
- 1error: Cannot delete branch 'xxx' checked out at 'xxxx'
- 2华为OD机试 - 内存资源分配(Java & JS & Python & C)_華為od機試 資源池 伏城
- 3毕业论文 | 基于STM32的MPU6050程序设计(源码)——卡尔曼滤波_stm32 mpu6050卡尔曼滤波姿态解算源码
- 4用 Pytorch 训练一个 Transformer模型
- 5Cuda 编程入门_csdn xiaohu2022
- 6读取JSON字符串中的一维、二维数组数据_json解析一维数组
- 78051 系列单片机内部结构_8051内部结构图
- 8scikit-learn(sklearn)库中的网格搜索(Grid Search)自动化的方法来搜索最佳参数组合_使用10折网格搜索最佳模型参数,打印得到的最佳模型,最佳模型参数,最佳得分
- 9Swift并发的结构化编程_withcheckedcontinuation
- 10NOI金牌冲刺day9_cf1334f题解
小甲鱼学python学习笔记_ccc,myqite,cn
赞
踩
一.序章
1.python缩进问题
if a == 0:
--------
else:
--------
while a = 0:
--------
- 1
- 2
- 3
- 4
- 5
- 6
2.字符串拼接与控制台输入输出
input()可从控制台读入数据,括号内地字符串为输入时的提示,输入结果可通过变量保存
print()控制台输出
s = input()
print(string1 + string1 +str(s)) (s是变量),变量与字符串拼接
- 1
- 2
3.python 每段语法结束后可以不用;
4.python可进行长整数运算
print(1111111111111111*1111111111111111)
- 1
5.python可进行字符串乘积
print("I love\n"*3); #输出3个I love
- 1
6.类型转换
int(),float(),str()
- 1
7.随机数(需导入random包)
import random
secret = random.randint(1,20)
- 1
- 2
8.获取关于类型信息,type()函数与isinstance()函数
isinstance()会根据两个参数返回一个布尔类型的值,True表示类型一致,False表示类型不一致
m = ---
print(type(m))
a = "卓世龙"
print(isinstance(a,str))
- 1
- 2
- 3
- 4
9.算数运算符
+ - * / % ** //
3/2 # value 1.5
3//2 #value 1
5%2 #value 1
3**2 #value 3^2,幂运算
- 1
- 2
- 3
- 4
- 5
幂运算操作符比其左侧的一元操作符优先级高,比其右侧的一元操作符优先级低
10.逻辑运算符
and or not
and:左右操作数同为真才真
or:左右操作数同时为假才假
not:一元操作符,得到一个和操作数相反的布尔类型值
not 0 #False
- 1
11.python的长字符串问题
print("""内容 value:内容 (保留了原格式)
花开 """) 花开
- 1
- 2
12.原始字符串
除了用\进行转义外,可以在字符串前加一个英文字母r
13.复数运算
a = 1 + 1j
b = 2 + 4j
print(a*b)
print(a.real,b.real,a.imag,b.imag)
运行结果:
(-2+6j)
1.0 2.0 1.0 4.0 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
python语言中,复数的虚数部分通过后缀“J"或“j”表示,eg: 12.3+4j , 1.23e-4+5.57e+89j .对于复数 z ,可以用z.real和z.imag分别获得实数和虚数部分。
14.顺序赋值法
a = 2
b=4
a,b = b,a+b #等同于 c = a a = b b = c + b
print(a,b) #,4,6
- 1
- 2
- 3
- 4
二.分支语句
1.elif语句
elif—等同于
else:
if---
- 1
- 2
2.python可有效避免“悬挂else”
python if-else根据缩进配对
3.三元操作符
语法:
a = x
if 条件 else y
small = x if x < y else y
- 1
- 2
- 3
4.断言(assert)
当这个关键字后面的条件为假时,系统会自动崩溃并抛出AssertionError的异常
一般来说,可以用它来在程序中置入检查点,当需要确保程序中的某个条件一定为真才能工作时,assert关键字就非常有用了。
#######################################
三.循环语句
1.while循环
while 条件:
循环体
- 1
- 2
2.for循环与range()
try = "Python"
for each in try:
print(each,end = '') #Python
- 1
- 2
- 3
内建函数range()
range([start,] stop[,step = 1])
for i in range(5):
print(i) #0 1 2 3 4
for i in range(2,9)
print(i) #2,3,4,5,6,7,8
for i in range(1,10,2)
print(i) # 1,3,5,7,9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.break语句与continue语句
break 跳出当前循环
for i in range(1,10,2)
if i == 1:
break
print(i) # ""
- 1
- 2
- 3
- 4
continue 跳出当前迭代
for i in range(1,10,2)
if i == 1:
continue
print(i) # 3,5,7,9
- 1
- 2
- 3
- 4
########################################
四.列表、元素和字符串
1.列表
创建列表
number = [1,2,3,4,5] 或
mix = [1,2,"卓世龙",3,14,[1,2,3]] #鱼龙混杂的列表
empty = [] #如果实在想不到要往列表里塞什么数据时,可以先创建一个空列表
- 1
- 2
- 3
向列表添加元素(append()方法)
number = [1,2,3,4,5]
number.append(6) #append()方法向表尾添加单个元素
number.extend([7,8]) #extend()方法事实上是用一个列表来拓展另一个列表,所以参数应为列表
- 1
- 2
- 3
向列表中插入数据
number.insert(1,0) #第一个参数表示在列表中的位置,第二个参数表示插入的值,凡是索引,python都是从0开始
- 1
获取列表中元素
number[i] #获取列表第i+1个元素,不可越界
- 1
删除列表数据
name = ["鸡蛋","鸭蛋","李狗蛋"]
name.remove("鸡蛋") #用remove()删除元素时,并不需要知道这个元素在列表中的具体位置,只需该元素存在列表中
del name[1] #del是一个语句,不是一个列表方法,所以不必再后方加()
del name #del加列表名可删除整个表
- 1
- 2
- 3
- 4
弹出列表元素
name = [1,2,3,4]
name.pop() #1,pop()方法直接弹出列表中的最后一个元素
name #[2,3,4]
name.pop(1) #弹出相应索引位置的元素
- 1
- 2
- 3
- 4
列表分片 #可实现一次性获取多个元素
name = ["鸡蛋","鸭蛋","鸵鸟蛋","鹌鹑蛋"]
name[0:2] #["鸡蛋","鸭蛋"] (:左边为开始位置,右边为结束位置,结束位置上的元素是不包含的)
name[:1] #没有开始位置,默认开始位置为0
name[1:] #没有结束位置,默认结束位置为列表末尾
name[:] #整个列表的拷贝
list = [1,2,3,4,5,6,7,8,9]
list1[0:9:2] #[1,3,5,7,9] 第三个参数代表步长
list[::-1] #[9,8,7,6,5,4,3,2,1] 相当于复制一个反转列表
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
操作符
>,<号比较
list1 = [123]
list2 = [234]
list1 > list2 #False
list2 > list1 #True
list1 = [123,567]
list2 = [234,123]
list1 > list2 #False
#当列表包含多个元素时,默认是从第一个元素开始比较,只要有一个PK赢了,就算整个列表赢了
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
*号操作
list1 = [I Love You]
list1*3 # [I Love You,I Love You,I Love You]
- 1
- 2
in 和 not in 操作符
list1 = [1,2,3,[4,5]]
1 in list1 # True
5 not in list1 #False in 和not in 只能判断一个层次的成员关系
- 1
- 2
- 3
访问列表中的列表
list1 = [1,2,3,[4,5]]
list1[3][1] #类似C语言访问二维数组
- 1
- 2
2.列表的伙伴
count()
计算它的参数在列表中出现的次数
list1 = [1,2,1,1,2,3]
list1.count(1) #3
- 1
- 2
index()
返回它的参数在列表中的位置,index()还有两个参数,可限定查找范围
list1.index(1,start,stop)
- 1
reverse()
将整个列表原地翻转(逆置)
sort()
对列表进行排序,由小到大排,sort(reverse = True) 从大到小排
3.元组,被约束的“列表” #元组是不可改变的,创建元组用的是小括号
创建元组
tuple = (1,2,3,4) #,是元组的关键,()不带也可识别
8*(8) # 64
8*(8,) #(8,8,8,8,8,8,8,8)
tuple1 = () #创建空元组
- 1
- 2
- 3
- 4
访问元组
tuple[1]
tuple[2:] #类似列表
tuple[:]
- 1
- 2
- 3
特殊的“修改”元组
tuple[1] = 1 #程序会报错,不能直接修改
tuple = tuple[0] + 1 + tuple[2:] #间接改变
- 1
- 2
删除元组
del tuple #删除整个元组
- 1
关系操作符,逻辑操作符,成员关系操作符in 和 not in 也可应用在元组上
4.字符串
元组的知识完全可以用在字符串上,字符串和元组一样不可更改
str = "I love you"
str[:6] #I love
str[2] #l
str = str[:6] + "---" + str[6:]
- 1
- 2
- 3
- 4
5.字符串的内置方法
capitalize() #把字符串第一个字符改为大写
casefold() #将字符串所有字母改为小写
center(width) #将字符串居中,并使用空格填充至长度width的新字符串
count(sub[,start[,end]]) #返回sub在字符串中出现的次数,start 和 end 参数表示范围
encode(encoding = 'utf-8',errors = 'strict') #以encoding指定的编码格式对字符串进行编码
