点跟Redis 其实很像。
根据上面的配置,我们这里会实现两个接口,都是RabbitTemplate 提供的,分别是发送方消息确认confirm 方法,队列投递失败通知returnedMessage 方法,如果没有开启手动消息确认的话,就不用重写消息确认的方法,失败通知也是也一样的,没有开启,就不需要重写。
不过这两个方法的具体内容应该怎么写,我们下篇再说,本次只说基础内容,也就是消息的发送。
@Component
public class MQProducer implements RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnCallback {
@Override
public void confirm(CorrelationData correlationData, boolean b, String s) {
}
@Override
public void returnedMessage(Message message, int i, String s, String s1, String s2) {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这里我们需要先注入一个对象RabbitTemplate,这个是什么时候放到IOC 容器中的呢,是amqp 项目中的RabbitAutoConfiguration 对象,这里会用@Bean 将RabbitTemplate 对象注入IOC。(具体的注入流程可以看我的springboot 自动配置文章内容)
注意啊:这里的init 方法是结合上面的发送方消息确认方法和队列投递失败通知方法使用的,没有上面那两个方法的话,是不需要这个的。
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 设置MQConfirmC模式
*/
@PostConstruct
public void init() {
// 用于处理消息发送失败的情况,当消息无法路由到任何一个队列时触发该回调函数。
rabbitTemplate.setReturnCallback(this);
// 用于处理消息是否已经成功发送到 RabbitMQ Broker 上的 Exchange 中,
// 并确认已由 Exchange 送达相应的 Queue 中,从而进行下一步操作。
rabbitTemplate.setConfirmCallback(this);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
然后才是真正的消息生产,通过调用rabbitTemplate.convertAndSend 来发送消息,第一个参数是交换器名称,第二个参数是队列名称,第三个就是消息内容了。
public void send(String mqMessage) {
rabbitTemplate.convertAndSend("my.exchange", "my.routing.key", mqMessage);
}
- 1
- 2
- 3
然后再看消费者,也是一样的尽量不要将MQ 的内容写到业务代码里面,做好代码解耦。这里使用的是@RabbitListener 注解来实现的监听队列。
@Service
public class MQConsumer {
@RabbitListener(queues = "my.queue")
public void handleMessage(String message) {
System.out.println("Received message: " + message);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这个就是一个完成的流程,但是也并不完全是一个完成的流程,如果是企业项目中这么写的话,那就一定死定了,因为完美实现了所有MQ 中要避免的坑。
直连交换器的使用
上述的内容已经简单是实现是生成者还有消费者,但是一个完成的rabbitMQ 是不能只有这些的,从最开始的模型架构的时候,就已经说明了,应该最少还需要交换器Exchange 还有队列Queue,并且还需有对应的绑定和监听关系Routingkey 和BindingKey。
我们使用一下简单的直连交换器,要先要弄清楚什么是直连,交换器和队列之间通过单独的key 值来绑定在一起,但是同时一个直连交换器又可以绑定多个不同key 值的队列,然后直连交换器在发送消息的时候,又通过不同的key 来将消息传递给绑定了的队列,最后由监听了该队列的消费者进行消费。
官方一点的解释,直连交换器就是:如果路由键完全匹配,消息就被投递到相应的队列,是根据消息携带的路由键(routing key)将消息投递给对应绑定键的队列。
构建直连交换器
