
- 1虚拟服务器集群新建linux虚拟机模板操作步骤_linux 虚拟机模板制作
- 2如何计算均值、标准差和标准误差_均值和标准差
- 3H5中iframe中嵌套的页面无法使用摄像头和麦克风_iframe跨域无法调用摄像头
- 4行人重识别综述(Person Re-identification: Past, Present and Future)
- 5termux使用教程python-Termux 入门教程:架设手机 Server 下载文件
- 6探索Gin框架:Golang使用Gin完成文件上传_golang gin multipartform
- 7linux本地安装nginx教程
- 8Linux用户密码管理_linux 密码管理
- 9打造类ChatGPT服务,本地部署大语言模型(LLM),如何远程访问?_fastchat 允许外部网络访问
- 1047.90.18.87 user.php,恶意软件分析 & URL链接扫描 免费在线病毒分析平台 | 魔盾安全分析...
T3D基于DenseNet可变时序的3D视频行为识别网络_行为识别可视化t3d
赞
踩
Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
最近读了一篇关于行为识别方向的文章《Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification》,这篇文章可以说是经典。本文最大的贡献就是提出了一种模型迁移的方法,同时引入一种新的时域层temporal layer给可变时域卷积核深度建模,此层叫做temporal transition layer(TTL) ,作者将这个新的temporal layer嵌入到提出的3D CNN,该网络叫做Temporal 3D ConvNets(T3D)。本文将DenseNet 结构从2D扩展到3D中。另一个贡献是将知识预先训练好的2D CNN转移到随记初始化的3D CNN以实现稳定的权值初始化。
文章思想建立在何种背景之下?在当下,提出的许多卷积神经网络不能够捕获长范围的时序信息,这限制了模型的表现,同时他们面临着如下问题:(1).这些视频结构相比2D卷积网络有许多参数;(2).训练这些模型需要相对大型的数据集;(3).光流图的获取是比较费力的,而且对于大型数据集来说,难以获取。文章提出了解决上述问题的方案:(1).采用一种网络结构可以有效的捕获视频的空间和时间特征,从而替代光流图;(2).采用一种可以在不同网络之间进行迁移的方法,从而避免网络从头训练。作者基于此提出了可变时序的3D卷积核,这种卷积核可以捕获短中长时序信息,作者将具有该特点的卷积层命名为temporal transition layer(TTL),这种思想受GooleNet启发,具体如图1。TTL的设计来concat来自不同时序之后feature map。之后作者会将该TTL嵌

如图1. Temporal Transition Layer(TTL)
入到DenseNet中,替换DenseNet结构中的transition层,这也就是所谓的T3D(Temporal 3D ConvNets),具体如图2,可以进行端到端训练。那么作者为何会选择DenseNet呢?因为其简单且有很高的参数效率,采用密集知识传播,在图像分类任务上取得非常好的表现。同时将2D DenseNet中卷积核池化核替换为3D的网络称为DenseNet3D。为了避免从头训练T3D,作者采用了跨结构迁移学习的方法,具体,作者先在ImageNet数据集上训练2D CNNs,之后通过指导性迁移来对一个随机参数初始化的3D CNNs进行学习,来获得稳定的初始化权重。之后作者在三个有挑战的数据集HMDB51,UCF-101,Kinetics上对T3D进行评估,结果显示T3D相比当下一些3D卷积网络,取得了很好的表现。

图2. T3D网络结构图
接下来,对网络中T3D的每个结构进行详细介绍。首先介绍3D DenseBlock,其类似于2D DenseBlock,内部采用密集连接,具体密集连接如图3,其具体实现采用所谓的合成函数,如图4,xl:表示第l层的输出,其输入为前l-1层的3D feature maps,Hl:表示

图3. 密集连接
对这些feature map进行concat操作,具体实现采用结构为:BN-ReLU-Conv3D。注意,xi的空间尺寸是一样的。接下来是TTL层,其内部采用了多个不同时序长度的卷积核,可以获取短,中,长信息,由于具有不同的时序,其输出的feature map个数是不一样的,但是空间大小相同,之后进行cocat操作,最后通过一个3D pooling,最红得到TTL层的输出。

