
- 1基于GSYVideoPlayer自定义布局结合RecyclerView高仿抖音实现上下滑动双击屏幕点赞/单击暂停,拖动进度条实时改变时间以及进度条放大_android gsyvideoplayer
- 2阿里云AIoT云端一体:迎接云原生+低代码时代的到来_云端平台与低代码的联合运行
- 3Hystrix熔断器使用时的三个参数介绍_hystrix熔断参数
- 4ffmpeg视频剪辑利器_ffmpeg开发的剪辑
- 5详解SDRAM基本原理以及FPGA实现读写控制(一)
- 6Git 如何快速的丢弃/抛弃/回滚本地的所有未stage的改动_git 丢弃stage
- 7Pycharm使用Git
- 8论文必备——将Excel中的图转化为高清矢量图eps_excel表怎么转成矢量图
- 9javaEE002.03 js的三种嵌入方式_js 方法嵌入方法
- 10git 001--建本地仓库和远程仓库和拉代码_git创建本地仓库拉远程代码
人物 | 所罗门诺夫:大语言模型的先知
赞
踩

1956年达特茅斯会议部分参会者。左2 罗切斯特,左3所罗门诺夫,左4 明斯基,右2麦卡锡,右1香农

导读:
目前最火热的大模型公司莫过于OpenAI。OpenAI首席科学家Ilya Sutskever在接受采访时不断暗示,next token prediction是GPT系列大模型成功的关键,但直到2023年8月,他在伯克利理论计算机科学研究所演讲时才明确透露,GPT的数学依据是所罗门诺夫归纳法(Solomonoff Induction)。
那么,所罗门诺夫归纳法是什么? 其对大模型研究有何重要意义?今年正值所罗门诺夫归纳法诞生60周年,人工智能学者尼克,撰写万字长文,解释所罗门诺夫归纳法为何是大语言模型的理论基础,如何解释GPT的核心机制next token prediction。
与此同时,尼克在文章中旁征博引,也介绍了苏联数学家柯尔莫哥洛夫和列文以及美国理论计算机科学家蔡廷等的独立贡献。最后,本文还讨论了这一理论近来的进展、在人工智能领域中可能的应用以及哲学涵义。
对人工智能感兴趣的读者朋友,不要错过这篇文章。(全文1.3万字,读完需约30分钟,听完约50分钟。)
尼克 | 撰文
科学发展有时理论先行,实践随后;有时则是工程或实验先出成果,理论解释慢慢到来;但也有时是理论和实践纠缠在一起。
自然语言处理(NLP)的历史较为曲折,更像最后一种情况。大语言模型,作为NLP的最新进展,除了理论和实践外,还夹杂着商业,这使得澄清历史更加困难。随着大语言模型在工程上的不断进展,有理论意识的工程师们企图寻找其数学基础,以求为大模型的成功提供解释。但很多脱离第一性原理的观察和拟合实在算不上理论基础,反而徒劳为工程师们增加了更多的困惑。
事实上,特立独行的数学家所罗门诺夫(Ray Solomonoff,1926年-2009年)在1960年代初期的天才贡献已经为大模型奠定了数学基础。他的原创理论开始被重新发现,至今对工程实践仍具指导作用,并可能为未来指明方向。所罗门诺夫可算得大语言模型的先知。
1956年麦卡锡(John McCarthy,1927年-2011年)和明斯基(Marvin Lee Minsky,1927年—2016年)牵头,在贝尔实验室的香农(Claude Elwood Shannon,1916年—2001年)和IBM的罗切斯特(Nathaniel Rochester, 1919年—2001年)支持下在麦卡锡当时任教的达特茅斯学院召开了人工智能夏季研讨会。这次会议标志人工智能作为一门独立学科的建立。会议聚集了一群来自多个不同学科、年轻且野心勃勃的学者。
最认真对待这个会议的就是所罗门诺夫。和其他来来往往的参会者不同,所罗门诺夫在达特茅斯待了整整一个暑假。他1951年在芝加哥大学跟随费米主修物理,只得了硕士就离开象牙塔,转往美国东北部(波士顿和纽约一带)开始了他半工半学、快乐但并不富贵的一生。在芝加哥求学期间,对他影响最大的是哲学家卡尔纳普(Rudolf Carnap,1891年-1970年)。卡尔纳普那时的主要兴趣是概率论和归纳推理,思想和成果都体现在他1950年出版的《概率的逻辑基础》(Logical Foundation of Probability)一书中(见Carnap-1950),所罗门诺夫深研此书,归纳推理遂成为他毕生的研究方向。