endswith(sub[,start[,end]]) #检查字符串是否以sub子字符串结束,如果是返回True,否则返回False。start 和 end 表示参数范围
。。。。。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
6.字符串常用方法
casefold()
count()
find()
查找某个子字符串在该字符串的位置
str = "abcdefg"
str.find("bc") #1 找到返回第一个字符的索引
str.find("ghi") #-1 找不到返回-1
- 1
- 2
- 3
join(sub)
join(sub)是以字符串作为分隔符,插入到sub字符串中所有的字符之间
'x'.join("Test") # "Txexsxt"
- 1
replace(old,new[,count])
替换指定字符串
str = "I love you"
str.replace("you","me") # I love me
- 1
- 2
附:程序员喜欢用join()连接字符串,因为当使用连接符号"+"去拼接大量字符串是低效的,因为’+'会引起一些内存复制和垃圾回收操作
7.格式化
format 方法
format()方法接受位置参数和关键字参数,二者均传递到一个教replacement字段,这个字段在字符串内由大括号({})表示
位置参数
print("{0} love {1}.{2}".format("I","zhuoshilong qq","com")) # I love zhuoshilong qq.com
- 1
关键字参数
print("{a} love {b}.{c}".format(a = "I",b = "zhuoshilong qq",c = "com")) # I love zhuoshilong qq.com
{a},{b},{c}相当于三个标签,format()将参数中等值的字符串替换进去,这就是关键字参数,也可综合位置参数一起使用,但这样位置参数必须在关键字参数之前,否则会报错
- 1
- 2
格式化操作符 %
当%出现在字符中时,它表示的是格式化操作符

i = "%c" % 97
print(i)
i ='%c%c%c%c%c'%(70,105,115,104,67)
print(i)
i = '%d转化为八进制是:%o'%(123,123)
print(i)
i = '%f用科学计数法表示为:%e' %(149500000,149500000)
print(i)
输出结果:
a
FishC
123转化为八进制是:173
149500000.000000用科学计数法表示为:1.495000e+08
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Python还提供了格式化操作符的辅助指令

i = '%5.1f'%27.182 print(i) i = '%.2e'%27.182 print(i) i = '%10d'%5 print(i) i = '%-10d'%5 print(i) i = '%010d'%5 print(i) i = '%#X'%100 print(i) 输出结果: 27.2 2.72e+01 5 5 0000000005 0X64

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Python转义字符及含义
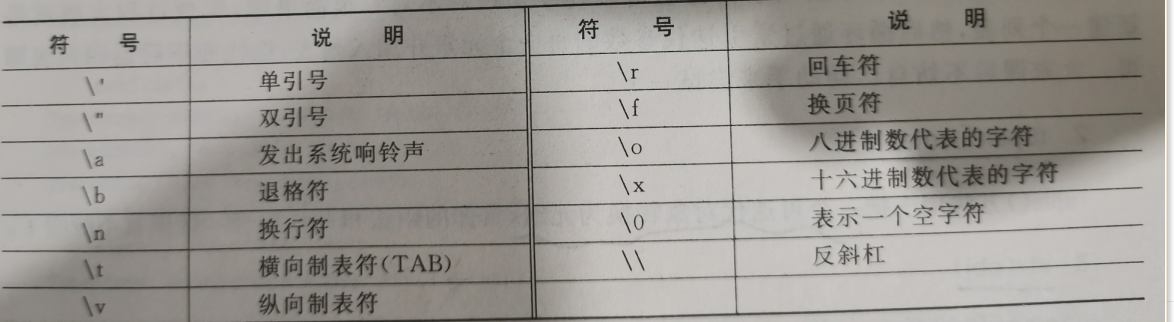
################################################
五.函数
#函数就是把代码打包成不同形状的乐高积木,以便可以发挥想象力进行随意拼装和反复使用。此前接触的BIF就是Python帮我们封装好的函数
1.创建调用函数
Python创建调用函数用关键字 def,函数名后面的小括号必不可少
def firstFunction():
print("这是我的第一个Python函数!")
print("在这里,我要感谢学校,感谢党,感谢国家")
- 1
- 2
- 3
2.调用函数
for i in range(3):
firstFunction() #打印这几句话三遍
- 1
- 2
3.函数传参(重难点)
def rank(a,b):
return a+b
print(rank(1,2)) #3
- 1
- 2
- 3
关键字参数
普通参数叫位置参数,通常在调用一个函数时,粗心的程序员容易搞错位置参数的位置,以至于函数无法按照预期实现。而使用关键字参数,就可以很简单解决这个问题,详见如下
def saysomething(name,words):
print(name + '->' + words)
saysomething("zsl","编程改变世界") #zsl->编程改变世界
saysomething("编程改变世界","zsl") #编程改变世界->zsl
saysomething(words = "编程改变世界",name = "zsl") #zsl->编程改变世界
- 1
- 2
- 3
- 4
- 5
- 6
- 7
默认参数
在函数定义时赋予了默认值的参数
def saysomething(name = "zsl",words = "编程改变世界"):
print(name + '->' + words)
saysomething() #zsl->编程改变世界
saysomething("1","2") #1->2
- 1
- 2
- 3
- 4
使用默认参数时,就可以不带参数去调用函数
4.函数文档
def exchange(dollar):
"""美元->人民币,汇率暂定为7"""
return dollar * 7
# 在函数开头写下的字符串是不会被打印出来的,但它会作为函数一部分储存起来,这个称为函数文档字符串,可以使别人更好理解你的函数,利于协同开发
- 1
- 2
- 3
- 4
5.收集参数
其实它大多时候又称“可变参数”
def test(*event):
print("有%d个参数" % len(event))
print("第二个参数为:",event[1],"第四个参数为",event[3])
test(1,2,3,4,5) #有5个参数 #第二个参数为: 2 第三个参数为 4
- 1
- 2
- 3
- 4
Python就是把标志为收集参数的参数们打包为一个元组,但是如果收集参数后面还要指定其他参数,在调用函数时就应该采用关键字参数来指定,否则Python就会把所有参数都列入收集参数的范围,程序会报错。
def test(*event,thing):
print("收集参数是:",event)
print("位置参数为:",thing)
test(1,2,3,4,5,6)
- 1
- 2
- 3
- 4
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nYK1l85v-1611326858169)(C:\Users\86182\AppData\Roaming\Typora\typora-user-images\image-20200927162556093.png)]
应修改为(使用关键字参数或默认参数)
def test(*event,thing):
print("收集参数是:",event)
print("位置参数为:",thing)
test(1,2,3,4,5,thing = 6)
- 1
- 2
- 3
- 4
或者
def test(*event,thing = "8"):
print("收集参数是:",event)
print("位置参数为:",thing)
test(1,2,3,4,5,6)
- 1
- 2
- 3
- 4
解包(将列表传入test参数的收集参数)
def test(*event,thing = "8"):
print("收集参数是:",event)
print("位置参数为:",thing)
table = [1,2,3,4,5,6]
test(table) #收集参数是: ([1, 2, 3, 4, 5, 6],)
test(*table) #收集参数是: (1, 2, 3, 4, 5, 6)
- 1
- 2
- 3
- 4
- 5
- 6
6.函数返回值
Python函数严格来说只有函数,没有过程
def event():
print("hello")
print(event()) #hello #None
- 1
- 2
- 3
当不写return时,Python会默认为函数是return None的,所以说Python所有函数都有返回值
7.变量作用域(局部变量与全局变量)
局部变量
def discounts(price,rate):
final_price = price * rate
return final_price
old_price = float(input("请输入原价:"))
rate = float(input("请输入折扣率:"))
new_price = discounts(old_price,rate)
print("打折后的价格为:",new_price)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中final_price 为函数内的局部变量
假如
print("打印局部变量final_price的值:",final_price)
- 1
编译无法通过
总结:在函数内定义的参数以及变量,都称为局部变量,出了这个函数,这些变量都是无效的。事实上的原理是,python在运行函数的时候,利用栈(Stack)进行存储,当执行完函数后,函数中所有的数据被自动删除。所以在函数外边是无法访问到函数内部的局部变量的。
全局变量
程序中old_price、new_price、rate都是在函数外边定义的,他们都是全局变量,拥有更大的作用域
print("打印全局变量old_price的值:",old_price)
- 1
这是合法的
全局变量在函数内存在伪修改
def discounts(price,rate):
final_price = price * rate
old_price = 50 #试图在函数内修改全局变量
print("在局部变量内修改后的old_price值为:",old_price)
return final_price
old_price = float(input("请输入原价:"))
rate = float(input("请输入折扣率:"))
new_price = discounts(old_pricex,rate)
print("打折后的价格为:",new_price)
print("打印全局变量old_price的值:",old_price)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果如下:
请输入原价:190
请输入折扣率:110
在局部变量内修改后的old_price值为: 50
打折后的价格为: 20900.0
打印全局变量old_price的值: 190.0
如果在函数内部试图修改全局变量,那么Python会创建一个新的局部变量鳞似替代(名字和全局变量相同),但真正的全局变量是不改变的。
global关键字
强行在函数内修改全局变量可通过global关键字实现,在函数内强调它是全局变量
global old_price
old_price = 50 #试图在函数内修改全局变量
- 1
- 2
8.内嵌函数
def fun1():
def fun2():
print("3")
fun1()
- 1
- 2
- 3
- 4
即允许在一个函数内创建另一个函数
fun2()函数的作用域在fun1内,在fun1()函数内可随意调用fun2(),在fun1()外调用则报错
9.闭包
闭包(closure)是函数式编程的一个重要语法结构,函数式编程是一种编程范式,著名的函数式编程语言就是LISP语言
