
- 1ifconfig 与永久修改MAC地址_if修改mac
- 22022年软件测试——精选金融银行面试真题_银行软件测试面试题
- 3基于Python_opencv的车牌识别系统_基于python-opencv的车牌识别系统
- 4SpringCloudNetflix-Eureka+Ribbon的初使用_spirng-cloud-netflix-ribbon使用
- 5jupyter 目录插件 jupyter_contrib_nbextensions_jupyter目录插件
- 6华为OD机试Js - 路口最短时间问题_假定街道是棋盘型的,每格距离相等,车辆通过每格街道需要时间均为 timeperroad;街
- 7[office] 如何在Excel中拉动单元格时表头不变形- #学习方法#职场发展#经验分享_如何让单元格拉宽后首字符不动
- 8hive--小文件问题_hive 文件大小
- 9英文面试:性格爱好篇 (转)_性格开朗,做事认真,爱好运动用英语怎么说
- 10github版本库使用详细教程(命令行及图形界面版)_sign in via ldap
数据结构之初始泛型
赞
踩
找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程(ಥ_ಥ)-CSDN博客
所属专栏:数据结构(Java版)
目录
深入了解包装类
我们在最开始学习Java的数据类型时,就知道了Java的八大基本数据类型有自己对应的包装类,也就是引用类型。今天,我们就来彻底了解它们。
包装类的由来
在Java中,由于基本类型不是继承自Object类,为了在泛型代码中可以支持基本类型,Java给每个基本类型都创造了对应的一个包装类型。如下:
| 基本数据类型 | 包装类 类型 |
| byte | Byte |
| char | Character |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| boolean | Boolean |
装箱与拆箱
装箱也叫作:装包。就是把基本数据类型转换成其对应的包装类 类型。
例如:
- public class Test {
- public static void main(String[] args) {
- Integer a = 10;
-
- Integer c = new Integer(10);
-
- Integer b = Integer.valueOf(10);
-
-
- System.out.println(a);
- System.out.println(b);
- System.out.println(c);
- }
- }
