
- 12022全球边缘计算大会·上海站参会指南
- 2计算机毕业设计之微信小程序的快递取件及上门服务系统的论文_研究生取件小程序论文
- 3自动驾驶研究生就业如何,自动驾驶的研究方向_研究生选自动驾驶好还是芯片设计好
- 4十四届蓝桥杯Python经典例题_第十四届蓝桥杯python 国赛
- 5最好用的论文数据搜索网站,搜索容易让写论文变轻松!_论文数据查询网站推荐
- 6解决:PermissionError: [Errno 13] Permission denied: ‘xxx’
- 7PyQt5教程(九)——实现QQ登录界面(三、加载gif动画效果)_qq登录动态图获取
- 8Zookeeper集群搭建_zeekeeper集群
- 9详解Spring Boot的RedisAutoConfiguration配置_redissonautoconfiguration @conditionalonmissingcla
- 10有哪些值得推荐的LoRa模块?_lora真实模型推荐
大数据—MapReduce概念_mapreduce是一种通用的数据处理模型,适用于各种领域,包括大规模数据分析,搜索引擎
赞
踩
MapReduce是什么?
- MapReduce是一种分布式计算模型,主要用于处理大规模数据集。它由Google公司提出,并被广泛应用于大数据处理领域。
- MapReduce将计算任务分为两个阶段:Map阶段和Reduce阶段。在Map阶段中,数据被切分成若干个小的子数据集,每个子数据集由一组键-值对组成。用户需要自定义一个Map函数,将输入的键-值对进行处理,并生成一个新的键-值对序列作为输出。在Reduce阶段中,Map阶段的输出被分组,按照键进行排序,并传递给用户定义的Reduce函数,生成最终的结果。
MapReduce思想
- mapReduce思想的核心是”先分再合,分而治之“。
- 就是吧复杂的问题简单化,将一个问题拆分成多个问题解决。
- Map表示第一阶段,负责“拆分问题”,即把复杂的问题拆分成多个问题并行处理,可以拆分的前提是这些问题可以并行运行,且几乎没有依赖关系。
- Reduce表示第二阶段,负责“合并”,即对Map结果进行全局汇总。
分布式计算概念
- 分布式计算是一种计算方法,和集中式计算是相对的。
- 分布式计算将应用分解成许多小的部分,分配给许多计算机进行处理。节约时间,提升计算效率。
集中式计算
- 集中式计算是指数据处理任务在一个中央服务器或计算机上进行的计算模型。在集中式计算中,所有的计算资源和数据都集中在一个地方,由中央服务器或计算机负责处理和管理
- 适用于小规模任务:集中式计算适用于处理小规模的数据任务,对于大规模的数据处理任务可能存在性能瓶颈和扩展性差的问题。
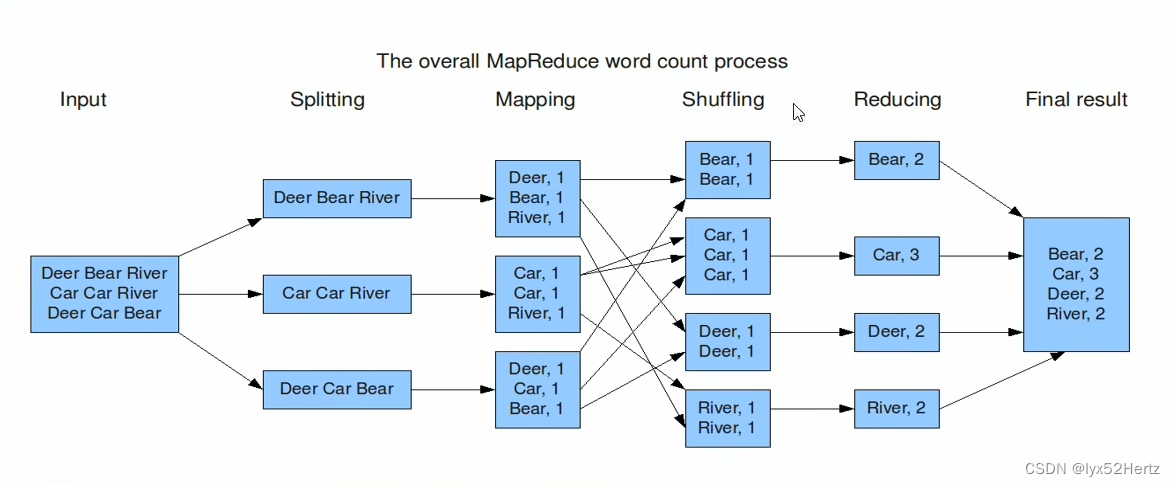
WordCount编程实现思路
单词统计问题,统计每个单词的个数。

