- 1《崇明新闻》报道智慧岛大数据云计算中心
- 2【论文笔记】D2A U-Net: Automatic segmentation of COVID-19 CT slices based on dual attention and hybrid di_gam注意力论文
- 3【安卓笔记】gradle入门_gardlew 执行指定任务
- 4SpringCloud——Eureka
- 5python爬取视频自动播放_介绍一个python视频处理库:moviepy
- 6iOS创建.a和.framework静态库,及Bundle资源文件的使用_framework bundle文件
- 7【强化学习-医疗】医疗保健中的强化学习:综述_强化学习在医疗行业的应用
- 8vue科大讯飞文字转语音
- 9Xinlinx FPGA内的存储器BRAM全解_xilinx fpga bram 分布
- 10一对一关联查询注解@OneToOne的实例详解(一)_@onetoone属性
Prometheus+Grafana通过kafka_exporter监控kafka_message in per second指标
赞
踩
Prometheus+Grafana通过kafka_exporter监控kafka
原文地址:
CSDN:GeekXuShuo:Prometheus 监控之 kafka
简书:whaike:【监控】Kafka - 详细指标
在与Prometheus的合作中,网络上很多的exporter其数据都来源于zookeeper,自kafka升级到版本2以后,数据不往zookeeper中写入了。
版本2以后的kafka,我使用了kafka-offset-exporter来作为kafka的exporter与Prometheus配合。
kafka本身就已经自带了监控,通过Yammer Metrics进行指标暴露与注册,可通过JMX进行指标收集。
默认情况下, Kafka metrics 所有的 metric 都可以通过 JMX 获取,暴露kafka metrics 支持两种方式
1.在 Kafka Broker 外部, 作为一个独立进程, 通过 JMX 的 RMI 接口读取数据. 这种方式的好处是有任何调整不需要重启 Kafka Broker 进程, 缺点是多维护了一个独立的进程。
2.在 Kafka Broker 进程内部读取 JMX 数据, 这样解析数据的逻辑就在 Kafka Broker 进程内部, 如果有任何调整, 需要重启 Broker。
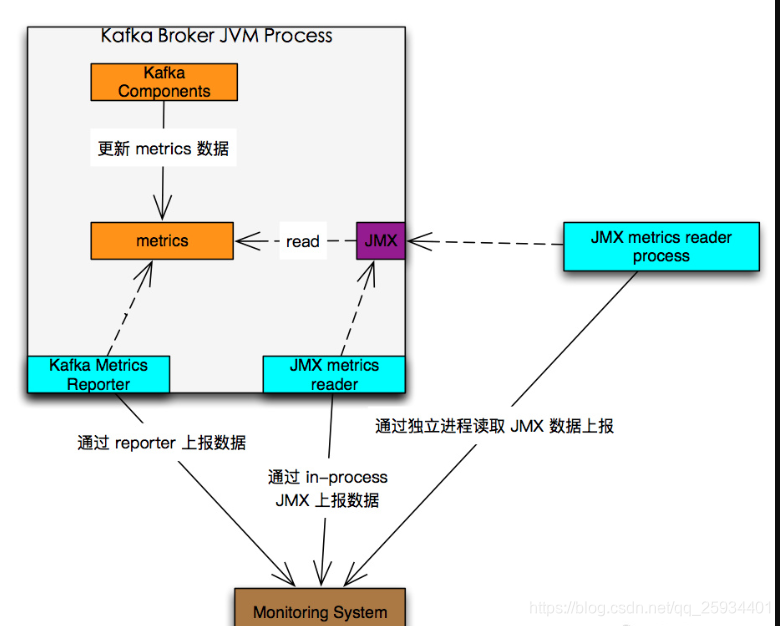
一、暴露 kafka-metric 方式
第一种需要外部多维护一个程序,而且还要考虑之后各种版本升级,实现起来比较繁琐,还好的是github上有许多优秀的开源kafka_exporter 下载过来直接启动就好了。
git项目地址:https://github.com/danielqsj/kafka_exporter
下载地址: https://github.com/danielqsj/kafka_exporter/releases/download/v1.2.0/kafka_exporter-1.2.0.linux-amd64.tar.gz
要在你想监控kafka的机器上装上kafka_exporter,每个都要装,如157、158、159:
启动:
# 解压kafka_exporter,进到目录,执行命令:
nohup ./kafka_exporter --kafka.server=10.131.178.157:9092 &
kafka_exporter --kafka.server=kafka:9092 [--kafka.server=another-server ...]
