
- 1基于微信小程序毕业设计论文题目
- 2Python,使用for循环计算0到一百的奇数或偶数之和。_for循环求1-100奇数和
- 3ubuntu服务器关机重新开机之后nvidia-smi不显示但nvcc -C没问题
- 4北京内推 | 微软亚洲研究院DKI组招聘Copilot与LLM研发实习生
- 5毕业设计 基于Stm32的智能药箱系统
- 6正向代理和反向代理的区别_正向代理与反向代理的区别
- 7金融领域中的大模型Lora微调:实战应用与性能优化
- 8最新Hadoop与HBase对应版本关系_hbase最新版本
- 9React18介绍及setState、suspense、useTransition、useDeferredValue的使用_react.suspense使用
- 10fatal: detected dubious ownership in repository at ‘D:/HBuilderProjects/uni-shop-2‘_is owned by: 's-1-5-32-544' but the current user i
Redis集群系列十一 —— 故障转移一_redis集群怎么故障转移
赞
踩
故障发现
Redis 集群内节点通过 ping/pong 消息实现节点通信,消息不但可以传播节点槽信息,还可以传播其他状态。当集群中某个节点出现问题时,需要识别出节点是否发生了故障,因此故障发现是通过Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。
下线原理
一个节点认为某个节点失联并不代表所有的节点都认为它失联了,所以集群还得经过一次协商的过程,只有当大多数节点都认定了某个节点失联了,集群才认为该节点需要进行主从切换来容错。
Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。假如一个节点发现某个节点失联了,它会将这条信息向整个集群广播,其它节点也就可以收到这点失联信息。如果一个节点收到了某个节点失联的数量已经达到了集群的大多数,就可以标记该节点为确定下线状态,然后向整个集群广播,强迫其它节点也接收该节点已经下线的事实,并立即对该失联节点进行主从切换。
主要环节包括:主观下线(PFAIL-Possibly Fail)和客观下线(Fail)。
主观下线
集群中每个节点都会定期向其他节点发送 ping 消息,接收节点回复 pong 消息作为响应。如果在 cluster-node-timeout 时间内通信一直失败,则发送节点会认为接收节点存在故障,把接收节点标记为主观下线状态。如图: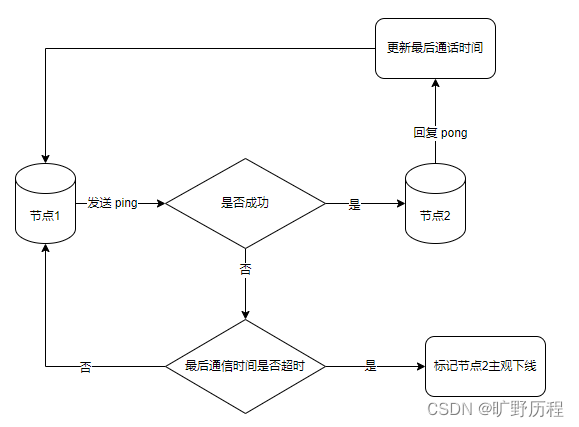
简单的说就是当 cluster-note-timeout 时间内某节点无法与另一个节点顺利完成 ping 消息通信时,则将该节点标记为主观下线状态。
客观下线
Redis 集群对于节点最终是否故障判断非常严谨,只有一个节点认为主观下线并不能准确判断是否故障。当某个节点判断另一个节点主观下线后,相应的节点状态会通过 Gossip 消息在集群内传播。当半数以上的持有槽的主节点都标记某个节点主观下线,就会尝试客观下线。如图:
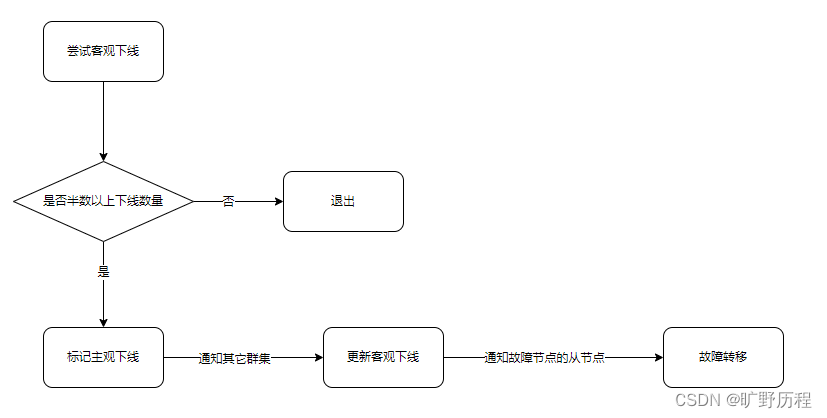
如果在 cluster-node-time*2 时间内无法收集到一半以上槽节点的下线报告,那么之前的下线报告将会过期。当主观下线上报的速度追赶不上下线报告过期的速度,那么故障节点将永远无法被标记为客观下线从而导致故障转移失败。因此不建议将 cluster-node-time 设置得过小。
为什么必须是负责槽的主节点参与故障发现决策?
因为集群模式下只有处理槽的主节点才负责读写请求和集群槽等关键信息维护,而从节点只进行主节点数据和状态信息的复制。
故障恢复
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个节点替换它,从而保证集群的高可用。
下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节点进入客观下线时,将会触发故障恢复流程。
注意:不是所有节点都能参加选举,在选举前要先进行资格检查,只有具备资格的从节点才能参加选举。参加选举有条件如下:
- 故障节点的所有从节点检查和故障主节点之间的断线时间
- 超过cluster-node-timeout * cluster-slave-validati-factor(默认10)则取消选举资格
当从节点被选举成主节点之后,就要开始进行替换主节点:
- 让该 slave 节点执行 slaveof no one 变为 master 节点
- 将故障节点负责的槽分配给该节点
- 向集群中其他节点广播 pong 消息,表明已完成故障转移
- 故障节点重启后,会成为 new_master 的 slave 节点
故障转移时间
主观下线识别时间 = cluster-node-timeout
主观下线状态消息传播时间 <= cluster-node-timeout/2,消息通信机制对超过 cluster-node-timeout/2 未通信节点会发起 ping 消息,消息体在选择包含哪些节点时会优先选取下线状态节点,所以通常这段时间内能够收集到半数以上主节点的下线报告从而完成故障发现。
选举存在一些延迟,从节点转移时间 <= 1000 毫秒,偏移量最大的从节点会最多延迟1秒发起选举,所以从节点执行转移时间在1秒以内。
根据以上分析可以预估出故障转移时间:failover-time ≤ (cluster-node-timeout * 1.5 + 1000)ms。
因此,故障转移时间跟 cluster-node-timeout 参数息息相关,默认15秒,配置时可以根据业务容忍度做出适当调整,但不是越小越好。

