
热门标签
热门文章
- 1跟我学Python图像处理丨图像分类原理与案例_图像分类案例
- 2zabbix监控交换机_zabbix添加锐捷交换机
- 3双目项目实战---测距(获取三维坐标和深度信息)_双目相机求解三维坐标点
- 4微信小程序访问webservice(wsdl)+ axis2发布服务端(Java)
- 5chromedriver和selenium的下载以及安装教程(114/116/117.....121版本)_chromedriver 121
- 6Window系统命令行调用控制面板程序_programs|and|features
- 701-Node.js 简史_nodejs历史版本
- 8【STM32】FSMC—扩展外部 SRAM 初步使用 1_stm32 外接 ram
- 9python爬虫爬取淘宝商品并保存至mongodb数据库_tbsearch?refpid=mm_26632258_3504122_32554087
- 10OpenWrt 软路由IPv6 DDNS Socat 端口映射_openwrt socat
当前位置: article > 正文
数据分析-10-扒一扒蔡徐坤微博100万+转发量的真假流量粉(包含数据和代码)
作者:花生_TL007 | 2024-03-01 16:38:37
赞
踩
数据分析-10-扒一扒蔡徐坤微博100万+转发量的真假流量粉(包含数据和代码)
0. 获取数据集
关注公众号:『AI学习星球』
回复:扒一扒蔡徐坤 即可获取数据下载。
论文辅导或算法学习可以通过公众号滴滴我

1. 项目背景与任务
项目主要随机抓取蔡徐坤100万+转发的微博《再见,“任性的”千千…》的10万条转发数据,并且分析蔡徐坤真假转发流量的比例以及真假粉丝的用户画像。根据数据分析出真假流量所占比例各有多少,假流量粉丝是如何生产出来的。
2. 数据读取
导入模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pymongo import MongoClient
from pandas.io.json import json_normalize
plt.style.use('ggplot')
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['PingFang'] #解决seaborn中文字体显示问题
plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点
plt.rcParams["figure.dpi"] =mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
%matplotlib inline
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
data = pd.read_csv('caixukun.csv')
- 1
data.to_csv('caixukun.csv', index=False)
- 1
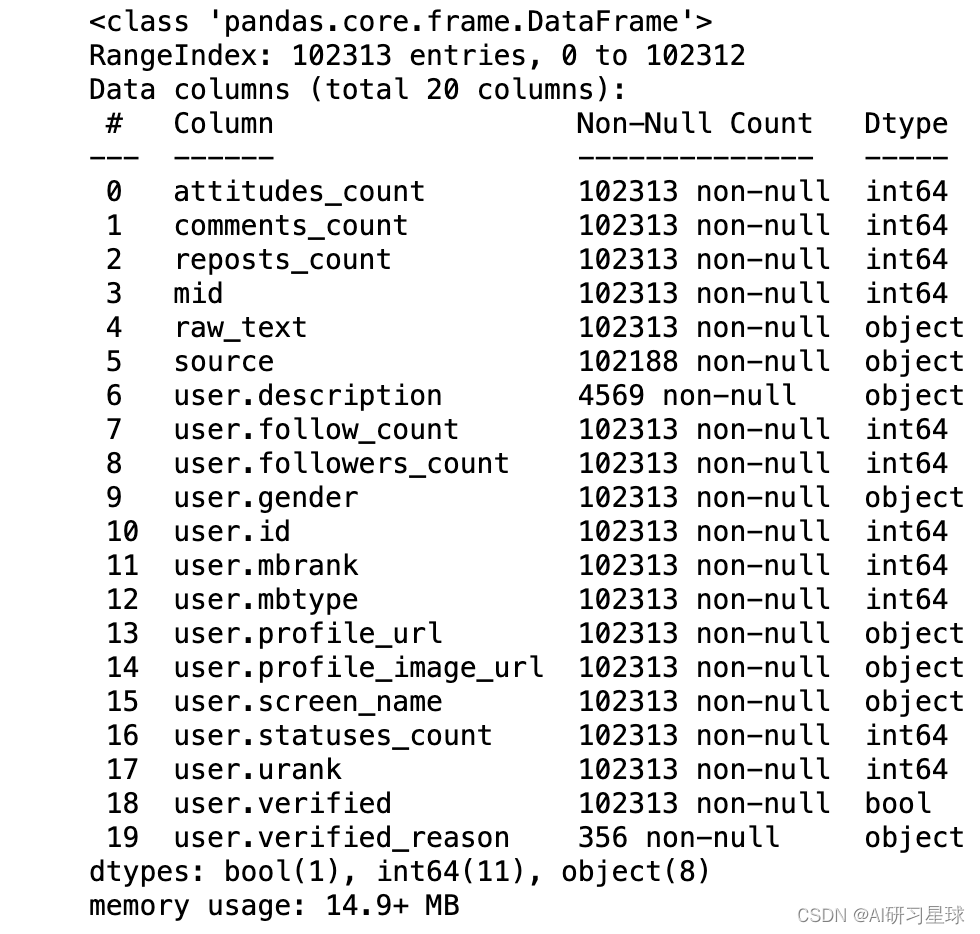
data.info()
- 1
2.1 问题
- 蔡徐坤的微博转发是否存在假流量?
- 真假流量所占的比例各有多少?
- 假流量粉丝是如何生产出来的?
- 真流量粉的粉丝画像
2.1.1 蔡徐坤的微博转发是否存在假流量?
