
- 1redis的基础底层篇 zset的详解_redis zset
- 2离线数仓数据导出-hive数据同步到mysql
- 3VR全景在线虚拟展厅实现全方位沉浸式互动体验_vr在线体验瑟瑟
- 4怎么自学python自动化测试-Python移动自动化测试面试 学习 教程
- 5vscode的launch.json是什么_vscode launch.json
- 6Git error: cannot lock ref_error: cannot lock ref 'refs/heads/main': is at
- 7MySql重点复习——删除表的方式_mysql删除表
- 8YOLOv9改进策略 | 损失函数篇 | 利用真实边界框损失之MPDIoU助力YOLOv9精度更上一层楼_pred_bboxes_pos = torch.masked_select
- 9华为OD机试统一考试D卷C卷 - 查找接口成功率最优时间段(C++ Java JavaScript Python C语言)
- 10【Git】本地仓库关联远程仓库_git本地仓库关联远程
requests库的使用(非常详细)从零基础入门到精通,看完这一篇就够了
赞
踩
urllib库使用繁琐,比如处理网页验证和Cookies时,需要编写Opener和Handler来处理。为了更加方便的实现这些操作,就有了更为强大的requests库。
request库的安装
requests属于第三方库,Python不内置,因此需要我们手动安装。
1、相关链接
-
GitHub:https://github.com/psf/requests
-
PyPI:https://pypi.org/project/requests/
-
官方文档:https://docs.python-requests.org/en/latest/
-
中文文档:https://docs.python-requests.org/zh_CN/latest/user/quickstart.html
2、通过pip安装
无论是Windows、Linux还是Mac,都可以通过pip这个包管理工具来安装requests。在命令行界面运行如下命令,即可完成requests库的安装:
pip3 install requests
- 1
- 2
除了通过pip安装,还可以通过wheel或源码安装,这里不进行叙述。
3、验证安装
在命令行可通过导入import库来测试requests是否安装成功。
 导入库成功,说明requests安装成功。
导入库成功,说明requests安装成功。
基本用法
下面案例使用requests库中的get( )方法发送了一个get请求。
#导入requests库
import requests
#发送一个get请求并得到响应
r = requests.get('https://www.baidu.com')
#查看响应对象的类型
print(type(r))
#查看响应状态码
print(r.status_code)
#查看响应内容的类型
print(type(r.text))
#查看响应的内容
print(r.text)
#查看cookies
print(r.cookies)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这里调用了get( )方法实现urlopen( )相同的操作,结果返回一个响应对象,然后分别输出响应对象类型、状态码、响应体内容的类型、 响应体的内容、Cookies。通过运行结果可以得知:响应对象的类型是requests.models.Response,响应体内容的类型是str,Cookies 的类型是RequestCookieJar。如果要发送其他类型的请求直接调用其对应的方法即可:
r = requests.post('https://www.baidu.com')
r = requests.put('https://www.baidu.com')
r = requests.delete('https://www.baidu.com')
r = requests.head('https://www.baidu.com')
r = requests.options('https://www.baidu.com')
- 1
- 2
- 3
- 4
- 5
- 6
GET请求
构建一个GET请求,请求http://httpbin.org/get(该网站会判断如果客户端发起的是GET请求的话,它返回相应的信息)
import requests
r = requests.get('http://httpbin.org/get')
print(r.text)
- 1
- 2
- 3
- 4

1)如果要添加请求参数,比如添加两个请求参数,其中name值是germey,age值是20。虽然可以写成如下形式:
r = requests.get('http://httpbin.org/get?name=germey&age=20')
- 1
- 2
但较好的写法是下面这种写法:
import requests
data = {
