
- 1Apusic应用服务器文档_com.apusic.ams.embed
- 2Oracle 单机/RAC 至 KingbaseES V8 安装部署最佳实践_oracle部署最佳实践
- 3Jmeter 性能 —— 阶梯负载最终请求数!_jmeter阶梯设置
- 4【华为OD技术面-手撕算法代码真题】翻转括号内的字符串_华为od手撕代码题
- 5Python上海美食商家爬虫数据可视化分析和推荐查询系统
- 6一篇通关代码随想录 - 二叉树
- 7openlayers-09-添加标注(文字+图片)_openlayers标注点
- 8贪心算法:55.跳跃游戏(C++)_跳跃游戏c++程序代码
- 9几句话说清session,cookie和token的区别_guestsession.getcookie()是随机的嘛
- 10自动化测试实践总结
微软发布Phi-3,性能超Llama-3,可手机端运行
赞
踩
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
更多资源欢迎关注

数据已成为提升大模型能力的重点。
Llama-3 刚发布没多久,竞争对手就来了,而且是可以在手机上运行的小体量模型。
本周二,微软发布了自研小尺寸模型 Phi-3。
新模型有三个版本,其中 Phi-3 mini 是一个拥有 38 亿参数的语言模型,经过 3.3 万亿 token 的训练,其整体性能在学术基准和内部测试上成绩优异。