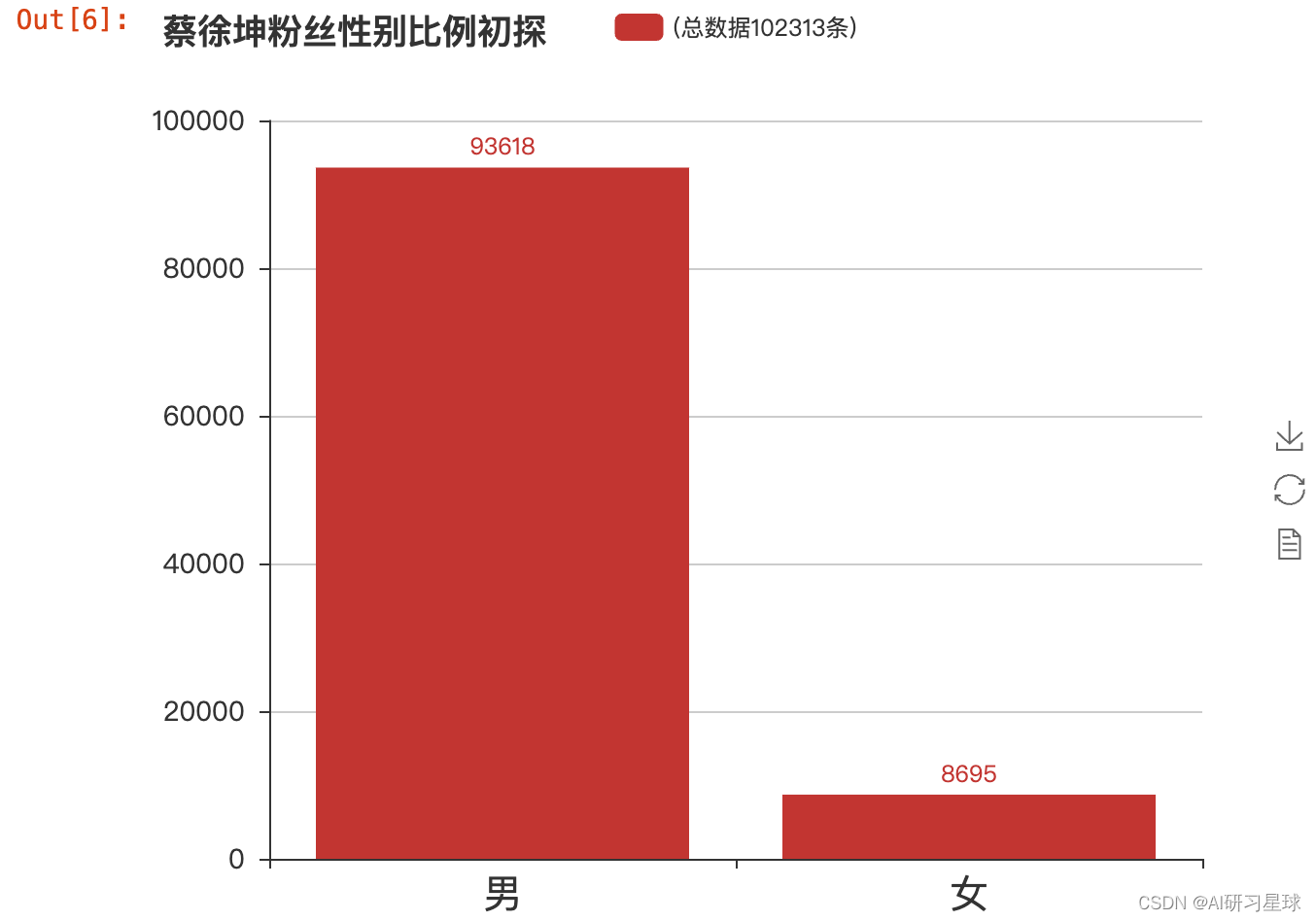
# 先来看看蔡徐坤的粉丝性别比例
fans_num = data['user.gender'].value_counts()
fans_num
- 1
- 2
- 3

from pyecharts import Bar
bar = Bar("蔡徐坤粉丝性别比例初探", width = 600,height=500)
bar.add("(总数据102313条)", ['男', '女'], fans_num.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True)
bar
- 1
- 2
- 3
- 4
- 5
- 6
np.round(fans_num/fans_num.sum()*100, 2)
- 1

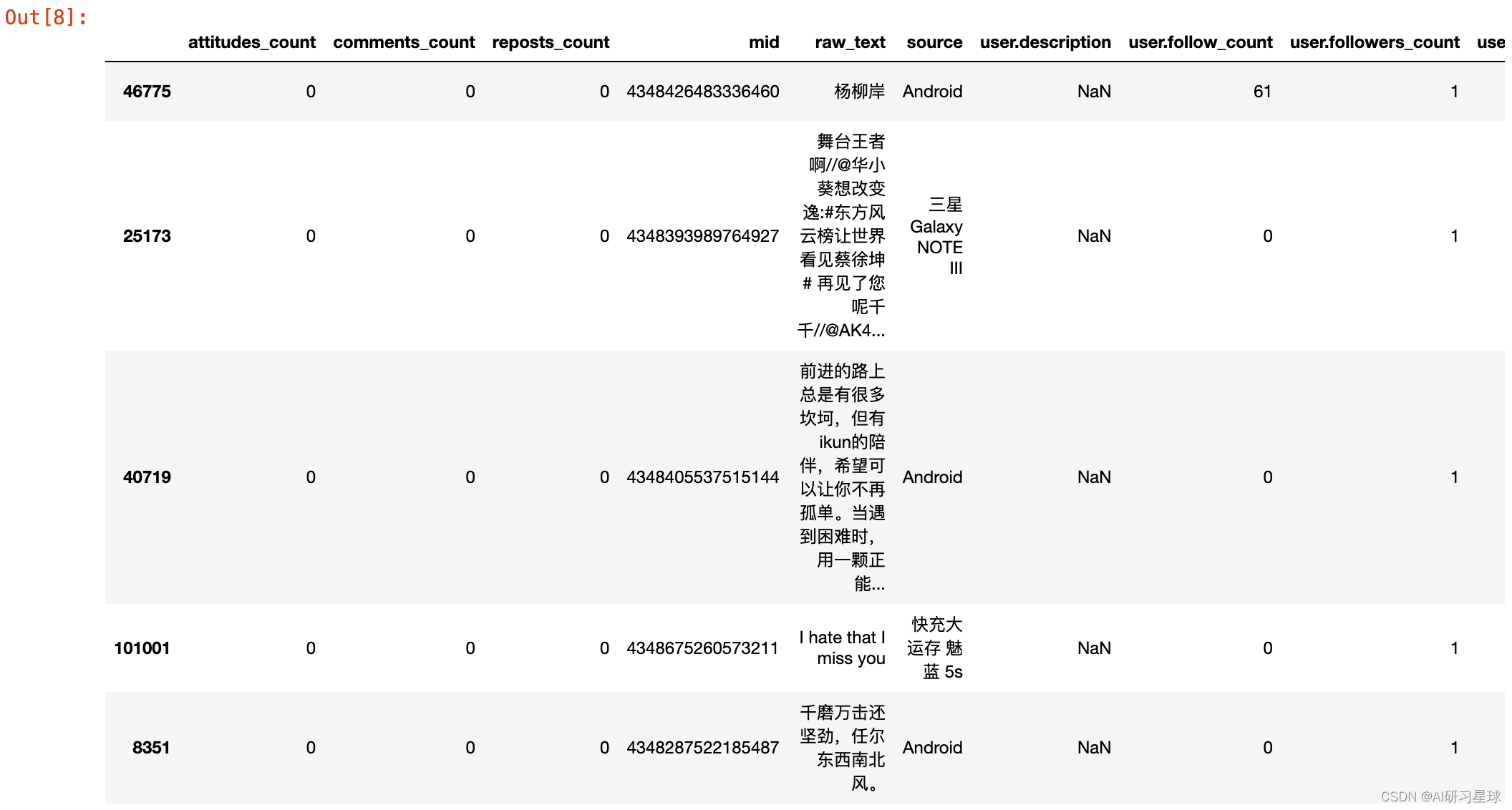
data[data['user.gender']=='m'].sample(5)
- 1
2.1.2 真假流量所占的比例各有多少
data=data.fillna({'user.description':'wu'})
- 1
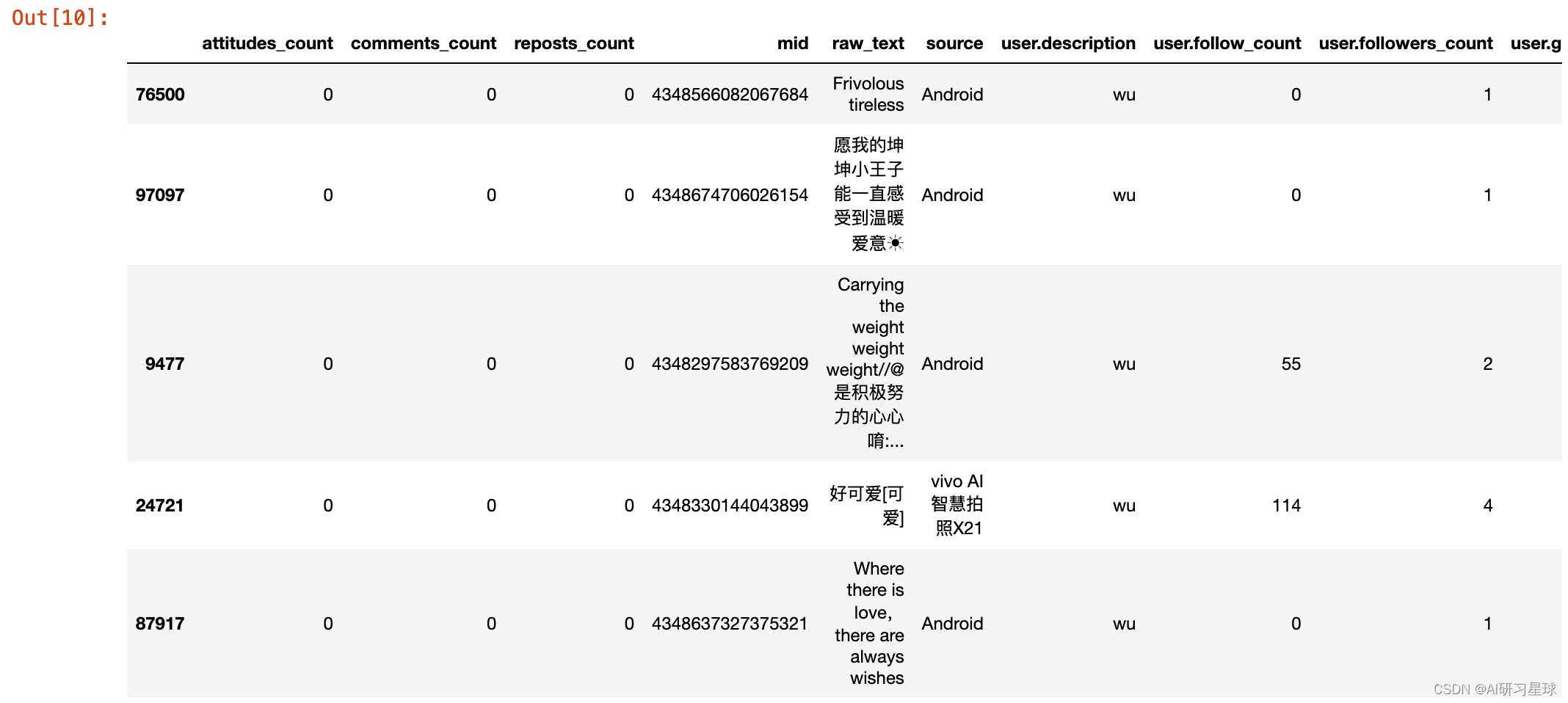