'name':'germey',
'age':22
}
r = requests.get('http://httpbin.org/get',params=data)
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

通过运行结果可以看出,请求的URL最终被构造成了“http://httpbin.org/get?name=germey&age=20”。
2)网页的返回内容的类型是str类型的,如果它符合JSON格式,则可以使用json( )方法将其转换为字典类型,以方便解析。
import requests
r = requests.get('http://httpbin.org/get')
#str类型
print(type(r.text))
#返回响应内容的字典形式
print(r.json())
#dict类型
print(type(r.json()))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
但需要注意,如果返回的内容不是JSON格式,调用json( )方法便会出现错误,抛出json.decoder.JSONDecodeError异常。
POST请求
1)发送POST请求。
import requests
r = requests.post('http://httpbin.org/post')
print(r.text)
- 1
- 2
- 3
- 4
2)发送带有请求参数的POST请求。
import requests
data = {
"name":"germey",
"age":"22"
}
r = requests.post('http://httpbin.org/post',data=data)
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

在POST请求方法中,form部分就是请求参数。
设置请求头
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'my-test':'Hello'
}
r = requests.get('http://httpbin.org/get',headers=headers)
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

响应
1)发送请求后,返回一个响应,它具有很多属性,通过它的属性来获取状态码、响应头、Cookies、响应内容等。如下:
import requests r = requests.get('https://www.baidu.com/') #响应内容(str类型) print(type(r.text),r.text) #响应内容(bytes类型) print(type(r.content),r.content) #状态码 print(type(r.status_code),r.status_code) #响应头 print(type(r.headers),r.headers) #Cookies print(type(r.cookies),r.cookies) #URL print(type(r.url),r.url) #请求历史 print(type(r.history),r.history)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2)状态码常用来判断请求是否成功,除了可以使用HTTP提供的状态码,requests库中也提供了一个内置的状态码查询对象,叫做 requests.codes,实际上两者都是等价的。示例如下:
import requests
r = requests.get('https://www.baidu.com/')
if not r.status_code==requests.codes.ok:
print('Request Fail')
else:
print('Request Successfully')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
requests.codes对象拥有的状态码如下:
#信息性状态码 100:('continue',), 101:('switching_protocols',), 102:('processing',), 103:('checkpoint',), 122:('uri_too_long','request_uri_too_long'), #成功状态码 200:('ok','okay','all_ok','all_okay','all_good','\\o/','√'), 201:('created',), 202:('accepted',), 203:('non_authoritative_info','non_authoritative_information'), 204:('no_content',), 205:('reset_content','reset'), 