尽管 Phi-3 mini 被优化至可部署在手机上,但它的性能可以与 Mixtral 8x7B 和 GPT-3.5 等模型相媲美。微软表示,创新主要在于用于训练的数据集。
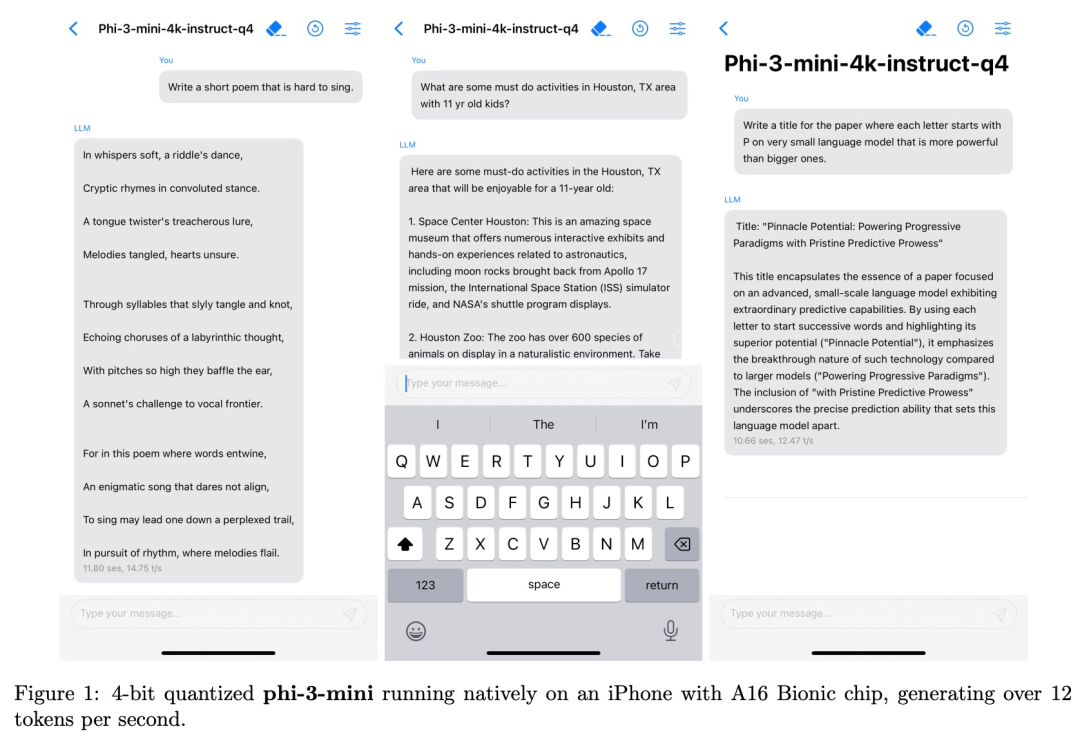
与此同时,Phi-3 与 Llama-2 使用相同的架构,方便开源社区在其基础上开发。

此前,微软的 Phi 系列模型曾经引发了人们的热议,去年 6 月,微软发布了《Textbooks Are All You Need》论文,用规模仅为 7B token 的「教科书质量」数据训练 1.3B 参数的模型 phi-1,实现了良好的性能。
去年 9 月,微软进一步探索这条道路,让 1.3B 参数的 Transformer 架构语言模型 Phi-1.5 显示出强大的编码能力。
去年底,微软提出的 Phi-2 具备了一定的常识能力,在 2.7B 的量级上多个基准测试成绩超过 Llama2 7B、Llama2 13B、Mistral 7B 等一众先进模型。

Phi-3 技术报告:https://arxiv.org/abs/2404.14219
刚刚提出的 phi-3-mini 是一个在 3.3 万亿个 token 上训练的 38 亿参数语言模型。实验测试表明,phi-3-mini 的整体性能可与 Mixtral 8x7B 和 GPT-3.5 等模型相媲美,例如 phi -3-mini 在 MMLU 上达到了 69%,在 MT-bench 上达到了 8.38。