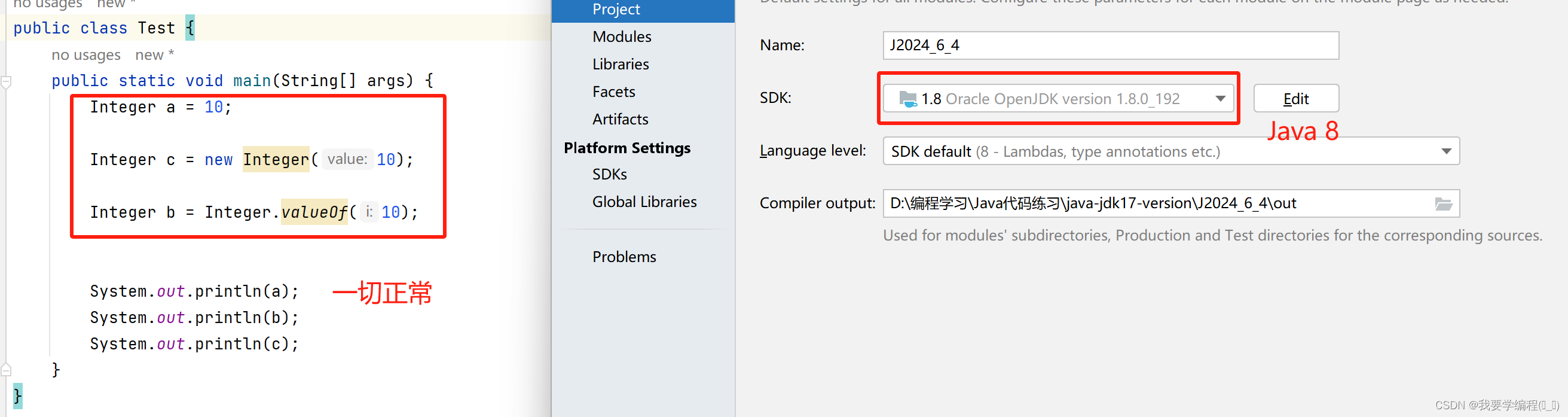
上面三种写法,都是装箱的操作,即把基本数据类型转换成其对应的包装类 类型。但要注意的是第二种方法,虽然代码可以正常执行,但我们现在不再使用这种方法了。从Java 9开始,这个方法就已经被摒弃了。下面是Java 8 和 Java 17的不同情况:
Java 8:
Java 17:
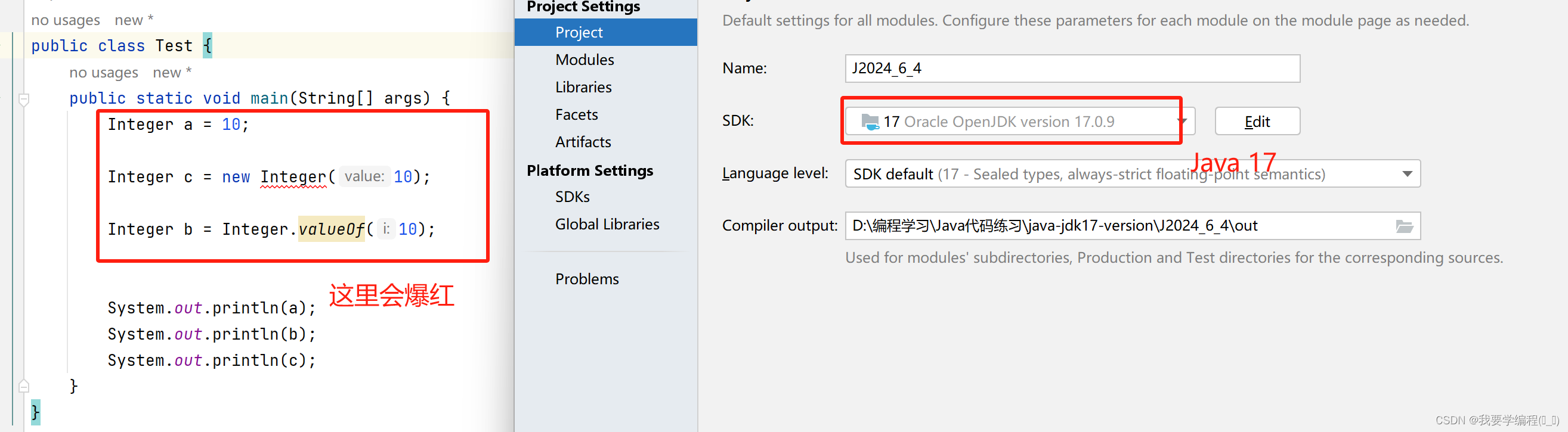
需要注意的是:这里爆红,但还是可以运行通过的。
拆箱也叫作:拆包。就是把包装类 类型转换成其对应的基本数据类型。
例如:
- public class Test {
- public static void main(String[] args) {
- Integer integer = 10;
-
- int a = integer;
-
- int b = integer.intValue();
-
- System.out.println(a);
- System.out.println(b);
- }
- }
注意:
当我们显式地去调用方法来进行装箱或者拆箱操作时,这种方式叫做:显式装箱(拆箱)。
当我们直接把基本数据类型转换为其对应的包装类 类型或者进行这种拆箱操作时,这就叫做:自动装箱(拆箱)。
- public class Test {
- public static void main(String[] args) {
- Integer a = 10; // 自动装箱
- Integer b = Integer.valueOf(10); // 显式装箱
-
- int c = a; // 自动拆箱
- int d = b.intValue(); // 显式拆箱
- }
- }
面试题
- public class Test {
- public static void main(String[] args) {
- Integer a = 100;
- Integer b = 100;
- System.out.println(a == b); // 结果是 true
-
- Integer c = 200;
- Integer d = 200;
- System.out.println(c == d); // 结果是 false
- }
- }
这里同样都是自动装箱,为什么输出的结果会不一样呢?
分析:a b c d 在这里都是一个引用类型,那么在用 == 比较时,比较的是它们各自在堆区的地址。这也就说明 a 和 b在堆区是同一块地址,但是c 和 d 在堆区不是同一块地址。

我们就可以去看这个装箱的源码,看看到底做了什么?