206:('partial_content','partial'), 207:('multi_status','multiple_status','multi_stati','multiple_stati'), 208:('already_reported',), 226:('im_used',), #重定向状态码 300:('multiple_choices',), 301:('moved_permanently','moved','\\o-'), 302:('found',), 303:('see_other','other'), 304:('not_modified',), 305:('user_proxy',), 306:('switch_proxy',), 307:('temporary_redirect','temporary_moved','temporary'), 308:('permanent_redirect',), #客户端请求错误 400:('bad_request','bad'), 401:('unauthorized',), 402:('payment_required','payment'), 403:('forbiddent',), 404:('not_found','-o-'), 405:('method_not_allowed','not_allowed'), 406:('not_acceptable',), 407:('proxy_authentication_required','proxy_auth','proxy_authentication'), 408:('request_timeout','timeout'), 409:('conflict',), 410:('gone',), 411:('length_required',), 412:('precondition_failed','precondition'), 413:('request_entity_too_large',), 414:('request_uri_too_large',), 415:('unsupported_media_type','unsupported_media','media_type'), 416:('request_range_not_satisfiable','requested_range','range_not_satisfiable'), 417:('expectation_failed',), 418:('im_a_teapot','teapot','i_am_a_teapot'), 421:('misdirected_request',), 422:('unprocessable_entity','unprocessable'), 423:('locked'), 424:('failed_dependency','dependency'), 425:('unordered_collection','unordered'), 426:('upgrade_required','upgrade'), 428:('precondition_required','precondition'), 429:('too_many_requests','too_many'), 431:('header_fields_too_large','fields_too_large'), 444:('no_response','none'), 449:('retry_with','retry'), 450:('blocked_by_windows_parental_controls','parental_controls'), 451:('unavailable_for_legal_reasons','legal_reasons'), 499:('client_closed_request',), #服务端错误状态码 500:('internal_server_error','server_error','/o\\','×') 501:('not_implemented',), 502:('bad_gateway',), 503:('service_unavailable','unavailable'), 504:('gateway_timeout',), 505:('http_version_not_supported','http_version'), 506:('variant_also_negotiates',), 507:('insufficient_storage',), 509:('bandwidth_limit_exceeded','bandwith'), 510:('not_extended',), 511:('network_authentication_required','network_auth','network_authentication')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
爬取二进制数据
