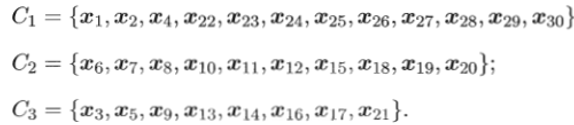- 1动作/行为识别调研_动作识别
- 2华为OD机试 - 多段线数据压缩(Java & JS & Python & C & C++)_多线段数据压缩华为od
- 3基于Python的豆瓣电影评论数据分析与可视化(源代码+可远程部署安装)_评论数据研究背景
- 4linux系统使用git对指定的文件进行回滚_linux git 回滚
- 5Python:“TypeError: list indices must be integers or slices, not str“问题解决方案
- 6实操指南:ORB-SLAM3的编译运行_orbslam3安装运行
- 72024 年第一季度勒索软件态势
- 8在使用python的Pip安装库时,报错:Fatal error in launcher:Unable to create process using ‘“‘_执行pip安装 fatal error in launcher:
- 9C语言链表实现
- 10linux中for引用变量,在 awk 中怎么使用循环 | Linux 中国
机器学习---半监督学习(基于分岐的方法)
赞
踩
1. 基于分歧的方法
与生成式方法、半监督SVM、图半监督学习等基于单学习器利用未标记数据不同,基于分歧的方
法(disagreement--based methods)使用多学习器,而学习器之间的“分歧”(disagreement)对未标记
数据的利用至关重要。
1.2 协同训练
“协同训练”(co-training)[Blum and Mitchell,l998]是此类方法的重要代表,它最初是针对“多视图”
(multi--view)数据设计的,因此也被看作“多视图学习”(multi--view learning)的代表。在介绍协同训
练之前,我们先看看什么是多视图数据。
在不少现实应用中,一个数据对象往往同时拥有多个“属性集”(attributeset),每个属性集就构成了
一个“视图”(view)。例如对一部电影来说,它拥有多个属性集:图像画面信息所对应的属性集、声
音信息所对应的属性集、字幕信息所对应的属性集、甚至网上的宣传讨论所对应的属性集等。每个
属性集都可看作一个视图。为简化讨论,暂且仅考虑图像画面属性集所构成的视图和声音属性集所
构成的视图。于是,一个电影片段可表示为样本(<x1,x2>,y),其中x是样本在视图元中的示例,即
基于该视图属性描述而得的属性向量,不妨假定x1为图像视图中的属性向量,x2为声音视图中的属
性向量;y是标记,假定是电影的类型,例如“动作片”、“爱情片”等。(<x1,x2>,y)这样的数据就是多
视图数据。
假设不同视图具有“相容性”(compatibility),即其所包含的关于输出空间y的信息是一致的:令y1表
示从图像画面信息判别的标记空间,y2表示从声音信息判别的标记空间,则有y=y1=y2,例如两者
都是{爱情片,动作片},而不能是y1={爱情片,动作片},而y2={文艺片,惊悚片}。在此假设下,
显式地考虑多视图有很多好处。仍以电影为例,某个片段上有两人对视,仅凭图像画面信息难以分
辨其类型,但此时若从声音信息听到“我爱你”,则可判断出该片段很可能属于“爱情片”;另一方
面,若仅凭图像画面信息认为“可能是动作片”,仅凭声音信息也认为“可能是动作片”,则当两者一
起考虑时就有很大的把握判别为“动作片”。显然,在“相容性”基础上,不同视图信息的“互补性”会给
学习器的构建带来很多便利。
协同训练正是很好地利用了多视图的“相容互补性”。假设数据拥有两个充分(sufficient)且条件独立
视图,“充分”是指每个视图都包含足以产生最优学习器的信息,“条件独立”则是指在给定类别标记
条件下两个视图独立。在此情形下,可用一个简单的办法来利用未标记数据:首先在每个视图上基
于有标记样本分别训练出一个分类器,然后让每个分类器分别去挑选自己“最有把握的”未标记样本
赋予伪标记,并将伪标记样本提供给另一个分类器作为新增的有标记样本用于训练更新…,这个
“互相学习、共同进步”的过程不断迭代进行,直到两个分类器都不再发生变化,或达到预先设定的
迭代轮数为止,算法描述如图所示。若在每轮学习中都考察分类器在所有未标记样本上的分类置信
度,会有很大的计算开销,因此在算法中使用了未标记样本缓冲池[Blum and Mitchell,,l998]。分类
置信度的估计则因基学习算法而异,例如若使用朴素贝叶斯分类器,则可将后验概率转化为分类置
信度;若使用支持向量机,则可将间隔大小转化为分类置信度。