可以看到当装箱的 i 的值在 [low, high] 之间的时候,返回的是一个数组所对应的下标的值,而当 i 不在这个范围内时,返回的是一个新的对象。因此,我们可以得出结论了:100在这个范围内,200不在这个范围内。我们还是可以看一个这个源码对应的 low 和 high 的值的。

low 对应的值是 -128,high 对应的值是 127。

根据条件得出这个数组大致是这样的。因此 当 i = 100时,返回的是在数组中的同一份;而 i = 200时,返回的是 new 的一个新对象。
泛型
包装类的出现就是为泛型服务的。那么什么是泛型呢?顾名思义:就是一个广泛的类型。泛型的出现是为了解决掉:一个类或者方法只能解决对应类型的问题。
例如:对整型数据排序,就只能用整型数组类解决。
- class Myarray {
- public static void bubble_sort (int[] array) {
- // 趟数
- for (int i = 0; i < array.length; i++) {
- boolean flag = true;
- // 每一趟要比较的内容
- for (int j = 0; j < array.length-i-1; j++) {
- if (array[j] > array[j+1]) {
- int tmp = array[j];
- array[j] = array[j+1];
- array[j+1] = tmp;
- flag = false;
- }
- }
- if (flag) {
- break;
- }
- }
- }
- }
- public class Test {
- public static void main(String[] args) {
- int[] array = {10,9,8,7,6,5,4,3,2,1};
- System.out.println("排序前:"+ Arrays.toString(array));
- Myarray.bubble_sort(array);
- System.out.println("排序后:"+ Arrays.toString(array));
- }
- }


从排序的结果来看:这个排序的功能是正确的。但是也只局限于排序整型数据,不能排序其他类型的数据,如果要排序的话,还得重新写一个这样的方法。于是就出现了泛型。 所以,泛型的主要目的:就是指定当前的容器,要持有什么类型的对象。让编译器去做检查。
泛型的语法与使用
- class 泛型类名称<类型形参列表> {
- // 这里可以使用类型参数
- }
这里的参数列表可以不只有一种。就像下面这样:
- class 泛型类名称<T1,T2,....,Tn> {
-
- }
这里的T代表的是占位符,表示当前类是一个泛型类。
类型形参一般使用一个大写字母表示,常用的名称有:
E 表示 Elements K 表示 Key V 表示 Value
N 表示 Number T 表示 Type S, U, V 等等 - 第二、第三、第四个类型
至于这些占位符的区别以及各自之间的含义,我们待会再学习。我们可以用一个数组来接收多种不同的元素了。
- class MyArray<T> {
- // 语法规定不能创建泛型数组,但Object可以拥有接收所有类的功能
- public Object[] objects;
- public MyArray(){
- this.objects = new Object[10];
- }
- public T getValue(int pos) {
- // 取出来的是一个Object类,得强转成 T
- return (T)objects[pos];
- }
- public void setValue(int pos, T value) {
- // 这里不考虑pos的无效,注重这里的思想
- objects[pos] = value;
- }
- }
-
- public class Test {
- public static void main(String[] args) {
- MyArray<Integer> myarray = new MyArray<>();
- myarray.setValue(0, 10);
- myarray.setValue(1, 20);
-
-
- // 这里可写可不写
- MyArray<String> myArray = new MyArray<String>();
- myArray.setValue(0, "Hello");
- myArray.setValue(1, "World");
- }
- }
这里就实现了同一个类,但是可以接收不同的类型,实现了类型的参数化。这就是泛型的意义。
注意:
1. 泛型只能接受类,所有的基本数据类型必须使用包装类!
