
- 1Logistic回归的基本原理(简单介绍)_logistic回归模型的理论基础
- 2PCB板上可以走100A的电流吗?大电流路径设置技巧_pcb焊盘十字连接过电流能力
- 3机器人运动学参数辨识(DH参数误差标定)_机器人运动学参数辨识方法
- 4 区块链共识机制简述
- 5Android SELinux开发入门指南之SELinux基础知识_selinux书
- 6Linux关于MySQL的卸载与安装详细教程(通过yum安装)_linux操作系统安装mysql5.7.44
- 7算法与数据结构 — 散列表_散列表装填因子计算
- 8BeanUtils源码解析
- 9Microsoft Visual C++ Runtime Library Runtime Error的解决的方法
- 10无人机超远距离WiFi传输,CV5200无线通信模组,无线音视频传输方案_无人机实时视频传输
CiteSpace学习笔记(四)——功能区和参数区_citespace节点不能超过300
赞
踩
1.菜单栏

(1)File(文件)菜单中的功能主要用于对当前的功能界面参数进行保存和软件退出。
(2)Project(项目)主要是新建、编辑和删除分析的工程项目。
(3)Data(数据)主要是数据的过滤和转换。
(4)Network(网络)主要是对网络文件的可视化。其中主要包括.net文件,GraphML以及Adjacency List。
(5)Adjacency List的可视化。特别地,Batch Export to Pajek.net Files提供了一次性生成一个按照时序保存的Pajek文件,并自动打开MapEquation网站的序列网络可视化应用平台。
(6)Visualization(可视化)主要用来读取CiteSpace分析得到的可视化文件。
(7)Geographical(地理化)主要是对数据地理信息的可视化分析。
(8)Overlay Map(图层叠加)主要用来实现期刊的双图叠加分析。
(9)Analytics(分析)菜单栏主要包含COA作者的合著分析、ACA作者的共被引分析、DCA文献的共被引分析、JCA期刊的共被引分析以及SVA结构变异分析等功能。
(10)Text(文本)主要是CiteSpace的一些高级功能,如概念书+谓词树、全文挖掘等功能。该模块的功能是独立于网络可视化窗口的。
(11)Preferences(偏好)菜单是对常见默认项的修改。其中,Set the Off Point of Centrality Computation为中介中心性的计算设置。CiteSpace默认,当网络的节点数量大于350时,将关闭节点中介中心性的计算功能。用户需要在网络的可视化界面Merics—>Compute Centrality来启动网络节点中介中心性的计算。此外,它还包含Show/Mute Visualization Window和Chinese Encoding for CNKI or CSSCI。
(12)Help(帮助)包含CiteSpace主页链接、PDF版的英文手册链接、术语表以及更新记录等。
2.快捷区域
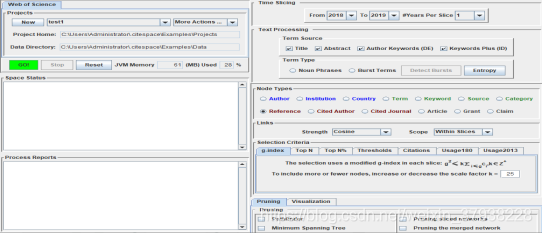
(1)Projects功能和参数区。该区域主要是新项目的建立、编辑和删除区域。
(2)Time Slicing功能和参数区。该区域的主要功能是对将要分析的数据进行时区分割。
(3)Text Processing功能和参数区。该区域的主要功能包含Term Source和Term Type。Term Source用于选择Term提取的位置,包含Title(标题),Abstract(摘要),Author Keywords(DE,作者关键词)以及Keywords Plus(ID,WoS增补关键词)。Term Type是对共词分析类型的补充选择,选择该功能就能提取到名词性术语。在此界面也可以对主要的名词术语进行突发性探测,在运行生成共词网络后可以查看熵值。
(4)Network configuration功能和参数区。该区域的功能主要是对网络参数的设置,包含Node Types(网络的类型)、Links(网络节点的关联强度)以及Selection Criteria(提取节点阈值的选择)。CiteSpace中共提供了11个节点类型,在以上选择中的一些节点类型还可以与其他节点类型复合选择。
①CiteSpace中分析的网络类型
在节点类型中,Author,Institution以及Country是用来进行Co—authorship分析的,他们之间的差异仅仅是在分析合作上的主体粒度不同而已(可以分别理解为微观合作、中观合作和宏观合作)。在分析时它们是可以多项选择的。Term分析的功能是对文献中名词性术语的提取,主要从文献的标题、摘要、关键词和索引词位置提取;Keyword主要是对作者的原始关键词的提取。Term和Keyword常常用来对文本主题进行共词(co—words)的挖掘分析。Category是对文献中标引的科学领域的共现分析(co—occurrence),这种分析有助于了解对象文本在科学领域的分布情况。Cited Reference是文献的共被引,Cited Author是作者的共被引,Cited Journal是期刊的共被引。Paper是文献的耦合分析功能,Grant则是对研究基金的分析(Web of Science的数据从2008年才增加了资助基金数段内容,因此不要对2008年之前的数据进行基金分析)。
在使用CiteSpace生成的各种图谱中,作者的合作图谱中的节点大小表示作者、机构或国家/地区发表论文的数量,之间的连线反应合作关系的强度。论文的主题、关键词以及科学类别的网络图谱中,节点的大小代表它们出现的频次,之间的连线表示共现强度。共被引分析图谱中,节点的大小反映了被引用的次数。文献的共被引反映了单个文献的引用次数,作者的共被引网络反映了作者被引用的次数,期刊的共被引网络中节点大小反映期刊被引用的次数,之间的连线反映了共被引的强度。在文献耦合网络中,一个节点代表一篇论文,节点的大小可以按照被引频次显示,节点之间的连线反映了耦合强度。
②CiteSpace中关系强度的计算
Links参数主要用于选择网络节点的关联强度的计算方法(在处理过程上往往可以认为是共现矩阵的标准化过程),CiteSpace提供了三种用于计算网络中连接强度的方法。