在Python中,如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包
def funX(x):
def funY(y):
return x * y
return funY #返回的是一个函数
i =funX(8)
print(i(5)) #40
- 1
- 2
- 3
- 4
- 5
- 6
在闭包中,外部函数的局部变量对应内部函数的局部变量类似于之前全局变量与局部变量的关系。在内部函数中,你只能对外部函数的局部变量进行访问,但不能进行修改。
def funX():
x = 5
def funY():
x *= x
return x
return funY
- 1
- 2
- 3
- 4
- 5
- 6
报错,因为Python在认为内部函数的x是局部变量时,外部的x就被屏蔽了起来,所以执行x *= x时,在右边根本找不到局部变量x的值,因此报错。
在Python3之前对这类问题并没有什么好的解决方法,只能间接通过容器类型来存放,因为容器类型不是放在栈里,所以不会被“屏蔽”掉 (之前说过的 字符串,列表,元组,这些啥都可以往里面放的就是容器类型。
def funX():
x = [5]
def funY():
x[0] *= x[0]
return x[0]
return funY
print(funX()()) #25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
nonlocal关键字
Python3中增添了nonlocal关键字,使用方式和global一样
def funX():
x = 5
def funY():
nonlocal x
x *= x
return x
return funY
print(funX()())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
拓展资料:游戏中的移动角色:闭包在实际开发中的作用
10.lambda表达式
lambda表达式示例
Python允许使用lambda关键字来创建匿名函数
def add(x,y):
return x + y
add(3,4)
#转换为lambda表达式
g = lambda x,y:x + y
g(3,4)
- 1
- 2
- 3
- 4
- 5
- 6
lambda表达式的作用
(1)Python写一些执行脚本时,使用lambda可以省下定义函数的过程,比如说只是需要写个简单的脚本来管理服务器时,就不需要专门定义一个函数然后再写调用,使用lambda就可以使代码更加精简。
(2)对于一些比较抽象并且整个程序执行下来只需要调用一两次的函数,有时候给函数起名字也是比较麻烦的,使用lambda就不需要考虑命名的问题了。
(3)简化代码的可读性,由于阅读普通函数经常要跳到开头def定义的位置,使用lambda函数可以省去这样的步骤。
filter()
这一个内建函数是一个过滤器,filter有两个参数,第一个参数可以是一个函数也可以是None,如果是一个函数的话,则将第二个可迭代数据里的每一个元素作为函数的参数进行计算,把返回True的值筛选出来;如果第一个参数为None,则直接把第二个参数中为True的值筛选出来。
temp = filter(None,(True,False,1,0))
print(list(temp)) #[True, 1]
def odd(x):
return x % 2
temp = filter(odd,range(0,10))
print(list(temp)) #[1, 3, 5, 7, 9]
#用lambda表示
temp = filter(lambda x:x%2,range(0,10)) #list() 方法用于将filter函数转换为列表。
print(list(temp)) #[1, 3, 5, 7, 9]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
map()
在编程领域,map一般作“映射”来解释。map()这个内置函数也有两个参数,仍然是一个函数和一个可迭代序列,将序列的每一个元素作为函数的参数进行运算加工,指导课迭代序列每个元素都加工完毕,返回所有加工后的元素构成的新序列。
temp = map(lambda x:x * 2,range(0,5))
print(list(temp)) #[0, 2, 4, 6, 8]
- 1
- 2
11.递归
六.字典
引例
字典是由多个键及其对应的值共同构成,每一对键值的组合称为项
zidian = {"卓世龙":"try everything","成龙":"功夫熊猫3","李小龙":"双截棍"}
print(zidian)
print("卓世龙的口号是:",zidian["卓世龙"])
运行结果:
{'卓世龙': 'try everything', '成龙': '功夫熊猫3', '李小龙': '双截棍'}
卓世龙的口号是: try everything
- 1
- 2
- 3
- 4
- 5
- 6
- 7
字典跟序列不同,序列讲究顺序,字典讲究映射,不讲顺序
字典的键必须是独一无二的(可以自己尝试,会有奇特结果),而值可以取任何数据类型,但必须是不可变的(如字符串,数或元组)
字典的创建
1.声明一个空字典,直接用大括号表示
empty = {}
zidian = {"1":"2","3":"4"}
- 1
- 2
2.也可用dict()函数来创建字典
dict1 = dict((("A",1),("B",2),("C",3))) #或 dict1 = dict([("A",1),("B",2),("C",3)])
print(dict1)
运行结果:
{'A': 1, 'B': 2, 'C': 3}
- 1
- 2
- 3
- 4
- 5
dict()函数的参数可以是一个序列(但不能是多个),所以要打包成一个元组序列(列表也可以)
3.当然,还可以通过提供具有映射关系的参数来创建字典:
dict1 = dict(A = 1,B = 2,C = 3)
print(dict1) #{'A': 1, 'B': 2, 'C': 3}
- 1
- 2
这里要注意键的位置不能加上字符串的引号,否则会报错
4.直接对字典的键赋值,如果键存在,则改写键对应的值,如果不存在,则创建一个新的键并赋值:
dict1 = {"A":1,"B":2}
dict1["C"] = 3
print(dict1)
dict1["A"] = 520
print(dict1)
运行结果:
{'A': 1, 'B': 2, 'C': 3}
{'A': 520, 'B': 2, 'C': 3}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
体会创建字典的方法
a = dict(A = 1,B = 2, C = 3)
b = {"A":1,"B":2,"C":3}
c = dict(zip(["A","B","C"],[1,2,3]))
d = dict((("A",1),("B",2),("C",3)))
- 1
- 2
- 3
- 4
字典内置方法
fromkeys()
fromkeys()方法用于创建并返回一个新的字典,它有两个参数,第一个参数是字典的键,第二个参数是可选的,是传入键对应的值,如果不提供,默认为None
注意:fromkeys 方法只用来创建新字典,不负责保存。当通过一个字典来调用 fromkeys 方法时,如果需要后续使用一定记得给他复制给其他的变量。
dict1 = {}
dict2 = dict1.fromkeys((1,2,3))
print(dict1)
print(dict2)
dict2 = dict1.fromkeys((1,2,3),(1,2,3))
print(dict2)
dict2 = dict1.fromkeys((1,2,3),("number"))
print(dict2)
运行结果:
{}
{1: None, 2: None, 3: None}
{1: (1, 2, 3), 2: (1, 2, 3), 3: (1, 2, 3)}
{1: 'number', 2: 'number', 3: 'number'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
keys(),values()items()
keys()用于返回字典中的键,values()用于返回字典中所有的值,那么items()当然就是返回字典中所有的键值对(也就是项)啦
dict1 = {1:"one",2:"two",3:"three",4:"four",5:"five"}
print(dict1.keys()) #返回字典中的键
print(dict1.values()) #返回字典中的值
print(dict1.items()) #返回字典中的键值对
运行结果:
dict_keys([1, 2, 3, 4, 5])
dict_values(['one', 'two', 'three', 'four', 'five'])
dict_items([(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four'), (5, 'five')])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
get()
get()方法提供了更宽松的方式去访问字典项,当键不存在时,get()方法并不会报错,只是默默的返回一个None值,表示什么也没得到,如果希望找不到数据时返回特定的值,可以在第二个参数中设置默认返回值
dict1 = {1:"one",2:"two",3:"three",4:"four",5:"five"}
print(dict1.get(1)) #one
print(dict1.get(9)) #None
print(dict1.get(9,"I can't find it")) #I can't find it
- 1
- 2
- 3
- 4
也可采用成员资格操作符(in 或 not in)来判断
在字典中检查成员的资格比序列更加高效,当数据规模相当大的时候,两者的差距会很明显(因为字典是采用哈希方法一对一找到成员,而序列是采用迭代的方式逐个比较),这里查找的是键而不是值,但是在序列中查找的是元素的值而不是索引
成员资格操作符
print(1 in dict1,22 in dict1,33 not in dict1) #True False True
- 1
clear()
清空一个字典可用clear()
dict1 = {1:"one",2:"two",3:"three",4:"four",5:"five"}
dict2 = dict1.clear()
print(dict1)
print(dict2)
运行结果:
{}
None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
注意,最好不要使用变量名赋值空字典的方式清空字典,这样存在风险
b = {1:"one",2:"two",3:"three",4:"four",5:"five"}
a = b
b = {}
print(a) #{1: 'one', 2: 'two', 3: 'three', 4: 'four', 5: 'five'}
- 1
- 2
- 3
- 4
我们会发现字典并没有被真的清空,只是b指向了新的字典而已,这样会留下安全隐患,比如信息被窃取
copy()
copy()方法是复制字典(两个内容完全相同,但id不同的字典,互不影响
b = {1:"one",2:"two",3:"three",4:"four",5:"five"}
a = b.copy()
print(id(a),id(b)) #2616333125376 2616333125312
- 1
- 2
- 3
pop()和popitem()
pop()是给定键弹出相应的值,而popitem()是弹出一个项
