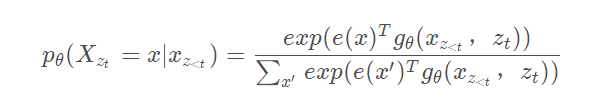【总结向】预训练模型小结_预训练任务设计 如何判断序列的信息量
赞
踩
1 语言模型
1.1 AR——自回归语言模型
代表:GPT、ELMo
对于一个给定的序列 x=[x1,⋯,xT],自回归语言模型致力于对该序列的概率分布进行估计。具体的,利用乘法公式对原始序列的似然函数进行分解,可以通过极大似然来进行预训练。
1.2 AE——去噪自编码语言模型(denoising auto-encoding)
代表:Bert
缺点:
-
独立性假设(independence assumption)。没有使用乘法公式。BERT 预测的所有
MASKtoken 在未 mask 序列的条件下是独立的,而xlnet认为他们是有关系的。 -
pretrain-finetune 不匹配(discrepancy)
1.3 PLM——乱序语言模型
乱序语言模型使用一个序列的所有可能排序方式来构建一个 AR 语言模型。
理论上,如果模型的参数在所有的顺序中共享,那么模型就能学到从所有位置收集上下文信息。乱序语言模型表示:
乱序语言模型使用的是原始位置的位置编码,而不是调整了原来句子的顺序,这得益于 Transformer 的 mask 机制来实现。
优点:
-
捕获双向信息(AE优点)
-
自然的避免了独立性假设、 pretrain-finetune 不匹配的问题。(AR优点,AE缺点)
-
模型的参数在所有的顺序中共享
2 XLNet
XLNet就是Bert、GPT 2.0和Transformer XL的综合体变身。
-
它通过PLM预训练目标,吸收了Bert的双向语言模型;
-
GPT2.0的核心其实是更多更高质量的预训练数据,这个明显也被XLNet吸收进来了;
-
Transformer XL来解决Transformer对于长文档NLP应用不够友好的问题。
XLNET好处
- 结合AE优点,PLM获取双向语义信息(对token级别的任务如RC\QA很重要)
- 结合AR优点,输入不用masking,解决了pretrain-finetune不匹配
- 可以对序列的概率分布进行建模,避免了独立性假设
- 探索到更长距离(利用了transformer-xl)
XLNet 创新点
-
PLM(与双流语言模型相辅相成)
-
Two-Stream self-attention(与PLM相辅相成)
content流、query流(相当于bert的
mask标记)核心是target-aware Representations,引入了target position zt
-
引入transformer-xl模型(以下简称txl)
-
segment recurrence mechanism
-
relative positional encoding
-
应用
-
在RC上,大幅度提升,尤其是长文档RC提升很大!
-
生成任务上,AR天然符合下游序列任务,如文本摘要、机器翻译、信息检索
预训练
-
输入和BERT一样 two-segment data format:
[CLS, A, SEP, B, SEP]把2个segment看作一个序列运行PLM、没用NSP做prediction
-
PLM语言模型;Two-Stream self-attention;局部预测,超参数
K -
引入transformer-xl
relative positional encoding(如一段序列里位置zt的位置编码)
segment recurrence mechanism
fine-tuning
-
和BERT的输入一样 two-segment data format:
[CLS, A, SEP, B, SEP] -
去掉query流
-
relative segment encodings
多segments,参考 Transformer-xl 的 relative encodings,对于 segments 进行相对位置编码。
-
span-based prediction
实验的一些方法
- bidirectional data
- span-based prediction
- NSP
两种相对位置编码
-
用txl的相对编码方式对输入序列进行relative positional encoding
-
参考txl,对多个segments进行相对编码,也就是relative segment encodings
这让muitiple input segments成为可能
3 Transformer-xl
创新点 (以上两者相辅相成)
- segment-level recurrence mechanism
- relative positional encoding
优点
- 捕获longer-term dependency
- 解决上下文碎片问题(让片段之间有依赖性,解决 context fragmentation)
- 学习长度超过fixed length(bert是512)
3.1 segment-level recurrence mechanism
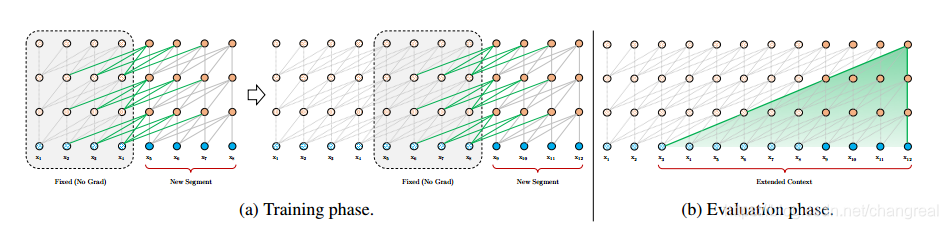
前面的segment的hidden state被fixed 和 cached,当做memory给下一个segment,从而被使用为extended context.
