
热门标签
热门文章
- 1数据结构——单链表基本操作的实现_输入无序的元素,分别建立两个有4个结点的有序单链表(无头结点)(显示排序后的链表)
- 2oneNET与MQTT.fx相链接常见错误_onenet连接不上
- 3React如何使用 Ant Design(简单使用)_react antdesign
- 4【IDEA--dubug相关】Debug项目时启动不了(启动至一半卡住)
- 5回溯法解决全排列问题总结_全排列回溯
- 6GetCommandLine 分析
- 7微信小程序使用Swiper组件实现层叠轮播图_swiper-item 图片叠加显示
- 8java 报错 unsupported_Java中List.remove报错UnsupportedOperationException
- 9【文章复现】基于主从博弈的社区综合能源系统分布式协同 优化运行策略
- 10Home Assistant安装指北(树莓派+Debian12+HASS Container+HACS极速版)_树莓派安装hass
当前位置: article > 正文
NLP:文本聚类【PCA-->K-means】_nlp 聚类
作者:羊村懒王 | 2024-04-15 02:51:03
赞
踩
nlp 聚类
什么是文本聚类?
文本聚类是将一个个文档由原有的自然语言文字信息转化成数学信息,以高维空间点的形式展现出来,通过计算那些点距离比较近来将那些点聚成一个簇,簇的中心叫做簇心。一个好的聚类要保证簇内点的距离尽量的近,但簇与簇之间的点要尽量的远。
文本聚类的难点是什么?
聚类是一种非监督学习,也就是说聚成几类,怎么聚,我们都不知道,只能一点点试出来。但是有时候机器认为这两堆点可以认为是两个簇,但人理解可能是一个簇,文本聚类就就难在了这里,机器与人的理解不太一样。一般能看到这个博的人都学过基本的聚类算法,拿k-means为例,簇心的选取是个非常随机的过程,导致k值相同的情况下聚类的结果每次都不一样,又不好取个平均,所以聚类的好坏很难被评价出来。
如何评价聚类的好坏?
http://blog.csdn.net/chixujohnny/article/details/51852633 中讲到完爆一切的S_Dbw评价指标,我目前还没试过,有兴趣的同学可以试试,总之早晚都要用的。
文本聚类过程
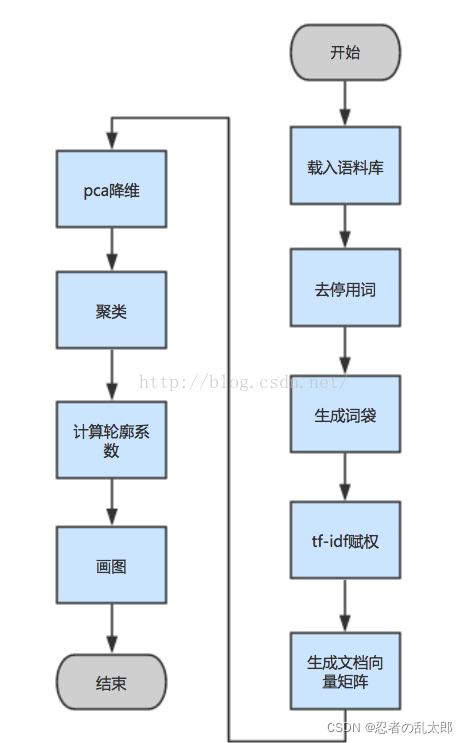
词赋权方法还有textrate,还没用,jieba自带的,肉眼看不错,可以试试。
上面的图说几个部分,一般生成声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/425462
推荐阅读
相关标签