图片、音频、视频这些文件本质上都是由二进制码组成的,所以想要爬取它们,就要拿到它们的二进制码。以爬取百度的站点图标(选项卡上的小图标)为例:
import requests
#向资源URL发送一个GET请求
r = requests.get('https://www.baidu.com/favicon.ico')
with open('favicon.ico','wb') as f:
f.write(r.content)
- 1
- 2
- 3
- 4
- 5
- 6
使用open( )方法,它的第一个参数是要保存文件名(可带路径),第二个参数表示以二进制的形式写入数据。运行结束之后,可以在当前目录下发现保存的名为favicon.ico的图标。同样的,音频和视频也可以用这种方法获取。
文件上传
requests可以模拟提交一些数据。假如某网站需要上传文件,我们也可以实现。
import requests
#以二进制方式读取当前目录下的favicon.ico文件,并将其赋给file
files = {'file':open('favicon.ico','rb')}
#进行上传
r = requests.post('http://httpbin.org/post',files=files)
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
处理Cookies
使用urllib处理Cookies比较复杂,而使用requests处理Cookies非常简单。
1)获取Cookies。
import requests
r = requests.get('https://www.baidu.com')
#打印Cookies对象
print(r.cookies)
#遍历Cookies
for key,value in r.cookies.items():
print(key+'='+value)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
通过响应对象调用cookies属性即可获得Cookies,它是一个RequestCookiesJar类型的对象,然后用items( )方法将其转换为元组组成 的列表,遍历输出每一个Cookies的名称和值。
2)使用Cookies来维持登录状态。以知乎为例,首先登录知乎,进入一个登录之后才可以访问的页面,在浏览器开发者工具中将Headers 中的Cookies复制下来(有时候这样直接复制的Cookies中包含省略号,会导致程序出错,此时可以在Console项下输document.cookie 即可得到完整的Cookie),在程序中使用它,将其设置到Headers里面,然后发送请求。
import requests
headers = {
'Cookie':'_zap=616ef976-1fdb-4b8c-a3cb-9327ff629ff1; _xsrf=0CCNkbCLtTAlz5BfwhMHBHJWW791ZkK6; d_c0=\"AKBQTnFIRhSPTpoYIf6mUxSic2UjzSp4BYM=|1641093994\"; __snaker__id=mMv5F3gmBHIC9jJg; gdxidpyhxdE=E%2BNK7sMAt0%2F3aZ5Ke%2FSRfBRK7B1QBmCtaOwrqJm%2F1ONP3VPItkrXCcMiAX3%2FIsSxUwudQPyuDGO%2BlHGPvNqGqO9bX1%2B58o7wmf%2FZewh8xSPg%2FH3T2HoWsrs7ZhsSGND0C0la%2BXkLIIG5XXV85PxV5g99d%5CMph%2BbkX1JQBGhDnL3N0zRf%3A1641094897088; _9755xjdesxxd_=32; YD00517437729195%3AWM_NI=rMeMx2d5Yt3mg0yHPvuPGTjPnGtjL%2Bn%2FPSBnVn%2FHFAVZnIEABUIPITBdsHmMX1iCHfKauO4qhW%2Bi5bTy12Cg91vrxMPgOHtnaAylN8zk7MFpoTr%2FTeKVo3%2FKSSM6T5cNSGE%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee8bea40f8e7a4b2cf69b3b48fb7c54b979b8fbaf17e93909b91fb338ebaaeadec2af0fea7c3b92ab293abaefb3aa8eb9795b267a5f0b7a9d37eb79089b5e95cae99bc8bcf21aef1a0b4c16696b2e1a9c54b9686a2aac84b828b87b1cc6082bcbda9f0479cefa7a4cb6e89bfbbb0b77bac89e58ab86a98a7ffd3c26dfbefba93fb4794b981a9f766a39fb78dcd34bab5f9aec57cad8cbed0d76f898aa1d4ae41918d83d7d73fa1929da8c837e2a3; YD00517437729195%3