【注】:这些标准化后的数值都在0~1之间,SI为i出现的频次,SJ为j出现的频次,CIJ为i和j的共现次数。
在科学知识网络的分析中,知识单元的相似性测度(知识单元矩阵的标准化)多是基于集合论方法。这种测度方法的广义相似性指数的表示公式为:
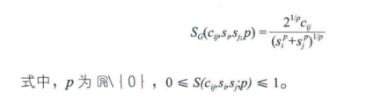
当上式中P—>0时,那么得到的公式就为Cosine的标准化公式;当P=1时,那么得到的标准化公式为Dice。此时的Jaccard算法与广义相似性系数的关系可以表示为:

在CiteSpace中可以将这些相似性算法用于“时间切片内”(Within slices)
或“时间切片之间”(Across slices),CiteSpaces默认的Scope选项为Within slices。
③CiteSpace中所分析数据阈值的设定
Selection Criteria功能区用来设定在各个时间段内所提取对象的数量。Top N per slice的意思是提取每个时间切片内的对象的数量;Top N%就是提取每个时间切片中排名前N%的对象;Usage 180为近180天内,全文的访问次数或保存该记录的次数;Usage 2013为2013年至今的全文的访问次数或保存该记录的次数;g—index是软件的知识单元提取方式,该算法是在增加规模因子k的基础上,按照修正后的g指数排名抽取知识单元。
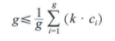
式中,k为规模因子,推荐使用10,20,30,…来进行尝试;
Thresholds通过设定前中后三个时间段c、cc和ccv赋值,其余用线性内插值算法处理,ccv是利用余弦函数得到的一个标准化值,ccv与c和cc三者关系如下:
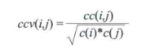
式中,c代表最低被引或者出现频次,cc代表本时间切片中共现或者共被引频次,ccv表示共现率或者共被引率;Citations的功能是通过提取施引文献被引频次的分布,按照频次分析调整阈值来分析文献,使用该功能只需要点击Citations—>Use TC Filter—>Check TC Distribution就会得到文献集的被引分布,0~211显示的是所有文献集的分布。其中TC为被引次数,Freq是指在某个被引次数下的文献数量,Accum.%是指该频次对应的累计百分比。
(5)Pruning参数和功能区。Pruning区域是网络的裁剪功能区,当网络比较密集时可以通过保留重要的连线来使网络的可读性提高。该模块主要有两种网络裁剪方法,分别为Minimum Spanning Tree(MST,最小生成树)和Pathfinder Network(PFNET,寻径网络)。
(6)Visualization参数和功能区。主要用于对可视化结果进行设置。默认为Cluster View-Static(聚类视图,静态)与Show Merged Network(显示分析的整体网络)。此外,也可以选择Show Networks by Time Slices,即显示各个时间切片的图谱。还可以选择动态的网络可视化Cluster View-Animated。
(7)数据分析状态与过程区域。Space Status和Process Report两个动态数据过程显示功能区。前者显示在相应参数设置下每个时间切片上的网络分布情况,criteria表示每个时间切片提取的节点数量,space表示空间中节点的数量总数,nodes表示实际提取的节点数量,links/all表示实际的连线数量/连线数量的总数。后者显示在数据处理过程中的动态过程以及网络处理后的整体参数,如显示了文献空间数据的总数,有效参考文献和无效参考文献的个数及其占比,运行的时间,合并后的网络节点数量和连线数量;在运行时可以动态地看到,CiteSpace处理数据是分时处理的。