这里先实现一个直连交换器并绑定队列。创建一个Configuration 配置对象,再声明队列名称和交换器名称的静态常量,这里两个名称我们后面会经常使用,所以可以直接声明静态常量。
之后再用@Bean 将队列和交换器注入IOC,注意我们这里的交换器是DirectExchange,如果是扇型或者主题的话,应该分别对应就是上述提到的FanoutExchange 和TopicExchange,上述的交换器名称中其实就已经说明了。
最后就是将Binding 注入IOC 了,将队列和交换器惊醒绑定,并且这里是将队列的名称当做了BindingKey,这样直连交换器就已经构建完成了。
@Configuration
public class RabbitMQConfig {
public static final String DIRECT_QUEUE_NAME = "directQueue";
public static final String DIRECT_EXCHANGE_NAME = "directExchange";
@Bean
public Queue directQueue() {
return new Queue(DIRECT_QUEUE_NAME);
}
@Bean
public DirectExchange directExchange() {
return new DirectExchange(DIRECT_EXCHANGE_NAME);
}
@Bean
public Binding directBinding() {
return BindingBuilder.bind(directQueue()).to(directExchange()).with(DIRECT_QUEUE_NAME);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
生产者使用
构建完成之后,就是给到之前创建的生产者来配置使用这个交换器了。
在之前的生产者的send 方法中,还是之前的调用方法,不同的是给到交换器的名称和交换器的队列即可。
public void send(String mqMessage) {
// 直连交换器
rabbitTemplate.convertAndSend(RabbitMQConfig.DIRECT_EXCHANGE_NAME,
RabbitMQConfig.DIRECT_QUEUE_NAME, mqMessage);
}
- 1
- 2
- 3
- 4
- 5
消费者使用
然后就是消费者的调用了。也很简单,将queues 的名称换成刚刚配置的名称就行了。
@RabbitListener(queues = RabbitMQConfig.DIRECT_QUEUE_NAME)
public void receiveDirectMessage(String message) {
System.out.println("Received message: " + message);
}
- 1
- 2
- 3
- 4
注意:还有一点需要注意啊,项目中所有声明的队列和交换器,都需要在rabbitMQ 的管理页面进行创建配置,要不然项目启动的时候就会报错。
RabbitMQ的管理页面-创建队列
具体配置队列情况如下图展示,其中最后的Arguments 配置,有兴趣的可以自己再去翻翻。

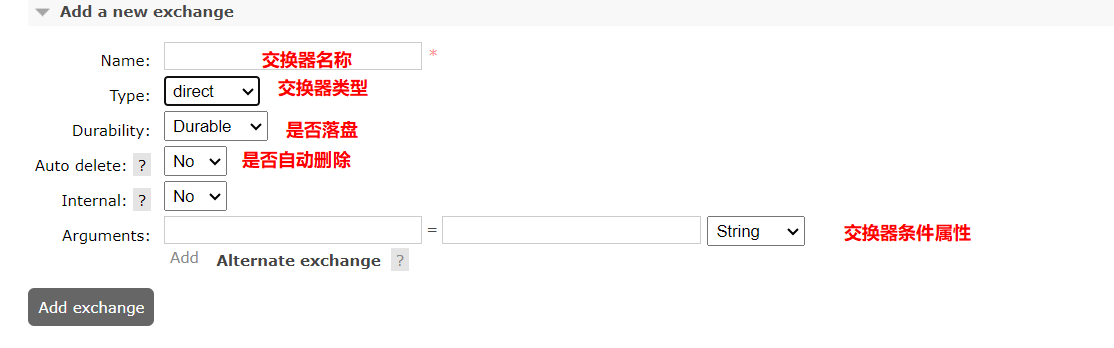
RabbitMQ的管理页面-创建交换器
具体配置交换器情况如下图展示。差不多跟队列是一样的,就是type 类型选择的时候,这里选择的是交换器类型,直连、扇型、主题之类的。
还有一个Internal 选项需要注意,这里如果选择yes,表示该交换器只能通过Binding 来绑定队列,不接受外部的AMQP 发布。也只有在 Virtual Host 中,对内部应用程序是必需的Exchange 类型才应使用此标志,因为它不能被客户端(生产者)直接访问,只能被服务器(处理协议的桥梁)访问。一般情况下,都是NO。
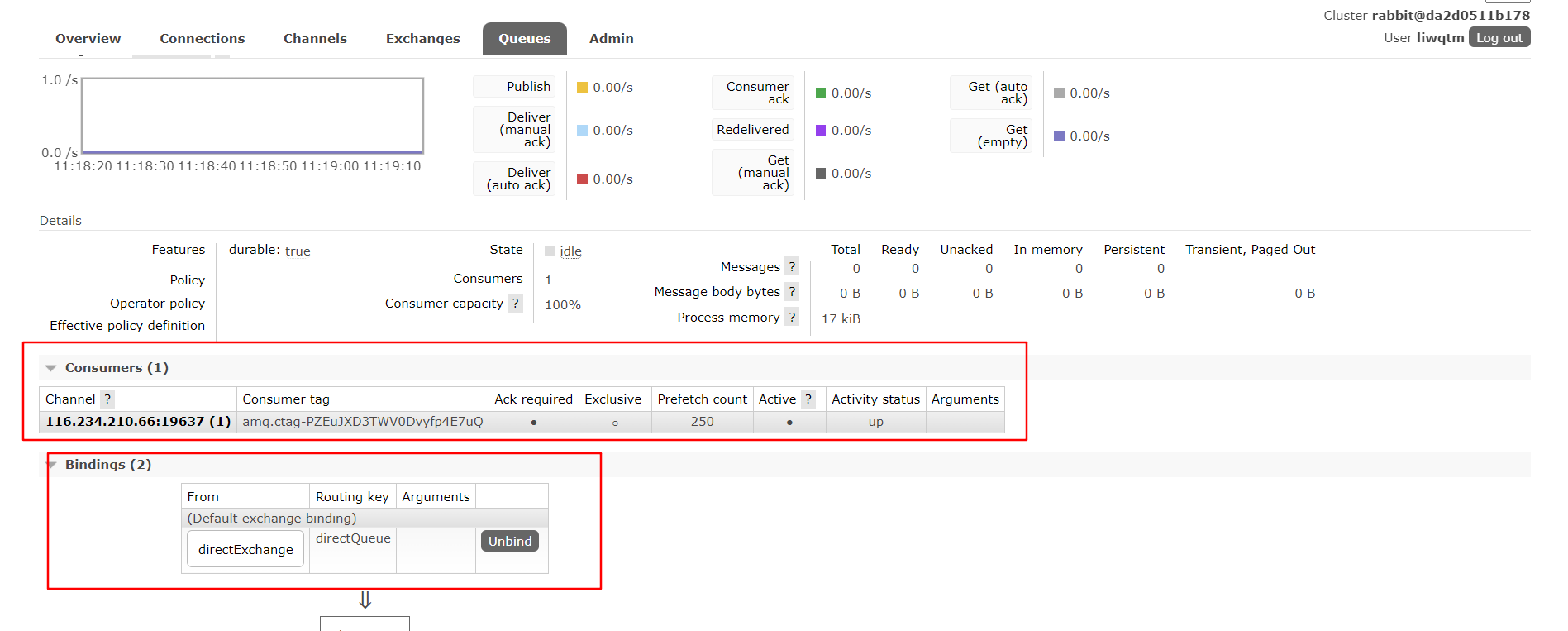
这样再次启动项目就不会有问题了,然后直接去访问你的生产者接口,就会做到调用rabbitMQ 的交换器了,然后就是交换器给到队列,消费者监听到队列之后,就会执行消费消息。
而且启动成功之后,我们还可以去管理页面中看到queue 的信息中有了channel 和binding 的信息配置。
扇型交换器的使用
直连交换器的使用相对来说还是比较简单的,下面我们再使用一下扇型交换器。
还是先说些什么是扇型交换器,其实跟直连交换器类似,就是去除了key 值的限制。只要绑定在扇型交换器上的队列,在扇型交换器收到生产者的消息,就会将消息给到所有这些绑定的队列,然后由各个监听了对应队列的消费者进行消费。