AWM_TID=Kji43bLtZbRAAAVABFMu4upmK4C%2BEGQH; KLBRSID=9d75f80756f65c61b0a50d80b4ca9b13|1641268679|1641267986; tst=r; NOT_UNREGISTER_WAITING=1; SESSIONID=lbWS7Y8pmp5qM1DErkXJCahgQwwyl79eT8XAOC6qC7A; JOID=V1wXAUwzD9BQH284PTQMxsZMqrkrXmuHBio3Bk1cfuMhV1x9fiHKBjYcaD44XxiWm2kKD5TjJvk-7iTeM3d6aYA=; osd=VVoQAk0xCddTHm0-OjcNxMBLqbgpWGyEBygxAU5dfOUmVF1_eCbJBzQabz05XR6RmGgICZPgJ_s46SffMXF9aoE=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1640500881,1641093994,1641267987; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1641268678',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'Host':'www.zhihu.com'
}
r = requests.get('https://www.zhihu.com/people/xing-fu-shi-fen-dou-chu-lai-de-65-18',headers=headers)
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行之后,结果中包含了登录后的内容,说明获取登录状态成功。
3)也可以通过cookies参数来设置,不过这样就需要构造RequestCookieJar对象,而且需要分割以下cookies,相对繁琐,但效果是一 样。
import requests
cookies ='_zap=616ef976-1fdb-4b8c-a3cb-9327ff629ff1; _xsrf=0CCNkbCLtTAlz5BfwhMHBHJWW791ZkK6; d_c0=\"AKBQTnFIRhSPTpoYIf6mUxSic2UjzSp4BYM=|1641093994\"; __snaker__id=mMv5F3gmBHIC9jJg; gdxidpyhxdE=E%2BNK7sMAt0%2F3aZ5Ke%2FSRfBRK7B1QBmCtaOwrqJm%2F1ONP3VPItkrXCcMiAX3%2FIsSxUwudQPyuDGO%2BlHGPvNqGqO9bX1%2B58o7wmf%2FZewh8xSPg%2FH3T2HoWsrs7ZhsSGND0C0la%2BXkLIIG5XXV85PxV5g99d%5CMph%2BbkX1JQBGhDnL3N0zRf%3A1641094897088; _9755xjdesxxd_=32; YD00517437729195%3AWM_NI=rMeMx2d5Yt3mg0yHPvuPGTjPnGtjL%2Bn%2FPSBnVn%2FHFAVZnIEABUIPITBdsHmMX1iCHfKauO4qhW%2Bi5bTy12Cg91vrxMPgOHtnaAylN8zk7MFpoTr%2FTeKVo3%2FKSSM6T5cNSGE%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee8bea40f8e7a4b2cf69b3b48fb7c54b979b8fbaf17e93909b91fb338ebaaeadec2af0fea7c3b92ab293abaefb3aa8eb9795b267a5f0b7a9d37eb79089b5e95cae99bc8bcf21aef1a0b4c16696b2e1a9c54b9686a2aac84b828b87b1cc6082bcbda9f0479cefa7a4cb6e89bfbbb0b77bac89e58ab86a98a7ffd3c26dfbefba93fb4794b981a9f766a39fb78dcd34bab5f9aec57cad8cbed0d76f898aa1d4ae41918d83d7d73fa1929da8c837e2a3; YD00517437729195%3AWM_TID=Kji43bLtZbRAAAVABFMu4upmK4C%2BEGQH; KLBRSID=9d75f80756f65c61b0a50d80b4ca9b13|1641268679|1641267986; tst=r; NOT_UNREGISTER_WAITING=1; SESSIONID=lbWS7Y8pmp5qM1DErkXJCahgQwwyl79eT8XAOC6qC7A; JOID=V1wXAUwzD9BQH284PTQMxsZMqrkrXmuHBio3Bk1cfuMhV1x9fiHKBjYcaD44XxiWm2kKD5TjJvk-7iTeM3d6aYA=; osd=VVoQAk0xCddTHm0-OjcNxMBLqbgpWGyEBygxAU5dfOUmVF1_eCbJBzQabz05XR6RmGgICZPgJ_s46SffMXF9aoE=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1640500881,1641093994,1641267987; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1641268678'
