
- 1python解析浏览器UA_python解析ua
- 2Domain adaptation from daytime to nighttime: A situation-sensitive vehicle detection and traffic…(翻)_this dataset, dapt 2020, was created with network
- 3Linux环境搭建以及项目部署问题总结_验证php与nginx的联动性
- 4Python Flask Web教程:make_response的详细用法_python make_response 跳转
- 5微信小程序-好友列表右侧字母导航功能_微信小程序字母导航
- 6在vue和小程序中使用腾讯实时音视频RTC(小程序端)_腾讯实时音视频 vue和小程序不在同一个环境
- 7CSV 文件是什么_csv是什么格式文件
- 8ElastchSearch 基本使用姿势_elatiscsearch 使用
- 9代码提示工具只显示一行 和 cssrem 不能转换单位的问题_command 'extension.cssrem.rpx-switch-px' not found
- 10智源社区2024 AI科研趋势调研开启!参与有礼
Hive分区分桶_为啥hive分桶了最后只有一个桶
赞
踩
分区
分区概念
在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的列值存储在表目录的子目录中,目录名=“分区键=键值”。其中需要注意的是分区键的值不一定要基于表的某一列(字段),它可以指定任意值,只要查询的时候指定相应的分区键来查询即可。我们可以对分区进行添加、删除、重命名、清空等操作。分为静态分区和动态分区两种,静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。详细来说,静态分区的列实在编译时期,通过用户传递来决定的;动态分区只有在 SQL 执行时才能决定。
分区案例
Hive的分区功能可以帮助用户快速的查找和定位,这里我们给出了一个应用场景,通过使用Hive分区功能创建日期和小时分区,快速查找定位对应的用户与IP地址。具体步骤如下:
步骤 1 创建一张分区表,包含两个分区dt 黑龙江干部培训 www.sxganxun.cn 和ht分别表示日期和小时:
CREATE TABLE partition_table001 ( name STRING, ip STRING ) PARTITIONED BY (dt STRING, ht STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY " ";
步骤 2 启用hive动态分区时,需要设置如下两个参数:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
步骤 3 把partition_table001表某个日期分区下的数据(如下图所示)load到目标表partition_table002中。

- 如果没有目标表则创建目标表partition_table002:
CREATE TABLE IF NOT EXISTS partition_table002 LIKE partition_table001;

- 如果使用静态分区,必须指定分区的值,如将partition_table001表中日期分区为“20190520”、小时分区为“00”的数据加载入表partition_table002中:
INSERT OVERWRITE TABLE partition_table002 PARTITION (dt='20190520', ht='00') SELECT name, ip FROM partition_table001 WHERE dt='20190520' and ht='00';
查询一下表partition_table002中我们插入的数据,结果如下图所示:

- 如果希望插入每天24小时的数据,则需要执行24次上面的语句。而使用动态分区会根据select出的结果自动判断数据该load到哪个分区中去,只需要一句语句即可完成,命令及结果如下所示:
INSERT OVERWRITE TABLE partition_table002 PARTITION (dt, ht) SELECT * FROM partition_table001 WHERE dt='20190520';

步骤 4 查看表格partition_table002下的所有分区信息使用如下命令:
SHOW PARTITIONS partition_table002;
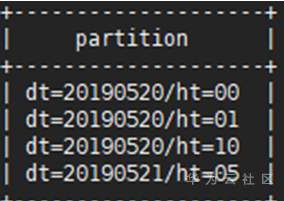
或者拥有admin权限的用户使用dfs –ls <表存储目录>命令如下:
dfs -ls hdfs://hacluster/user/hive/warehouse/partition_table002;

说明:
静态分区和动态分区可以混合使用,在动静结合使用时需要注意静态分区值必须在动态分区值的前面,在select中按位置顺序出现在最后(因为静态分区提前产生,动态分区运行时产生)。如果动态分区作为父路径,则子静态分区无法提前生成,会报错为动态分区不能为静态的父路径。当静态分区是动态分区的子分区时,执行DML操作会报错。因为分区顺序决定了HDFS中目录的继承关系,这点是无法改变的。
分桶
分桶概念
对于每一个表或者分区, Hive可以进一步组织成桶,也就是说分桶是更为细粒度的数据范围划分。Hive会计算桶列的哈希值再以桶的个数取模来计算某条记录属于那个桶。把表(或者分区)组织成桶(Bucket)有两个理由:
获得更高的查询处理效率。桶为表加上了额外的结构,Hive在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用Map端连接(Map-side join)高效的实现。
使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
分桶案例
步骤 1 创建一张含有桶的表格,例如创建一个含有四个桶的表格bucketed_table:
CREATE TABLE bucketed_table (id INT, name STRING) CLUSTERED BY (id) INTO 4 BUCKETS;
**步骤 2 ** 设置hive.enforce.bucketing属性为true,以便自动控制上reduce的数量从而适配bucket的个数,推荐命令如下(当然也可以手动设置参数“mapred.reduce.task”去适配bucket的个数,只是多次手动修改会比较麻烦):
set hive.enforce.bucketing = true;
步骤 3 向表里插入准备好的没有划分桶的数据,例如将没有划分桶的表users的数据插入目标表bucketed_table:
INSERT OVERWRITE TABLE bucketed_table SELECT * FROM users;
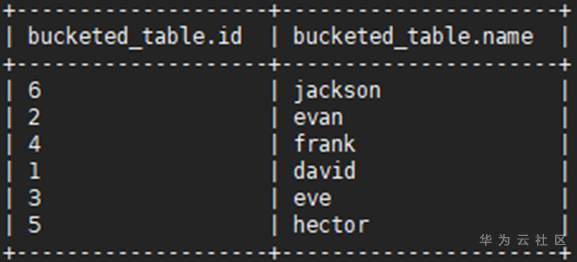
步骤 4 查看表格bucketed_table下的所有分桶信息,需要拥有admin权限的用户使用dfs –ls <表或分区存储目录>命令如下:
dfs -ls hdfs://hacluster/user/hive/warehouse/bucketed_table;

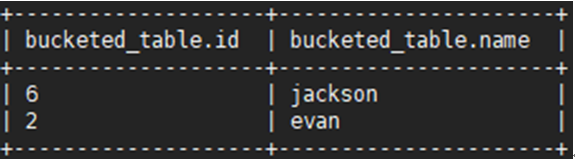
步骤 5 对桶中的数据进行采样,使用抽样命令TABLESAMPLE(BUCKET x OUT OF y),例如对表格bucketed_table从第一个桶开始抽取1个桶数据量的样本:
SELECT * FROM bucketed_table TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
说明:
抽样命令TABLESAMPLE(BUCKET x OUT OF y)中,y必须是表格中分桶数的倍数或者因子。Hive根据y的大小,决定抽样的比例。x表示从哪个桶开始抽取。例如,表格的总分桶数为16,tablesample(bucket 3 out of 8),表示总共抽取(16/8=)2个bucket的数据,分别为第3个桶和第(3+8=)11个桶的数据。
本文由华为云发布。