所罗门诺夫(1926年7月25日-2009年12月7日)
有意思的是,神经网络的奠基者之一皮茨(Walter Pitts,1923年-1969年)也受惠于卡尔纳普。而另一位人工智能的开拓者司马贺(Herbert Simon,1916年-2001年)在他的回忆录里讲到自己在芝加哥时听过卡尔纳普的数理逻辑课,从而开始萌生对机器定理证明以及更广泛的智能问题的兴趣。这么说来,人工智能的两大流派——逻辑和神经网络——都受教于卡尔纳普(见尼克-2021)。
所罗门诺夫1952年左右结识了明斯基和麦卡锡,那时两人还都是普林斯顿大学数学系的博士生。虽然丘奇(Alonzo Church)在那里坐镇逻辑学,但明斯基和麦卡锡的博士论文却都不是关于逻辑的,不过他们毫无疑问都受到了逻辑的强烈熏陶,刚出道时都聚焦逻辑,尤其是递归函数的研究。当时逻辑在美国大学的数学系是新兴学科。递归函数作为数理逻辑的子学科,逐渐演变成现在的可计算性理论,并进一步衍生出计算复杂性。明斯基1967年还写过一本早期颇有影响的计算理论教科书Computation:Finite and Infinite Machines(见Minsky-1967),在麻省理工还带过几个专做计算理论的学生,其中曼纽尔· 布鲁姆(Manuel Blum)后来因为计算复杂性和密码学的贡献得了图灵奖。明斯基所谓“AI孵化出计算理论”的说法不无道理。
1953年夏天,已经博士毕业的麦卡锡和即将博士毕业的明斯基都在贝尔实验室工作,他们都围绕着因为信息论而声名雀起的香农。香农当时的兴趣则是图灵机以及是否可用图灵机作为智能活动的理论基础。那时名气更大的是更长一辈的维纳,他刚出版了一本颇有影响的新书,书名Cybernetics(控制论)借用自希腊语(舵手),维纳企图以这个新词一统天下,他在书中不时暗示或明示香农的信息论也是受到他的启发。很明显,年轻的香农和更年轻的麦卡锡都不买维纳的账,也不喜欢“控制论”这个词。麦卡锡向香农建议编一本文集,请当时相关的一线研究人员都贡献文章,这本文集直到1956年才以《自动机研究》(Automata Studies)为名出版,这个普普通通的书名最后是香农定的,他不喜欢用创造新名词的手段来吸引眼球,但麦卡锡认为这个不显山不露水的书名并没有反映出他们的初衷,这导致他后来坚持用另一个新词“人工智能”来命名这个全新的领域。在这本文集中,麦卡锡本人也贡献了一篇只有5页的短文,题为“图灵机定义的逆函数”(The Inversion of Functions Defined by Turing Machines,见McCarthy-1956)。
麦卡锡在文中讨论了这样一个问题:假设知道一个图灵机的输出,如何猜到其输入。更严谨地:给定一个递归函数(即一个图灵机)fm及其输出r(fm(n)=r),如何找到一个“有效”的逆函数g(m, r) 使得 fm(g(m, r)) = r,这里m是图灵机的序号。这个问题就是通过观察一个黑盒子(图灵机)的输出,力图猜出黑盒子的内部构造。最土的办法就是枚举所有能够产生输出的图灵机,但很明显这个办法不一定停机。事实上,在今天大模型的语境里,g(m, r)就是一个大语言模型。麦卡锡意识到这个问题对应于在所有可能的文章中以某种顺序寻找证明(It corresponds to looking for a proof of a conjecture by checking in some order all possible English essays)。麦卡锡认为所有的数学问题都可以表达为用图灵机求逆,这正是所罗门诺夫想解决的归纳推理问题。
达特茅斯会议期间,麦卡锡和所罗门诺夫有了更多的机会进行长时间讨论。所罗门诺夫认为麦卡锡的问题可以转化成:“给定一个序列的初始段,求这个序列的后续”。通过已知的初始段,建模,以模型来预测后续序列。麦卡锡一开始并没有意识到这个思路的重要性,反问了一句:这不就是外插吗?当时在场的人都被麦卡锡的反问卡住了。第二天麦卡锡反应过来,他说所罗门诺夫的问题通俗地说,就是:“假设我们发现一座老房子里有一个计算机正在打印你说的序列,并且已经接近序列的末尾,马上就要打印下一个字符,你敢打赌它会打印正确的字符吗?” 麦卡锡和所罗门诺夫所谓“sequence continuation”,“next word”或者“next symbol”,用今天的话说就是 “next token”。

2006年达特茅斯会议50年周纪念会。左2麦卡锡,左3明斯基,右1所罗门诺夫
其实,这个说法有着更早的起源。法国数学家博雷尔(Félix Édouard Justin Émile Borel,1871年—1956年)在1913年的文章“Mécanique Statistique et Irréversibilité”(统计力学与不可逆性)中考虑过这样一个问题:让一个猴子在一个打字机上随意地敲字,它能敲出一部《哈姆雷特》吗?博雷尔指出猴子随机敲出一部《哈姆雷特》的概率是5.02×10-29,概率极小,但不是绝对不可能,这被称为“无限猴子定理”(infinite monkey theorem)。阿根廷诗人和作家博尔赫斯(Jorge Luis Borges ,1899年-1986年)在1944年出版的短篇小说集《小径分岔的花园》中收录了一篇他的哲理小说(其实更像是散文)“巴比伦图书馆”,文中设想一个完美的图书馆,它可以收藏由字母枚举产生的所有可能的书;事实上,他在1939年写过一篇更严肃的哲学文章“总图书馆”(Total Library),回顾了从亚里士多德开始不同阶段思想家对这个理想的各种思辨。
今天看来,大模型不就是走在这个方向吗?大模型的训练力图穷举人类已有的所有知识。如果博尔赫斯的出发点是理性主义的,那么随机猴子肯定是经验主义的,但他们都可以用麦卡锡的求逆统一为某种图灵机的枚举过程。
图灵1948年的文章“智能机器”的价值正在被越来越多的人注意到。图灵文中提到了几种机器学习的方法。在通用图灵机中,程序等于数据,于是,所有的程序,就像数据一样,是可以逐一被枚举出来的。这个枚举方法是自己把所有可能的程序都学出来。这就是图灵所谓“主动性”(initiative)(见尼克-2024)。图灵明确表示,所有“学习”都可以归约到这个方法。计算理论告诉我们这个枚举过程不停机,或者说不可计算。