jar = requests.cookies.RequestsCookieJar()
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'Host':'www.zhihu.com'
}
for cookie in cookies.split(';'):
key,value = cookie.split('=',1)
jar.set(key,value)
r = requests.get('https://www.zhihu.com/people/xing-fu-shi-fen-dou-chu-lai-de-65-18',headers=headers)
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
会话维持
通过调用get( )或post( )等方法可以做到模拟网页的请求,但是这实际上是相当于不同的会话,也就是说相当于你用了两个浏览器打开不同的页面。如果第一个请求利用post( )方法登录了网站,第二次想获取登录成功后的自己的个人信息,又使用了一次get( )方法取请求个人信息,实际上,这相当于打开了两个浏览器,所以是不能成功的获取到个人信息的。为此,需要会话维持,你可以在两次请求时设置一样的Cookies,但这样很繁琐,而通过Session类可以很轻松地维持一个会话。
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
首先通过requests打开一个会话,然后通过该会话发送了一个get请求,该请求用于向cookies中设置参数number,参数值为123456789;接着又使用该发起了一个get请求,用于获取Cookies,然后打印获取的内容。

成功获取。
SSL证书验证
requests还提供了证书验证功能,当发送HTTP请求的时候,它会检查SSL证书,我们可以使用verify参数控制是否检查SSL证书。
1)请求一个HTTPS网站时,如果该网站的证书没有被CA机构信任,程序将会出错,提示SSL证书验证错误。对此,只需要将verify参数 设置为False即可。如下:
import requests
resposne = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
- 1
- 2
- 3
- 4
也可以指定一个本地证书用作客户端证书,它可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组。
import requests
#本地需要有crt和key文件(key必须是解密状态,加密状态的key是不支持的),并指定它们的路径,
response = requests.get('https://www.12306.cn',cert('/path/server.crt','/path/key'))
print(response.status_code)
- 1
- 2
- 3
- 4
- 5
2)在请求SSL证书不被CA机构认可的HTTPS网站时,虽然设置了verify参数为False,但程序运行可能会产生警告,警告中建议我们给它 指定证书,可以通过设置忽略警告的方式来屏蔽这个警告:
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
- 1
- 2
- 3
- 4
- 5
- 6
或者通过捕获警告到日志的方式忽略警告:
- 1
- 2
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
- 1
- 2
- 3
- 4
- 5
- 6
代理设置
对于某些网站,在测试的时候请求几次,能正常获取内容。但是一旦开始大规模、频繁地爬取,网站可能会弹出验证码,或者跳转到登录验证页面,更有甚者可能会直接封禁客户端的IP,导致一定时间内无法访问。为了防止这种情况,我们需要使用代理来解决这个问题,这就需要用到proxies参数。
1)设置代理
import requests
proxies = {
#该代理服务器在免费代理网站上得到的,这样的网站有很多
'http': 'http://161.35.4.201:80',
'https': 'https://161.35.4.201:80'
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

可以发现,我们使用的是代理服务器进行访问的。