协同训练过程虽简单,但令人惊讶的是,理论证明显示出,若两个视图充分且条件独立,则可利用
未标记样本通过协同训练将弱分类器的泛化性能提升到任意高[Blum and Mitchel,l998]。不过,视
图的条件独立性在现实任务中通常很难满足,因此性能提升幅度不会那么大,但研究表明,即便在
更弱的条件下,协同训练仍可有效地提升弱分类器的性能[周志华,2013]。
协同训练算法本身是为多视图数据而设计的,但此后出现了一些能在单视图数据上使用的变体算
法,它们或是使用不同的学习算法[Goldman and Zhou,2000],或使用不同的数据采样[Zhou and
Li,2005b],甚至使用不同的参数设置[Zhou and Li,2005a]来产生不同的学习器,也能有效地利用未
标记数据来提升性能。后续理论研究发现,此类算法事实上无需数据拥有多视图,仅需弱学习器之
间具有显著的分歧(或差异),即可通过相互提供伪标记样本的方式来提升泛化性能[周志华,
2013];不同视图、不同算法、不同数据采样、不同参数设置等,都仅是产生差异的渠道,而非必
备条件。
基于分歧的方法只需采用合适的基学习器,就能较少受到模型假设、损失函数非凸性和数据规模问
题的影响,学习方法简单有效、理论基础相对坚实、适用范围较为广泛。为了使用此类方法,需能
生成具有显著分歧、性能尚可的多个学习器,但当有标记样本很少,尤其是数据不具有多视图时,
要做到这一点并不容易,需有巧妙的设计。
Co-training 是基于分歧的方法,其假设每个数据可以从不同的角度(view)进行分类,不同角度
可以训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选
出认为可信的无标签样本加入训练集中。由于这些分类器从不同角度训练出来的,可以形成一种互
补,而提高分类精度;就如同从不同角度可以更好地理解事物一样。该方法虽然理论很强,但却有
一定的假设条件(事实上半监督学习都是在一定的假设条件下进行的),引用周志华大大《基于分
歧的半监督学习》中的描述:
协同训练法要求数据具有两个充分冗余且满足条件独立性的视图:
①“充分(Sufficient)” 是指每个视图都包含足够产生最优学习器的信息,此时对其中任一视图来
说,另一个视图则是“冗余(Redundant)” 的;
②对类别标记来说这两个视图条件独立。
这个数据假设就很强力了,既要求数据信息充分还冗余,你还要找到两个独立互补的视图。但是,
在一定程度上满足条件的情况下,co-training 的效果也是非常给力。 那么,在半监督深度学习
里,co-training 会以什么方式呈现呢?问题的关键自然在于,如何去构建两个(或多个)近似代表
充分独立的视图的深度模型,两个比较直观的方法就是:使用不同的网络架构(据我看过的论
文 [1] [2] 中指出,哪怕是对同一个数据集,不同的网络架构学习到的预测分布是不一样的);使用
特殊的训练方法来得到多样化的深度模型。

这是一篇ECCV2018的文章,论文首先指出,直接对同一个数据集训练两个网络,会有两个弊端:
对同一个数据集训练两个网络,并不能保证两个网络具有不同的视图,更不能保证具有不同且互补
的信息;协同训练会使得两个网络在训练过程中趋于一致,会导致collapsed neural networks,进
而使得协同训练失效。
为了解决上述问题,论文主要做了两个工作:
①提出了一个新的代价函数,进行协同训练,其形式如下:

均匀分布的熵最大,当两个预测分布不一致时,这两个预测分布求和取平均会使得熵增大。相反,
如果预测一致熵就不会增加多少。 论文中还明确强调,该代价函数只用在无标签数据上,因为有
标签数据的监督代价函数(论文用的交叉熵)已经使得预测趋于一致(趋于真实标签),用在有标
签数据上没有必要,但是好像没说明也用在有标签数据上的后果。
②(关键)提出了 View Difference Constraint。其思路是:我们只有一个数据集 D,但我们不能再
同一个数据集上训练两个网络,因此需要从 D 中派生出另一个数据集 D',而这个派生方法就是计
算 D 的对抗样本。具体即使用对方的对抗样本来训练自己:
![]()
其中, g1(x) 表示网络 p1 的对抗样本, H(·) 是某种代价函数(KL 散度),该约束的设计期望是
使得两个网络具备不同却互补信息。

