
- 1漏洞&修复规范描述_httplimitreqmodule and httplimitzonemodule
- 2短视频seo抖音矩阵源码开发搭建技术解析_抖音矩阵一键发布 用的什么接口
- 3复旦微JFM7VX690计算后IO接口模块,用于雷达信号处理、数据处理等需要高速密集计算的应用场景
- 4GPT实战系列-LangChain如何构建基通义千问的多工具链_通义千问 集成langchain好多样例跑不通
- 5微信公众号&小程序 -- 获取并解密用户数据(获取openId、unionId)
- 6android studio简单实现登录注册界面的跳转,新手教学android期末项目点击简单跳转界面的实现_android登录跳转简单界面
- 7chatGPT与传统搜索引擎的比较_chatgpt跟csdn对比
- 8OAuth 2.1 带来了哪些变化_说透oauth 2.1
- 9inpaint-anything:分割任何东西遇到图像修复_inpaint anything macos 12错误
- 10PX4 OffBoard Control_offboard_control
CLIP大模型图文检索——原理解读及代码实现_图文检索代码
赞
踩
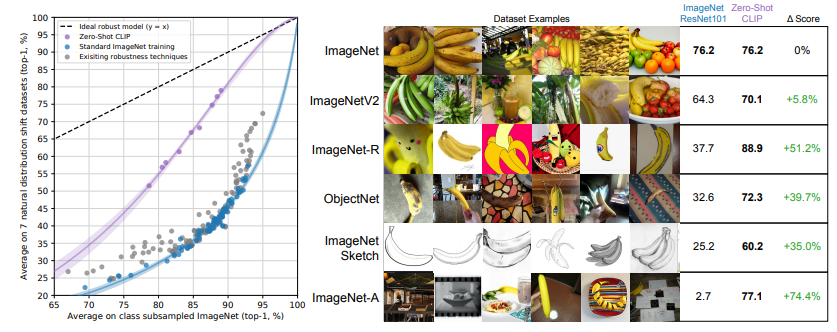
一. 核心思想
通过自然语言处理获得的监督信号可用于训练迁移效果出色的视觉模型。本论文的作者团队构建了一个庞大的图像文本配对数据集,其中包含400 million个图片文本的配对。利用最大规模的ViT-large模型,他们提出了CLIP(Contrastive Language-Image Pre-training)方法,这是一种有效的从自然语言监督中学习的方法。研究团队在30个数据集上进行了实验,结果显示CLIP模型的性能与之前的有监督模型相当,甚至更好。
二. 模型实现
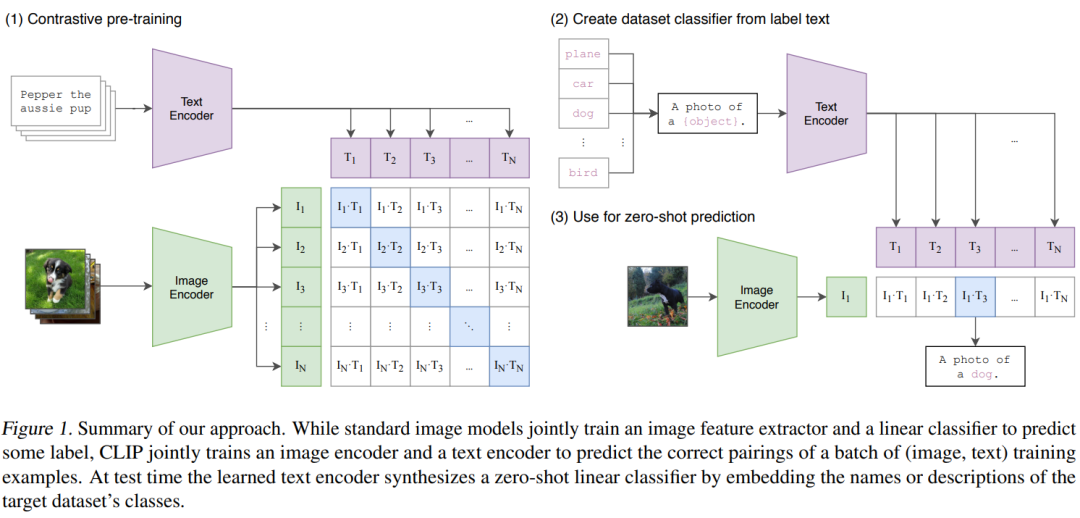
(1)CLIP的训练过程
CLIP的训练过程是基于图像和文字配对的数据,其中图像输入经过图像编码器得到特征,而文本输入则经过文本编码器得到特征。每个训练批次包含n个图像-文本配对,从而获得n个图像特征和n个文本特征。随后,利用这些特征进行对比学习,其中对比学习的灵活性要求定义正样本和负样本。在这里,配对的图像-文本对即为正样本,因为它们描述的是同一物体。在特征矩阵中,对角线上的元素表示正样本,而非对角线上的元素则表示负样本。有了正负样本,模型便可以通过对比学习的方式进行无监督训练。这种无监督训练方式需要大量的训练数据支持。
(2)CLIP的推理过程
在预训练之后,CLIP模型只能得到图像和文本的特征,而没有分类头。为了进行分类,作者提出了一种利用自然语言的方法,即"prompt template"。例如,对于ImageNet的类别,可以将其转化为类似"A photo of a {object}"这样的句子,对于ImageNet的1000个类别,就可以生成1000个这样的句子。然后,通过之前预训练好的文本编码器,可以得到这1000个句子对应的文本特征。虽然也可以直接使用类别单词提取文本特征,但在预训练阶段,图像与文本的配对是以句子形式出现的,因此在推理阶段使用单词效果会下降。推理时,将需要分类的图像送入图像编码器以获取特征,然后计算图像特征与1000个文本特征的余弦相似度,选择最相似的文本特征对应的句子,从而完成分类任务。CLIP模型不仅局限于这1000个类别,任何类别都可以进行分类,因此彻底摆脱了分类标签的限制,无需在训练和推理阶段提前定义好标签列表。
(3)CLIP的损失函数
CLIP的损失函数使用了对称的损失函数,其中包括图像编码器、文本编码器、学习的投影矩阵、以及温度参数。具体步骤包括提取各模态的特征表示,计算它们之间的余弦相似度,然后应用交叉熵损失函数计算图像和文本的损失。通过将两个损失的平均值作为最终损失,得到了模型的整体损失。
- # Image encoder - ResNet or Vision Transformer
- # Text encoder - CBOW or Text Transformer
- # Input: minibatch of aligned images I[n, h, w, c] and minibatch of aligned text T[n, 1]
- # Parameters: W_i[d_i, d_e] learned projection of image to embed, W_t[d_t, d_e] learned projection of text to embed, t learned temperature parameter