和麦卡锡的讨论,促使所罗门诺夫进一步完善自己的想法,达特茅斯会议结束前,他写好了一篇关于归纳推理的备忘录“An Inductive Inference Machine”,这篇打字稿的日期是1956年8月14日。所罗门诺夫把该打字稿给参会人员传阅。1956年底他还将一个改进的版本寄给卡内基理工学院工业管理系的司马贺(Herbert Simon)。
所罗门诺夫的工作首次公开发表是在1960年加州理工学院召开的“大脑系统与计算机”(Cerebral Systems and Computers)会议上。同年这篇文章作为Zator公司报告和美国空军AFOSR报告得到更广泛的流传。1961年明斯基在一篇影响广泛的文章“Steps Toward Artificial Intelligence”中提到了这项工作(见Minsky-1961)。所罗门诺夫后来对1960年的工作做了进一步修订,以“归纳推理的形式理论”(A Formal Theory of Inductive Inference)为题,于1964年正式发表在计算理论的重要刊物《信息与控制》(Information and Control)。因为文章太长,被拆成两部分,在两期分别刊出,前半部分讲理论,后半部分讲了几个实例(见Solomonoff-1964)。
所罗门诺夫归纳法可以如下定义:给定序列(x1, x2, …, xn), 预测xn+1。归纳推理就是力图找到一个最小的图灵机,可以为(x1, x2, …, xn)建模,从而准确地预测后续序列。序列的描述长度就是图灵机的大小,这其实就是麦卡锡最初模糊地意识到的“有效”。例如,如果一个序列是n个1: (1, 1, 1,…),那么我们可以写出如下程序输出该序列:
for i = 1 to n
print 1
这个序列的描述长度就是O(log(n))。
例如,如果我们给出序列(3, 5, 7),会有无穷多种预测后续的结果,其中一种是 9,因为程序有可能打印奇数,如下:
for i = 1 to n
print 2i+1
但也许猜的不对,还有一种可能性是 11,因为程序有可能是打印素数的。很明显,打印素数的程序就要比打印奇数的程序复杂很多,也就是说素数的描述长度要大于奇数的描述长度。等等。
监督学习也可以看作是自监督学习的特殊情况。监督学习(包括分类问题),就是给定序列对(tuple):(x1,c1),(x2,c2),…,(xn,cn),以及xn+1,预测cn+1。学习的过程就是找到拟合函数c=f(x)。这类问题都可以轻松地转化为自监督学习如下:给定序列(x1,c1,x2,c2,…,xn,cn,xn+1), 预测cn+1。
这个被麦卡锡刻画为“在下一个字符上下注”(bet on next symbol)的问题,其实就是GPT为代表的大语言模型的核心机制:next token prediction。能够对已知数据做出概括的图灵机就是大模型。对于同样的数据集,我们当然期望覆盖数据集的大模型的参数越少越好,换句话说,我们期望找到可以做出概括的最经济的图灵机,即最小的图灵机。在这个意义上,学习可以被当作压缩。参数量和token量之间的关系也可借此研究。所罗门诺夫归纳法可能不停机,于是只能用近似算法,放宽对图灵机的“最小性”和预测准确性的限制。所罗门诺夫利用贝叶斯定理推导出序列的先验概率分布。神经网络作为一个通用近似器(universal approximator),可以是实现所罗门诺夫归纳法的一个很好的候选机制。这其实就是今天大模型的进路。
所罗门诺夫想到的另一个要解决的问题,是给定一些句子,看能否学会生成这些句子的语法。此时乔姆斯基(Noam Chomsky)的“语言描述的三种模型”的文章刚刚发表,所罗门诺夫受到启发,把乔姆斯基文法推广成概率文法。他的“归纳推理机”的一种应用场景就是通过输入文本,学会文法,这被他后来称为“文法发现”(discovery of grammar)。
乔姆斯基的先天内生文法(innate grammar)其实就是所罗门诺夫的先验概率分布,只不过乔姆斯基采取了理性主义的立场,而所罗门诺夫无疑是经验主义的。事实上,如果认可丘奇-图灵论题,理性主义和经验主义的区别只是修辞的,而不是本质的。在所罗门诺夫的先验概率分布下,程序的置信度随着其长度指数递减。这就是奥卡姆剃刀,即越短的程序应该有越高的置信度。这一点也可以从经验数据中得到佐证(见Veldhuizen-2005)。在所罗门诺夫的纪念网站(raysolomonoff.com)上,醒目地放着所罗门诺夫的美丽公式:
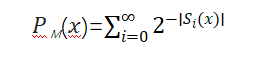
所罗门诺夫一生没有大富大贵,大部分时间是在自己的咨询公司Oxbridge(“牛桥”,牛津+剑桥的简称,相当于汉语俗称“清北”)拿政府(空军、海军、ARPA和NIH)的研究经费,公司只有他自己一个雇员。他的学术自传“算法概率论的发现”(The Discovery of Algorithmic Probability)1997年发表在计算理论杂志《计算机与系统科学》(Journal of Computer and System Sciences)上(见Solomonoff-1997),这篇文章后来历经修订,在多处以不同形式发表。最新的一版在他去世后被收录在文集Randomness Through Computation: Some Answers, More Questions之中(见Solomonoff-2011)。