优点:
- 评估的时候也会更快,因为可以直接拿前一个segments的表示来用,所以每个txl块不用从头计算
- 理论上可以缓存很多
3.2 relative positional encoding
优点
-
简单有效,不会造成时间混乱,每段重要性不同
-
既能捕获长距离依赖关系,也能充分利用短距离依赖关系
TXL 成为第一个同时在字符级和词汇级任务上超越循环神经网络的自注意力模型。
核心

4 Bert
阶段1:语言模型
- 预训练
- 特征抽取器是transformer
- 输入是3个embedding:token\segment\positional embeddings,[CLS]很重要
- 双向语言模型(DAE)
- 任务,2种无监督的学习方式
- MaskedLM(有CBOW思想,colze-style task,待预测的单词抠掉)
- NSP(这种句子关系、句子匹配型的任务,很适合RC\QA)
阶段2:fine-tune
bert适用原则
- 语言中包含答案,如QA\RC
- 句子/段落匹配任务
- 适用深层语义特征的任务
- 句子/段落级别的NLP任务(文档级不好,也就是说更适合长度不太长的任务)
5 GPT
-
阶段1:语言模型预训练
- 特征抽取器:transformer
- 单向
-
阶段2:fine-tune
6 ELMo
-
阶段1:语言模型
-
学到:单词、位置、语义的embedding,分别对应词义、句法、语义
-
单向
-
-
阶段2:Feature- base Pre-trained
7 其他
7.1 迁移的2种方法
-
feature-based
把预训练模型的参数作为具体任务特征补充,两阶段的模型结构可以不同
对于序列标注类任务,多层特征融合更适合应用场景,融合会更细致些
-
fine-tuning
具体任务fine-tune,两阶段的模型结构要相近
QA这种句子匹配的问题,fine-tune效果好于feature-base;
fine-tune的方式有些门道,比如数据少的话可以找相近任务数据fine-tune,stage-wise方式(数据增强)
7.2 零碎
-
cloze task可以提高文字生成的鲁棒性
-
区分句子的方式
分隔符、句子embedding加入句子的编号,
-
QA vs RC
QA依赖上下文更小,倾向于短文本;RC依赖上下文范围更大;
7.3关于MASK
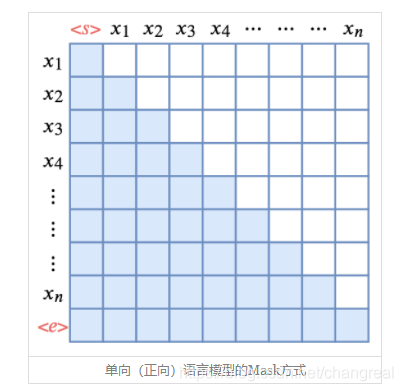
如图是单向语言模型的Mask方式,可见是一个下三角。Attention矩阵的每一行事实上代表着输出,而每一列代表着输入,而Attention矩阵就表示输出和输入的关联。
XLNet是乱序语言模型,它跟语言模型一样,都是做条件概率分解,但是乱序语言模型的分解顺序是随机的:
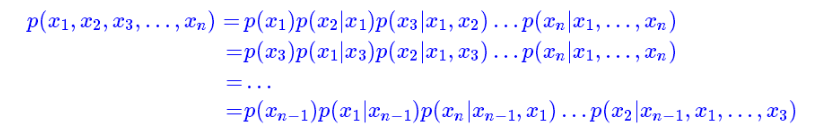
任意一种“出场顺序”都有可能。原则上来说,每一种顺序都对应着一个模型,所以原则上就有n!个语言模型。基于Transformer的模型,则可以将这所有顺序都做到一个模型中去!
以“北京欢迎你”的生成为例,假设随机的一种生成顺序为**“< s > → 迎 → 京 → 你 → 欢 → 北 → < e >”**,那么我们只需要用下图中第二个子图的方式去Mask掉Attention矩阵,就可以达到目的了:
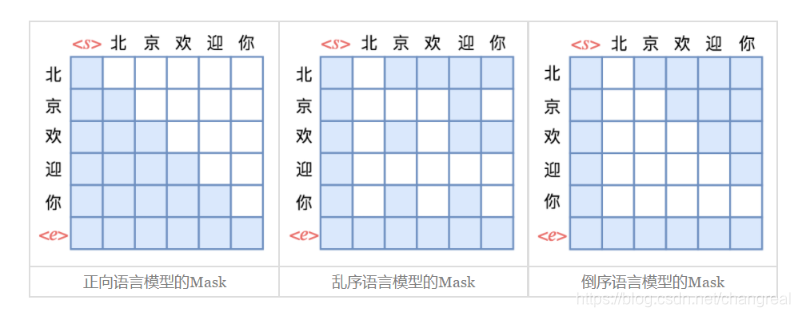
直观来看,这就像是把单向语言模型的下三角形式的Mask“打乱”了。
hθ(xZ<t)并不依赖于要预测的内容的位置信息,基于上面提到的乱序语言模型的分解顺序是随机的,因此无论预测目标的位置在哪里,因式分解后得到的所有情况都是一样的,并且transformer的权重对于不同的情况是一样的,因此无论目标位置怎么变都能得到相同的分布结果,因此需要修改预测next-token distribution的公式,也就是引入target position zt,重新参数化: