
- 1基于vue-simple-uploader封装文件分片上传、秒传及断点续传的全局上传插件功能_vue-uploader(simple-uploader)源码
- 2vulfocus——solr远程命令执行(CVE-2019-17558)_vulfocus solr 上传代码
- 3判断有向图图是否有环_判断有向图是否有环,若有环,则将环剔除java
- 4解决prettier和eslint冲突详细配置_prettier-eslint
- 5CodeForces 597A(公式+技巧)_codeforce 597a
- 6Apache_Solr环境变量信息泄漏漏洞(CVE-2023-50290)
- 7MyBatis 源码解析——SQL解析_mybatis sql解析
- 8排序算法---插入排序
- 9Leetcode 347:前K个高频元素(最详细解决方案!!!)_前k个高频元素 python
- 10python3 web服务器_python3 简单web服务器
你好,我是百川大模型|国内可开源免费商用Baichuan2揭秘
赞
踩
“ 百川智能发布了新一代语言模型Baichuan2。相比之前的第一代,新版本在各个学科领域的表现都有很大提升,特别是在数学、科学、安全方面的能力得到明显增强。Baichuan2以开源方式对外发布,为大模型领域提供了新的选择和可能。”

01
—
昨天下午,百川智能发布了一个令人振奋的消息:正式开源了经过微调的Baichuan2-7B、Baichuan2-13B、Baichuan2-13B-Chat以及它们的4bit量化版本,并且可以完全免费商用,只需进行简单登记即可。
国内开源可商用的大模型又多了一个选择。开源地址:
https://github.com/baichuan-inc/Baichuan2
Baichuan2是对“Baichuan”系列开源模型的一次全面升级。据官方介绍,相对于第一代,Baichuan2在文科和理科方面的能力都得到了显著的提升。
Baichuan2-13B-Base在数学能力上提升了49%,代码能力提高了46%,安全能力增强了37%,逻辑推理方面进步了25%,同时在语义理解方面也提高了15%。
目前Baichuan2在大模型的权威基准数据测试集的结果如下(Baichuan2-13B)
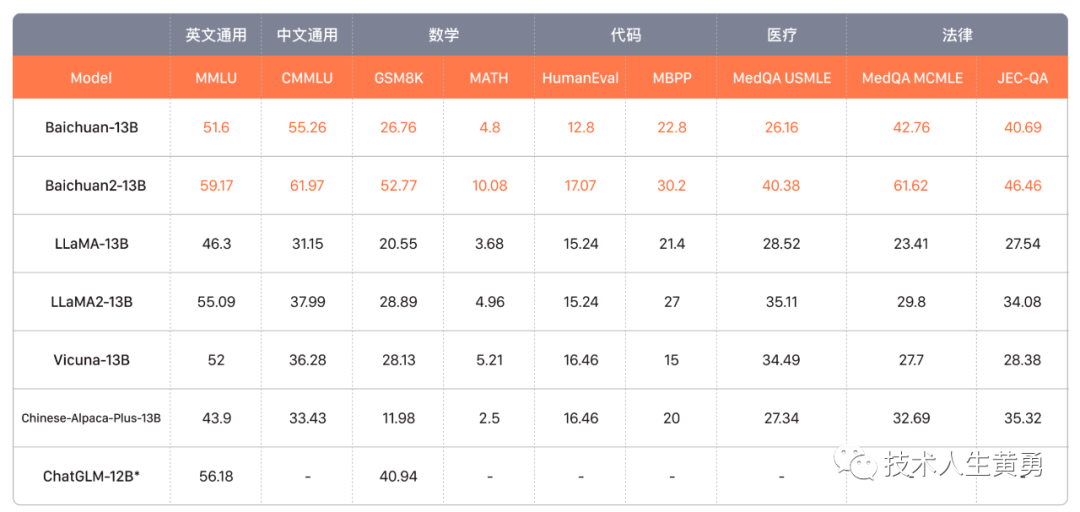
基础评测数据集说明:
C-Eval 是一个全面的中文基础模型评测数据集,涵盖了 52 个学科和四个难度的级别。
MMLU 是包含 57 个任务的英文评测数据集,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,是目前主流的 LLM 评测数据集。
CMMLU 是一个包含 67 个主题的综合性性中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。
Gaokao 是一个以中国高考题作为评测大语言模型能力的数据集,用以评估模型的语言能力和逻辑推理能力。百川保留了其中的单项选择题,并进行了随机划分。
AGIEval 旨在评估模型的认知和解决问题相关的任务中的一般能力。 我们只保留了其中的四选一单项选择题,并进行了随机划分。
BBH 是一个挑战性任务 Big-Bench 的子集。Big-Bench 目前包括 204 项任务。任务主题涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等方面。BBH 是从 204 项 Big-Bench 评测基准任务中大模型表现不好的任务单独拿出来形成的评测基准。
测试集的表现还可以,不知道非测试集的实际应用过程的表现如何。
用这篇文章《ChatALL:发现最佳答案的神奇AI机器人!》里测试过大模型的的一道题体验一下。
“一个猎人向南走了一英里,向东走了一英里,向北走了一英里,此时恰好回到起点。他看到一只熊,于是开枪打了它。这只熊是什么颜色的?”