- map阶段的核心:把输入的数据经过切割,全部标记成一,因此就是 <单词,1>
- shuffle阶段核心:经过MR程序内部自带默认的排序分组等功能,吧key相同的单词作为一组数据构成新的kv对。
- reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是单词的总次数。
- MapReduce会自动进行字典性排序。
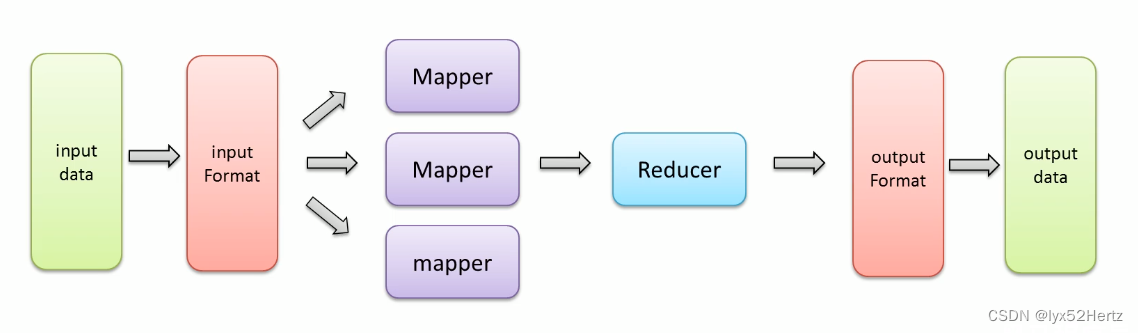
MapReduce编程规范
- 用户编写的程序代码分成三个部分:Mapper,Reducer,Driver(客户端提交作业驱动程序)。
- 用户自定义的Mapper和Reducer都要继承各自的父类。
- 注意:整个MapReduce程序中,数据都是以kv键值对的形式流转的。
Mapper中的业务逻辑写在map()方法中。
Reducer的业务逻辑写在reducer()方法中。
整个程序需要一个Driver来进行提交,提交的是一个描述了各种必要信息的job对象。
编写MapReduce程序主要步骤
编写MapReduce程序主要涉及以下几个步骤:
-
定义Mapper函数:Mapper函数是对输入数据进行处理的函数。它接收输入的数据记录,将其转化为(Key,Value)对,并输出到Reducer函数进行处理。你可以根据需求自定义Mapper函数。
-
定义Reducer函数:Reducer函数接收来自Mapper函数输出的(Key,Value)对,并对具有相同Key的Value进行合并和聚合。你可以根据需求自定义Reducer函数。
-
配置MapReduce作业:通过配置作业来定义输入和输出路径,指定Mapper和Reducer函数等。你可以使用Hadoop提供的API或编辑配置文件来配置MapReduce作业。注意:输出路径不能存在,不然会报错。
-
提交作业并运行:将编写好的MapReduce程序打包成JAR文件,并通过Hadoop提供的命令或API提交作业并运行。
MapReduce内部执行流程
- 虽然MapReduce从外表看起来就两个阶段Map阶段和Reduce阶段,但是内部包含了很多默认组件和默认的行为。包括:
- 组件:读取数据组件InputFormat,输出数据组件OutputFormat。
- 行为:排序(key的字典排序),分组(reduce阶段key相同的分为一组,一组调用一次reduce处理)
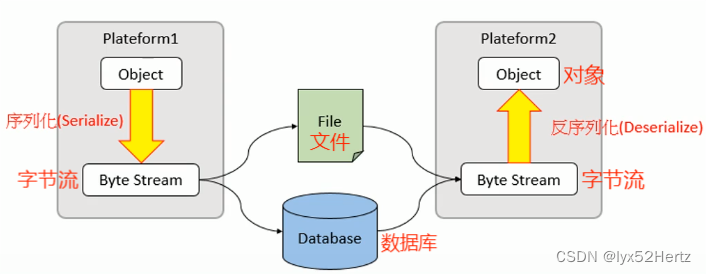
序列化机制
概念
- 序列化(Serialization):是将结构化对象转化成字节流以便于进行网络传输或写入持久存储的过程
- 反序列化(Deserialization):是将字节流转化为一系列结构化对象的过程,重新创建该对象。
Java序列化机制
- Java是面对对象的编程。