b = {1:"one",2:"two",3:"three",4:"four",5:"five"}
print(b.pop(1))
print(b.popitem())
输出结果:
one
(5, 'five')
- 1
- 2
- 3
- 4
- 5
- 6
update()
update()可以用来更新字典
students = {"小明":"中南","小红":"清华","小李":"北大"}
students.update(小李 = "浙大")
print(students) #{'小明': '中南', '小红': '清华', '小李': '浙大'}
- 1
- 2
- 3
注意键值在update()中不带参数
收集参数用字典形式打包
两个**的收集参数表示将参数打包成字典的形式,当然,有打包就肯定有解包
def test(**params):
print("有%d个参数" %len(params))
print("它们分别是:",params)
test(a=1,b=2,c=3,d=4,e=5)
a = {"小明":"中南","小红":"清华","小李":"北大"}
test(**a) #解包
输出结果为:
有5个参数
它们分别是: {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
有3个参数
它们分别是: {'小明': '中南', '小红': '清华', '小李': '北大'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注意第四行的格式问题,可自己运行修改尝试
七.集合(在我的世界里,你就是唯一)
初识集合
与字典类似,集合的定义也和大括号有关,且集合会自动帮我们把重复的数据清理掉
set1 = {1,2,3,2,2}
set2 = {}
print(type(set1))
print(type(set2))
print(set1)
运行结果:
<class 'set'>
<class 'dict'>
{1, 2, 3}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在Python3里,如果用大括号括起一堆数字但并没有体现映射关系,那么Python就会认为这堆玩意儿是集合
创建集合
直接用{}括起创建或用set()创建
set1 = {1,2,3,4}
set2 = set([1,2,3,4])
print(set1 == set2) #True
- 1
- 2
- 3
集合的应用
去除列表[1,2,3,4,0,4,3,2,1]中的重复元素
list1 = {1,2,3,4,0,4,3,2,1}
list1 = list(set(list1))
print(list1) #[0, 1, 2, 3, 4]
- 1
- 2
- 3
注意,set()创造了的集合内部是无序的,所以再调用list()将无序的集合转换成列表就不能保证原来列表的顺序了
访问集合
迭代访问
由于集合中的元素是无序的,所以不能像序列那样用下标来访问,但是可以用迭代把集合中的数据一个个读取出来
set1 = {1,2,3,4,5,4,3,2,1,0}
for each in set1:
print(each,end=" ") #元素间以空格分隔
- 1
- 2
- 3
in 或in not判定
0 in set1
1 not in set1
- 1
- 2
添加删除元素
add()可为集合添加元素,remove()可删除集合已知元素
set1 = {1,2}
set1.add("CSU")
set1.remove(2)
print(set1) #{1, 'CSU'}
- 1
- 2
- 3
- 4
不可变集合
有时我们希望集合中的数据比较稳定,即像元组一样不能随意地增加或删除集合中的元素。那么我们可以定义不可变集合,可使用frozenset()函数(frozen(冰冻))
set1 = frozenset({12,2223,2})
- 1
之后再修改此集合会报错
八.文件存储
open()函数
在Python中使用open()这个函数打开文件并返回文件对象
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
完整的语法如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
- 1
open()有很多参数,作为初学者,目前我们只需要关注第一个和第二个参数即可。第一个参数是文件路径(相对或绝对),第二个参数指定文件的打开模式
-
file: 必需,文件路径(相对或者绝对路径)。
-
mode: 可选,文件打开模式
-
buffering: 设置缓冲
-
encoding: 一般使用utf8
-
errors: 报错级别
-
newline: 区分换行符
-
closefd: 传入的file参数类型
-
opener:
mode 参数有:
模式 描述 t 文本模式 (默认)。 x 写模式,新建一个文件,如果该文件已存在则会报错。 b 二进制模式。 + 打开一个文件进行更新(可读可写)。 U 通用换行模式(不推荐)。 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 r+ 打开一个文件用于读写。文件指针将会放在文件的开头。 rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
默认为文本模式,如果要以二进制模式打开,加上 b 。
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close()关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next()返回文件下一行。 |
| 6 | [file.read(size])从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | [file.readline(size])读取整行,包括 “\n” 字符。 |
| 8 | [file.readlines(sizeint])读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 |
| 9 | [file.seek(offset, whence])设置文件当前位置 |
| 10 | file.tell()返回文件当前位置。 |
| 11 | [file.truncate(size])截取文件,截取的字节通过size指定,默认为当前文件位置。 |
| 12 | file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
文件的关闭
使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。因为Python可能会缓存你写入的数据,如果中途发生类似断电的之类的事故,那些缓存的数据根本不会写入到文件中。所以要养成使用完文件后立即关闭的好习惯。

f = open("experience.txt") #默认为只读模式
f.seek(0,0)
print(f.read())
f.close() #ssjdfjwk jdkjwkfj jskdjfkwjfksjd
- 1
- 2
- 3
- 4
如果含有中文,可能需要 encoding='UTF-8’参数来修正
f = open("experience.txt", encoding='UTF-8') #默认为只读模式
f.seek(0,0)
print(f.read())
f.close()
输出结果:
ssjdfjwk jdkjwkfj jskdjfkwjfksjd
卓世龙是个好孩子
- 1
- 2
- 3
- 4
- 5
- 6
- 7
文件的读取与定位

文件的读取方法很多,可以采用文件对象的read()和readline()方法,也可以直接list(f)或者直接使用迭代来读取
read()
read()是按字节为单位来读取,如果不设置参数,那么会全部读取出来,文件指针指向文件末尾
tell()
tell方法可以告诉你当前文件指针的位置
f = open("experience.txt", encoding='UTF-8') #默认为只读模式
print(f.tell())
- 1
- 2
seek()
seek()可以调整文件指针的位置
seek(offect,from)有两个参数,表示从from(0代表起始位置,1代表当前位置,2代表文件末尾)偏移offect个字节
因此使用seek(0,0)可将文件指针设到文件起始位置
f = open("experience.txt", encoding='UTF-8') #默认为只读模式
f.seek(0,0)
print(f.tell()) # 0
- 1
- 2
- 3
readline()
readline()方法用于在文件中读取一整行,就是从文件指针的位置向后读取,知道遇到换行符(\n)结束
f = open("experience.txt", encoding='UTF-8') #默认为只读模式
f.seek(0,0)
print(f.readline())
f.close() # ssjdfjwk jdkjwkfj jskdjfkwjfk是sjd
- 1
- 2
- 3
- 4
readlines()
f = open("experience.txt", encoding='UTF-8') #默认为只读模式
f.seek(0,0)
print(f.readlines())
f.close()
输出结果:
['ssjdfjwk jdkjwkfj jskdjfkwjfk是sjd\n', '卓世龙是个好孩子']
- 1
- 2
- 3
- 4
- 5
- 6
文件的写入
若果需要写入文件,需要确保之前打开的模式为’w’或’a’,否则会出错
使用write()写入内容
f = open("experience.txt", mode = "w",encoding='UTF-8')
f.write("I love you,but you will never know")
f.close()
f = open("experience.txt",encoding='UTF-8')
print(f.read())
输出结果:
I love you,but you will never know
- 1
- 2
- 3
- 4
- 5
- 6
- 7

注意:使用’w’写入文件,此前的文件内容会被全部删除
需要再次读取时要先关闭文件保存内容,再通过读取模式打开
文件系统(模块)
在前面的几个章节中我们脚本上是用 python 解释器来编程,如果你从 Python 解释器退出再进入,那么你定义的所有的方法和变量就都消失了。
为此 Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
import sys
- 1
OS模块
对于文件系统的访问,Python一般是通过OS模块来实现的,有了OS模块,不需要关心什么操作系统下使用什么模块,OS模块会帮你选择正确的模块并调用

getcwd()
有时我们需要获得应用程序当前的工作目录(如保存临时文件),可以通过使用getcwd()获得
import os
i = os.getcwd()
print(i) #E:\Python project
- 1
- 2
- 3
chdir(path)
chdir()可以改变当前工作目录,比如切到D盘
import os
os.chdir("D:\\")
i = os.getcwd()
print(i) #D:\
- 1
- 2
- 3
- 4
listdir(path = '. ')
有时候我们需要知道当前目录下有哪些文件和子目录,那么listdir()函数可以帮我们列举出来。path参数用于指定列举的目录,默认值为’.’,代表根目录,也可使用’…'代表上一级目录
import os
i = os.listdir("..")