万能的苏联数学家柯尔莫哥洛夫(Andrey Nikolaevich Kolmogorov,1903年-1987年),除了对传统数学做出广泛和深刻的贡献外,对计算机科学和信息论的诸多方面,也有直接和间接的影响。
1950年代初期,香农的信息论和维纳的控制论,通过俄文翻译传入苏联。柯尔莫哥洛夫凭着他敏锐的直觉,意识到信息论的重要性。同时他对控制论则表示出不屑,他认为控制论并没有内在的统一性。这个认识和香农、麦卡锡等参与达特茅斯会议的人对控制论的看法一致。苏联当时的科学发展状况非常复杂。即使地位如柯尔莫哥洛夫,他对遗传学的兴趣也遭到李森科的打压,倒是李森科下台后,柯尔莫哥洛夫还替他说过好话。
柯尔莫哥洛夫对控制论的看法并没有阻挡控制论成为苏联的主流学科。这也许导致苏联在计算机科学以及多少作为计算机科学子学科的人工智能的后知后觉;这肯定也带偏了中国相关学科的发展。控制论在美国没有成为独立的学科,倒是计算机科学成为主导的学科,1960年代末开始,美国顶流学校纷纷设立计算机系。
控制论的核心概念:反馈,不过是递归函数的一种最简单的特殊情况,不足以作为第一性原理。柯尔莫哥洛夫在为匈牙利数学家罗莎·培特所著《递归函数论》俄译本所写的序言中(莫绍揆先生1958年将此书依照俄文版译为中文,其中将“柯尔莫哥洛夫”译为“郭尔莫哥洛夫”,将“图灵”译为“杜令”)指出,一般递归函数和能行可计算性仍需从可构造性的角度进一步考察——他对丘奇-图灵论题也有着深刻洞见(见Peter-1951)。
无论如何,柯尔莫哥洛夫的切入点是他喜欢的领域:概率论。1965年,他创办了学术季刊《信息传输问题》(Problems of Information Transmission),这份刊物很快成为苏联在计算理论最重要的阵地。柯尔莫哥洛夫本人在创刊号上发表了 “信息的量化定义的三种方式”(Three Approaches to the Quantitative Definition of Information),从算法的角度研究了概率论和信息论。信息论的核心是研究信息的含量。香农的信息量定义是熵。柯尔莫哥洛夫把信息论的基础分成三种,第一是频率,第二是组合学,第三是算法。柯尔莫哥洛夫对信息论和概率论的评价令人深思:“信息论在逻辑上要先于概率论。而不是以后者为基础。”他认为组合学比频率更加坚实,但最令人信服的是算法。一段信息所包含的信息量,可以用最短的生成这段信息的程序的长度来衡量(见Kolmogorov-1965)。这就是现在所谓“柯尔莫哥洛夫复杂性”(Kolmogorov Complexity),可定义如下:
KC(x) = min{ℓ(p) : U(p) = x}
即输出字符串x的最短程序p的长度。柯尔莫哥洛夫这篇经典文章只有7页,而后面他写的几篇相关文章甚至更短。这与所罗门诺夫细致但冗长的文章形成鲜明对比。苏联数学家的简洁是他们的一大特色,据说那是因为苏联时期纸张紧缺,但另一种说法是苏联数学家(尤其是大家)就是不太讲究细节,以至于结果的完整证明,需要他们的学生们补齐,有时甚至需要一代人。柯尔莫哥洛夫的KAM(Kolmogorov–Arnold–Moser)理论就是后来由他的学生阿诺德(Vladimir Arnold)和德裔美国数学家Jürgen Moser等人完善的,而他关于希尔伯特第十三问题的研究,也是由阿诺德画上句号,这个重要的工作值得另写一篇长文。
可以证明柯尔莫哥洛夫复杂性与程序的表示无关。不同的程序表示,例如:C,Java,Python,或图灵机代码,导致的最短描述之间只差一个常量。这个不变性定理有时也被称为“柯尔莫哥洛夫论题”(Kolmogorov Thesis)。越来越多的证据表明柯尔莫哥洛夫复杂性(如果能算出来的话)要比香农熵更加靠谱,例如一个图的结构熵会因为图的表示不同而变化,而这个图的柯尔莫哥洛夫复杂度应该是不变的。
柯尔莫哥洛夫后来注意到所罗门诺夫的工作,他在1968年分别用俄文和英文发表的文章中引用了所罗门诺夫的工作,使得后者在苏联的名声比在西方更加响亮。“柯尔莫哥洛夫复杂性”也被称为“所罗门诺夫复杂性”,或者“所罗门诺夫-柯尔莫哥洛夫-蔡廷复杂性”,偶尔也被称为“描述复杂性”,但计算复杂性理论里有好几个东西都被称为“描述复杂性”,为避免歧义,本文使用最常用的“柯尔莫哥洛夫复杂性”的说法。因为柯尔莫哥洛夫的影响,这门学科也被称为“算法概率论”,或“算法信息论”。
几位苏联学者,其中包括柯尔莫哥洛夫的学生,在伦敦大学皇家哈洛威学院(Royal Holloway)建立了机器学习研究中心(原名Computer Learning Research Centre,后改名Centre for Machine Learning)。在他们倡导下设立了柯尔莫哥洛夫奖章(Kolmogorov Medal,注意:有别于俄国科学院颁发的柯尔莫哥洛夫奖,Kolmogorov Prize)。所罗门诺夫是第一届柯尔莫哥洛夫奖章获奖人,最近一次(2018年)的获奖人是以发明支持向量机(Support Vector Machine)著称的苏联犹太裔统计学家弗拉基米尔·瓦普尼克(Vladimir Vapnik)。所罗门诺夫也在伦敦大学皇家哈洛威学院兼职教授。

阿根廷出生的犹太裔美国理论计算机科学家蔡廷(Greg Chaitin, 1947年-),有着与众不同的成长经历。他高中就读著名的纽约布朗克斯科学高中(Bronx High School of Science),这个学校贡献过9位诺贝尔奖,2位图灵奖。他的第一篇文章在他18岁时发表于IEEE Transactions on Electronic Computers,是关于自动机时钟同步的,这是他高中时的作品,署名单位是哥伦比亚大学工程与应用学院,因为他高中时参加了哥大的荣誉生项目。他高中毕业后,入学纽约城市学院(CCNY)。他在第一学期同时在看三本书:冯诺依曼和摩根士敦合著的《博弈论》,香农和韦弗的《通讯的数学理论》,以及马丁·戴维斯编辑的《不可判定》文集(其中收录了图灵1936年开天辟地的文章)。他本科没有毕业就跟随父母回到阿根廷。
蔡廷在很小的时候就访问过IBM,于是研究逻辑和编程成为他的爱好。他的编程能力使得他在布宜诺斯艾利斯的IBM分公司轻易地找到一份程序员的工作。在此期间他研究哥德尔不完全性定理。他第一篇关于最小程序长度的文章发表在《美国计算机学会会刊》(JACM),那时他才19岁,独立地把所罗门诺夫归纳法和柯尔莫哥洛夫信息量的思想又以新的方式重新发明了一遍。审稿人已经知道柯尔莫哥洛夫的工作并告知蔡廷,他不懂俄文,但还是在论文发表时以脚注形式承认了柯氏的工作。