Tri-net 是 IJCAI 2018 的论文。论文称类协同训练为 disagreement-based semi-supervised
learning,其关键在于训练多个分类器,已经对不同视图上的不一致性的探索。为此,论文从三个
方面改进:model initialization,diversity augmentation 和 pseudo-label editing。
在展开这三个贡献点之前,我们先来看看Ti-net的网络架构:
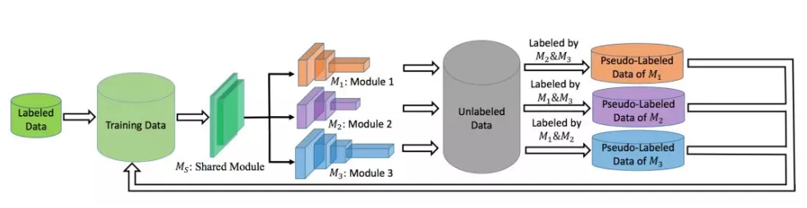
按照把网络架构分为低层抽象和高层抽象部分,Ti-net架构中的Ms是一个共享的低层抽象部分,而
Tri-net的高层抽象部分是用三个不同的网络架构组成。
然后其训练过程主要分为两部分:①使用Output Smearing处理的有标签数据初始化网络,可以使
不同的高层抽象具有不同的预测分布;②Tri-training网络:如果有两个高层抽象对一个样本具有一
致预测,且该预测可信且稳定,则把该样本作为加入到第三个高层抽象的训练数据中。同时,为了
防止collapsed neuralnetworks问题(Deep Co-Training提到),还会在某些epoch中继续使用
OutputSmearing训练网络,以增加不同高层抽象的diversity。
现在来看看论文的三个贡献点:①Output Smearing:同上文的Deep Co-Training的论文一样,该
论文也认为不能直接在同一个数据集D上直接训练网络,Output Smearing通过向有标签数据的添
加随机噪声来构造不同的数据集D1、D2、D3,分别用来初始化对应的高层抽象部分M1、M2、
M3,这样就能使用高层抽象部分多样化(即代表不同视图)。②Diversity Augmentation:为了解
决collapsed neural networks问题,在特定的epoch继续使用output smearing数据集来fine-tune网
络,以继续增强多样化;③Pseudo-Label Editing:Tri-training训练时,需要挑选可靠且稳定的无标
签样本加入训练集,如何确定预测的样本是可靠且稳定?
本身Tri-training这种类协同训练挑选的样本就具有很强的可靠,论文提出一个的方法Pseudo-label
editing:通过Dropout的随机性,对样本进行多次预测,如果多次预测的结果都几乎一样,则认为
是稳定的。模型的缺点也相对明显,训练过程相对复杂,感觉靠经验设计;Pseudo-label editing需
要进行多次预测,估计计算负担也挺重的。

这篇 ECCV 2018 的论文是做人脸识别的,主要提出了一个 Consensus-driven propagation 的算
法,该算法主要由三部分:Committee,Mediator 和 Pseudo Label Propagation 组成。
①Commitee:需要用有标签数据训练一个 base model 和 N 个 committee models,而且这些
models 都需要使用不同的网络架构,以保证 diversity (信息的多样性)。然后使用这些 models
提取深度特征,构建 KNN 图,并进一步获取三种信息:
Relationship:0-1 邻接图,若两个节点在所有的 committee models 的 KNN图中都邻接,则为 1
(为什么要排除 base model?)。
Affinity:节点间的相似性信息,论文用余弦相似度。
Local structures w.r.t each node:一个节点与其他所有节点的相似性信息,论文用余弦相似度。
②Mediator:一个全连接网络,用来融合上面的多视图信息,来判断正的样本对,和负的样本对。
③Pseudo Label Propagation:一个对无标签数据赋 pseudo label 的算法,通过 mediator 给出的
正样本对的概率作为相似度量,貌似通过一种类似聚类的方法,给样本赋 pseudo label。
2. 半监督聚类
聚类是一种典型的无监督学习任务,然而在现实聚类任务中我们往往能获得一些额外的监督信息,
于是可通过半监督聚类(semi-supervised clustering)来利用监督信息以获得更好的聚类效果。聚类
任务中获得的监督信息大致有两种类型。第一种类型是“必连”(must-link)与“勿连”(cannot-link)约
束,前者是指样本必属于同一个簇,后者是指样本必不属于同一个簇;第二种类型的监督信息则是
少量的有标记样本。
约束k均值(Constrained k-means)算法Wagstaff et al..,200l]是利用第一类监督信息的代表。给定样
本集D={c1,x2,·,m}以及“必连”关系集合M和“勿连”关系集合C,(x,x)∈M表示xi与xj必属于同簇,
(xi,xj)∈C表示:xi与xj必不属于同簇。该算法是k均值算法的扩展,它在聚类过程中要确保M与C中
的约束得以满足,否则将返回错误提示,算法如图所示。