data_fake = data[((data['user.follow_count']<=5)|(data['user.followers_count']<=5))&
(data['user.description']=='wu')&
(data['comments_count']==0)&
(data['attitudes_count']==0)&
(data['reposts_count']==0)&
(data['user.mbrank']==0)]
data_fake.sample(5)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
data_fake.shape
- 1
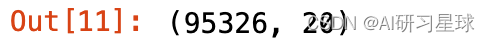
# 昵称里包含“用户”的,基本上可以断定是假粉丝
data_fake2_index = data[(data['user.follow_count']>5)&
(data['user.followers_count']>5)&
(data['user.screen_name'].str.contains('用户'))].index
- 1
- 2
- 3
- 4
# 把假的流量粉丝转发组合起来
data_fake = pd.concat([data_fake, data.iloc[data_fake2_index]])
- 1
- 2
data_fake.shape
- 1
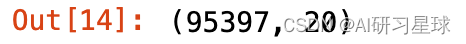
# 取出真粉的转发# 取出真粉的转发
data_true = data.drop(data_fake.index)
- 1
- 2
data_true.shape
- 1
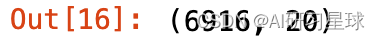
print('真粉丝转发数占总转发数的{}%'.format(np.round(data_true.shape[0]/data.shape[0]*100, 2)))
print('假粉丝转发数占总转发数的{}%'.format(np.round(data_fake.shape[0]/data.shape[0]*100, 2)))
- 1
- 2

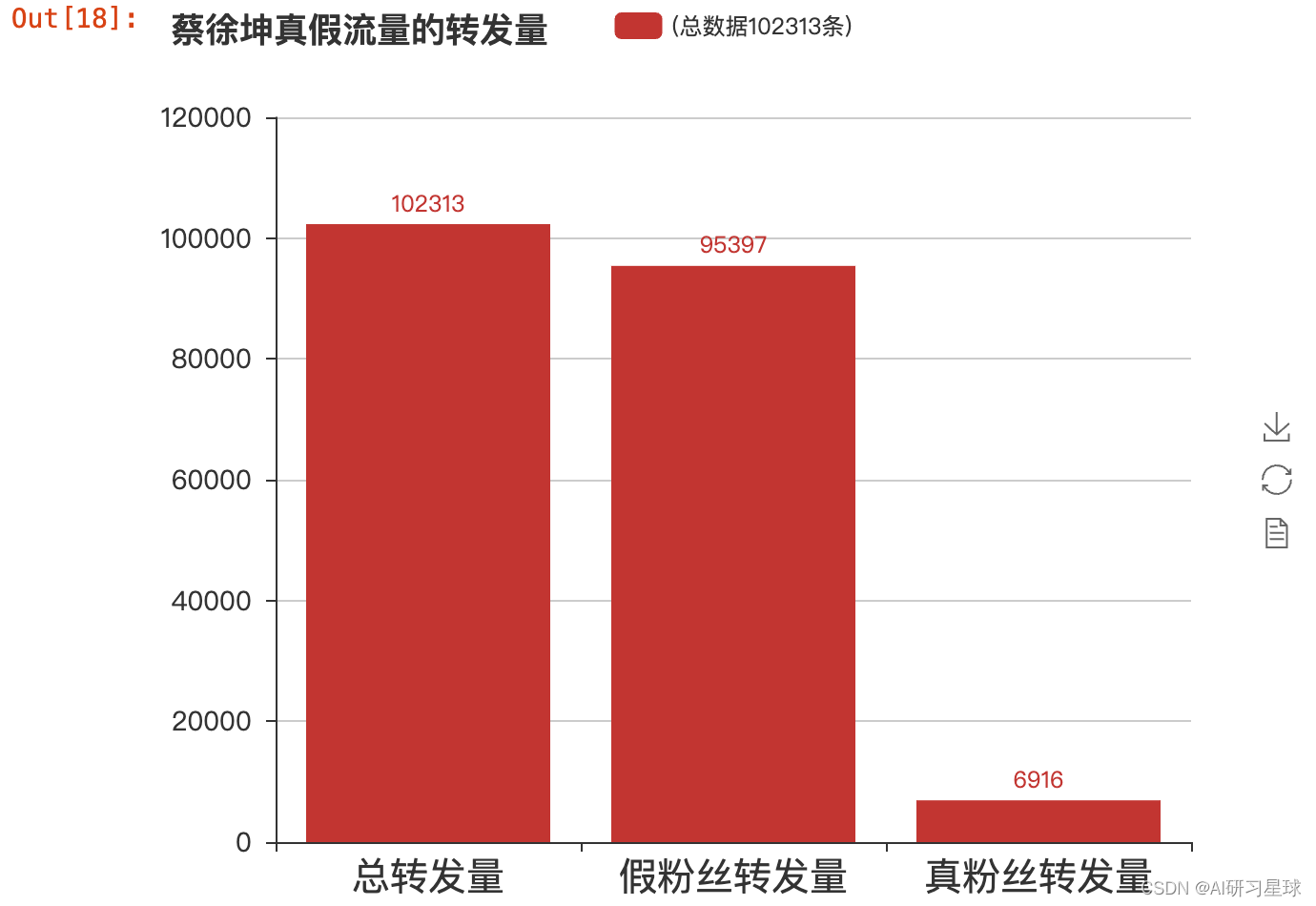
bar = Bar("蔡徐坤真假流量的转发量", width = 600,height=500)
bar.add("(总数据102313条)", ['总转发量', '假粉丝转发量', '真粉丝转发量'],
[data.shape[0], data_fake.shape[0], data_true.shape[0]], is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True)