print(i)
- 1
- 2
- 3
mkdir(path)
mkdir()函数用于创建文件夹,如果文件夹存在,则抛出FileExistsError异常
import os
os.mkdir("test1")
i = os.listdir()
print(i)
输出结果:
['.idea', 'experience.txt', 'Hello World.py', 'main.py', 'resouse', 'sendEmials.py', 'test.py', 'test1', 'venv', '参赛指南.pdf', '科协报名表(最终版).xlsx', '邮箱号.xlsx']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
makedirs(path)
makedirs()函数可用来创建多级目录
os.makedirs(r".\a\b\c")
- 1
remove(path)、rmdir(path)、removedirs(path)
remove()用于删除指定文件,注意是删除文件,不是删除目录。如果要删除目录,则用rmdir()函数,如果要删除多层目录,则用removedirs()函数
import os
os.removedirs(r".\a\b\c")
os.remove("experience.txt")
os.rmdir("test1")
- 1
- 2
- 3
- 4
rename(old,new)
rename()函数重命名文件或文件夹
import os
os.rename("大一萌新记","大二老油条")
- 1
- 2
system(command)
几乎每个操作系统都会提供一些小工具,system()函数用于使用这些小工具
import os
os.system("calc") #calc是windows自带的计算器,其他工具可以百度
- 1
- 2
walk(top)
该函数的作用是遍历top参数指定路径下的所有子目录,并将结果返回一个三元组(路径,[包含目录],[包含文件])
import os
print(list(os.walk(".idea")))
输出结果:
[('.idea', ['inspectionProfiles'], ['.gitignore', 'misc.xml', 'modules.xml', 'Python project.iml', 'workspace.xml']), ('.idea\\inspectionProfiles', [], ['profiles_settings.xml'])]
- 1
- 2
- 3
- 4
附录
path模块也提供了一些很实用的定义,分别是:os.curdir表示当前目录;os.pardir表示上一级目录("…"); os.set表示路径的分隔符,比如Windows系统下为’\\’,Linux下为’/’; os.linesep表示当前平台使用的行终止符。os.name表示当前使用的操作系统。
另一个强大的模块是os.path,它可以完成一些针对路径名的操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pdhv2OVH-1611326858176)(https://gitee.com/shilong-com/typora-img/raw/master/typora-img/image-20201002200158815.png)]
basename(path) 和 dimame(path)
basename() 和 dirname()函数分别用于获得文件名和路径名:
print(os.path.dirname(r"a\b\test.txt")) #a\b
print(os.path.basename(r"a\b\test.txt")) #test.txt
- 1
- 2
join(path1[,path2[,…]])
join函数和BIF的那个join()函数不同,os.path.join()是用于将路径名和文件名组合成一个完整的路径:
print(os.path.join(r"C:\Python Project","python.py")) #C:\Python Project\python.py
- 1
split(path) 和 splitext(path)
spilt()分割路径和文件名(如果完全使用目录,它也会将最后一个目录当作文件分离,且不会判断文件或目录是否存在);splitext()函数是用来分割文件名和拓展名的
print(os.path.split("E:\Python project\邮箱号.xlsx"),os.path.splitext("E:\Python project\邮箱号.xlsx"))
输出结果:
('E:\\Python project', '邮箱号.xlsx') ('E:\\Python project\\邮箱号', '.xlsx')
- 1
- 2
- 3
getsize(file)
getsize()函数用于获取文件的尺寸,返回的值是以字节为单位的
print(os.path.getsize("E:\Python project\邮箱号.xlsx")) #10777
- 1
getatime(file)、getctime(file)、getmtime(file)
getatime(file)、getctime()和getmtime()分别用于获取文件最近访问的时间、创建时间和修改时间,不过返回值是浮点型秒数,可用time模块的gmtime()或localtime()函数换算
import os
import time
temp = time.localtime(os.path.getatime("邮箱号.xlsx"))
print("文件被访问时间为",time.strftime("%d %b %Y %H:%M:%S",temp))
temp = time.localtime(os.path.getctime("邮箱号.xlsx"))
print("文件被创建时间为",time.strftime("%d %b %Y %H:%M:%S",temp))
temp = time.localtime(os.path.getmtime("邮箱号.xlsx"))
print("文件被修改时间为",time.strftime("%d %b %Y %H:%M:%S",temp))
输出结果:
文件被访问时间为 27 Sep 2020 10:49:11
文件被创建时间为 26 Sep 2020 18:46:18
文件被修改时间为 27 Sep 2020 10:49:11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
风味独特的“泡菜” pickle
引例
从一个文件中读取字符串是非常简单的,但要想读取数值,那就有些麻烦了。因为无论是read()方法,还是readline()方法,都是返回一个字符串,如果希望从字符串中提取数值,可以使用int()函数或float()函数强行转换。
此前一直保存的是文本,然而当保存的数据像列表、字典、图像甚至是类的实例这些更复杂的数据类型时,普通文件就难以完成。如果把这些都转化为字符串保存,这会很麻烦。
Python为此提供了一个标准模块,使用这个模块就可以十分容易的将列表、字典等复杂数据类型存储为文件了,这就是pickle模块
这是个amazing模块,它几乎可以将所有Python对象都转化为二进制形式存放,这个过程称为picking,那么从二进制转换回对像的过程称为unpicking
转为二进制存放入文件
import pickle
list1 = ['卓世龙','善良','天真','handsome','optimistic']
file = open('list1.pkl','wb')
pickle.dump(list1,file)
file.close()
- 1
- 2
- 3
- 4
- 5
这里希望把这个列表永久保存下来(保存成文件),打开的文件一定要以二进制的形式打开,后缀名可以随意,但是为了记忆,最好使用.pkl
或 .pickle 使用dump方法保存数据,完成后记得保存,跟操作普通文本一样(.close())
执行后在相应路径上会出现 list.pkl文件,用记事本打开会乱码(因为保存的是二进制)
使用文件
import pickle
file = open('list1.pkl','rb')
list1 = pickle.load(file)
print(list1)
输出结果:
['卓世龙', '善良', '天真', 'handsome', 'optimistic']
- 1
- 2
- 3
- 4
- 5
- 6
事实上,利用pickle模块,不仅可以保存列表,还可以保存任何你能想象得到的东西,神奇的"泡菜"
九.异常处理
程序员有时的代码会有漏洞,程序总是会出问题的,我们应该用适当的方法解决问题。程序出现逻辑错误或者用户输入不合法都会引发异常,但这些异常并不致命,不会导致程序崩溃死掉,可以利用Python提供的异常处理机制,在异常出现时及时捕获,并从内部自我消化掉
引例
text = str(input("请输入您想要打开的文件名称"))
f = open(text,mode = "rb")
- 1
- 2
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yR9jA6HH-1611326858176)(…/…/…/…/AppData/Roaming/Typora/typora-user-images/image-20201003102146584.png)]
用户输入一个不存在的文件路径,就会抛出一个FileNotFoundError异常,而我们就要对异常进行一些处理,此外Python通常还可能抛出一下异常。
Python抛出异常总结
AssertionError:断言语句(assert)失败
当assert这个关键字后面的条件为假时,程序将终止并抛出AssertionError异常。assert语句一般是在测试程序时在代码中作为置入检查点