官方一点,扇型交换机(fanout exchange)将消息路由给绑定到它身上的所有队列,而不理会绑定的路由键。如果交换器收到消息,将会广播到所有绑定的队列上。
构建扇型交换器
还是跟直连交换器一样,先构建一个Configuration,这里面用@Bean 注解来将扇型交换器的队列和交换器本身,以及绑定规则一起注入到IOC 里面。
@Configuration
public class FanoutMQConfig {
// 扇型交换器名称
public static final String FANOUT_EXCHANGE_NAME = "fanout.exchange";
// 队列名称
public static final String FANOUT_QUEUE_NAME1 = "fanout.queue1";
public static final String FANOUT_QUEUE_NAME2 = "fanout.queue2";
// 配置扇型交换器
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange(FANOUT_EXCHANGE_NAME);
}
// 配置队列1
@Bean
public Queue fanoutQueue1() {
return new Queue(FANOUT_QUEUE_NAME1);
}
// 配置队列2
@Bean
public Queue fanoutQueue2() {
return new Queue(FANOUT_QUEUE_NAME2);
}
// 将队列1绑定到扇型交换器
@Bean
public Binding fanoutBinding1() {
return BindingBuilder.bind(fanoutQueue1()).to(fanoutExchange());
}
// 将队列2绑定到扇型交换器
@Bean
public Binding fanoutBinding2() {
return BindingBuilder.bind(fanoutQueue2()).to(fanoutExchange());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
还有一点需要注意,我们上面的时候不是创建了一个古典队列嘛,这里我们创建的这两个队列的时候,需要看RabbitMQ 的版本,新版本目前是不需要更换选择的,它们分别是:
- Classic 类型:是RabbitMQ 原生的队列类型,它是一个传统的基于 AMQP 协议的队列,能够保证消息的可靠传递;
- Quorum类型:是RabbitMQ的官方插件Queue Quorum允许在经典队列模式上构建基于多个节点的高可用性队列。Quorum队列提供更简单的 HA 且更加可靠,它采用了Raft Consensus算法,保证消息不会丢失;
- Stream 类型:是RabbitMQ 的官方插件 rabbitmq_stream 的一个部分,它通过将消息以日志形式存储在磁盘上来保证消息的可靠传递。
所以还是跟着上面说的步骤创建队列和交换器就行了,还有记得不要绑定Routingkey。
生产者使用
这里使用的时候需要注意,虽然跟之前的直连交换器非常类似,但是这里是没有传入队列名称的,应该是不指定队列。
public void sendFanout(String mqMessage) {
// 扇型交换器
rabbitTemplate.convertAndSend(FanoutMQConfig.FANOUT_EXCHANGE_NAME, "", mqMessage);
}
- 1
- 2
- 3
- 4
消费者使用
消费者的使用,和之前直连交换器的时候使用的方式是一模一样的,监听对应的队列就行了。
@RabbitListener(queues = FanoutMQConfig.FANOUT_QUEUE_NAME1)
public void consumeMessage1(String message) {
System.out.println("Received fanout message from queue1: " + message);
}
@RabbitListener(queues = FanoutMQConfig.FANOUT_QUEUE_NAME2)
public void consumeMessage2(String message) {
System.out.println("Received fanout message from queue2: " + message);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
小结:其实扇型交换器,可以理解为没有RoutingKey 的直连交换器,只要将队列绑定到了扇型交换器上面之后,所有的队列都会收到扇型交换器的消息。