所罗门诺夫(左一)与蔡廷,2003
蔡廷的出发点是贝里悖论(Berry Paradox)。贝里悖论用英文说就是"The smallest positive integer not definable in under sixty letters",用中文说是“不可能用少于十九个汉字命名的最小正整数”。这是一种命名悖论。因为贝里悖论和所用的语言载体有关,蔡廷于是决定用函数式编程语言LISP以避免混淆。所谓命名一个整数就是给出一个可以输出这个整数的程序。蔡廷的命名就是柯尔莫哥洛夫的描述。绝大多数整数最短的命名方式就是直接打印它们自身,而没有更短的程序表示它们,这些整数被蔡廷称为“无趣的”(uninteresting)、不可理解的(incomprehensible)、不可归约的(irreducible)以及随机的。蔡廷事实上由此证明了柯尔莫哥洛夫复杂度是不可计算的。他当时称之为“不完全性”。
1974年蔡廷回到美国,在纽约州的IBM TJ Watson 研究中心工作,先是做访问学者,后来成为永久研究员。有意思的是他刚回到美国后,就准备乘火车前往普林斯顿拜访他的上帝哥德尔。于是1974年4月的某一天,他鼓足勇气给哥德尔打了个电话,告诉哥德尔他利用贝里悖论也得出了不完全性定理的一个版本。
哥德尔说:“用什么悖论无所谓”(“It doesn’t make any difference which paradox you use!” )。
蔡廷回答:“是的,但是我的证明指出了不完全性的信息论视角,我很想当面告诉你。”
哥德尔说:“好吧,先把论文寄给我,然后再给我打电话看能不能约上我的时间。”
于是蔡廷把自己刚刚发表在IEEE Transactions on Information Theory的文章寄给哥德尔,并再次致电哥德尔,哥德尔看过文章后同意和他见面并约定了时间。但就在他约定的那天下了雪。当他正准备离开办公室去火车站时,电话响了,是哥德尔的秘书,说“哥德尔教授身体不好,很怕雪,今天不到高等研究院上班,见面取消了。”没有见到哥德尔成了蔡廷一生的遗憾。1991年他被哥德尔的母校维也纳大学邀请演讲,当地报纸把他的照片印在头版,标题是 “比哥德尔还哥德尔!”( Out-Gödeling Gödel”!)(见Chaitin-2023, 及Wuppuluri & Doria-2020)
蔡廷晚年兴趣转向生物学,出版过有趣的科普著作Proving Darwin(《证明达尔文》,见Chaitin-2012)。一个人成名早的特点是他喜欢用熟悉的锤子去敲他碰见的所有钉子,所谓一招鲜吃遍天。他不满生物学缺乏理论基础,用算法信息论解释进化论,并把这个方法称为“元生物学”(metabiology)。一点也不惊奇,他的元生物学的核心思想可以从遗传算法和遗传编程中找到线索。

苏联数学家列文(Leonid Levin, 1948年-)1972年独立提出了NP完全性并证明了几个等价问题(见Levin-1973)。这篇现在看来极为重要的文章只有两页纸,发表在柯尔莫哥洛夫创办的著名刊物Problems of Information Transmissions 1973年第3期上。列文是柯尔莫哥洛夫的学生,但由于政治问题,他没有被授予博士学位。1978年他移民美国,麻省理工学院很快给他补了一个博士,此后他的结果渐为人知。他后来在波士顿大学教书直到退休。2000年后的计算理论教科书都把原来的库克定理改为库克-列文(Cook-Levin)定理。2012年他被授予高德纳奖(Knuth Prize)——与面向特定贡献的图灵奖和哥德尔奖不同,高德纳奖更加考虑对整个学科的影响,有点终身成就奖的意思。这算是对他缺失图灵奖的补偿吧。
和他的老师一样,列文的文章也都很短,他1986年开创算法平均复杂性分析的文章也只有两页(见Levin-1986)。有意思的是,列文倾向于认为P=NP,他肯定是少数派。
在Levin-1973中,列文给出了两个定理,定理1关于NP完全性,而定理2当时被忽略了。定理1没有详细证明,而定理2甚至连说明都没有。文章在列出定理2之后就结束了。定理2其实和定理1的关系不大,或者至少关系并不明显。列文给出了一个通用搜索过程(universal search),这个过程能够求解一个函数的逆,这恰是麦卡锡1950年代提出的问题,而所罗门诺夫已经在这个问题上耗了20年。
当所罗门诺夫得知列文在苏联的遭遇后,联系了美国的几所学校和多名学者,恳请他们帮助列文。所罗门诺夫把他和列文的学术讨论写成报告(见Solomonoff-1984),为Levin-1973补齐了定理2的证明。所罗门诺夫称列文的通用搜索过程为L-search。
列文的L-search在柯尔莫哥洛夫复杂性的基础上加了一个时间的限制,可定义如下:
Kt(x) = min{ℓ(p) + log(time(p)): U(p) = x}
这样列文的复杂性就是可计算的了,也就是说,如果逆函数存在,总可以通过列文的通用搜索过程找到。这和所罗门诺夫更早获得的收敛性定理契合。

列文1973年文章第二页。参考文献前是一句鸣谢,鸣谢前即是定理2的陈述。

物理学家本内特(Charles Bennett, 1943-)因量子计算出名,他是量子密码分发协议BB84的第一个B。他对算法信息论也有杰出贡献,他在1988年引入了逻辑深度(logical depth)的概念(见Bennett-1988),定义如下:
LD(x) = min{T(p): ℓ(p) =p*+s ∧U(p) = x}
即近乎最短的程序输出x所需的时间。这里p*就是柯尔莫哥洛夫复杂性,ℓ(p)就是近乎最短的程序的长度。可以看出,逻辑深度进一步放宽了柯尔莫哥洛夫复杂性对程序最短长度的要求。
如果把归纳看作是压缩的话,逻辑深度考虑的是解压的时间。逻辑深度让我们考虑时间和空间的关系。直觉上,我们会认为时间比空间更“贵”,但目前在计算理论中,我们尚不知多项式时间的类P是不是等于多项式空间的类PSPACE,当然NP是PSPACE的子集但不知是不是真子集。如果P≠PSPACE,那么必然存在PSPACE中可计算的字符串,其逻辑深度大于多项式。压缩首先考虑的是空间成本,但解压有时间成本。
用大语言模型的话来说,压缩时间是训练时间;柯尔莫哥洛夫复杂度是大模型的参数量;逻辑深度对应于大模型的最短“推理”(inference)时间。顺便说,大模型术语中“推理”(inference)更合适的译法应该是“推断”,推断是统计意义上的,有别于逻辑意义的“推理”(reasoning)。汉语里“推理”常常指后者。况且,大模型中也有逻辑意义的“推理”,例如CoT(Chain of Thought),而机器定理证明的教科书里时常也不严格区分inference和reasoning。人工智能的逻辑派和统计派,如果都是讲汉语的,估计就打不起来了。