bar
- 1
- 2
- 3
- 4
- 5
real_fans_num = data_true.drop_duplicates(subset='user.id').shape[0]
- 1
bar = Bar("蔡徐坤真假流量的转发量与真实转发粉丝量(总数据102313条)", width = 600,height=500)
bar.add('', ['总转发量', '假粉丝转发量', '真粉丝转发量', '真实转发粉丝量'],
[data.shape[0], data_fake.shape[0], data_true.shape[0], real_fans_num], is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, xaxis_rotate=20)
bar
- 1
- 2
- 3
- 4
- 5
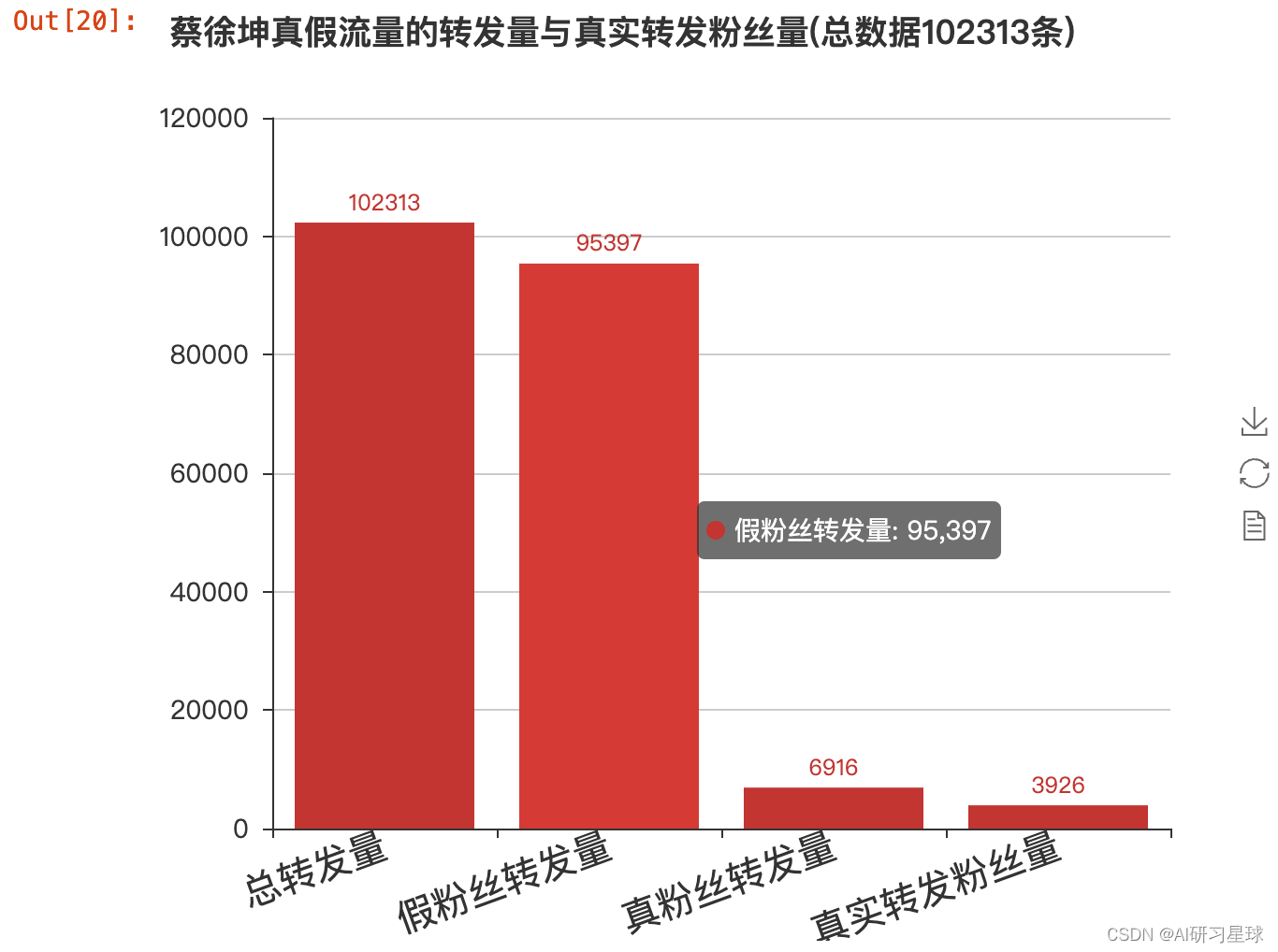
print('真实转发粉丝量占总转发数的{}%'.format(np.round(real_fans_num/data.shape[0]*100, 2)))
- 1
真实转发粉丝量占总转发数的3.84%
data.sample(5)
- 1
2.1.3 假流量粉丝是如何生产出来的?