图4. 合成函数
文章比较重要的就是实现了跨结构迁移学习,从与训练好的2D ConvNets到3D ConvNets。这里2D ConvNets假设已经学到了很好的图像表示,而3D ConvNets的权重采用随机初始化的方法,具体迁移学习的方法使用帧和视频片段之间的对应关系,因为它们同时出现在一起。给定一组X帧和同一时间戳的视频片段,帧和视频中的视觉信息是相同的。跨结构迁移利用这种思想来在2D和3D ConvNet架构之间的图像视频通信任务来学习中级特征表示,具体如图5。使用预先训练过的ImageNet 2D DenseNet CNN和T3D网络作为V,2D DenseNet CNN最后有4个DenseBlock卷积层和一个全连接的层,而3D架构是4个3D-DenseBlocks和一个全连接的层。作者简单地concat两个体系结构的最后一个fc层,并将它们与2048维fc层连接,之后依次连接到两个具有512和128大小的fc层(fc1,fc2)和最终的二元分类器层。作者使用一个简单的二值(0/1)匹配分类器:具体给定X个视频帧和视频片段 - 判断他们是否属于同一个时间戳。对于给定的成对X图像及其相应的视频片段,精确步骤如下:X个帧顺序送入入I并且平均X最后2D fc特征,产生1024-D特征表示,并行视频片段被提供给V,我们提取3D fc特征(1024-D),并将它们连接起来,然后传递给fc1-fc2进行分类。在训练期间,I的模型参数被冻结,而任务是有效地学习V的模型参数而没有任何额外的监督而不是帧 - 视

图5. 跨结构迁移
频之间的对应关系。属于同一视频的相同时间戳的对是正例,而来自两个不同视频的对通过X帧的随机采样和来自两个不同视频的视频剪辑是负例。注意,在反向传播期间,仅更新V的模型参数,即将知识从I传递到V.文中表明,实现了V的稳定权重初始化,并且在目标上进行微调时数据集允许模型快速适应目标数据集,从而避免从头开始训练模型并提高性能。作者证明了通过使用提出的知识转移方法,3D ConvNets可以直接在像UCF101这样的小数据集上进行训练,并且比从头开始训练获得更好的性能。
最后是实验阶段,这个阶段,作者对T3D模型和输入数据进行了search。具体结构探索,作者先从DenseNet 3D开始,对其network-size和输入数据的temporal-depth进行了测试。具体network-size测试如图6。temporal-depth测试如图7。基于上述实验

图6. 不同的network-size
结构,作者搭建了T3D,具体如图8。之后作者对ResNes-3D,I3D,DenseNet3D和T3D进行比较,这些模型都是从头开始训练,具

图7. 不同的temporal depths
体如图9。之后作者对输入数据的Frame Resolution进行了实验。对于视频帧采样率探索,具体如图11。图12显示了通过指导性迁移模型效果。图13显示了和当前最优模型的比较,显示出了T3D最有性。

图8. T3D结构

图9. T3D与其他模型比较
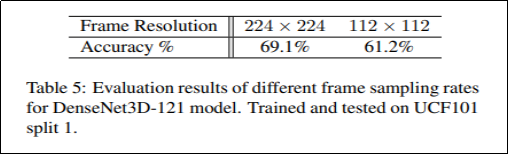
图10. 不同的Frame Resolution
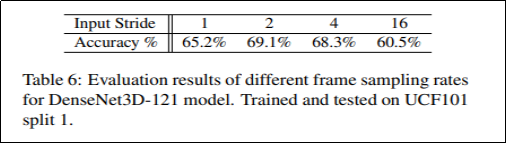
图11. 不同的 frame sampling rates

图12. 通过迁移网络效果

图13. 和不同模型比较
本文地址:https://blog.csdn.net/weixin_44402973/article/details/100167115