理论计算机科学家李明等的一系列工作,为所罗门诺夫-柯尔莫哥洛夫-蔡廷复杂性的研究做出重要贡献。李明和维特涅(Paul Vitanyi)合著的《柯尔莫哥洛夫复杂性及其应用》(Li-Vitanyi-2019)是这个领域的权威(definitive)参考书和教科书,也被誉为该领域的《圣经》,目前已经出到第4版。早期版本有中译本《描述复杂性》(科学出版社,1998),但“描述复杂性”这个译法容易和计算复杂性里各种被称为 Descriptive Complexity的东西混淆,本文中我们还是使用全名所罗门诺夫-柯尔莫哥洛夫-蔡廷复杂性或柯尔莫哥洛夫复杂性。

李明夫妇和所罗门诺夫夫妇
Marcus Hutter 1996年从慕尼黑大学博士毕业,他的博士论文是理论物理。但他博士毕业后转向通用人工智能。2000年他提出用强化学习作为基础的AGI的理论框架,AIXI,他的主要数学工具就是所罗门诺夫归纳法(见Hutter-2005)。
OpenAI的 ChatGPT的成功,使得大家一直在关注它的基本工作原理。很多人把它的成功归于底层神经网络架构Transformer。但事实上,Transformer的发明者Google在语言大模型上反而落后于OpenAI。一种可能的解释是Google使用的框架是BERT,这是当时所有大模型团队采用的框架;而OpenAI采用了GPT。其主要区别是:GPT是next token prediction,也即所罗门诺夫归纳;而BERT可以用类似的语言描述为:给定序列(x1, x2, …, xn),从中抽走xi 让你猜xi是什么。虽然没有数学证明,但我们直觉上可以猜测单向的GPT应该比双向的BERT效率更高。这作为一个开放问题留给读者。所罗门诺夫归纳为我们提供了BERT不可能比GPT更强的证据。
目前的大模型研究中,理论暂时落后于工程实践。过去的计算机科学和工程的研究经验中,一般benchmark都是领先于工程的,但对大模型的评价,明显落后于大模型的开发。ChatGPT成功后,OpenAI首席科学家伊利亚·苏茨凯弗(Ilya Sutskever)在接受采访时不断暗示next token prediction是GPT系列大模型成功的关键,但直到2023年8月他在伯克利理论计算机科学研究所(Simons Institute,另一个由数学家出身的金融家赛蒙斯捐助的基础科学机构)演讲时,才明确透露GPT的数学依据就是所罗门诺夫归纳法(见Sutskever-2023)。他声称他自己在2016年独立想出来——这也稍微晚了点,我们自然没法强迫他进行零知识证明。
按照所罗门诺夫-柯尔莫哥洛夫-蔡廷理论,所有的学习都可被看作是压缩。形象地考虑,用精简的系统概括大量数据的过程,或者从殊相到共相的过程,自然是压缩,因为共相的表示要比诸多殊相的表示经济得多。Hutter在2006年设立过Hutter Prize以奖励最好的无损压缩(即压缩比最高的)工作。Hutter现已加入DeepMind,他作为合作者的文章“Language Modeling is Compression”(见Deletang-2023)曾在工程师群体中引起过热烈讨论。实验表明,用大语言模型做无损压缩,效果要远远好于基于哈夫曼编码(Huffman coding)的各种压缩算法的变种(Li-2024)。大语言模型对token的概率预测肯定好于一般的压缩算法。柯尔莫哥洛夫和蔡廷最早的出发点是信息表达和信息传输,其实也是压缩。殊途同归。

所罗门诺夫归纳法的科普版或者哲学版(philosophical formulation)可描述如下:
1. 观察结果以数据方式输入.
2. 形成新假设以解释目前所有的数据. 假设就是图灵机。
3. 新的数据输入,检测数据是否证实假设。
4. 如果数据证伪假设,返回第2步。
5. 如果数据证实假设,持续接受假设,并返回第3步。
美国最原创的哲学家皮尔士(Charles Sanders Peirce,1839-1914)创立的实用主义强调科学方法(见Peirce-1877)。皮尔士曾说“推理的目的是从已知中发现未知”,他这里的“推理”用的词是reasoning,他更喜欢的词是“溯因”(abduction),以别于“归纳”(induction)和“演绎”(deduction)。我们可以把所罗门诺夫归纳法作为皮尔士科学方法的精确版本。我甚至更愿意用一个新创的词“老派实用主义”(paleo-pragmatism),有别于后来被庸俗化了的实用主义,来指称这个新的科学实用主义,由此,所有皮尔士的理论和信条都可以被更严谨地建立。在实用主义中(见James-1907),理性主义与经验主义并不是作为完全的对立面,当新的假设成立并开始解释大量数据时,系统表现得更像理性主义者;而当新的数据证伪旧的假设时,系统表现得更像经验主义者。
我们也可以用所罗门诺夫归纳法来解释卡尔·波普尔(Karl Popper,1902-1994)的证伪理论。历史地看,波普尔的思想也与美国哲学家卡尔纳普有关,只不过波普尔的意图是通过攻击卡尔纳普的概率论,以建立一个用新词“可证伪性”来命名的哲学路线。事实上,“可错性”(fallibility)早就被皮尔士更深刻地讨论过。所罗门诺夫归纳法既然可以解释皮尔士的实用主义,当然可以轻松地概括波普尔的所有理论,并且也可以解释波普尔难以认可的东西,例如进化论。所谓证伪,任何有智力的人都能想的到:说一个东西不对总要比说一个东西对容易得多。统计学家乔治·博克斯(George Box)有言:“所有模型都是错的,但有些模型是有用的”(all models are wrong,but some are useful),所谓“有用”就是可以用来预测。我们由此可看出哲学家与科学家或数学家处理问题的不同态度,前者更关心造新词儿,而后者更关心知识的进步。
库恩的科学革命理论也可以作为所罗门诺夫归纳法的特例。奥卡姆的剃刀,在被提出之后的很长时间里并没有严格定义,只是直觉上认为在解释力相近的前提下,模型越小越好。在所罗门诺夫-柯尔莫哥洛夫-蔡廷理论里,覆盖所有数据的最小的模型,就是最短的程序或者最小的图灵机。在一定误差内,可以有多个差不多大小的图灵机,即,可以有多个解释,即伊比鸠鲁的无差别原则(principle of indifference)。当然,在实际中,我们只能寻找在一定误差范围内较小的图灵机。当我们找到的模型/程序/图灵机和以前的模型/程序/图灵机差别较大时,我们就称之为科学革命。一般来讲,科学革命之后的新模型/图灵机大概率要比革命前的更长(即柯尔莫哥洛夫复杂度更大),并且大概率其逻辑深度也要更深。一个新的模型/程序/图灵机就是新的范式。
所罗门诺夫归纳可以解释几乎所有目前关于意识的理论。此处略去一万字(值得另一篇长文)。