data_fake_gender = data_fake.drop_duplicates(subset='user.id')['user.gender'].value_counts()
data_fake_gender
- 1
- 2

data_fake[data_fake['user.gender']=='f'].sample(5)
- 1
bar = Bar("蔡徐坤假粉丝性别比例", width = 600,height=500)
bar.add("(假粉丝总数为40838)", ['男', '女'], data_fake_gender.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True)
bar
- 1
- 2
- 3
- 4
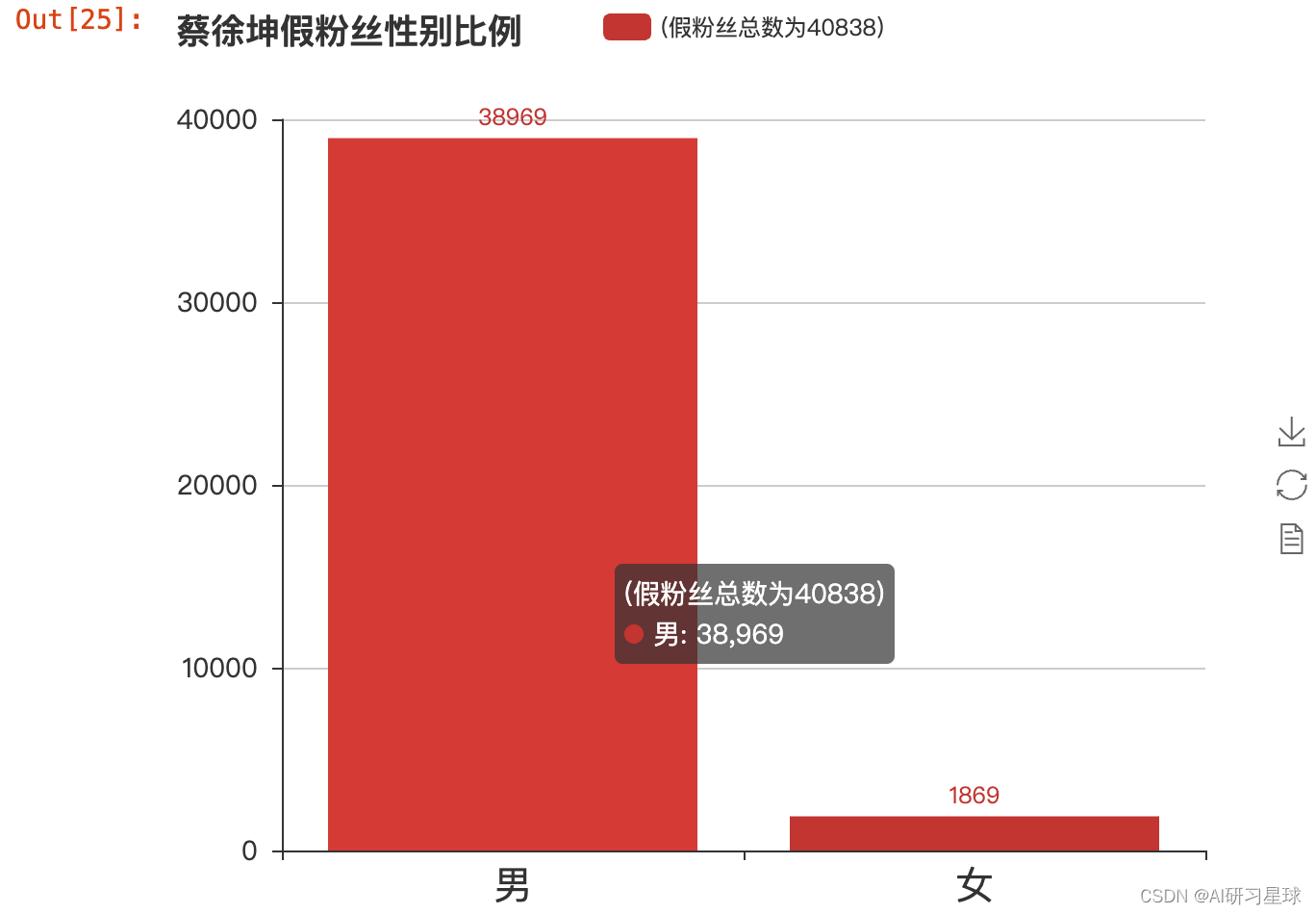
38969/40838
- 1
0.954233801851217
data_fake['raw_text'].value_counts()
- 1

fake_source = data_fake['source'].value_counts()[:10]
- 1
bar = Bar("蔡徐坤假粉丝Top10转发设备", width = 600,height=600)
bar.add("", fake_source.index, fake_source.values, is_stack=True,
xaxis_label_textsize=11, yaxis_label_textsize=14, is_label_show=True, xaxis_rotate=30)
bar
- 1
- 2
- 3
- 4
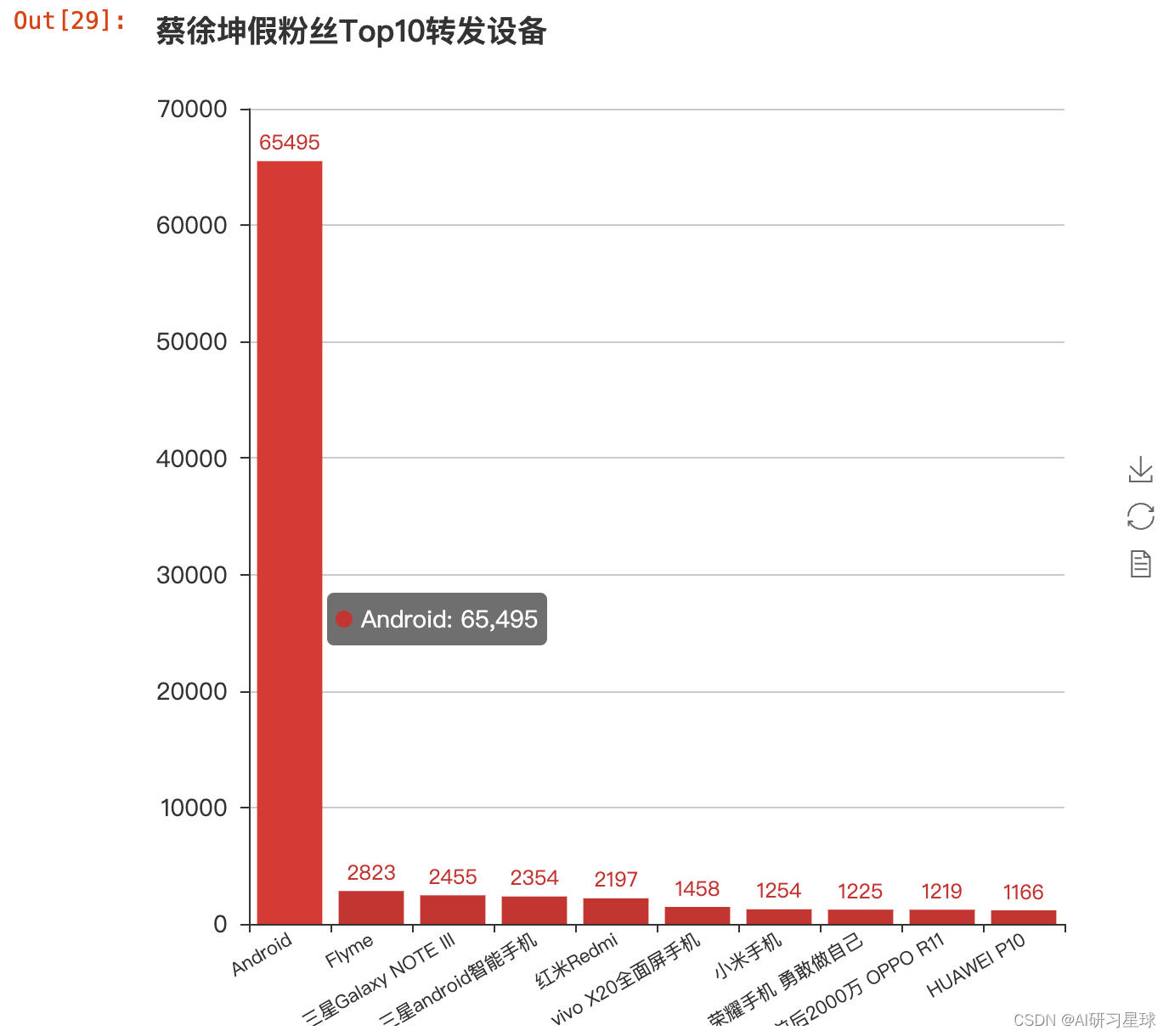
data_fake['user.follow_count'].mean()
- 1
3.4412612555950397
data_fake['user.followers_count'].mean()
- 1
1.04576663836389
data_fake_sample = data_fake.sample(5)
data_fake_sample['user.screen_name']
- 1
- 2

data_fake_sample['user.profile_image_url'].values