2. 编译器会根据我们在实例化一个对象的时候来判断这个T到底是什么类型。
3. 我们也可能会遇到有的代码在使用泛型类时,没有标明具体的类型,但是还是可以运行通过。这是因为泛型这个概念是在 java 5之后提出来的。之前的 java 版本并没有这种写法,所以为了兼容老版本,泛型类在实例化时,会有未标明具体类型的情况,这种叫做裸类型。但是我们最好不要写这种代码出来。
泛型如何编译的
泛型是只存在于编译时期的名词,因为在编译过后不存在T、E等泛型占位符了。泛型的占位符在编译之后就被替换成了Object。这种机制被称为“擦除机制” 。将占位符擦除成Object。
泛型的上界
如果我们想要限制泛型的传过来的种类也是可以的。
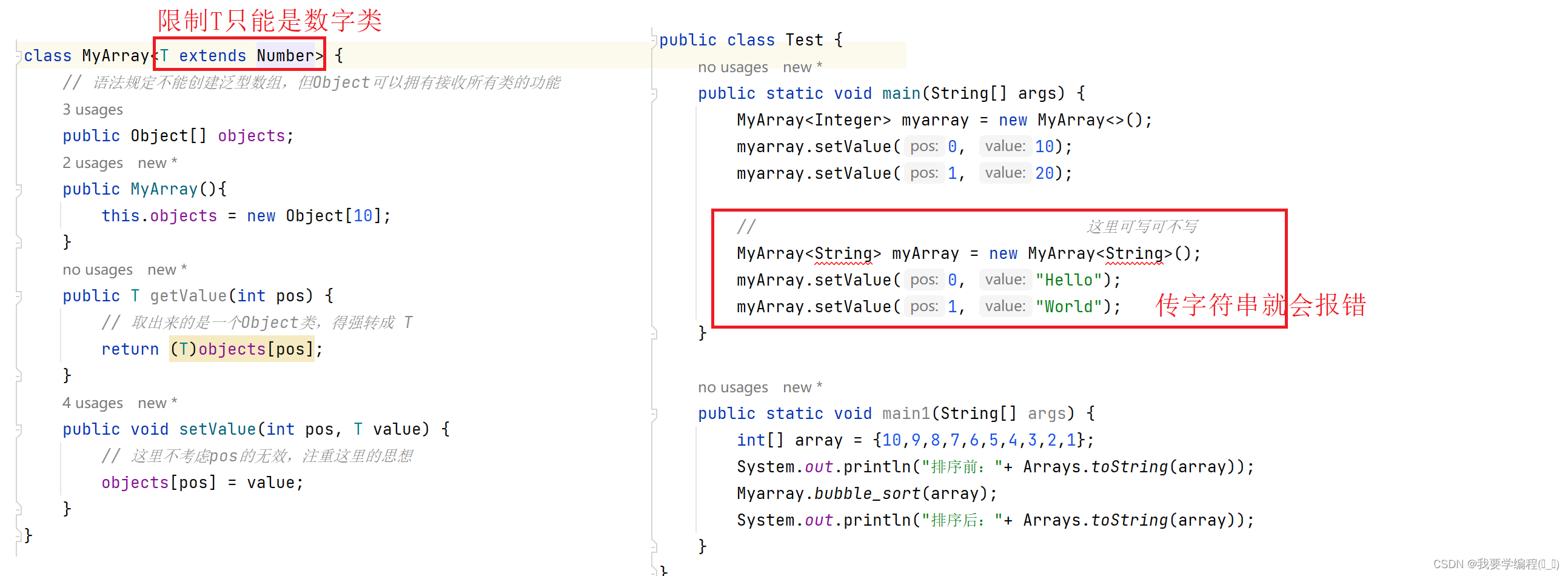
在定义泛型类时,有时需要对传入的类型变量做一定的约束(就像上面那样),可以通过类型边界来约束。
语法:
- class 泛型类名称<类型形参 extends 类型边界> {
- ...
- }
注意:其实所有的泛型类都有一个上界:Object。
泛型方法
语法:
- 方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) {
- ...