- # Extract feature representations of each modality
- I_f = image_encoder(I) # [n, d_i]
- T_f = text_encoder(T) # [n, d_t]
- # Joint multimodal embedding [n, d_e]
- I_e = 1/2 * normalize(np.dot(I_f, W_i), axis=1)
- T_e = 1/2 * normalize(np.dot(T_f, W_t), axis=1)
- # Scaled pairwise cosine similarities [n, n]
- logits = np.dot(I_e, T_e.T) * np.exp(t)
- # Symmetric loss function
- labels = np.arange(n)
- loss_i = cross_entropy_loss(logits, labels, axis=0)
- loss_t = cross_entropy_loss(logits, labels, axis=1)
- loss = (loss_i + loss_t) / 2

模型接收两个输入,一个是图片,一个是文本。图片的维度为[n,h,w,c],文本的维度为[n,l],其中l是序列长度。这些输入分别通过图片编码器和文本编码器提取特征,然后经过一个投射层学习如何从单模态变为多模态。投射完成后,对特征进行l2范数归一化,得到最终用于对比的特征。接下来,计算余弦相似度得到对比学习的logits。最后,使用对称的损失函数计算loss,其中正样本为对角线上的元素。损失函数包括图片损失和文本损失,将两者加起来并取平均。这种操作在对比学习中很常见,是一种对称的目标函数。
三.API代码实现
论文地址:https://arxiv.org/pdf/2103.00020.pdf
代码地址:https://github.com/openai/CLIP
文末可快速免费获取论文和代码~~~
- import torch
- import clip
- from PIL import Image
- device = "cuda" if torch.cuda.is_available() else "cpu"
- model, preprocess = clip.load("ViT-B/32", device=device)
- image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
- text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
- with torch.no_grad():
- image_features = model.encode_image(image)
- text_features = model.encode_text(text)
- logits_per_image, logits_per_text = model(image, text)
- probs = logits_per_image.softmax(dim=-1).cpu().numpy()
- print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
四.论文实验总结
在CLIP预训练完成后,系统具备两个编码器:一个用于图像,一个用于文本。在推理过程中,给定一张图片,通过图像编码器可得到该图片的特征。对于文本方面的输入,则包括用户感兴趣的标签,例如"plane"、"car"、"dog"等。这些标签经过prompt工程处理,转换成对应的句子,如"A photo of a plane"、"A photo of a dog"等。一旦得到这些句子,它们就会被送入文本编码器,以获取相应的文本特征。假设有三个标签,分别是"plane"、"car"、"dog",那么通过文本编码器得到对应的文本特征。接下来,将这三个文本特征与图片的特征进行余弦相似度计算,得到相似度后再经过softmax处理,得到一个概率分布。其中概率最大的那个句子,就是最可能描述这张图片的句子。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/503276
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