指出错误后,还是认为正方形。

“树上10只鸟,开枪打死一只,树上还剩几只?”

这个推理回答完全正确,还考虑的声音吓飞的因素。
02
—
对齐
官方的技术报告手册(https://baichuan-paper.oss-cn-beijing.aliyuncs.com/Baichuan2-technical-report.pdf)提到,除了训练上的优化和改进,baichuan2 还引入了对齐过程,包括两个主要组成部分:监督微调(SFT)和人类反馈强化学习(RLH F)。
在监督微调阶段,使用人工标注器来注释从各种数据源收集的提示。每个提示都被标记为有帮助或无害,拒绝任何不符合质量标准的批次。以此为标准收集了超过 100k 的监督微调样本,并在其上训练了百川的基本模型。
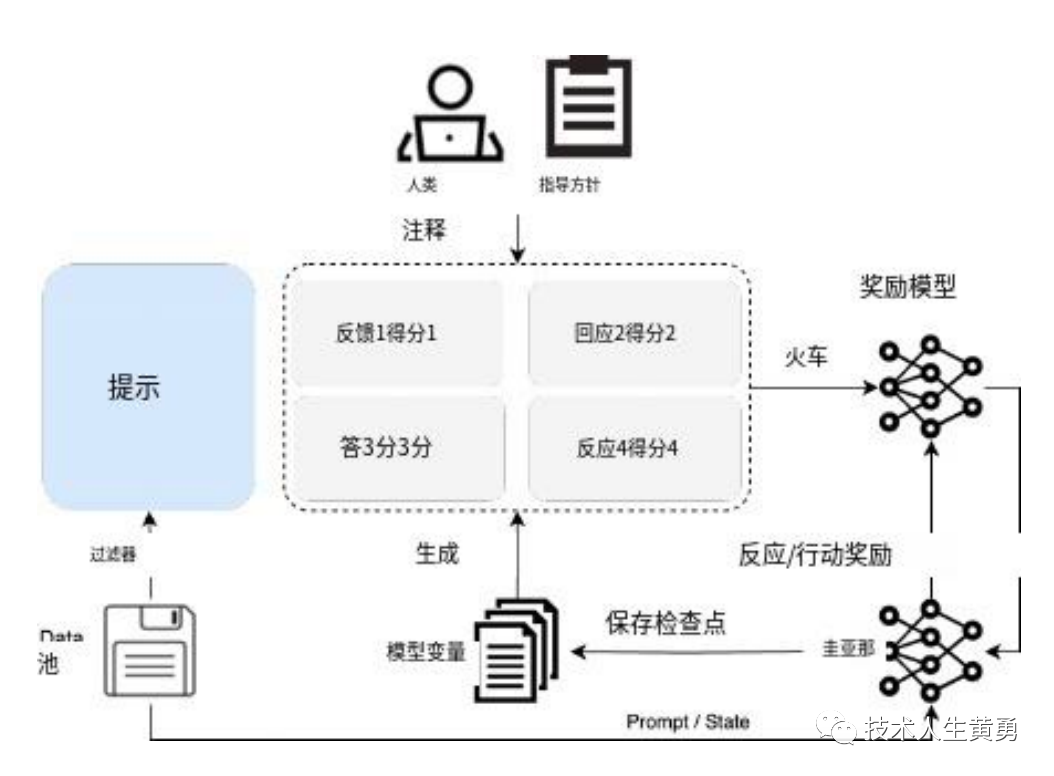
在这篇文章《人工智能安全吗?OpenAI正在让大模型和人类“对齐”-确保ChatGPT比人类聪明的同时还遵循人类意图》提到,“对齐”是现在大模型训练中重要的一环,它可以让大模型更智能,同时又确保有足够的安全性。
在对齐的阶段,百川构建了由 6 种攻击类型和 100+颗粒安全价值类别组成的红队流程,由 10 人组成的具有传统互联网安全经验的专家标注团队初始化安全对齐提示。从预训练数据集中检索相关片段来创建响应,产生大约 1K 的注释数据用于初始化。
专家标注团队指导一个 50 人的外包标注团队与初始化的对齐模型进行红蓝对抗,产生 200K的攻击提示。
通过采用专门的多值监督抽样方法,最大限度地利用了攻击数据,以生成不同安全级别的响应。
有兴趣的朋友可以看百川的官方技术报告手册,里面有比较多的技术实现细节。
03
—
在实际目前比较热的几个应用领域:法律、医疗、数学、代码、多语言翻译,百川也介绍了如何做的基准测试。
法律领域:使用了 JEC-QA 数据集。JEC-QA 数据集来源于中国国家司法考试。
医疗领域:使用通用领域数据集(C-Eval、MMLU、CMMLU)中的医学相关学科、MedQA 和 MedMCQA。
MedQA 数据集来源于美国、中国的医学考试。测试了 MedQA数据集 中的 USMLE 和 MCMLE 两个子集,并采用了五个候选的版本。
MedMCQA 数据集来源于印度医学院的入学考试。只测试了其中的单选题。
数学领域:使用 OpenCompass 评估框架,对 GSM8K 和 MATH 数据集进行了 4-shot 测试。
GSM8K 是由 OpenAI 发布的一个由 8.5K 高质量的语言多样化的小学数学应用题组成的数据集,要求根据给定的场景和两个可能的解决方案,选择最合理的方案。
MATH 数据集包含 12,500 个数学问题(其中 7500 个属于训练集,5000 个属于测试集),这些问题收集自 AMC 10、AMC 12、AIME 等数学竞赛。