- }
例如:
- // 规定这个方法是叫把pos位置的值置为value
- public static <T> void swap (T[] array, int pos, T value) {
- array[pos] = value;
- }
注意:只有静态的泛型方法里面才能有泛型的出现,普通的静态方法不能有泛型的出现。
这句话不是说只有静态方法才能是泛型方法,普通方法也可以是泛型方法。只是说不是泛型的方法里面如果没有实例化泛型对象,就不能出现任何与泛型有关的东西。
因此,上面的排序就可以用泛型方法来解决。但是会有一个新的问题:Comparable 与 这个数组会出现不兼容的情况,因为这个数组是基本数据类型,没有实现接口这一说法。所以得把这个数组变成包装类,但是在传参的过程中,T会被擦除成Object类,因此即使我们传过去的参数强转成T[ ],也会发生类型转换异常。
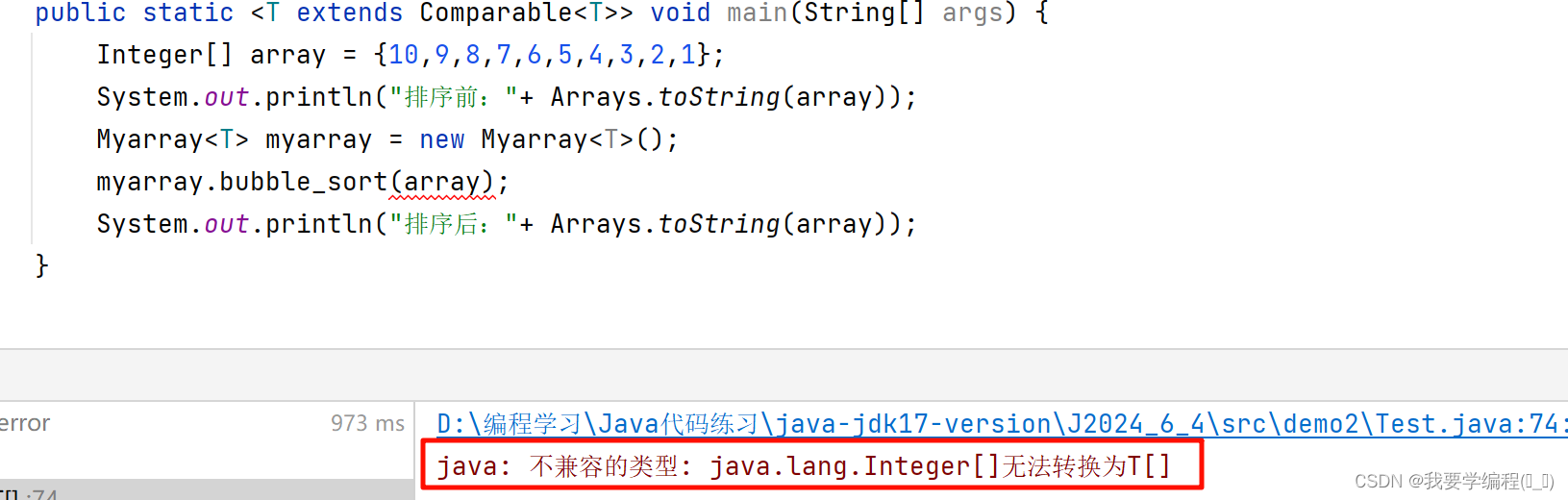
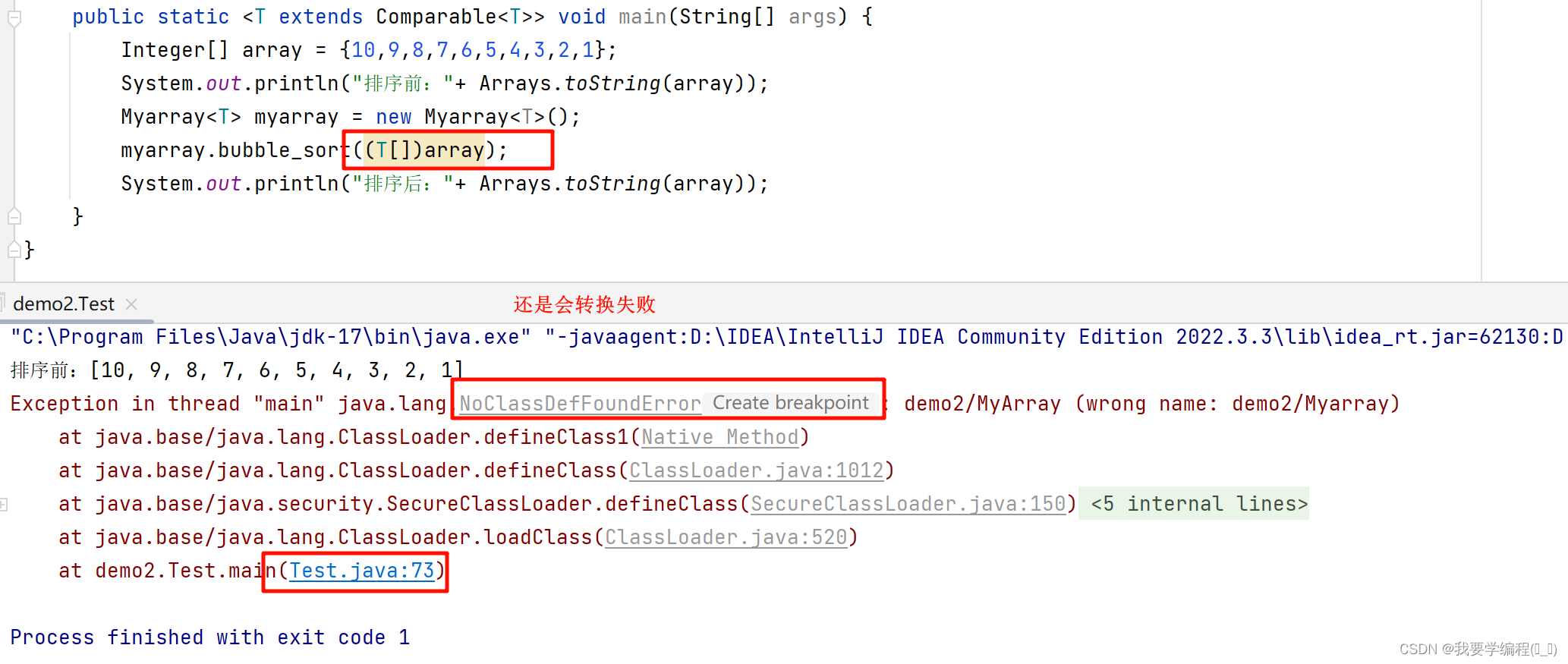
因此这个排序最终是失败了。所以我就没有把代码传上来。但是泛型还是有很大的好处的:可以让一份代码对不同的对象执行相同的操作。
类型推导
- class Myarray<T> {
- // ......
- }
-
-
- public class Test {
- public static void main(String[] args) {
- // 通过这个 Integer 来推导出 Myarray 中的泛型
- Myarray<Integer> myarray = new Myarray<>();
- }
- }
上面是泛型类的推导。下面是泛型方法的推导
- class Myarray {
- public <T> void func () {
- // ......
- }
- }
-
-
- public class Test {
- public static void main(String[] args) {