微软之前对 phi 系列模型的研究表明,高质量的「小数据」能够让较小的模型具备良好的性能。phi-3-mini 在经过严格过滤的网络数据和合成数据(类似于 phi-2)上进行训练,并进一步调整了稳健性、安全性和聊天格式。
此外,研究团队还提供了针对 4.8T token 训练的 7B 和 14B 模型的初始参数扩展结果,称为 phi-3-small 和 phi-3-medium,两者都比 phi-3-mini 能力更强。
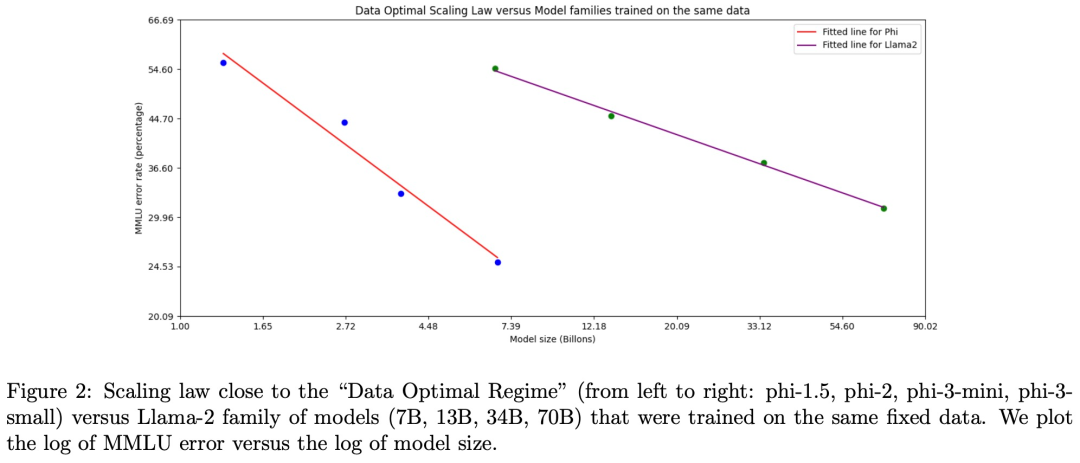
学术基准
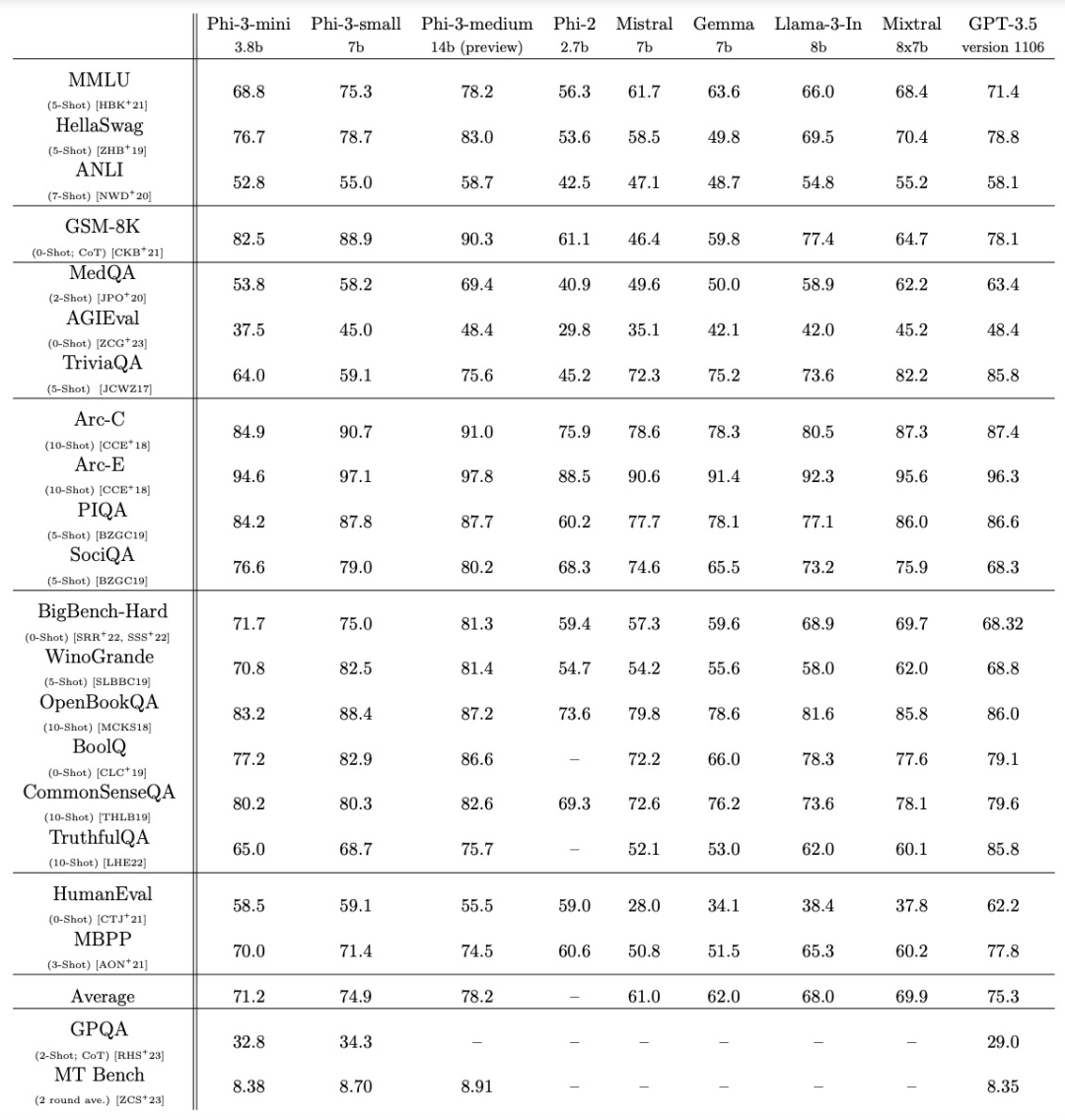
在标准开源基准测试中,phi-3-mini 与 phi-2 、Mistral-7b-v0.1、Mixtral-8x7B、Gemma 7B 、Llama-3-instruct8B 和 GPT-3.5 的比较结果如下表所示,为了确保具有可比性,所有结果都是通过完全相同的 pipeline 得到的。
安全性
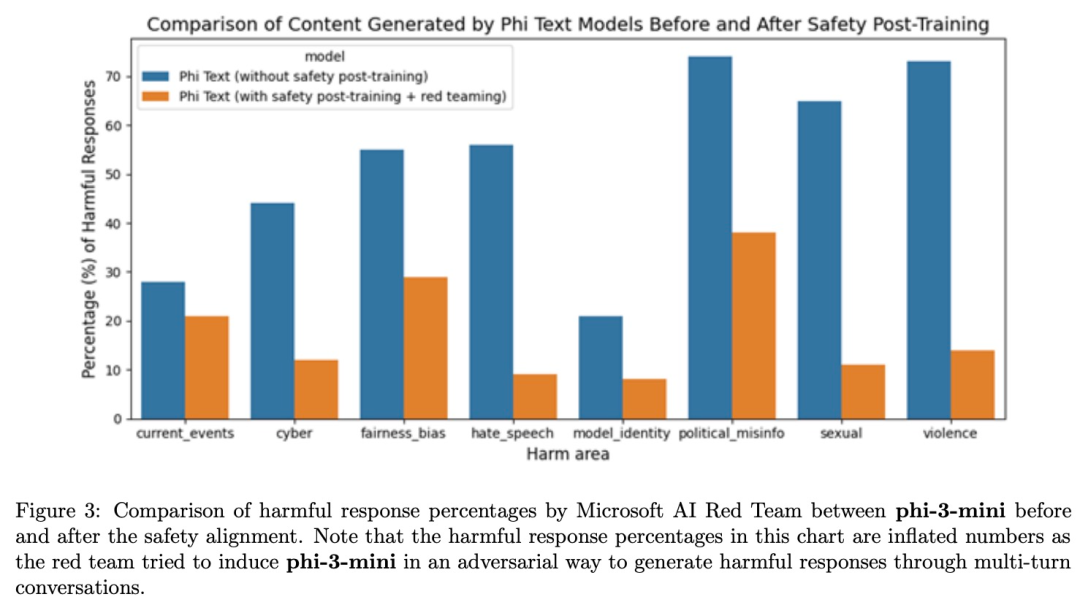