AttributeError:尝试访问未知的对象属性
当试图访问的对象属性不存在时抛出的异常:
my_list = []
my_list.fishc
File "E:/Python project/Hello World.py", line 456, in <module>
my_list.fishc
AttributeError: 'list' object has no attribute 'fishc'
- 1
- 2
- 3
- 4
- 5
- 6
IndexError:索引超出序列的范围
my_list = []
my_list[3]
- 1
- 2
KeyError:字典中查找一个不存在的关键字
my_list = {"loong":1,"house":2}
print(my_list["l"])
###############
KeyError: 'l'
- 1
- 2
- 3
- 4
NameError:尝试访问一个不存在的变量
当试图访问一个不存在的变量时,Python会抛出NameError异常
OSError:操作系统产生的异常
OSError为操作系统产生的异常,像打开一个不存在的文件会引发FileNotFoundError,而这个FileNotFoundError就是OSError的子类
SyntaxError:Python的语法错误
TypeError:不同类型间的无效操作
1+'1'
- 1
ZeroDivisionError:除数为零
try-except 语句
语句格式
语句格式如下
try:
检测范围
except Exception[as reason]
出现异常后的处理句子
try:
f = open('candy.txt')
print(f.read())
f.close()
except OSError:
print('文件打开过程出错了')
- 1
- 2
- 3
- 4
- 5
- 6
从程序员的角度来说,导致OSError异常的原因很多(例如FileExistsError,FileNotFoundError,PermissionError等等),所以可能更加在乎错误的具体内容,这里可以用as把具体的错误信息打印出来:
try:
f = open('candy.txt')
print(f.read())
f.close()
except OSError as reason:
print('文件打开过程出错了\n 错误原因是'+str(reason))
输出结果:
文件打开过程出错了
错误原因是[Errno 2] No such file or directory: 'candy.txt'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
针对不同异常可设置多个except
一个try语句可以和多个except语句搭配,分别对感兴趣的异常进行检查处理
try:
sum = 1 + '1'
f = open('candy.txt')
f.close()
except OSError as reason:
print('文件出错了\n原因是:'+str(reason))
except TypeError as reason:
print('类型出错了,原因是' + str(reason))
输出结果:
类型出错了,原因是unsupported operand type(s) for +: 'int' and 'str'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
多个异常统一处理
except后面可以跟多个异常,然后对异常统一处理
try:
sum = 1 + '1'
f = open('candy.txt')
f.close()
except (OSError ,TypeError) as reason:
print('文件出错了\n原因是:'+str(reason))
- 1
- 2
- 3
- 4
- 5
- 6
捕获所有异常
如果无法确定要对哪一类异常进行处理,只是希望在try语句块里一旦出现任何异常,可以给用户一个看的懂得提示,可以
try:
sum = 1 + '1' #try语句块了必须有代码
except:
print("出错了")
- 1
- 2
- 3
- 4
但这样往往会隐藏所有程序员未想到并且未做好处理准备的错误。另外注意,try语句检测的范围内一旦出现异常,剩下的代码将不会被执行。
try-finally语句
为了实现一些“就算出现异常,但也不得不收尾的工作(比如在程序崩溃前保存用户文档),引入finally来拓展try:
try:
f = open('邮箱号.xlsx')
print(f.read())
sum = 1 + '1'
except:
print("Error")
finally:
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果try语句块中没有出现任何运行错误,会跳过except语句块执行finally语句块的内容。如果出现异常,会先执行except语句块的内容,再执行finally语句块的内容。总之,finally语句块就是确保无论如何都将被执行的内容。
raise语句
通过raise语句,我们可以自己抛出异常
raise ZeroDivisionError
- 1
抛出的异常还可以带参数,表示异常的解释
raise ZeroDivisionError("除数不能为0")
- 1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LuisSZOS-1611326858177)(…/…/…/…/AppData/Roaming/Typora/typora-user-images/image-20201003154013126.png)]
else语句扩展
和if搭配
if 条件:
条件为真执行
else:
条件为假执行
和for,while循环语句配合使用
不过else语句块只能在循环完成后执行,也就是说,如果循环中间使用break语句跳出循环,那么else语句中的内容就不会被执行
def showMaxFactor(num):
count = num // 2
while count > 1:
if(num % count == 0):
print('%d最大公约数是%d'%(num,count))
break
count -= 1
else:
print('%d是素数!'% num)
num = int(input('请输入一个数'))
showMaxFactor(num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K5UISvRI-1611326858178)(…/…/…/…/AppData/Roaming/Typora/typora-user-images/image-20201003155008349.png)]
与try语句搭配
只要try语句块里没有出现任何异常,那么就会执行else语句块里的内容
try:
int('abc')
except ValueError as reason:
print('出错了:'+ str(reason))
else:
print('程序非常正确')
- 1
- 2
- 3
- 4
- 5
- 6
简洁的with语句
Python提供了一个with语句,利用这个语句抽象出文件操作中频繁使用的try/except/finally相关的细节。对文件操作使用with语句将大大减少代码量,而且也不用但心文件关闭问题(with会自动帮你关闭文件)
try:
f = open('list1.pkl',mode = 'rb')
for each_line in f:
print(each_line)
except OSError as reason:
print('出错了' + str(reason))
finally:
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
转变为with语句
try:
with open('list1.pkl','rb') as f:
for each_line in f:
print(each_line)
except OSError as reason:
print('出错了' + str(reason))
- 1
- 2
- 3
- 4
- 5
- 6
有了with语句,代码简洁很多,而且再也不用担心忘记关闭文件了。
十.初识图形化界面
安装EasyGui
教程
在命令行输入pip install easygui

import easygui
easygui.msgbox("嗨,大噶好")
- 1
- 2
导入EasyGui
import easygui
easygui.msgbox("嗨,大噶好")
- 1
- 2
from easygui import *
msgbox("嗨,大噶好")
- 1
- 2
3.(建议使用,保持了EasyGui的命名空间,同时也减少输入字符的数量)
import easygui as g
g.msgbox("嗨,大噶好")
- 1
- 2
引例
运行一下
import easygui as g
import sys
while 1:
g.msgbox("hi,welcome to this game")
msg = "what would you want to learn in this game"
title = "connect"
choices = ["love","knowledge","demo","poem"]
choice = g.choicebox(msg,title,choices)
g.msgbox("what's your choice:"+str(choice),"result")
msg = "do you want to have a game again?"
