
- 1图像去噪_数字图像处理中加法图像数量越多,去噪效果越好对不对
- 2【Neo4j构建知识图谱】配置知识图谱插件APOC与案例实现_知识图谱 前端插件
- 3java socket编程_Java TCP/IP Socket编程
- 4【数据集划分】oracle数据集划分(总结版)
- 5Linux操作系统内存管理(详解)_linux系统的内存管理
- 6黑客团伙利用Python、Golang和Rust恶意软件袭击印国防部门;OpenAI揭秘,AI模型如何被用于全球虚假信息传播? | 安全周报0531_cve-2024-1086 cvss
- 7FPGA 20个例程篇:7.FLASH读写断电存储_极化码 fpga 例程
- 8CentOS 7 搭建 Hadoop3.3.1集群_sentos7 格式化集群 启动
- 9启动vue项目时报错:digital envelope routines::unsupported
- 10live2dviewer android,live2dviewerex最新版
MySQL开窗函数_mysql 开窗函数
赞
踩
测试环境:mysql8.0.18
官方文档:https://dev.mysql.com/doc/refman/8.0/en/window-functions.html
一、窗口函数介绍
开窗函数是mysql8.0中的新特性,用于实现和group by分组函数类似的分组聚合功能。区别在于:
- 分组函数:对一个集合输出一个标量结果,改变了数据的粒度,且丢失了非分组字段及非聚合字段的信息。
- 开窗函数:分别以每一行为当前行,与当前行相关的所有行为窗口,对同一个窗口内的数据进行聚合等类似操作,结果附加到当前行的后面,不改变原始数据粒度,不丢失原始数据信息。
二、语法结构
开窗函数|聚合函数 over([分组函数] [排序函数] [自定义窗口]) ,over是进行开窗,里面的分组函数、排序函数、自定义窗口都可以省略。
开窗函数|聚合函数:不可省略,用于对窗口范围内的所有数据行进行某种指定操作。可以是只适用于开窗函数的非聚合函数(https://dev.mysql.com/doc/refman/8.0/en/window-functions-usage.html),也可以是适用于group by的聚合函数(https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html)。
分组函数:partition by ...,根据指定的字段对表分组,分组字段可以有多个。省略时表示整个表为一组。
排序函数:order by ...,排序字段也可以有多个,当排序字段为多个时表示先按照第一个字段排序,当第一个字段相等确定不了顺序时再按照第二个字段排序,以此类推…
三、自定义窗口
这部分可以直接查看文档https://dev.mysql.com/doc/refman/8.0/en/window-functions-frames.html,个人觉得这部分算是开窗函数里最重要的了,弄明白了各种情况下窗口的大小,其他的就没啥容易混淆的点了。
mysql中的窗口类型有两种:rows和range。rows是以物理行距离为基准通过计算与当前行的物理距离计算窗口大小,range是以当前行的值为基准通过计算与当前行值的差值计算窗口大小。
窗口大小可通过between 上界 and 下界来指定,其中,窗口的上下界分别有下面几种取值:
unbounded preceding:包含当前行及当前行之前的所有记录。n preceding:包含当前行及当前行之前的n-1行,实际窗口大小n。current row:仅包含当前行。unbounded following:包含当前行及当前行之后的所有记录。n following:包含当前行及当前行之后的n-1行,实际窗口大小n。
当窗口下界为current row时,可以不使用between and,也就是下面几种情况可简写:
1)between unbounded preceding and current row --> unbounded preceding
2)between n preceding and current row --> n preceding
3)between current row and current row --> current row
而following的情况不支持简写,原因可以参考下怎么理解mysql开窗函数 unbounded following这种简写形式不支持 而unbounded preceding支持,觉得有些道理。
1.rows(重点)
物理范围窗口,窗口大小只与当前行的物理距离有关。下面造点测试数据:
create table test_rows_range as select 1 as id, '2020-10-03' as trans_date, 349 as sales union all select 2 as id, '2020-10-01' as trans_date, 563 as sales union all select 3 as id, '2020-10-02' as trans_date, 716 as sales union all select 4 as id, '2020-10-05' as trans_date, 628 as sales union all select 5 as id, '2020-10-02' as trans_date, 412 as sales union all select 6 as id, '2020-10-02' as trans_date, 857 as sales union all select 7 as id, '2020-10-08' as trans_date, 201 as sales union all select 8 as id, '2020-10-05' as trans_date, 191 as sales union all select 9 as id, '2020-10-06' as trans_date, 675 as sales union all select 10 as id, '2020-10-08' as trans_date, 941 as sales;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

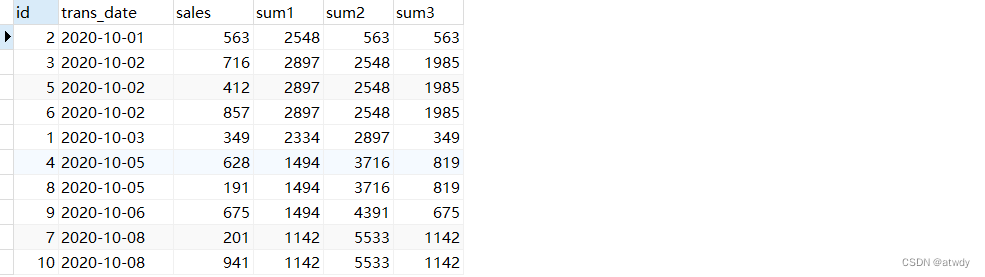
select *,
sum(sales) over(order by trans_date rows between 1 preceding and 1 following) as sum1, -- 当前行的前一行、后一行、及当前行共3行作为一个窗口
sum(sales) over(order by trans_date rows unbounded preceding) as sum2, -- 当前行及当前行之前的所有行为窗口
sum(sales) over(order by trans_date rows current row) as sum3 -- 仅取当前行为窗口
from test_rows_range;
- 1
- 2
- 3
- 4
- 5
output:

2.range
逻辑范围窗口,业务中一般都会和order by连用,否则使用range窗口没啥实际意义。range类型窗口的上下界依然可以沿用rows类型窗口的上下界,规则是以当前行order by字段的值为基准,对值按照指定的上下界范围进行加减操作以确定逻辑窗口上下界的值。例如当前行的值为3,自定义窗口大小为range between 2 preceding and 1 following,那么此时逻辑窗口的临界值为[3-2, 3+1] -> [1, 4],所有order by字段值在该范围内的行都属于当前行窗口中的记录。
这里有两个小细节:
1)因为range是以行的值为基准,按照指定的上下界对值进行加减操作以确定窗口上下临界值的范围,因此range窗口的order by排序字段只能是数值型或日期时间类型这样支持逻辑意义上加减的字段类型,否则像varchar这种类型就会报下面这个错误:
> 3587 - Window '<unnamed window>' with RANGE N PRECEDING/FOLLOWING frame requires exactly one ORDER BY expression, of numeric or temporal type
2)当排序字段为数值型时,自定义窗口的格式可以直接沿用rows中列举的上下界,例如range n preceding,这时窗口的上界值为当前行的值-n。但是如果为时间日期类型时对于n preceding这样的上界就不能使用了,因为mysql不知道是在这个时间日期的基础上-n day?还是-n hour?,因此需要用range between interval 1 day preceding and interval 1 day following这种语法格式明确一下,否则会报下面异常:
> 3588 - Window '<unnamed window>' with RANGE frame has ORDER BY expression of datetime type. Only INTERVAL bound value allowed.
但是,对于unbounded preceding这样的上界,就不用interval的形式指定,很好理解,这种上界包括了所有小于当前行的值的记录,此时是- day还是- hour已经不重要了。