Phi-3-mini 是根据微软负责任人工智能原则开发的。保证大模型安全的总体方法包括训练后的安全调整、红队(red-teaming)测试、自动化测试和数十个 RAI 危害类别的评估。微软利用受 [BSA+ 24] 启发修改的有用和无害偏好数据集 [BJN+ 22、JLD+ 23] 和多个内部生成的数据集来解决安全性后训练(post-training)的 RAI 危害类别。微软一个独立的 red team 反复检查了 phi-3-mini,以进一步确定后训练过程中需要改进的领域。
根据 red team 的反馈,研究团队整理了额外的数据集从而完善后训练数据集。这一过程导致有害响应率显著降低,如图 3 所示。
下表显示了 phi-3-mini-4k 和 phi-3-mini-128k 与 phi-2、Mistral-7B-v0.1、Gemma 7B 的内部多轮对话 RAI 基准测试结果。该基准测试利用 GPT-4 模拟五个不同类别的多轮对话并评估模型响应。
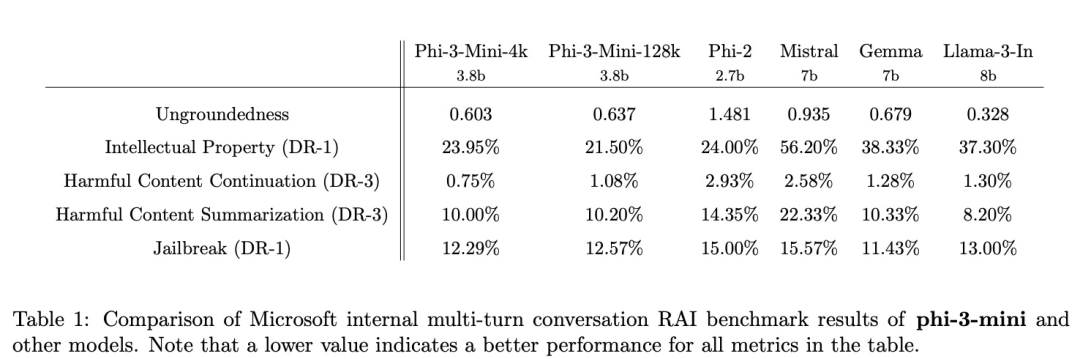
缺陷
微软表示,就 LLM 能力而言,虽然 phi-3-mini 模型达到了与大型模型相似的语言理解和推理能力水平,但它在某些任务上仍然受到其规模的根本限制。例如,该模型根本没有能力存储太多「事实知识」,这可以从 TriviaQA 上的低评分中看出。不过,研究人员相信这些问题可以通过搜索引擎增强的方式来解决。

ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
更多资源欢迎关注