title = "please make a choice"
if g.ccbox(msg,title):
pass
else:
sys.exit(0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
语法
修改默认位置
默认情况下显示的对话框非常大,而且字体也很不好看,这里可以手动调整EasyGui的参数修改
十一.类与对象
引例
class Girlfriend: hight = 165 weight = 48 likeFood = "hotdog" likesong = "try everything" def __init__(self): #构造方法 print("I'm a beautiful girl,my boyfriend is ...,we love each other") def getHight(self): print("我身高是"+str(self.hight)+"cm呀") def getWeight(self): print("讨厌了,这是秘密,不知道问女孩子体重是不礼貌的吗") def getFood(self): print("the food I like best is "+self.likeFood) def getSong(self): print("the song I like best is "+self.likesong) def saysomething(self): print("I love you") def setHeigt(self,heigt): #self类似于C++,java中的this self.hight = heigt def setWeight(self,weight): self.weight = weight girl1 = Girlfriend() #创建对象 girl1.getFood() girl1.getSong() girl1.setHeigt(168) girl1.getHight() girl1.getWeight() 输出结果: I'm a beautiful girl,my boyfriend is ...,we love each other the food I like best is hotdog the song I like best is try everything 我身高是168cm呀 讨厌了,这是秘密,不知道问女孩子体重是不礼貌的吗
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
对象 = 属性 + 方法
类的定义
class Girlfriend:
- 1
- 2
创建对象
使用定义的类创建对象,这个对象就叫做这个类的一个实例,也叫实例对象
类好比工厂的模具,对象就是一个个产品
girl1 = Girlfriend()
- 1
注意:类名后跟着小括号,这跟调用函数是一样的,所以在Python中,类名的约定用大写字母开头,函数用小写字母开头,这样更容易区分。另外赋值操作并不是必须的,但如果没有创建把创建好的实例对象赋值给一个变量,那这个对象就无法使用,因为没有任何引用指向这个实例,最终会被Python垃圾回收机制自动回收
如果要调用对象里的方法,使用**点操作符(.)**即可
self
可以发现,对象的方法都会有一个self参数,类似于C++的this指针
由于同一个类可以生成无数个对象,当一个对象的方法被调用时,对象会将自身的引用作为第一个参数传给该方法,那么Python就知道需要操作那个对象的方法了。
class Girlfriend:
def __init__(self,own_name,boyFriend_name):
print("我是"+str(own_name)+",是"+str(boyFriend_name)+"的女朋友")
self.name = own_name
def setName(self,newName):
self.name = newName
print(self.name)
girl = Girlfriend("白娘子","许仙")
girl.setName("许县")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
构造方法
Python的对象天生拥有一些魔力的方法,他们是面向对象的Python的一切。他们是可以给你的类增加魔力的特殊方法,如果你的对象实现了这些方法中的某一个,那么这个方法就会在特殊的情况下被Python所调用,而这一切都是自动发生的。
Python这些具有魔力的方法总是被双下划线所包围,构造方法( **__init__() **)就是其最基本的一类
通常把 **__init__() **方法称为构造方法, **__init__() **方法的魔力体现在只要实例化一个对象,这个方法就会在对象创建时自动调用(类似于C++中的构造函数)
实例化对象是可以传入参数的,这些参数会自动传入 **__init__() **方法中,可以通过重写这个方法来自定义对象的初始化操作
class Girlfriend:
def __init__(self,own_name,boyFriend_name):
print("我是"+str(own_name)+",是"+str(boyFriend_name)+"的女朋友")
Girlfriend("白娘子","许仙") #我是白娘子,是许仙的女朋友
- 1
- 2
- 3
- 4
公有私有
C++和Java他们使用关键字(public,private)用于声明数据是共有的还是私有的,但在Python中并没有类似的关键字来修饰
Python默认上对象的属性和方法都是公开的,可以直接通过点操作符进行访问。
为了实现类似私有变量的特征,Python内部采用了一种叫name mangling(名字改编)的技术,在Python中定义私有变量只需要在变量名或函数名前加上"__"两个下划线,那么这个函数或变量就成私有的了
继承
被继承的类称为基类,父类或超类;继承者称为子类,一个子类可以继承他的父类的任何属性和方法
语法
class 类名(被继承的类):
class Girl:
def introduce(self):
print("有长长的头发")
class GirlFriend(Girl):
pass
g1 = Girl()
gf = GirlFriend()
g1.introduce()
gf.introduce()
运行结果:
有长长的头发
有长长的头发
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
如果自类和父类有同名的方法或属性,则会自动覆盖父类对应的方法
class Girl:
def introduce(self):
print("有长长的头发")
class GirlFriend(Girl):
def introduce(self):
print("有长长的头发,有深爱她的男朋友")
g1 = Girl()
gf = GirlFriend()
g1.introduce()
gf.introduce()
运行结果:
有长长的头发
有长长的头发,有深爱她的男朋友
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
多重继承
就是可以同时继承多个父类的属性和方法
class 类名(父类1,父类2,父类3,···):
调用未绑定的父类方法
import random as r class Fish: def __init__(self): self.x = r.randint(0,10) self.y = r.randint(0, 10) def move(self): self.x -= 1 #假设所有鱼都是一路向西游的 print("我现在的位置在:",self.x,self.y) class Goldfish(Fish): pass class Shark(Fish): def __init__(self): self.hungry = True def eat(self): if self.hungry: print("I want to eat you") self.hungry = False else: print("算了算了,放过你了") fish = Fish() fish.move() goldfish =Goldfish() goldfish.move() shark = Shark() shark.eat() shark.move() #运行后会发现这条语句会报错
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
因为在Shark中重写了魔法方法**__init__,但新的__init__方法里面没有初始化鲨鱼的x坐标和y坐标,因此调用move方法时会报错,所以应该在Shark类中重写__init__方法时先调用Fish的__init__**方法
解决方法一
class Shark(Fish):
def __init__(self):
Fish.__init__(self)
self.hungry = True
- 1
- 2
- 3
- 4
需要注意:这里的self并不是父类Fish的实例对象,而是子类Shark的实例对象,所以这里说的未绑定是指并不需要绑定父类的实例对象,使用子类的实例对象代替即可。
方法二 super函数
super函数
super函数能够自动找到基类的方法,而且为我们传入了self参数
class Shark(Fish):
def __init__(self):
super().__init__()
self.hungry = True
- 1
- 2
- 3
- 4
super函数强大之处在于你不需要明确给出任何基类的名字,它会自动帮你找出所有基类以及对应的方法。由于你不用给出基类的名字,这就意味者如果需要改变类继承关系,只要改变class语句中的父类即可,而不必在大量代码中修改所有被继承关系。
组合
其实也就是在类内创建对象,把需要的类放进去实例化
class School: def __init__(self,x,y): self.teahcer = Teacher(x) #类内 self.student = Student(y) def coutNumber(self): print("这个学校共有%d个老师,%d个学生"%(self.teahcer.numberOfTeachers,self.student.numberOfStudents)) class Teacher: def __init__(self,x): self.numberOfTeachers = x class Student: def __init__(self,x): self.numberOfStudents = x CSU = School(3000,100000) CSU.coutNumber() 运行结果: 这个学校共有3000个老师,100000个学生
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
类对象与实例对象
class C:
count = 0
a = C()
b = C()
c = C()
print(a.count,b.count,c.count)
c.count = 111
print(a.count,b.count,c.count)
C.count = 123
print(a.count,b.count,c.count)
运行结果:
0 0 0
0 0 111
123 123 111
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
注意,类中定义的属性是静态变量,类似于C++中加上static声明的变量,类的属性是与类对象进行绑定,并不会依赖于任何他的实例对象
另外,当类的属性与方法名相同时,属性会覆盖方法
class C:
def first(self):
print("zsl")
first = 1
a = C()
a.first()
print(a.first)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pDmrPjUG-1611326858180)(…/…/…/…/AppData/Roaming/Typora/typora-user-images/image-20201005153015564.png)]
为了避免名字上的冲突,大家应该遵守一些约定俗成的规矩
**·**不要试图在一个类里面定义出所有能想到的特性和方法,应该用继承和组合机制来进行拓展
**·**用不用的词性命名,如属性名用名词,方法名用动词
Python的绑定
仔细观察这段代码
class C:
first1 = 1
second = 2
class B(C):
def first():
print("zsl")
print(C.second)