- 1
- 2
- 3
- 4
经测试,这种方式可以获取到kafka的指标数据,但是没有合适的Grafana的Dashboard支撑。
二、jmx_exporter方式
(这种方式,自己搭建起来后,9999端口和9991端口一直打不开,暂未查明原因,还在研究之中。)
第二种是读取 JMX 的数据. Prometheus 官方的组件 jmx_exporter 把两种实现都提供了:
- jmx_prometheus_httpserver 通过独立进程读取 JMX 的数据
- jmx_prometheus_javaagent 使用 Java Agent 方式, 尽量无侵入(仅需在 java 命令行中使用 -javaagent 参数)的启动 in-process library, 读取 JMX 数据.
- Prometheus 采用了 PULL 方式, Prometheus 主动抓取 metrics 数据, 而不是靠客户端主动 PUSH 数据, 因此 jmx_prometheus 都是通过暴露 HTTP 端口的方式暴露 metrics 数据, 方便 Prometheus 抓取数据。
2.1 下载jmx_prometheus_javaagent和kafka.yml
wget https://raw.githubusercontent.com/prometheus/jmx_exporter/master/example_configs/kafka-0-8-2.yml
wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.6/jmx_prometheus_javaagent-0.6.jar
- 1
- 2
打开 kafka-server-start.sh 文件
添加几行代码:
export JMX_PORT="9999"
export KAFKA_OPTS="-javaagent:/path/jmx_prometheus_javaagent-0.6.jar=9991:/path/kafka-0-8-2.yml"
- 1
- 2
然后重启kafka。
访问 http://localhost:9991/metrics 可以看到各种指标了。
在/opt/kafka目录编辑kafka-*.yaml
配置1(面向kafka2.0以前的版本):【部分指标匹配,且部分配置只在低版本kafka有效,例如kafka.consumer等】:
hostPort: 127.0.0.1:9999 lowercaseOutputName: true whitelistObjectNames: - "kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec" - "kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec" - "kafka.network:type=RequestMetrics,name=RequestsPerSec,request={Produce|FetchConsumer|FetchFollower}" - "kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec" - "kafka.network:type=RequestMetrics,name=TotalTimeMs,request={Produce|FetchConsumer|FetchFollower}" - "kafka.network:type=RequestMetrics,name=RequestQueueTimeMs,request={Produce|FetchConsumer|FetchFollower}" #- "kafka.consumer:type=consumer-fetch-manager-metrics,client-id={client-id}" - "kafka.server:type={Produce|Fetch},user=([-.\\w]+),client-id=([-.\\w]+)" - "kafka.server:type=Request,user=([-.\\w]+),client-id=([-.\\w]+)" - "kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\\w]+)" - "kafka.producer:type=[consumer|producer|connect]-node-metrics,client-id=([-.