主题交换器的使用
终于到了本次的最后一个环节了,主题交换器的使用,还是一样的,先了解一下什么是主题交换器。
主题交换器一般叫法是topic 交换器,是一种比较常用的交换器,它也是通过routingKey 来将消息传递给对应的队列的,但是它和直连交换器的区别在于,它支持通配符来实现routingKey。
binding key 中可以存在两种特殊字符 “” 与“#”,用于做模糊匹配,其中 “” 用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
routing key 为一个句点号 “.” 分隔的字符串(我们将被句点号 “. ” 分隔开的每一段独立的字符串称为一个单词),binding key 与 routing key 一样也是句点号 “.” 分隔的字符串。
做个比如吧:假设现在有两个队列,分别是A.E.C.F 和D.E.G.F,那么binding key 为*.E.*.F 那么两个队列都会匹配,如果key 值改为A.E.*.* 则只会匹配到第一个,如果该为#.F 则两个都会匹配。
官方一点,主题交换器:可以使来自不同源头的消息能够到达同一个队列,使用topic 交换器时,可以使用通配符。基于消息的routing key 与绑定到该交换器的队列的pattern 进行匹配,路由消息到一个或多个队列。常用于复杂的发布/订阅场景,当出现多消费者/应用的场景,消费者选择性地接收消息时,应该考虑使用topic exchange。
构建主题交换器
还是和直连交换器、扇型交换器的构建差不多,区别点就是Binding 构建的时候,binding key 赋值的时候,是使用了通配符的。
@Configuration
public class TopicMQConfig {
// 主题交换器名称
public static final String TOPIC_EXCHANGE_NAME = "topic.exchange";
// 队列名称
public static final String TOPIC_QUEUE_NAME1 = "topic.queue1";
public static final String TOPIC_QUEUE_NAME2 = "topic.queue2";
// 配置主题交换器
@Bean
public TopicExchange topicExchange() {
return new TopicExchange(TOPIC_EXCHANGE_NAME);
}
// 配置队列1
@Bean
public Queue topicQueue1() {
return new Queue(TOPIC_QUEUE_NAME1);
}
// 配置队列2
@Bean
public Queue topicQueue2() {
return new Queue(TOPIC_QUEUE_NAME2);
}
// 将队列1绑定到主题交换器上,绑定键值为 topic.message.*
@Bean
public Binding topicBinding1() {
return BindingBuilder.bind(topicQueue1()).to(topicExchange()).with("topic.message.*");
}
// 将队列2绑定到主题交换器上,绑定键值为 topic.#
@Bean
public Binding topicBinding2() {
return BindingBuilder.bind(topicQueue2()).to(topicExchange()).with("topic.#");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
生产者使用
这里的使用还是大差不差的,但是需要注意的时候,routing key 给的时候不是含有通配符的啊,是具体的值,但是也不是具体队列的名称。
public void sendMessage1(String message) {
System.out.println("Sending topic message1: " + message);
rabbitTemplate.convertAndSend(TopicMQConfig.TOPIC_EXCHANGE_NAME, "topic.message.one", message);
}
public void sendMessage2(String message) {
System.out.println("Sending topic message2: " + message);
rabbitTemplate.convertAndSend(TopicMQConfig.TOPIC_EXCHANGE_NAME, "topic.message.two", message);