B.first()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
虽然会有警告标红,但程序可以正常运行
但是根据类的实例化的对象根本无法调用里面的函数
b = B()
b.first()
- 1
- 2
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3gRLYB5y-1611326858181)(…/…/…/…/AppData/Roaming/Typora/typora-user-images/image-20201005160842842.png)]
事实上由于Python的绑定机制,这里自动把b对象当作第一个参数传入,所以会出现TypeError
再看这段代码
class B: def first(self,x,y): self.first = x self.second = y print("zsl") b = B() b.first(52,1) print(B.__dict__) b.first =2 print(b.__dict__) print(B.__dict__) del B b.first 运行结果: zsl {'__module__': '__main__', 'first': <function B.first at 0x000002021DECA670>, '__dict__': <attribute '__dict__' of 'B' objects>, '__weakref__': <attribute '__weakref__' of 'B' objects>, '__doc__': None} {'first': 2, 'second': 1} {'__module__': '__main__', 'first': <function B.first at 0x000002021DECA670>, '__dict__': <attribute '__dict__' of 'B' objects>, '__weakref__': <attribute '__weakref__' of 'B' objects>, '__doc__': None}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
对象的改变不影响类属性,两次B.__dict__输出一样
这是因为self参数,当实例对象b调用first方法时,它传入的第一个参数就是b,所以函数内的self.first = x就相当于b.first = x
此时x,y这两个属性仅属于b这个对象
因而删去类实例B后,d还能调用first方法
相关的一些BIF
issubclass(class,classinfo)
如果第一个参数(class)是第二个参数(classinfo)的一个子类,则返回True,否则返回False
注意:
1.一个类被认为是自身的子类
2.classinfo可以是类对象组成的元组,只要class是其中任何一个候选类的子类,则返回True
3.其他情况下会抛出一个TypeError异常
isinstance(object,classinfo)
如果第一个参数(object)是第二个参数(classinfo)的实例对象,则返回True,否则返回False
1.如果object是classinfo的子类的一个实例,也符合条件
2.如果第一个参数不是对象,则永远返回False
3.classinfo可以是类对象组成的元组,只要object是其中任何一个候选对象的实例,则返回True
4.如果第二个参数不是类或者是由类对象组成的元组,则会抛出一个TypeError异常
class B:
pass
b = B()
class C:
pass
class D:
pass
lisg = 1
print(isinstance(b,B))
print(isinstance(b,(B,C,D)))
print(isinstance(lisg,B))
输出结果:
True
True
False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
hasattr(object,name)
hasattr()作用是测试一个对象里是否有指定的属性
第一个参数(object)是对象,第二个参数(name)是属性名
class C:
def __init__(self,x = 0):
self.x = x
c1 = C()
print(hasattr(c1,'x')) #True
- 1
- 2
- 3
- 4
- 5
getattr(object,name[,default])
返回对象的指定属性值,如果指定的属性不存在,则返回default(可选参数)的值;若没有设置default参数,则抛出ArttributeError异常
class C:
def __init__(self,x = 0):
self.x = x
c1 = C()
print(getattr(c1,'x')) #0
print(getattr(c1,'y',"访问属性值不存在")) #访问属性值不存在
print(getattr(c1,'y')) #报错 (因为指定属性不存在,且没设置default参数)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
setattr(object,name,value)
setattr可以设置对象中指定属性的值,如果指定属性不存在,则会新建属性并赋值
setattr(c1,'y','Fish')
print(getattr(c1,'y')) #Fish
- 1
- 2
delattr(object,name)
与setattr相反,delattr用来删除对象中指定的属性,如果属性不存在,则抛出AttributeError异常
delattr(c1,'y')
delattr(c1,'z')
- 1
- 2
property(fget = None,fest = None,fdel = None,doc = None)
property可以通过属性设置属性
以下是 property() 方法的语法:
property([fget[, fset[, fdel[, doc]]]])
- 1
-
fget – 获取属性值的函数
-
fset – 设置属性值的函数
-
fdel – 删除属性值函数
-
doc – 属性描述信息
返回新式类属性。
property()返回一个可以设置属性的属性
class C(object): def __init__(self): self._x = None def getx(self): return self._x def setx(self, value): self._x = value def delx(self): del self._x x = property(getx, setx, delx, "I'm the 'x' property.") c.x c.x = value del c
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
如果 c 是 C 的实例化, c.x 将触发 getter,c.x = value 将触发 setter , del c.x 触发 deleter。
如果给定 doc 参数,其将成为这个属性值的 docstring,否则 property 函数就会复制 fget 函数的 docstring(如果有的话)。
十二.魔法方法
构造与析构函数
_init_(self[,···])
构造函数,可以传入参数,在类实例化时会调用的一个函数,但并不是实例化时第一个调用的魔法方法
_new_(cls[,···])
_new_(cls[,···])是对象实例化时调用的第一个方法
它的第一个参数不是self而是这个类(cls),而其它参数会直接传给__init__()方法
_del_(self)
析构器,当对象被销毁时调用,类似C++的析构函数
class C:
def __init__(self):
self._x = None
def __del__(self):
print("该对象已被销毁")
x = C()
del x
输出结果:
该对象已被销毁
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
算数运算
def a():
pass
print(type(int))
print(type(a))
输出结果:
<class 'type'>
<class 'function'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
int(),float(),str(),list(),tuple()这些BIF转换为工厂函数
所谓工厂函数就是类对象,当调用她们时,事实上就是创建一个相应的实例对象:
a = int("123")
b = int("456")
print(a+b)
- 1
- 2
- 3
由此可知对象是可以进行运算,Python的魔法方法还提供了自定义对象的数值处理,通过对下面这些魔法方法的重写,可以定义任何对象间的算数运算。
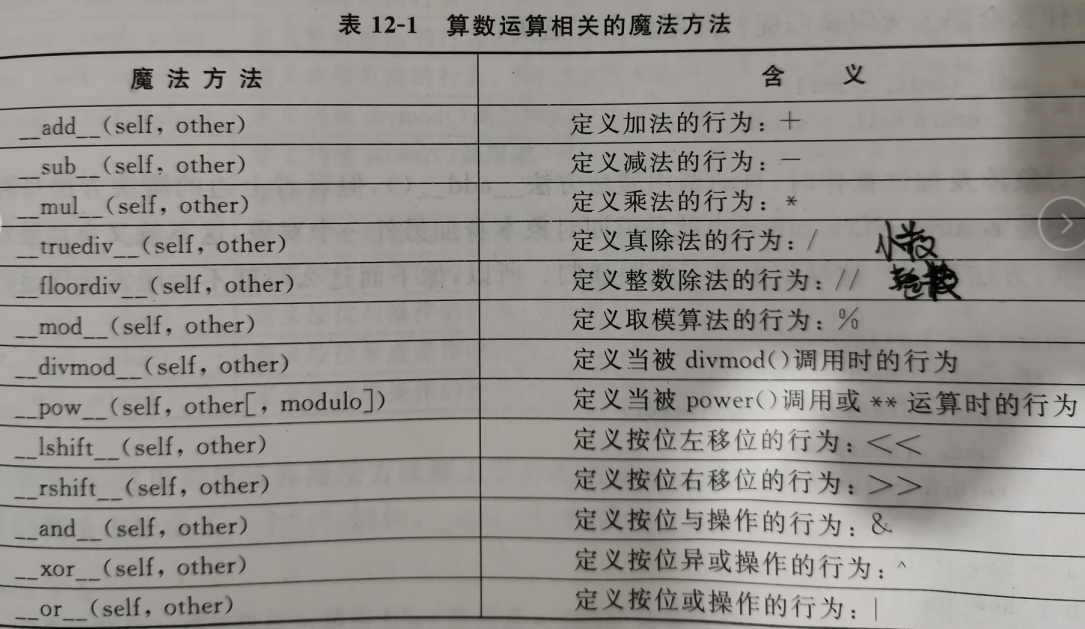
class New_int(int):
def __add__(self, other):
return int.__sub__(self,other)
def __sub__(self, other): #重写方法
return int.__add__(self,other)
a = New_int('4')
b = New_int('6')
print(a-b)
print(a+b)
输出结果:
10
-2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
生成器
def myGen(): print("生成器被执行") yield 1 yield 2 yield "zsl is handsome" print(myGen()) myGen1 = myGen() print(next(myGen1)) print(next(myGen1)) print(next(myGen1)) 运行结果: <generator object myGen at 0x0000022C2D953CF0> 生成器被执行 1 2 zsl is handsome
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
generator 生成器,由于python的for循环会自动调用next()方法和处理StopIteration异常,所以for循环当然也是可以对生成器产生作用的
for i in myGen():
print(i)
运行结果:
生成器被执行
1
2
zsl is handsome
- 1
- 2
- 3
- 4
- 5
- 6
- 7
列表推导式,字典推导式,集合推导式
a = [i for i in range(50,100) if not(i % 2) and i % 3]
print(a)
b = {i:i % 2 == 0 for i in range(10)}
print(b)
c = {i for i in range(20,50) if i % 5 == 0}
print(c)
运行结果:
[50, 52, 56, 58, 62, 64, 68, 70, 74, 76, 80, 82, 86, 88, 92, 94, 98]
{0: True, 1: False, 2: True, 3: False, 4: True, 5: False, 6: True, 7: False, 8: True, 9: False}
{35, 40, 45, 20, 25, 30}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
字符串推导式,元组推导式
c = "i for i in 'I love you'"
print(c)
运行结果:
i for i in 'I love you'
- 1
- 2
- 3
- 4
显然字符串推导式是不行的,在双引号内,所有东西都变成了字符串
e = (i for i in range(1,4))
print(e)
输出结果:
<generator object <genexpr> at 0x000002A1607CCC80>
- 1
- 2
- 3
- 4
generator,用小括号括起的正是生成器推导式
print(next(e))
print(next(e))
运行结果:
1
2
- 1
- 2
- 3
- 4
- 5
另外,生成器推导式如果作为函数参数,可以直接写推导式,而不用加小括号
print(sum(i for i in range(1,4)))
- 1
十三.模块
十四.爬虫
十五.界面设计
十六.游戏开发