-- 修改trans_date字段类型为date
alter table test_rows_range modify trans_date date;
select *,
sum(sales) over(order by trans_date range between interval 1 day preceding and interval 1 day following) as sum1, -- 当前行的日期&前一天的日期&后一天的日期 的所有行作为一个窗口
sum(sales) over(order by trans_date range unbounded preceding) as sum2, -- 所有小于等于当前行日期的行作为窗口
sum(sales) over(order by trans_date range current row) as sum3 -- 仅取和当前行日期相等的行作为窗口
from test_rows_range;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
output:
3.默认窗口
如果不显式指定窗口大小,则默认窗口大小主要分为over()中有没有order by子句两种情况:
- 没有
order by子句:默认窗口为每个组内的全部行。 - 有
order by子句:默认窗口为range unbounded preceding。
select *,
sum(sales) over() as sum1, -- 无order by,窗口范围为全部行
sum(sales) over(order by trans_date) as sum2 -- 有order by,窗口范围为当前行及之前的所有行
from test_rows_range;
- 1
- 2
- 3
- 4
output:

四、常用窗口函数示例
这部分可以直接查看文档https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
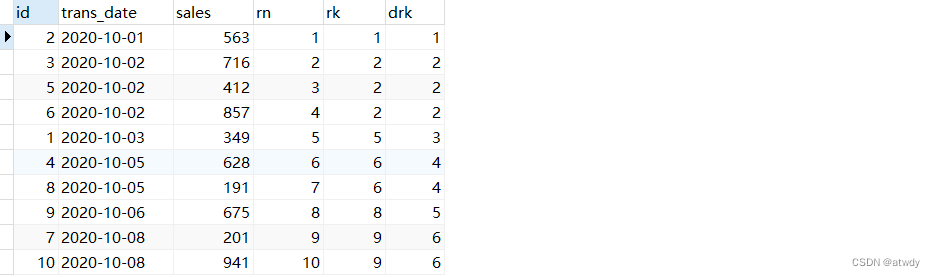
1.row_number & rank & dense_rank
这三个都是排序函数,区别在于:
- row_number():序号不重复,不间断。
- rank():序号可重复,可间断。
- dense_rank(),序号可重复,不间断。
select *,
row_number() over(order by trans_date) as rn,
rank() over(order by trans_date) as rk,
dense_rank() over(order by trans_date) as drk
from test_rows_range;
- 1
- 2
- 3
- 4
- 5
output:
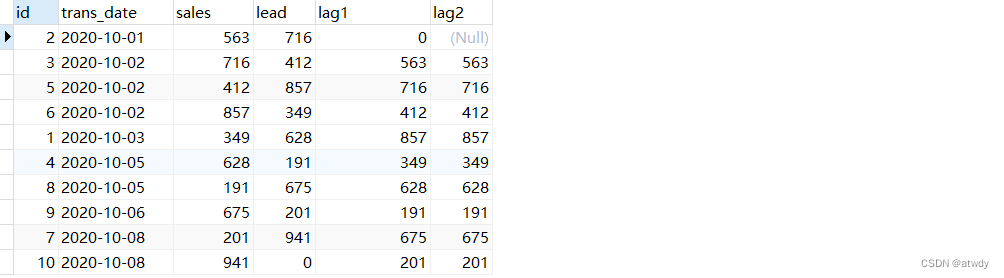
2.lead & lag
对指定字段整体上移(lead)或者下移(lag)。
- lead(col, n, default):上移。参数col表示移动的字段,不可缺省;参数n表示移动的距离,可缺省,缺省值默认值为1;参数default表示当出现空值时用来填充的默认值,可缺省,缺省时用null填充。
- lag(col, n, default):下移,参数含义同上。
select *,
lead(sales,1,0) over(order by trans_date) as `lead`, -- 将sales字段值整体上移1位,空值用0填充
lag(sales,1,0) over(order by trans_date) as lag1, -- 将sales字段值整体下移1位,空值用0填充
lag(sales) over(order by trans_date) as lag2 -- 将sales字段值整体下移1位,空值不处理
from test_rows_range;
- 1
- 2
- 3
- 4
- 5
output:
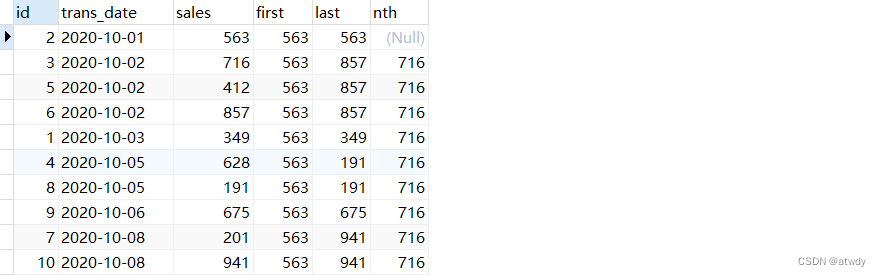
3.first_value & last_value & nth_value
下面几个函数的作用是取窗口中指定顺序的字段值。
- first_value(col):取窗口中字段col的第一个值。
- last_value(col):取窗口中字段col的最后一个值。
- nth_value(col, n):取窗口中第n顺序的值。
select *,
first_value(sales) over(order by trans_date) as `first`, -- 取每个窗口第一个值