亚里士多德《形而上学》开篇就说“求知是人的本性”(All men by nature desire to know)。亚里士多德论述了人从经验到技术再到科学的过程就是“to know”的过程。所谓“不可计算”或“不停机”也许是上帝留给人类的希望。在所罗门诺夫的框架里,知识的进步就是“递增学习”(incremental learning)。进一步研究所罗门诺夫归纳法和柯尔莫哥洛夫复杂性会为机器学习提供新的理论基础。现在看,遗传算法、遗传编程、强化学习都可以在所罗门诺夫归纳法的框架内得到计算理论的解释。
我们可以讨巧地借用亚里士多德:“压缩是人的本性”(All men by nature desire to compress)。休谟认为归纳虽然是不能用来证实(verification),但却是人性之本(essential to human nature)。我们可以有一个替代的说法:压缩是人性之本。经验得自于感觉,经验数据被建模是经济的考虑,建模就是压缩,压缩是由图灵机完成的。正是在这个意义上,所罗门诺夫归纳法可被当作第一性原理。进化过程甚至也可以被看作是压缩,所谓“适者生存”(survival of the fittest),也可被狭义地转述成“最压者生存”(survival of who compress the most)。压缩即物理世界规律在信息世界的体现。笛卡尔的格言“我思故我在”可以被更严格地表达为“我压故我在”。(I compress, therefore, I am.)
回顾了所罗门诺夫-柯尔莫哥洛夫-蔡廷理论的发展过程,再来看大语言模型,我们会觉得也许不是理论落后于实践,而是太超前了。
鸣谢:作者受惠于同李明老师的讨论,本文写作过程还得到白硕、刘卓军、马少平、毛德操、孙茂松、张永刚和赵伟等诸位师友的指点和帮助,特此感谢。
作者简介:
尼克,乌镇智库理事长。曾获吴文俊人工智能科技进步奖。中文著作包括《人工智能简史》《理解图灵》《UNIX内核剖析》和《哲学评书》等。
参考文献:(上下滑动可浏览)
1.Bennett, Charles H. (1988), "Logical Depth and Physical Complexity", in Herken, Rolf (ed.), The Universal Turing Machine: a Half-Century Survey, Oxford U. Press, pp. 227–25
2.Calude C.S. (2007), (ed.) Randomness and Complexity, from Leibniz to Chaitin
3.Carnap, R. (1950), Logical Foundations of Probability.
4.Chaitin. G. J. (1965), “An improvement on a theorem by E. F. Moore”, IEEE Transactions on Electronic Computers, EC-14, 466–467.
5.Chaitin, G. J. (1966), “On the Length of Programs for Computing Finite Binary Sequences”, Journal of the Assoc. of Comp. Mach., 13, pp. 547–569.
6.Chaitin, G. J. (1969), “On the Length of Programs for Computing Finite Binary Sequences: Statistical Considerations,” Journal of the Assoc. of Comp. Mach., 16, pp. 145–159.
7.Chaitin, G. J. (2012), Proving Darwin: Making Biology Mathematical (证明达尔文,人民邮电出版社,2015)
8.Chaitin, G. J. (2023), Building the World from Information & Computation, Expanded 2nd ed.
9.Chomsky, A.N. “Three Models for the Description of Language,” IRE Transactions on Information Theory, Vol. IT–2, No. 3, Sept. 1956
10.Deletang, G. et al (2023), “Language Modeling is Compression”, arXiv
11.Gleick, J. (2011), The Information: A History, a Theory, a Flood.
12.Hutter, M. (2005), Universal Artificial Intelligence: Sequential Decisions Based on Algorithmic Probability, Springer-Verlag, Berlin.
13.James, William (1907), Pragmatism: A New Name for Some Old Ways of Thinking
14.Kolmogorov, A.N. (1965), “Three Approaches to the Quantitative Definition of Information”, Problems of Information Transmission, 1 (1): 1–7.
15.Kolmogorov, A.N. (1968), “Logical Basis for Information Theory and Probability Theory”, IEEE Trans. on Information Theory, IT–14(5): 662– 664.
16.Kolmogorov, A.N. (1969), “On the Logical Foundations of Information Theory and Probability Theory”, Problems of Information Transmission, 5:1-4.
17.Kolmogorov, A.N. (1988), How I became a mathematician, (姚芳等编译,我是怎么成为数学家的,大连理工大学出版社,2023)
18.Levin, L. (1973), “Universal search problems”, Problems of Information Transmission, 9 (3): 115–116
19.Levin, L. (1986), “Average case complete problems”, SIAM Journal on Computing, 15 (1), pp. 285–286
20.Li, M. and Vitanyi, P. (2019), An Introduction to Kolmogorov Complexity and Its Applications, Springer-Verlag, N.Y., 1st ed. 1993, 3rd ed. 2008, 4th ed. 2019.
21.Li, M., et al (2023), “A Theory of Human-like Few-shot Learning”, work in progress.
22.Li, M. (2024), “Approximating Human-Like Few-shot Learning with GPT-based Compression”, preprint
23.McCarthy, J. (1956), The Inversion of Functions Defined by Turing Machines, in McCarthy and Shannon ed. Automata Studies.
24.Minsky, M.L. (1961), “Steps Toward Artificial Intelligence,” Proceedings of the IRE, 49:8–30, 1961. reprinted in Feigenbaum, E.A. and Feldman, J. ed. Computers and Thought, 1963
25.Peirce, C.S. (1877), “The Fixation of Belief”, in Philosophical Writings of Peirce,1955
26.Peter, Rozsa (1951), Rekursive Funktionen, Budapest, 递归函数论, 莫绍揆 译, 科学出版社, 1958.
27.Shannon, C.E. (1948), “The Mathematical Theory of Communication,” Bell System Technical Journal, 27:379–423, 623–656.
28.Solomonoff, R.J. (1956), “An Inductive Inference Machine,” Report circulated at the Dartmouth Summer Workshop on Artificial Intelligence, August 1956
29.Solomonoff, R.J. (1957), “An Inductive Inference Machine,” IRE Convention Record, Section on Information Theory.
30.Solomonoff, R.J. (1960), “A Preliminary Report on a General Theory of Inductive Inference,” (Revision of Report V–131), Contract AF 49(639)– 376, Report ZTB–138, Zator Co., Cambridge, Mass., Nov, 1960.
31.Solomonoff, R.J. (1964), “A Formal Theory of Inductive Inference,” Information and Control, Part I: Vol 7, No. 1, pp. 1–22, March.
32.Solomonoff, R.J. (1964), “A Formal Theory of Inductive Inference,” Information and Control, Part II: Vol 7, No. 2, pp. 224–254, June.
33.Solomonoff, R.J. (1978), “Complexity–based induction systems: Comparisons and convergence theorems”, IEEE Trans. on Information Theory, IT–24(4):422–432.
34.Solomonoff, R.J. (1984), “Optimum Sequential Search”, Oxbridge Research Report, revised 1985
35.Solomonoff, R.J. (1997), “The Discovery of Algorithmic Probability”, J. Computer and System Sciences, 55, 73-88.
36.Solomonoff, R.J. (2010), “Algorithmic Probability, Heuristic Programming and AGI”, Proceedings of the 3d Conference on Artificial General Intelligence
37.Solomonoff, R.J. (2011), “Algorithmic Probability -- Its Discovery -- Its Properties and Application to Strong AI”, in Hector Zenil (ed.), Randomness Through Computation: Some Answers, More Questions, Chapter 11, pp. 149-157
38.Sutskever, Ilya (2023), “An Observation on Generalization”, Talk at Simons Institute Aug 14, 2023
39.Veldhuizen, Todd L. (2005), “Software Libraries and Their Reuse: Entropy, Kolmogorov Complexity, and Zipf’s Law”,arxiv
40.Vitanyi, P. (1988), “A Short Biography of A.N. Kolmogorov”, CWI Quarterly, (homepages.cwi.nl/~paulv/KOLMOGOROV.BIOGRAPHY.html)
41.Vitanyi, P. (2009), “Obituary: Ray Solomonoff, Founding Father of Algorithmic Information Theory” (homepages.cwi.nl/~paulv/obituary.html)
42.Wuppuluri, S. and Doria, F.A., (ed) (2020), Unravelling Complexity: The Life and Work of Gregory Chaitin, World Scientific Publishing Company
43.尼克 (2021), 人工智能简史, 第2版.
44.尼克 (2024), 理解图灵.(即将出版)
01