- 开发中,经常有以下场景,跨进程,跨网络传递对象,将对象数据持久化存储。
- 需要有一种可以在两端传输数据的协议。
- java序列化就是问为了解决这个问题而产生。
- Java对象序列化的机制,把对象表示成一个二进制的字节数组,里面包含了对象的数据,对象的类型信息,对象内部的数据的类型信息等等。通过保存或转移这些二进制数组达到持久化,传递的目的。
-
Java序列化机制可以通过实现Serializable接口来实现对象的序列化和反序列化,就是将二进制数组转化为对象的过程。
Hadoop的序列化机制
- Hadoopd序列化没有采用java的序列化机制,而是实现了自己的序列化机制Writable。
- 原因在于java的序列化机制比较臃肿,是一种不断创建对象的机制,并且会额外附带很多信息(校验,继承关系,系统等)。
- 但在Hadoop的序列化机制中,用户可以复用对象,这样就减少了java对象的分配和回收,提高了应用效率 。
- Hadoop通过Writable接口实现的序列化机制,接口提供两个方法write和readFields。
- write:序列化方法,用于把对象指定的字段写出去。
- readFields:反序列化方法,用于从字节流中读取字段重构对象。
- Hadoop没有提供对象比较功能,所以和java中的Comparable接口合并,提供一个接口WritableComparable。
Hadoop封装的数据类型
- 这些数据类型都实现了WritableComparable接口,以便这些类型定义的数据可以被序列化进行网络传输和文件储存,以及大小比较。
| Hadoop数据类型 | Java数据类型 |
| BooleanWritable | boolean |
| ByteWritable | byte |
| IntWritable | int |
| FloatWritable | float |
| LongWritable | long |
| DoubleWritable | double |
| Text | String |
| MapWritable | Map |
| ArrayWritable | array |
| NullWritable | null |
MapReduce Partition分区
mapreduce输出结果文件个数探究
- 默认情况下
不管map阶段有多少个并发执行task,到reduce阶段,所有的结果都有一个task处理。并且最终结果输出到一个文件中,及reducetask参数为1。
- 改变输出结果个数
输出结果文件的个数和reducetask个数是一种对等关系。也就说有几个reducetask,就输出几个文件。
ke
设置job.setNumReduceTask(3) ##括号内填入输出结果的个数
- 引出数据分区