last_value(sales) over(order by trans_date) as last, -- 取每个窗口最后一个值
nth_value(sales,2) over(order by trans_date) as nth -- 取每个窗口第二个值
from test_rows_range;
- 1
- 2
- 3
- 4
- 5
output:
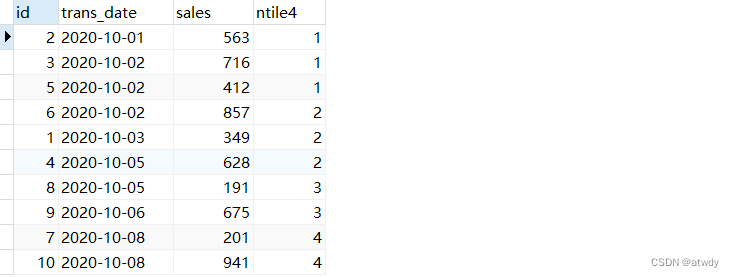
4.ntile
将数据分组。
- ntile(n):n是指定的组数。分组逻辑是从小到后为每条数据打上一个组号的标签,尽可能使每组内的数据相对均匀,当每组内的数据不能完全一样时,多余的数据优先给组号较小的分组。
select *,
ntile(4) over(order by trans_date) as ntile4 -- 数据均匀分为4组
from test_rows_range;
- 1
- 2
- 3
output:
5.cume_dist & percent_rank(了解)
这两个函数基本不用,了解即可,下面是两个函数的官方描述。


从文档中可以看到这两个函数都应该与order by放在一起使用,返回的结果也都和order by字段的值有关。
cume_dist:返回的是窗口中所有小于等于当前行order by字段的值的总行数 / 窗口所在的分组内的总行数。percent_rank:返回的是窗口中所有小于当前行order by字段的值的总行数 / 窗口所在的分组内的总行数-1。
select *,
cume_dist() over(order by trans_date) as `cume_dist`,
percent_rank() over(order by trans_date) as `percent_rank`
from test_rows_range;
- 1
- 2
- 3
- 4
output:
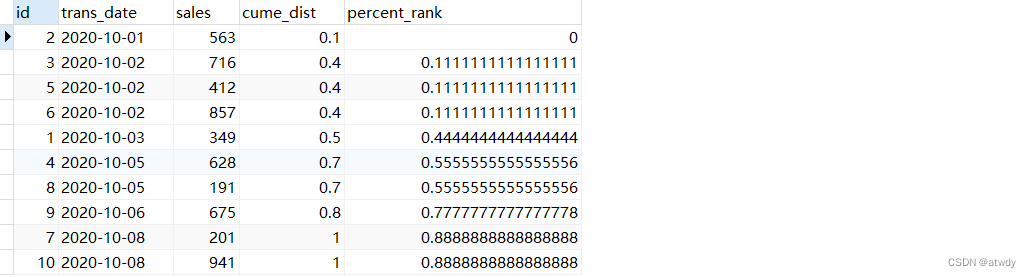
解释一下这个输出结果,默认窗口range unbounded preceding,对于cume_dist列,第一行trans_date为’2020-10-01’时,窗口内小于等于这一行的总行数为1,而这个窗口所在的分组也就是整个表总行数为10,因此第一行结果为0.1;而对于后面3个连续的0.4,是因为窗口类型为range,小于等于第二行值’2020-10-02’的总行数为4,所以结果为0.4。
对于percent_rank列,窗口所在的分组也就是整个表总行数为10,所以分母都为10-1=9。窗口内小于第一行’2020-10-01’的总行数为0,所以该列第一个值为0,后面以此类推…
PS
文档中没看到直接的描述,但在测试中发现了这两个函数有一些特点:
1)只适用于range类型窗口,这并不是说显式指定rows会报错,而是mysql忽略指定,输出的结果和range类型一致。
2)窗口范围自定义无效,也就是只能为默认窗口range unbounded preceding,像是修改为range between interval 1 day preceding and interval 1 day preceding无效。
select *,
cume_dist() over(order by trans_date) as dist_range,
cume_dist() over(order by trans_date rows unbounded preceding) as dist_rows,
percent_rank() over(order by trans_date) as percent_range,
percent_rank() over(order by trans_date rows unbounded preceding) as percent_rows,
percent_rank() over(order by trans_date range between interval 1 day preceding and interval 1 day preceding) as percent_range1 -- 自定义窗口无效,不影响输出
from test_rows_range;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
output:
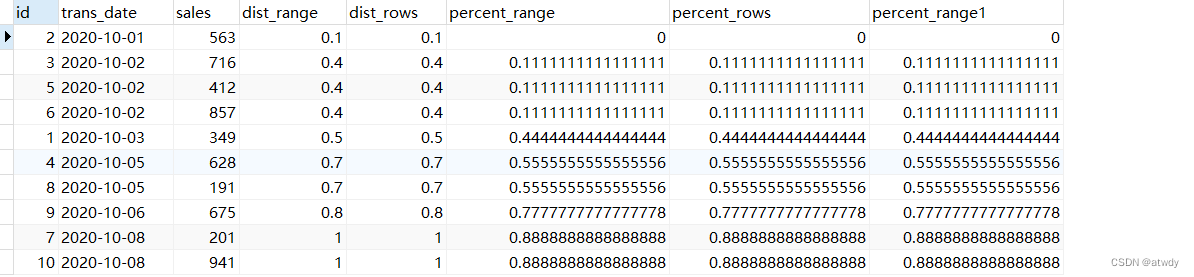
可以看到结果均无变化,我的理解是这两个函数都是用来计算某行记录在排序后的总体分布情况,因此rows类型的窗口因为忽略了重复值的影响所以不合适。而在此需求中更没必要让用户可以自定义指定窗口,因为这两个需求的总体思路都是按照当前行值在所有数据中的相对位置 / 所有记录数这样的思路来计算。