\\w]+),node-id=([0-9]+)" - "kafka.producer:type=producer-metrics,client-id=([-.\\w]+)" - "kafka.producer:type=producer-topic-metrics,client-id=([-.\\w]+),topic=([-.\\w]+)" - "kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\\w]+)" - "kafka.consumer:type=consumer-fetch-manager-metrics,client-id={client-id}" - "kafka.consumer:type=consumer-fetch-manager-metrics,client-id={client-id},topic={topic}" - "kafka.streams:type=stream-metrics,client-id=([-.\\w]+)" - "kafka.streams:type=stream-task-metrics,client-id=([-.\\w]+),task-id=([-.\\w]+)" - "kafka.streams:type=stream-processor-node-metrics,client-id=([-.\\w]+),task-id=([-.\\w]+),processor-node-id=([-.\\w]+)" - "kafka.streams:type=stream-[store-type]-state-metrics,client-id=([-.\\w]+),task-id=([-.\\w]+),[store-type]-state-id=([-.\\w]+)" - "kafka.streams:type=stream-record-cache-metrics,client-id=([-.\\w]+),task-id=([-.\\w]+),record-cache-id=([-.\\w]+)"

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
配置2(面向kafka2.0以后的版本):【kafka2.0以后,匹配所有jmx指标(虚拟机测试每次请求约2秒,生产环境大约10秒。Prometheus默认15秒请求一次)】:
lowercaseOutputName: true jmxUrl: service:jmx:rmi:///jndi/rmi://192.168.112.129:9999/jmxrmi ssl: false rules: - pattern : JMImplementation<type=(.+)><>(.*) - pattern : com.sun.management<type=(.+)><>(.*) - pattern : java.lang<type=(.+)><>(.*) - pattern : java.nio<type=(.+)><>(.*) - pattern : java.util.logging<type=(.+)><>(.*) - pattern : kafka<type=(.+)><>(.*) - pattern : kafka.controller<type=(.+)><>(.*) - pattern : kafka.coordinator.group<type=(.+)><>(.*) - pattern : kafka.coordinator.transaction<type=(.+)><>(.*) - pattern : kafka.log<type=(.+)><>(.*) - pattern : kafka.network<type=(.+)><>(.*) - pattern : kafka.server<type=(.+)><>(.*) - pattern : kafka.utils<type=(.+)><>(.*)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
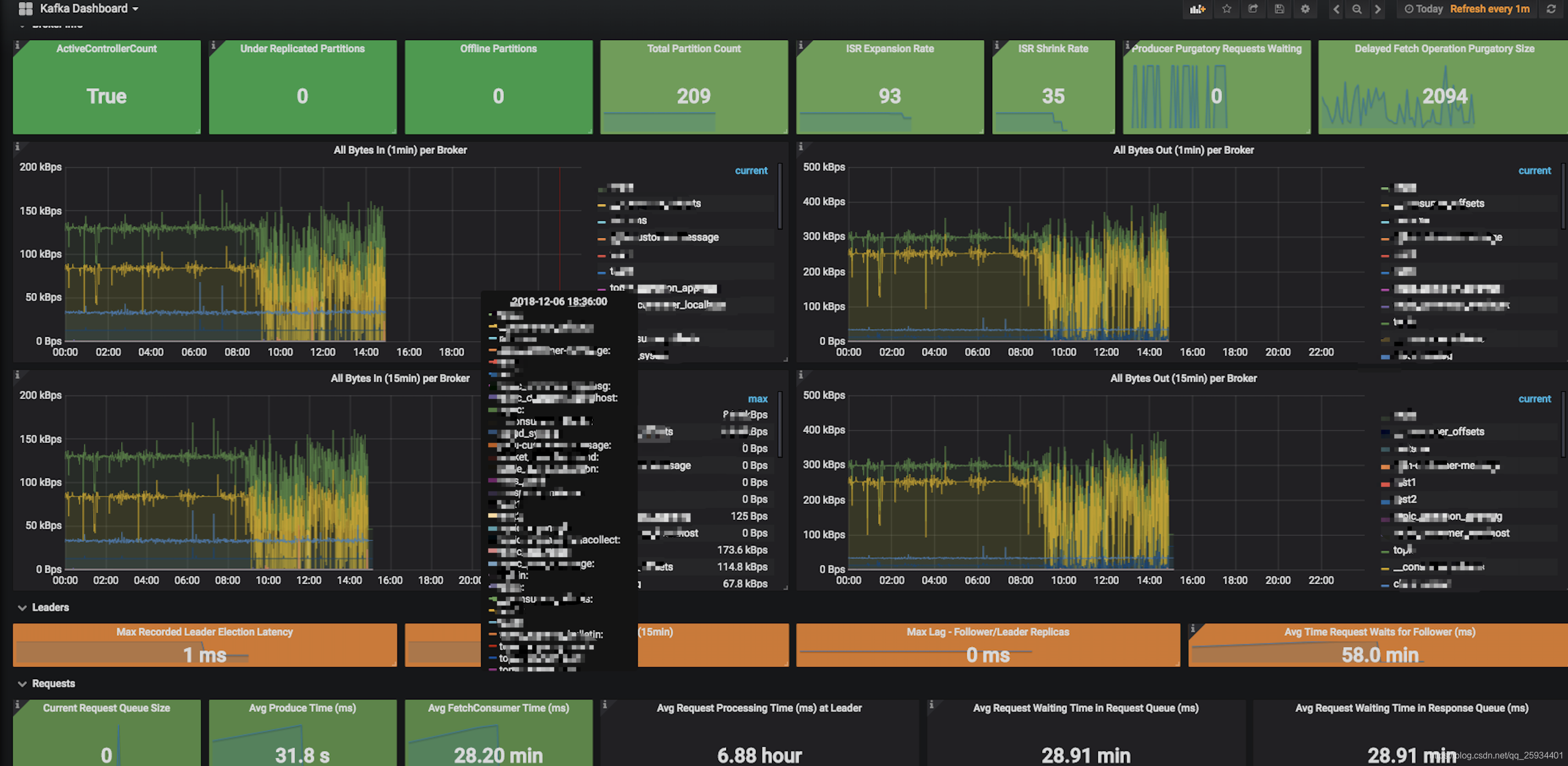
2.2 监控指标

2.3 预警指标分析
kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions **
含义: 正在复制的 Partition 的数量.
建议报警阈值: > 0 就建议报警. 但如果 Kafka 集群正在 reassign partition 时, 这个值也会 >0
