
- 1这6种最佳移动自动化测试工具你知道吗?
- 2我的2021年总结
- 3PostgreSQL存储过程(函数)_greenplumn 存储过程loop循环
- 4湖南文理学院c语言题库,湖南文理学院_通讯录管理系统课程设计归纳总结报告书(C语言)(21页)-原创力文档...
- 5postgres14.5+postgis3.3.2+pgRouting3.4.2源码安装_pgrouting 安装
- 6无公网IP,使用ZeroTier免费内网穿透_allow assignment of global ips
- 72024年MathorCup数学建模挑战赛A题B题C题D题思路模型代码_2024数学建模挑战杯
- 8Ardupilot 高度控制代码整理(超长篇)_无人机定高代码
- 9git 强制将本地代码提交到远端分支_git push origin --force
- 10学历低能不能大厂?
终于等到open Sora开源,解读open- Sora1.0文生视频模型_open-sora
赞
踩

Colossal-AI团队全面开源了名为「Open-Sora 1.0」的视频生成模型,该模型采用类Sora架构,基于Diffusion Transformer (DiT) 架构设计,并扩展到视频数据领域。Open-Sora 1.0 的训练流程涵盖了从数据处理、训练细节到模型权重的全部内容,
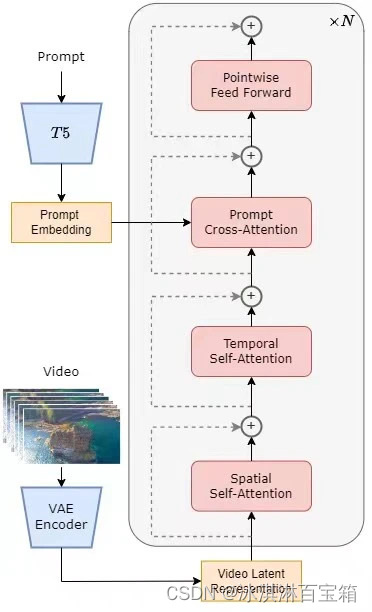
并且包括三个关键阶段:
1. 大规模图像预训练:利用已有的大规模图像数据和高质量文生图技术(如Stable Diffusion模型提供的图像 VAE),降低了视频预训练的成本。
2. 大规模视频预训练:在第一阶段的基础上增加了时序注意力模块,通过使用大量多样性的视频数据进行训练,以增强模型对时间序列关系的学习能力和泛化能力。团队采用了PixArt-α模型的部分开源权重以及T5作为文本编码器,采用小分辨率预训练加速收敛速度。
3. 高质量视频数据微调:针对高分辨率、高质量和更长时长的视频数据进行微调,显著提升了视频生成的质量,实现了从低分辨率向高分辨率、短时长向长时长的高效过渡。
为了降低复现门槛和简化数据预处理过程,Colossal-AI 团队提供了便捷的数据预处理脚本和批量视频标题生成工具,用户可以轻松下载公开视频数据集、分割视频片段并生成对应提示词。此外,他们还展示了Open-Sora 模型的实际应用效果,能够生成包括航拍海岸、瀑布景色、水下世界和星空延时摄影等多种场景的视频。
整个项目开源地址为https://github.com/hpcaitech/Open-Sora,
并且作者团队计划不断优化与更新模型,增加更多训练数据以提高视频生成质量和时长,并支持多分辨率特性,推动AI视频生成技术在多个行业中的应用。同时,他们在训练效率上也取得了显著成果,借助Colossal-AI加速系统,不仅降低了训练成本,还在视频训练过程中实现了高效的加速效果。