2)如果代理需要使用HTTP Basic Auth,可以使用类似http://user:password@host:port这样的语法来设置代理。
import requests
proxies = {
"http":"http://user:password@161.35.4.201:80"
}
r = requests.get("https://www.taobao.com",proxies=proxies)
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3)除了基本的HTTP代理外,requests还支持SOCKS协议的代理。首先需要安装socks这个库:
pip3 install 'requests[socks]'
- 1
- 2
import requests
proxies = {
'http':'socks5://user:password@host:port',
'https':'socks5://user:password@host:port'
}
request.get('https://www.taobao.com',proxies=proxies)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后就可以使用SOCKS协议代理了
import requests
proxies = {
'http':'socks5://user:password@host:port',
'https':'socks5://user:password@host:port'
}
requests.get('https://www.taobao.com',proxies=proxies)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才可能收到响应,甚至到最后收不到响应而报错。为了应对这种情况,应设置一个超时时间,这个时间是计算机发出请求到服务器返回响应的时间,如果请求超过了这个超时时间还没有得到响应,就抛出错误。这就需要使用timeout参数实现,单位为秒。
1)指定请求总的超时时间
import requests
#向淘宝发出请求,如果1秒内没有得到响应,则抛出错误
r = requests.get('https://www.taobao.com',timeout=1)
print(r.status_code)
- 1
- 2
- 3
- 4
- 5
2)分别指定超时时间。实际上,请求分为两个阶段:连接(connect)和读取(read)。如果给timeout参数指定一个整数值,则超时时 间是这两个阶段的总和;如果要分别指定,就可以传入一个元组,连接超时时间和读取超时时间:
import requests
#向淘宝发出请求,如果连接阶段5秒内没有得到响应或读取阶段30秒内没有得到响应,则抛出错误
r = requests.get('https://www.taobao.com',timeout=(5,30))
print(r.status_code)
- 1
- 2
- 3
- 4
- 5
3)如果想永久等待,可以直接timeout设置为None,或者不设置timeout参数,因为它的默认值就是None。
import requests
#向淘宝发出请求,如果连接阶段5秒内没有得到响应或读取阶段30秒内没有得到响应,则抛出错误
r = requests.get('https://www.taobao.com',timeout=None))
print(r.status_code)
- 1
- 2
- 3
- 4
- 5
身份验证
访问某网站时,可能会遇到如下的验证页面:
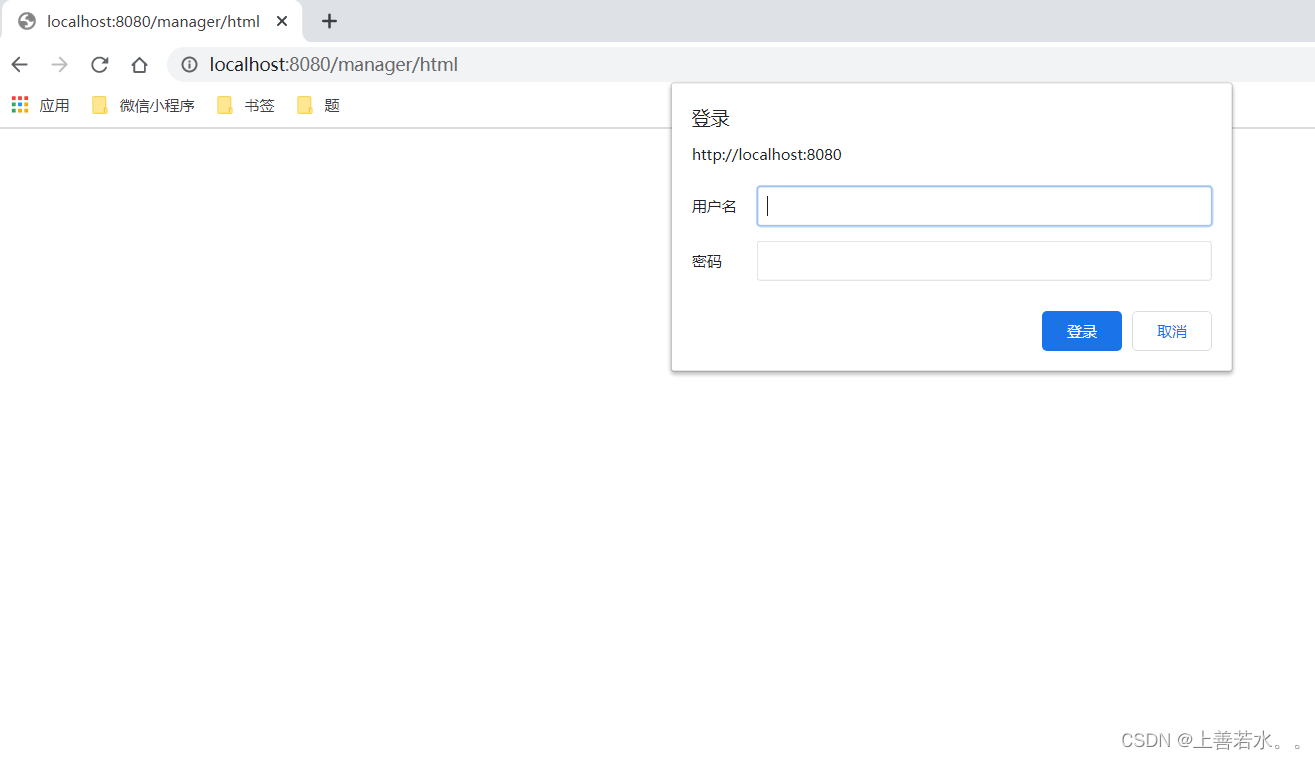
1)此时可以使用requests自带的身份验证功能,通过HTTPBasicAuth类实现。
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:8080/manager/html',auth=HTTPBasicAuth('admin','123456'))
print(r.status_code)
- 1
- 2
- 3
- 4
- 5
如果用户名和密码正确的话,返回200状态码;如果不正确,则返回401状态码。也可以不使用HTTPBasicAuth类,而是直接传入一个 元组,它会默认使用HTTPBasicAuth这个类来验证。
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:8080/manager/html',auth=('admin','123456'))
print(r.status_code)
- 1
- 2
- 3
- 4
- 5
2)requests还提供了其他验证方式,如OAuth验证,不过需要安装oauth包,安装命令如下:
pip3 install requests_oauthlib
- 1
- 2
使用OAuth验证的方法如下:
import requests
from requests_oauthlib import OAuth1