以西瓜数据集4.0为例,令样本x4与x25,x12与x20,x14与x17之间存在必连约束,x2与x21,x13
与x23,x19与x23之间存在勿连约束,即
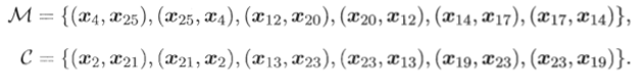
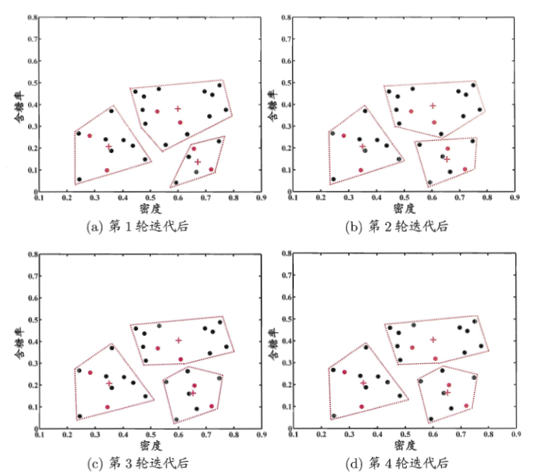
设聚类簇数k=3,随机选取样木x6,x12,x27作为初始均值向量,下图显示出约束k均值算法在不
同迭代轮数后的聚类结果。经5轮迭代后均值向量不再发生变化(与第4轮迭代相同),于是得到最
终聚类结果:
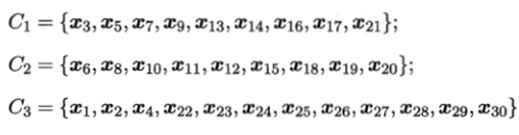
第二种监督信息是少量有标记样本。给定样本集D={x1,x2,...,xm},假定少量的有标记样本为
![]() ,其中
,其中![]() 为隶属于第j个聚类簇的样本.这样的监督信息利用起来很容易:直
为隶属于第j个聚类簇的样本.这样的监督信息利用起来很容易:直
接将它们作为“种子”,用它们初始化k均值算法的k个聚类中心,并且在聚类簇迭代更新过程中不改
变种子样本的簇隶属关系。这样就得到了约束种子k均值(Constrained Seedk-means)算法Basu et
al.,2002),其算法描述如图所示。

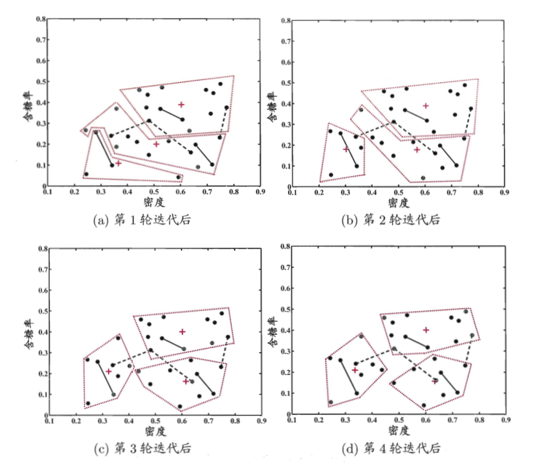
仍以西瓜数据集4.0为例,假定作为种子的有标记样本为
![]()
以这三组种子样本的平均向量作为初始均值向量,下图显示出约束种子及均值算法在不同迭代轮数
后的聚类结果。经4轮迭代后均值向量不再发生变化(与第3轮迭代相同),于是得到最终聚类结果