kafka.controller:type=KafkaController,name=OfflinePartitionsCount
含义: 没有 Leader 的 Partition 的数量. 处于这个状态的 Partition 是不可读也不可写
建议报警阈值: >0 一旦出现就报警.
kafka.controller:type=KafkaController,name=ActiveControllerCount
含义: 活跃的 Controller 的数量.
建议报警阈值: != 0 就赶紧报警
kafka.server:type=ReplicaManager,name=PartitionCount
含义: 集群中 Partition 的总数
建议报警阈值: 感觉这个报警不可控.
kafka_controller_controllerstats_leaderelectionrateandtimems
含义: Leader election rate 领导人选举率
UncleanLeaderElectionsPerSec
含义: Unclean leader election rate 争议的 leader 选举次数
描述:所有的topic的消息速率(消息数/秒)
Mbean名:“kafka.server”:name=“AllTopicsMessagesInPerSec”,type=“BrokerTopicMetrics”
正常的值:
描述:所有的topic的流入数据速率(字节/秒)
Mbean名:“kafka.server”:name=“AllTopicsBytesInPerSec”,type=“BrokerTopicMetrics”
正常的值:
描述:producer或Fetch-consumer或Fetch-follower的请求速率(请求次数/秒)
Mbean名:“kafka.network”:name="{Produce|Fetch-consumer|Fetch-follower}-RequestsPerSec",type=“RequestMetrics”
正常的值:
描述:所有的topic的流出数据速率(字节/秒)
Mbean名: “kafka.server”:name=“AllTopicsBytesOutPerSec”,type=“BrokerTopicMetrics”
正常的值:
描述:刷日志的速率和耗时
Mbean名: “kafka.log”:name=“LogFlushRateAndTimeMs”,type=“LogFlushStats”
正常的值:
描述:正在做复制的partition的数量(|ISR| < |all replicas|)
Mbean名:“kafka.server”:name=“UnderReplicatedPartitions”,type=“ReplicaManager”
正常的值:0
描述:当前的broker是否为controller
Mbean名:“kafka.controller”:name=“ActiveControllerCount”,type=“KafkaController”
正常的值:在集群中只有一个broker的这个值为1
描述:选举leader的速率
Mbean名:“kafka.controller”:name=“LeaderElectionRateAndTimeMs”,type=“ControllerStats”
正常的值:如果有broker挂了,此值非0
描述:Unclean的leader选举速率
Mbean名:“kafka.controller”:name=“UncleanLeaderElectionsPerSec”,type=“ControllerStats”
正常的值:0
描述:该broker上的partition的数量
Mbean名: “kafka.server”:name=“PartitionCount”,type=“ReplicaManager”
正常的值:应在各个broker中平均分布
描述:Leader的replica的数量
Mbean名: “kafka.server”:name=“LeaderCount”,type=“ReplicaManager”
正常的值:应在各个broker中平均分布
描述:ISR的收缩(shrink)速率
Mbean名:“kafka.server”:name=“ISRShrinksPerSec”,type=“ReplicaManager”