url = 'https://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1("YOUR_APP_KEY","YOUR_APP_SECRET","USER_OAUTH_TOKEN","USER_OAUTH_TOKEN_SECRET")
requests.get(url,auth=auth)
- 1
- 2
- 3
- 4
- 5
- 6
Prepared Request
在学习urllib库时,发送请求如果需要设置请求头,需要通过一个Request对象来表示。在requests库中,存在一个与之类似的类,称为Prepared Request。
from requests import Request,Session
url = 'http://httpbin.org/post'
data = {
'name':'germey'
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0'
}
s = Session()
req = Request('POST',url,data=data,headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这里引入了Request,然后用url、data和headers参数构造了一个Request对象,这时需要再调用Session的prepare_request( )方法将其转换为一个Prepared Request对象,然后调用send( )方法发送。这样做的好处时:可以利用Request将请求当作独立的对象来看待,这样在进行队列调度时会非常方便,后面会用它来构造一个Request队列。
题外话
初入计算机行业的人或者大学计算机相关专业毕业生,很多因缺少实战经验,就业处处碰壁。下面我们来看两组数据:
-
2023届全国高校毕业生预计达到1158万人,就业形势严峻;
-
国家网络安全宣传周公布的数据显示,到2027年我国网络安全人员缺口将达327万。
一方面是每年应届毕业生就业形势严峻,一方面是网络安全人才百万缺口。
6月9日,麦可思研究2023年版就业蓝皮书(包括《2023年中国本科生就业报告》《2023年中国高职生就业报告》)正式发布。
2022届大学毕业生月收入较高的前10个专业
本科计算机类、高职自动化类专业月收入较高。2022届本科计算机类、高职自动化类专业月收入分别为6863元、5339元。其中,本科计算机类专业起薪与2021届基本持平,高职自动化类月收入增长明显,2022届反超铁道运输类专业(5295元)排在第一位。
具体看专业,2022届本科月收入较高的专业是信息安全(7579元)。对比2018届,电子科学与技术、自动化等与人工智能相关的本科专业表现不俗,较五年前起薪涨幅均达到了19%。数据科学与大数据技术虽是近年新增专业但表现亮眼,已跻身2022届本科毕业生毕业半年后月收入较高专业前三。五年前唯一进入本科高薪榜前10的人文社科类专业——法语已退出前10之列。

“没有网络安全就没有国家安全”。当前,网络安全已被提升到国家战略的高度,成为影响国家安全、社会稳定至关重要的因素之一。
网络安全行业特点
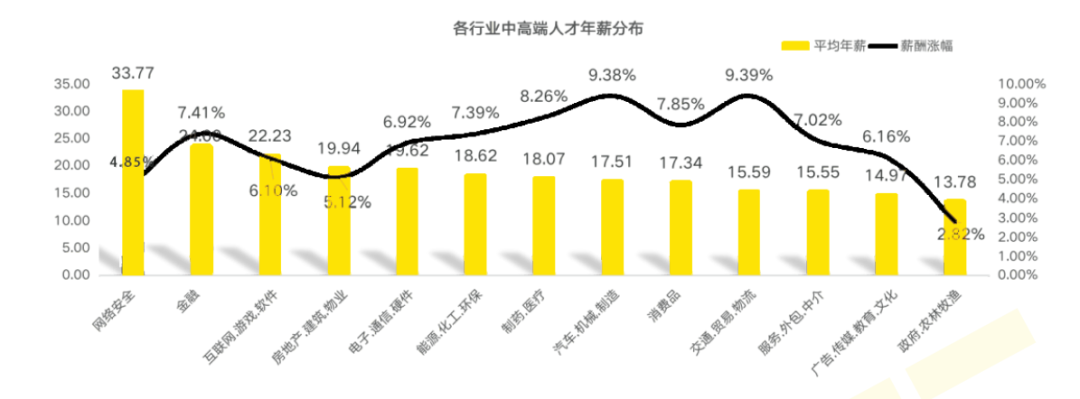
1、就业薪资非常高,涨薪快 2021年猎聘网发布网络安全行业就业薪资行业最高人均33.77万!
2、人才缺口大,就业机会多
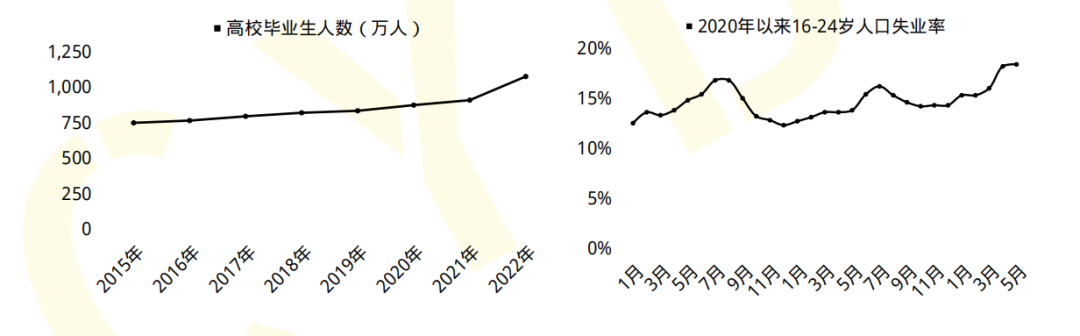
2019年9月18日《中华人民共和国中央人民政府》官方网站发表:我国网络空间安全人才 需求140万人,而全国各大学校每年培养的人员不到1.5W人。猎聘网《2021年上半年网络安全报告》预测2027年网安人才需求300W,现在从事网络安全行业的从业人员只有10W人。
行业发展空间大,岗位非常多
网络安全行业产业以来,随即新增加了几十个网络安全行业岗位︰网络安全专家、网络安全分析师、安全咨询师、网络安全工程师、安全架构师、安全运维工程师、渗透工程师、信息安全管理员、数据安全工程师、网络安全运营工程师、网络安全应急响应工程师、数据鉴定师、网络安全产品经理、网络安全服务工程师、网络安全培训师、网络安全审计员、威胁情报分析工程师、灾难恢复专业人员、实战攻防专业人员…
职业增值潜力大
网络安全专业具有很强的技术特性,尤其是掌握工作中的核心网络架构、安全技术,在职业发展上具有不可替代的竞争优势。
随着个人能力的不断提升,所从事工作的职业价值也会随着自身经验的丰富以及项目运作的成熟,升值空间一路看涨,这也是为什么受大家欢迎的主要原因。
从某种程度来讲,在网络安全领域,跟医生职业一样,越老越吃香,因为技术愈加成熟,自然工作会受到重视,升职加薪则是水到渠成之事。
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
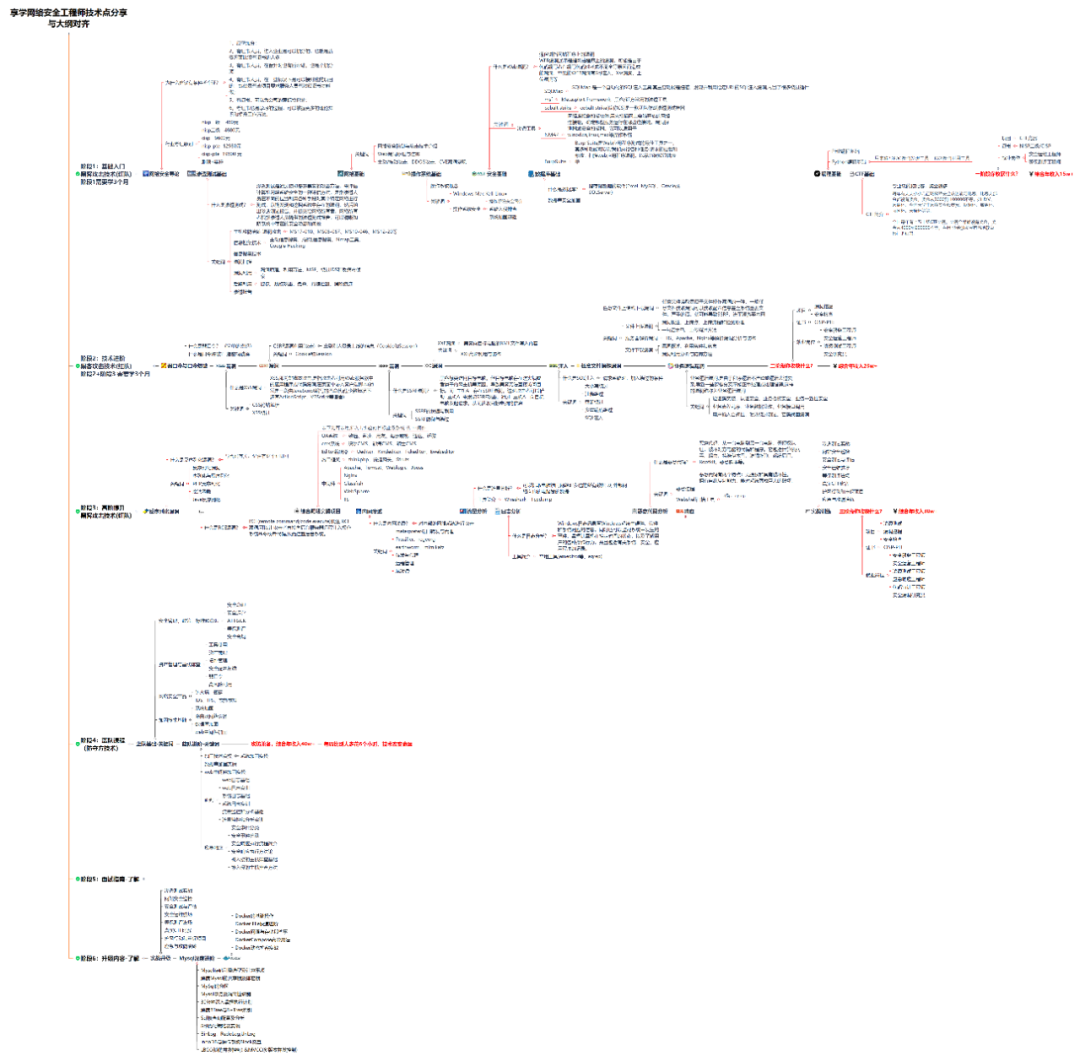
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