引出数据分区当MapReduce中有多个reducetask执行的时候,此时maptask的输出就会面临一个问题:究竟将自己的输出数据交给哪一个reducetask来处理?这就是所谓的数据分区(partition)问题。
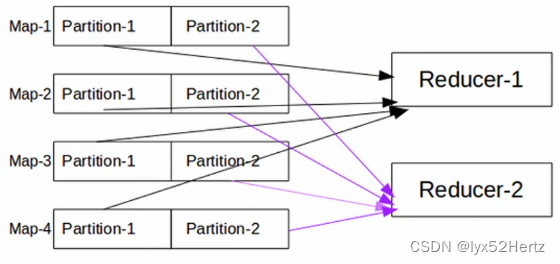
Partition概念
改变reducetask个数时,mapreduce就会涉及到分区的问题,即:maptask输出的结果如何分配给各个reducetask来处理。
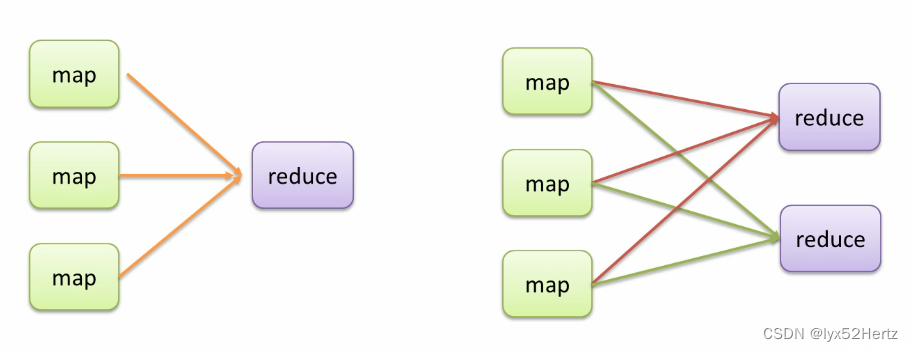
- MapReduce默认分区规则是HashPartitioner。
- 分区的结果和map输出的key有关。
Partition注意事项
- reducetask个数的改变导致了数据分区的产生,而不是有数据分区导致了reducetask个数改变
- 数据分区的核心是分区规则。即如何分配数据给各个reducetask。
- 默认的规则可以保证只要map阶段输出的key一样,数据就一定可以分到同一个reducetask,但不能保证数据平均分区。
- reducetask个数的改变还会导致输出结果文件不在是一个整体,而是输出到多个文件中。
Combiner规约
数据规约的含义
- 数据规约是尽可能保持数据原貌前提下,最大限度地精简数据量。
MapReduce弊端
- MapRduce是一种具有两个执行阶段的分布式计算程序,Map阶段和Reduce阶段之间会涉及到跨网络数据传递。
- 每一个MapReduce都可能会产生大量的本地输出,这就导致网络传输数据量变大,网络IO性能低。
Combiner规约概念
- Combiner中文叫数组规约,是MapReduce的一种优化手段。
- Combiner的作用就是对map端的输出先做一次局部合并,以减少map和reduce节点之间的数据传输量。
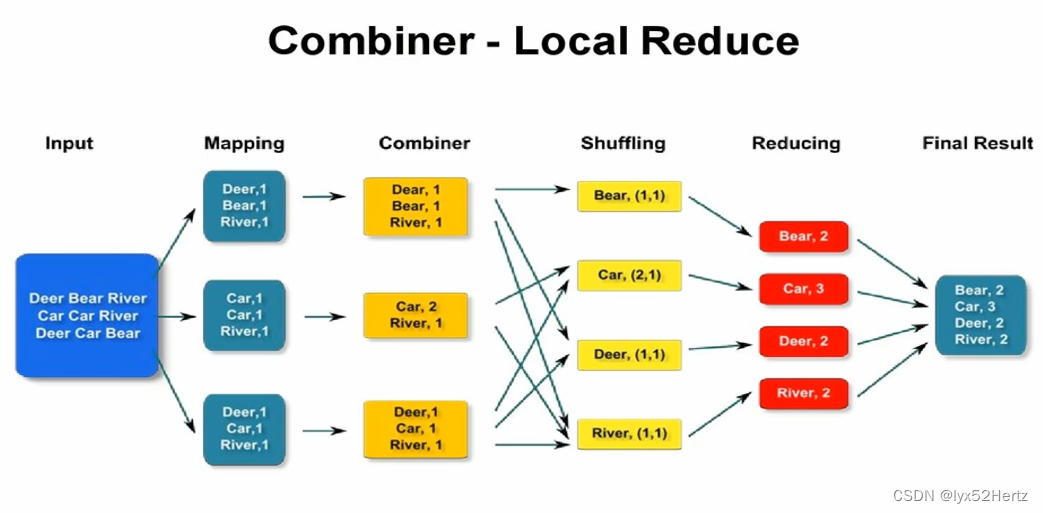
Combiner组件使用
- Combiner是MapReduce程序中除了Mapper和Reducer之外的一种组件,默认情况下不启用。
- Combiner的本质就是Reducer,Combiner和reduce的区别在于运行的位置:
- Combiner是在每一个maptask所在的节点本地本地运行是局部聚合;
- reducer是对所有maptask的输出结果计算,是全局聚和;
- 具体实现步骤:
- 定义一个CustCombiner类,继承Reduce,重写reduce方法
- job.setConbinerClass(CustomCombiner.class)
Combiner使用注意事项
- Combiner 能够应用的前提是不能影响最终的业务逻辑,而且Combiner的输出kv应该跟reducer的输入kv类型要对应起来。
- Combiner 要慎用,用的好提升程序性能,用不好,改变程序结果且不发现。