正常的值:如果一个broker挂掉了,一些partition的ISR会收缩。当那个broker重新起来时,一旦它的replica完全跟上,ISR会扩大(expand)。除此之外,正常情况下,此值和下面的扩大速率都是0。
描述:ISR的扩大(expansion)速率
Mbean名: “kafka.server”:name=“ISRExpandsPerSec”,type=“ReplicaManager”
正常的值:参见ISR的收缩(shrink)速率
描述:follower落后leader replica的最大的消息数量
Mbean名:“kafka.server”:name="([-.\w]+)-MaxLag",type=“ReplicaFetcherManager”
正常的值:小于replica.lag.max.messages
描述:每个follower replica落后的消息速率
Mbean名:“kafka.server”:name="([-.\w]+)-ConsumerLag",type=“FetcherLagMetrics”
正常的值:小于replica.lag.max.messages
描述:等待producer purgatory的请求数
Mbean名:“kafka.server”:name=“PurgatorySize”,type=“ProducerRequestPurgatory”
正常的值:如果ack=-1,应为非0值
描述:等待fetch purgatory的请求数
Mbean名:“kafka.server”:name=“PurgatorySize”,type=“FetchRequestPurgatory”
正常的值:依赖于consumer的fetch.wait.max.ms的设置
描述:一个请求(producer,Fetch-Consumer,Fetch-Follower)耗费的所有时间
Mbean名:“kafka.network”:name="{Produce|Fetch-Consumer|Fetch-Follower}-TotalTimeMs",type=“RequestMetrics”
正常的值:包括了queue, local, remote和response send time
描述:请求(producer,Fetch-Consumer,Fetch-Follower)在请求队列中的等待时间
Mbean名:“kafka.network”:name="{Produce|Fetch-Consumer|Fetch-Follower}-QueueTimeMs",type=“RequestMetrics”
正常的值:
描述:请求(producer,Fetch-Consumer,Fetch-Follower)在leader处理请求花的时间
Mbean名:“kafka.network”:name="{Produce|Fetch-Consumer|Fetch-Follower}-LocalTimeMs",type=“RequestMetrics”
正常的值:
描述:请求(producer,Fetch-Consumer,Fetch-Follower)等待follower花费的时间
Mbean名:“kafka.network”:name="{Produce|Fetch-Consumer|Fetch-Follower}-RemoteTimeMs",type=“RequestMetrics”
正常的值:producer的ack=-1时,非0才正常
描述:发送响应花费的时间
Mbean名:“kafka.network”:name="{Produce|Fetch-Consumer|Fetch-Follower}-ResponseSendTimeMs",type=“RequestMetrics”
正常的值:
描述:consumer落后producer的消息数量
Mbean名:“kafka.consumer”:name="([-.\w]+)-MaxLag",type=“ConsumerFetcherManager”
正常的值:
建议对GC耗时和其他参数和诸如系统CPU,I/O时间等等进行监控。在client端,建议对"消息数量/字节数"的速率(全局的和对于每一个topic),请求的"速率/大小/耗时"进行监控。还有consumer端,所有partition的最大的落后情况和最小的fetch请求的速率。consumer为了能跟上,最大落后数量需要少于一个threshold并且最小fetch速率需要大于0.
2.4 Grafana Dashboard JSON
json文件链接:https://pan.baidu.com/s/1H6MesKpqi80R14OF5k7auQ 密码:kiox