- Myarray myarray = new Myarray();
- // 通过这个 Integer 来推断这个 T(也可以不写,编译器会根据其具体操作来判断)
- myarray.<Integer>func();
- }
- }
泛型占位符
接下来就学习泛型占位符的知识:
在Java泛型中,像 <T> 和 <E> 这样的占位符是用来表示类型参数的。它们本身没有本质上的区别,都代表一种未知的类型,将在编译时期由具体的实际类型替换。选择使用T、E或其他的,更多是基于习惯和上下文的清晰性。以下是几个常用的占位符及其常见用途:
T - 通常代表 Type,是最常见的泛型占位符,用于表示任何类型。在没有特定上下文暗示的情况下,泛型类或方法常使用
T。E - 通常代表 Element,特别在集合框架中使用较多,暗示它代表集合中的元素类型,如 List<E> 或 set<E>。
K - 代表 Key,通常用在表示键的类型,比如在 Map <K,V> 中。
V - 代表 Value,通常与 K 一起使用,表示映射中的值类型。
N - 有时代表 Number,表示数值类型,尽管这不是Java标准库中的正式约定,但在特定上下文中可能会看到它的使用。
使用这些占位符主要是为了提高代码的可读性和自文档化能力。开发者可以根据上下文选择最合适的占位符来表达意图,但最终这些占位符都会被编译器替换为具体的类型信息,不会影响到生成的字节码或运行时行为。
此外,泛型中还有一个特殊的占位符 ?(问号),它作为通配符使用,表示未知的类型,可以有三种形式:无界通配符(?)、上界通配符(
? extends SomeType)和下界通配符(? super SomeType),用来实现更灵活的泛型参数约束。(了解即可)
这里基本就是java泛型语法的全部内容啦!通过对泛型的学习,我们就可以让代码变得更加高大上一些。
好啦!本期 数据结构之初始泛型 的学习之旅就到此结束了!相信通过这篇文章的学习,你对Java中泛型的了解将会更进一步!我们下一期再一起学习吧!
- 线性表的顺序存储 ...
赞
踩