《人工智能简史(第2版)》
作者:【美】尼克
本书全面讲述人工智能的发展史,几乎覆盖人工智能学科的所有领域,包括人工智能的起源、自动定理证明、专家系统、神经网络、自然语言处理、遗传算法、深度学习、强化学习、超级智能、哲学问题和未来趋势等,以宏阔的视野和生动的语言,对人工智能进行了全面回顾和深度点评。
获得第七届中华优秀出版物图书奖、第八届吴文俊人工智能科技进步奖,入围央视“2017年度中国好书”,获选第十三届“文津图书奖”推荐图书。
02

《中国人工智能简史》
作者:林军 岑峰
高文院士、李国杰院士、戴琼海院士作序推荐;张钹 沈向洋 杨强 张正友 张建锋 王海峰 王小川联名推荐。
本书为该系列第一卷,梳理了自 1979 年至 1993 年中国人工智能领域初期十多年的发展历程,用轻松而真诚的笔触,讲述了为中国人工智能发展寻路的奠基者,并介绍了重要历史事件的来龙去脉,带领读者深入了解中国人工智能发展早期鲜为人知的历史。
03

《信息简史》
作者:詹姆斯•格雷克
第九届文津图书奖得主,享誉全球的科普作家詹姆斯•格雷克带来一段人类与信息遭遇的波澜壮阔的历史,告诉我们如何在人工智能时代的信息爆炸中生存。
ChatGPT陡然崛起,人类历史面临重大转折,我们将何去何从?人类与信息遭遇的历史由来已久。
但人类开始自觉地理解和利用信息始于克劳德•香农在1948年创立的信息论。香农的信息论不仅推动了信息技术的发展,也引发了许多学科的信息转向。部分科学家甚至认为,构成世界的基础不是物质,不是能量,而是信息。正如物理学家约翰•惠勒所说,“万物源自比特”。
人类文明与机器文明必然会彼此推动,一起走向一个未来前所有未有的高峰。而在这个历史转弯处,应该回过头来读历史。《信息简史》与其说是一部科技史,不如说它是以信息为视角的世界观与发展史。