}
public void sendMessage3(String message) {
System.out.println("Sending topic message3: " + message);
rabbitTemplate.convertAndSend(TopicMQConfig.TOPIC_EXCHANGE_NAME, "topic.test", message);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
消费者使用
这里消费者监听的时候,还是监听那两个创建好的队列,不是生产者配置的routing key。
@RabbitListener(queues = TopicMQConfig.TOPIC_QUEUE_NAME1)
public void consumeMessage3(String message) {
System.out.println("Received topic message from queue1: " + message);
}
@RabbitListener(queues = TopicMQConfig.TOPIC_QUEUE_NAME2)
public void consumeMessage4(String message) {
System.out.println("Received topic message from queue2: " + message);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
交换器使用小结一下
上述内容基本上已经将三种交换器的基本使用说明了,其余的两种交换器,默认交换器和头交换器不常用,这里就不单独写了,而且我还是小瞧rabbitMQ 的复杂程度,单章是写不完了,复杂一点的rabbitMQ 使用下篇在说吧。
下面给出一份交换器的不同使用区别,面试的时候可以总结说一下。
| 类型名称 | 路由规则 |
|---|---|
| Default | 自动命名的直交换机 |
| Direct | 把消息路由到BindingKey和RoutingKey完全匹配的队列中,Routing Key==Binding Key,严格匹配 |
| Fanout | 发送到该交换机的消息都会路由到与该交换机绑定的所有队列上,可以用来做广播 |
| Topic | topic和direct类似,也是将消息发送到RoutingKey和BindingKey相匹配的队列中,只不过可以模糊匹配 |
| Headers | 根据发送的消息内容中的 headers 属性进行匹配,性能差,基本不会使用 |
总结
本来还想一篇解决完的,写到一半我就发现这玩意儿根本就一篇搞不定,这篇就是一些基础的知识了解,还有一些简单的使用MQ 的时候大概率遇到的一些坑,但是代码中应该怎么解决这些问题还没有说。
而且现在也是简单的用amqp 来实现了几种rabbitMQ 的交换器调用,原生代码的调用方式、stream 中间件的调用方式都还没有说。
还有一些结合第三方中间来完善rabbitMQ 的使用也没有说明,比如:Redis 加入后防止重复消费的方案、MongoDB 加入后防止消息丢失等等,目前这篇文章都没有体现。
这些问题,我准备用进阶篇来展示算了,也就是下一篇,本篇的话就定义为RabbitMQ 的基本使用和认识,有兴趣的可以看看我后续的文章,也欢迎提出意见,大家一起进步一起卷嘛。
直交换机 |
| Direct | 把消息路由到BindingKey和RoutingKey完全匹配的队列中,Routing Key==Binding Key,严格匹配 |
| Fanout | 发送到该交换机的消息都会路由到与该交换机绑定的所有队列上,可以用来做广播 |
| Topic | topic和direct类似,也是将消息发送到RoutingKey和BindingKey相匹配的队列中,只不过可以模糊匹配 |
| Headers | 根据发送的消息内容中的 headers 属性进行匹配,性能差,基本不会使用 |
总结
本来还想一篇解决完的,写到一半我就发现这玩意儿根本就一篇搞不定,这篇就是一些基础的知识了解,还有一些简单的使用MQ 的时候大概率遇到的一些坑,但是代码中应该怎么解决这些问题还没有说。
而且现在也是简单的用amqp 来实现了几种rabbitMQ 的交换器调用,原生代码的调用方式、stream 中间件的调用方式都还没有说。
还有一些结合第三方中间来完善rabbitMQ 的使用也没有说明,比如:Redis 加入后防止重复消费的方案、MongoDB 加入后防止消息丢失等等,目前这篇文章都没有体现。
这些问题,我准备用进阶篇来展示算了,也就是下一篇,本篇的话就定义为RabbitMQ 的基本使用和认识,有兴趣的可以看看我后续的文章,也欢迎提出意见,大家一起进步一起卷嘛。