代码领域:采用了 HumanEval 和 MBPP 数据集。使用 OpenCompass,对 HumanEval 进行了 0-shot 测试,MBPP 数据集进行了 3-shot 测试。
HumanEval 中的编程任务包括模型语言理解、推理、算法和简单数学,以评估模型功能正确性,并衡量模型的问题解决能力。
MBPP 包括 974 个 Python 短函数、程序的文字描述以及用于检查功能正确性的测试用例的数据集。
多语言翻译:采用了 Flores-101 数据集来评估模型的多语言能力。Flores-101 涵盖了世界各地的 101 种语言。它的数据来源于新闻、旅游指南和书籍等多个不同领域。
选择了联合国官方语言(阿拉伯文、中文、英文、法文、俄文和西班牙文)以及德文和日文作为测试语种。使用 OpenCompass 对 Flores-101 中的中-英、中-法、中-西班牙、中-阿拉伯、中-俄、中-日、中-德等七个子任务分别进行了 8-shot 测试。
可以看出,百川大模型的国内应用场景针对性还是比较强。
现在后续的各家大模型厂家纷纷选择开源可商用,前有清华团队的ChatGLM,国外有Meta的Llama,后有baichuan。
这么做的好处:
扩大在大模型赛道的影响力。后发的大模型并没有影响力的优势,开源商用后,可以让产品广为人知。
建立品牌信任度。大模型是一个新生事务,用户对其功能、安全性、可用程度等没有过多的认知。开源可以让用户了解其创建、训练、微调、对齐、评测所做的一系列工作内容,从而达到对其有个全面了解的目的。
快速收集客户反馈,加速模型进化迭代。开源后可以有更多的用户加入进来参与对模型的使用,获得更多、更全面的用户使用反馈。并用于后续的版本进化迭代,使其应用更有针对性、普适性。
参考资料
https://www.baichuan-ai.com/
https://github.com/baichuan-inc/Baichuan2
https://baichuan-paper.oss-cn-beijing.aliyuncs.com/Baichuan2-technical-report.pdf
阅读推荐
什么是AI的“智能涌现”,以及为什么理解它对创业者、从业者、普通人都价值巨大
提示攻击再次攻击大模型,被催眠后的ChatGPT可能会泄露重要信息-大模型的隐藏风险
全球最大开源翻译模型!Meta出品,支持100种语音、语言!
人工智能安全吗?OpenAI正在让大模型和人类“对齐”-确保ChatGPT比人类聪明的同时还遵循人类意图
如何做大模型的微调实验,记录一次基于ChatGLM-6B 大模型微调实验过程。
REACT:在语言模型中协同推理与行动,使其能够解决各种语言推理和决策任务。
5分钟玩转PDF聊天机器人!超简单的Langchain+ChatGPT实现攻略
为什么对ChatGPT、ChatGLM这样的大语言模型说“你是某某领域专家”,它的回答会有效得多?(二)
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。

