
- 1网安学习(B站小迪安全)_小迪安全2022百度网盘
- 2BART论文要点解读:看这篇就够了
- 3精心整理20+Python实战案例(附源码、数据)
- 4SQL中的升序和降序_select语句升序降序
- 5Java笔记(入门篇)
- 6向量数据库与图数据库:理解它们的区别_向量数据库 图数据库 区别
- 7Redis发布订阅:美丽的陷阱与不宜之境_redis 订阅发布 可靠吗
- 8云盾防Ddos文献之应对篇 ——DDoS防御方案
- 9but there is no HDFS_NAMENODE_USER defined. Aborting operation.
- 10java调用Hanlp分词器获取词性;自定义词性字典_java hanlp
InstructABSA基于指示学习的情感分析方法
赞
踩
这篇文章还没有正式发出,只是罗列了大概内容。文章主要应用指示学习的思想,首先介绍下指示学习。指示学习是谷歌Deepmind的Quoc V.Le团队在2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》文章中提出的思想。指示学习的目的是去挖掘语言模型本身具备的知识。Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。指示学习的优点是它经过多任务的微调后,也能够在其他任务上做zero-shot。
论文题目(Title):InstructABSA: Instruction Learning for Aspect Based Sentiment Analysis
研究问题(Question):ATE方面术语提取,ATSC方面术语情感分类,Joint Task联合任务

主要贡献(Contribution):
1. 引入了指示性学习。
2. 参数量200M,相比于其他效果相当的模型参数量有了数量级的减少。
3. 评估性能时用了跨域评估,即用一个数据集进行训练,另一个不同的数据集进行测试,证明了跨域评估具有局限性。
研究思路(Idea):通过给训练样本添加指示性的指令,让模型做出正确的判断。
研究方法(Method):为每个训练样本引入了积极的、消极的和中性的例子,并为每个ABSA子任务指导调整模型(tk - instruction Base),产生了显著的性能改进。
研究过程(Process):
1.数据集(Dataset):Sem Eval 2014 dataset
2.评估指标(Evaluation):F1,accuracy
3.实验结果(Result):
ATE:F1 laptops 4.37%
restaurants 7.31%
ATSC:acc laptops 2.16%
restaurants -0.57%
JT:F1 laptops 8.63%
restaurants 1.4%
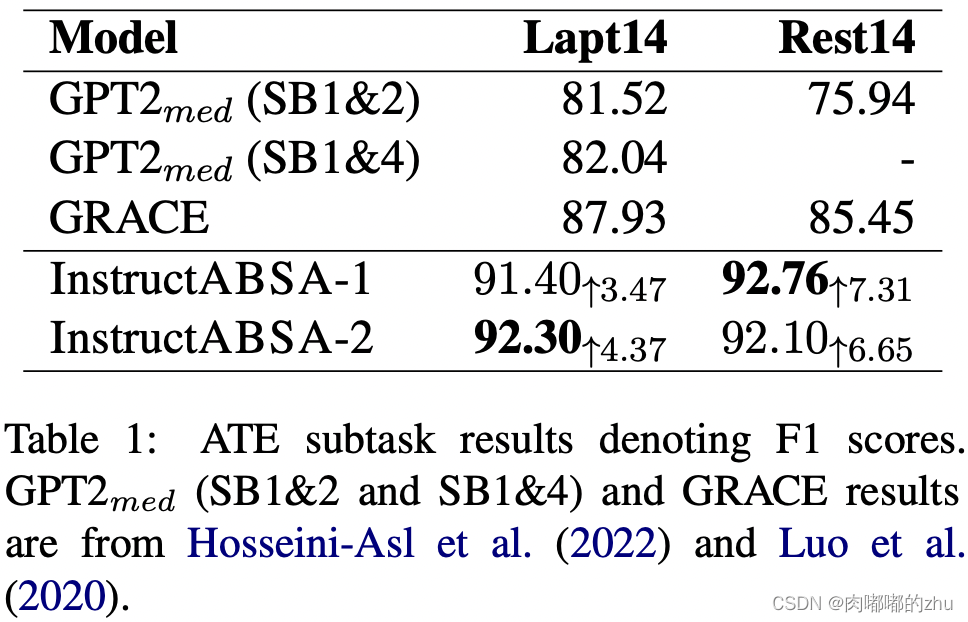
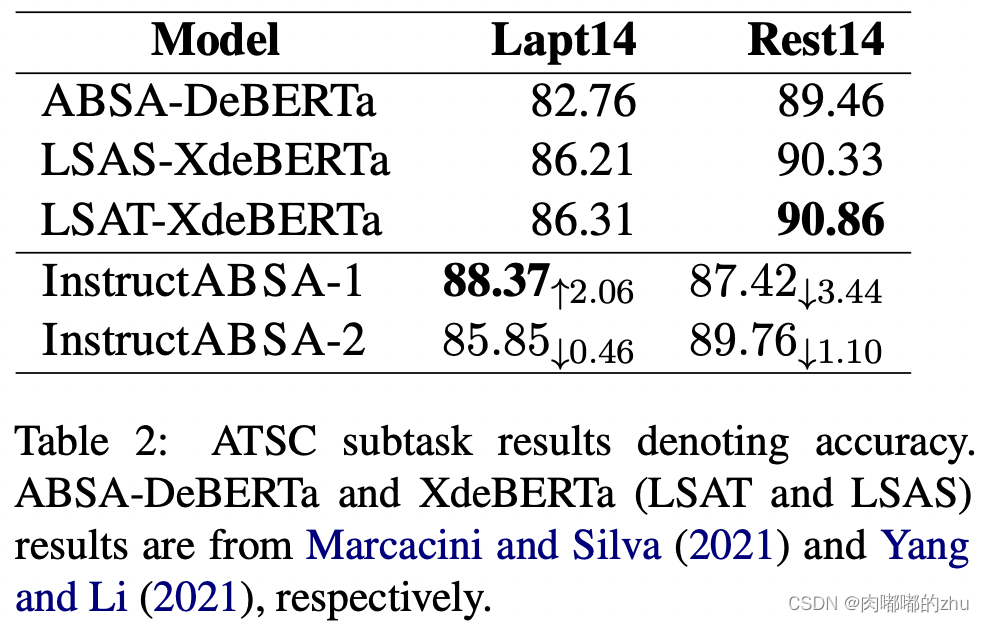
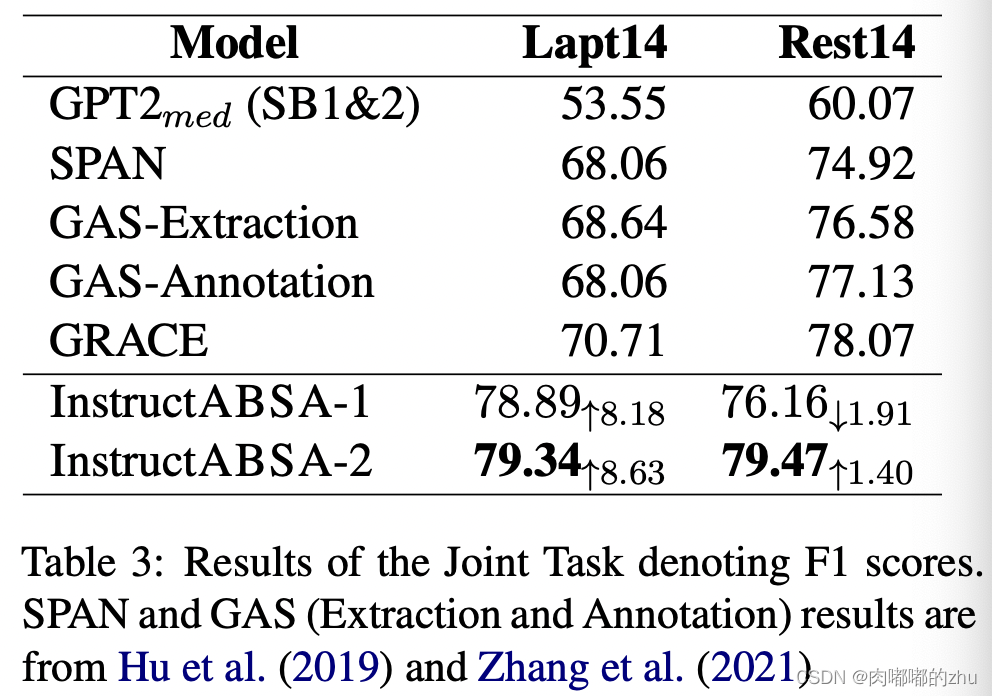
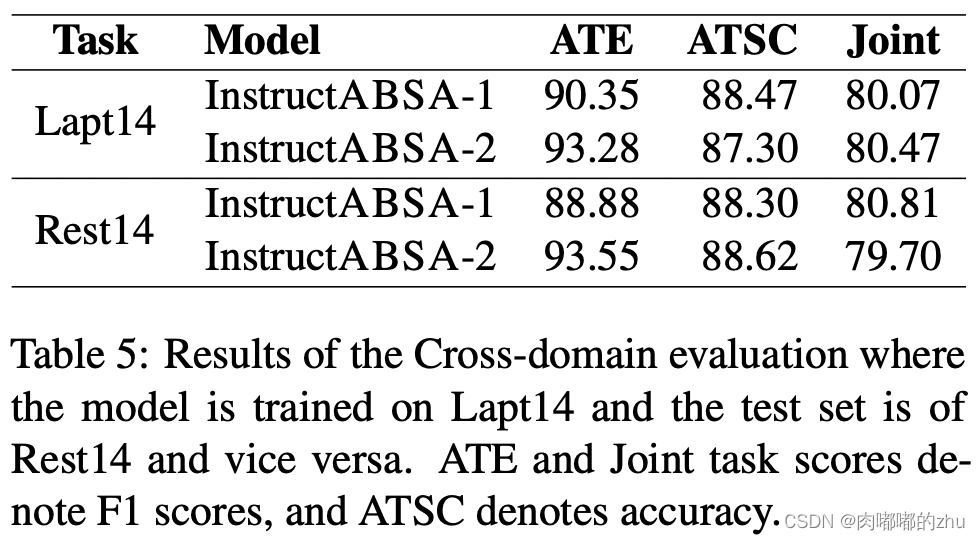
总结(Conclusion):大部分结果时优于其他的,只有一个略低,证明了指示学习的有效性。可以考虑应用,还有提示学习,后续可以参考使用。文中实验结果表明,Instruct1,Instruct2带来的结果有正向有反向,两者结合提升了总体效果,其中解释还未给出。

