- 1Verilog电路设计语法基础_verilog语言中always是什么意思
- 2netlink机制_/proc/net/netlink
- 3FPGA结构:LATCH(锁存器)和 FF(触发器)介绍_ff en触发器
- 4Spark on Hive 和 Hive on Spark的区别与实现_hive on spark 和spark on hive
- 5SQL数据插入操作详解,让你不再迷茫_sql插入数据
- 6深度学习保姆级别之NLP入门文本分类之情感分析_nlp 文本情感分类项目
- 7C++:关联式容器:unordered_map_c++ unordered_map
- 8Oh! Binlog还能这样用之Canal篇_canal binlog
- 9python requests v2.22.0源码阅读_python requests-2.22.0 依赖的包
- 10C++11新特性:STL中的无序关联容器unordered_map的底层实现和用法_unordered_map扩容
Transfomer,VIT,Swin-TR,DETR,SETR的网络结构以及改进思路_setr改进的网络有哪些
赞
踩
1、Transformer结构
Transformer的结构和Attention模型一样,Transformer模型中也采用了 encoer-decoder 架构。但其结构相比于Attention更加复杂,论文中encoder层由6个encoder堆叠在一起,decoder层也一样。
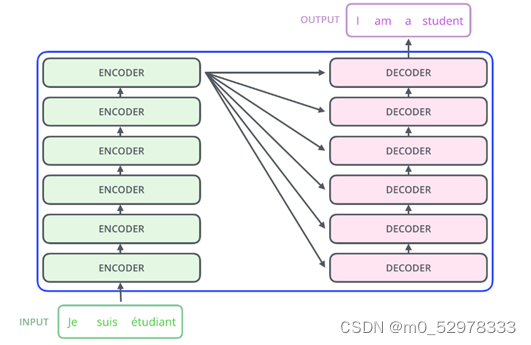
每一个encoder和decoder的内部结构如下图:
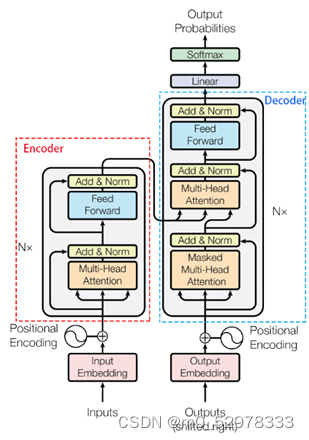
encoder,包含两层,一个self-attention层和一个前馈神经网络,self-attention能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。
decoder也包含encoder提到的两层网络,但是在这两层中间还有一层attention层,帮助当前节点获取到当前需要关注的重点内容
2、VIT的网络结构
VIT的网络结构如下所示
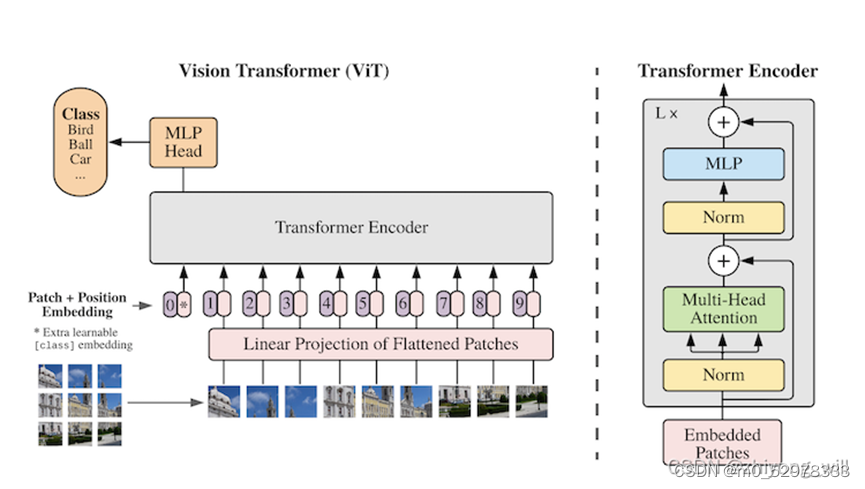
ViT模型的网络结构如上图的右半部分所示,与原始的Transformer中的Encoder不同的是Norm所在的位置不同,类似BERT模型中[class]标记位的设置,ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位,并且该位置的Transformer Encoder输出作为图像特征。
Vision Transformer(ViT)将输入图片拆分成16×16个patches,每个patch做一次线性变换降维同时嵌入位置信息,然后送入Transformer。类似BERT[CLS]标记位的设计,在ViT中,在输入序列前增加了一个额外可学习的[class]标记位,并将其最终的输出作为图像特征,最后利用MLP做最后的分类,如上图中的左半部分所示,其中,[class]标记位为上图中Transformer Encoder的0*。
3、Swin-TR的网络结构
Swin-TR引入了窗口注意力机制,通过将图像分为若干窗口,以窗口为单位进行注意力计算,实现对大图像的高效建模。这种结构使得Swin-TR在处理大图像时具有明显的优势。
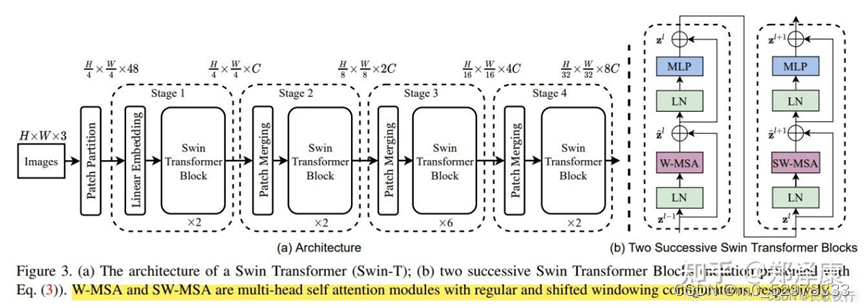
4、SETR的网络结构
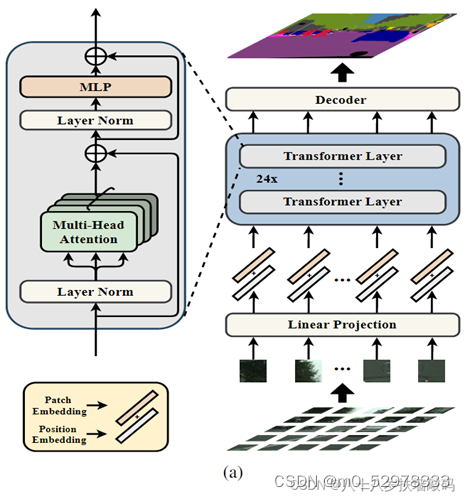
模型整体结构如下图所示,