- 1

data_fake.sample(5)['user.screen_name']
- 1

data_fake['user.screen_name'].str.contains('蔡|坤|葵|kun').sum()
- 1
41766
data_fake.shape[0]
- 1
95397
data_fake['user.statuses_count'].mean()
- 1
72.4942503433022
2.1.4 真流量粉的粉丝画像
data_true.sample(5)
- 1
data_true_gender = data_true.drop_duplicates(subset='user.id')['user.gender'].value_counts()
data_true_gender
- 1
- 2

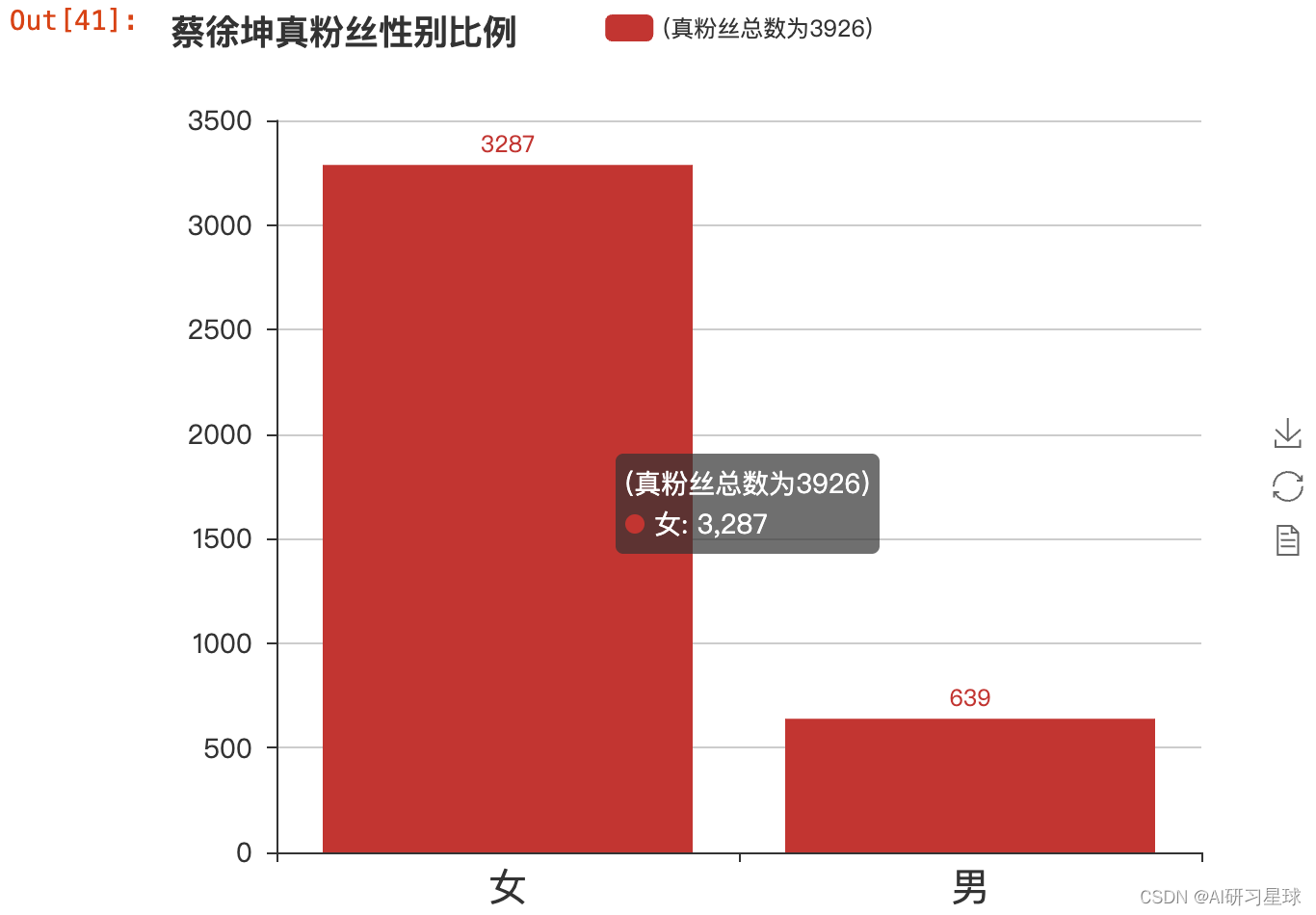
bar = Bar("蔡徐坤真粉丝性别比例", width = 600,height=500)
bar.add("(真粉丝总数为3926)", ['女', '男'], data_true_gender.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True)
bar
- 1
- 2
- 3
- 4
data_true['raw_text'].value_counts()
- 1

true_source = data_true['source'].value_counts()[:10]
- 1
bar = Bar("蔡徐坤真粉丝Top10转发设备", width = 600,height=600)
bar.add("", true_source.index, true_source.values, is_stack=True,
xaxis_label_textsize=11, yaxis_label_textsize=14, is_label_show=True, xaxis_rotate=30)
bar
- 1
- 2
- 3
- 4
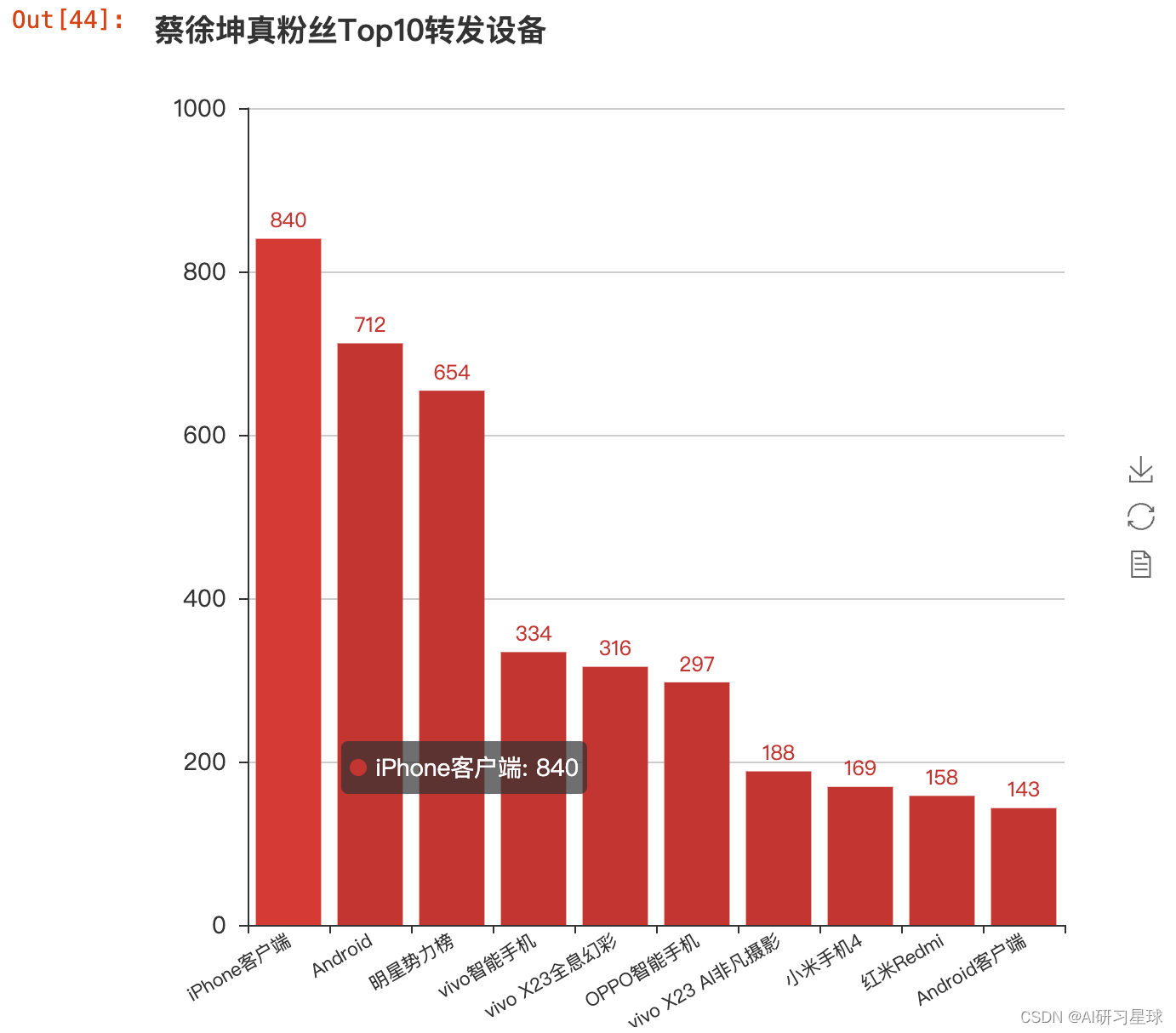
data_true['user.follow_count'].mean()
- 1
222.0597165991903
data_true['user.followers_count'].mean()
- 1
178.9480913823019
data_true.sample(5)['user.screen_name']
- 1

data_true['user.screen_name'].str.contains('蔡|坤|葵|kun').sum()
- 1
3153
data_true.shape[0]
- 1
6916
# 绘制蔡徐坤真粉丝的简介词云图
import jieba
from collections import Counter
from pyecharts import WordCloud
jieba.add_word('蔡徐坤')
swords = [x.strip() for x in open ('stopwords.txt')]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
def plot_word_cloud(data, swords, columns):
text = ''.join(data[columns])
words = list(jieba.cut(text))
ex_sw_words = []
for word in words:
if len(word)>1 and (word not in swords):
ex_sw_words.append(word)
c = Counter()
c = Counter(ex_sw_words)
wc_data = pd.DataFrame({'word':list(c.keys()), 'counts':list(c.values())}).sort_values(by='counts', ascending=False).head(100)
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", wc_data['word'], wc_data['counts'], word_size_range=[20, 100])
return wordcloud
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
plot_word_cloud(data=data_true, swords=swords, columns='user.description')
- 1
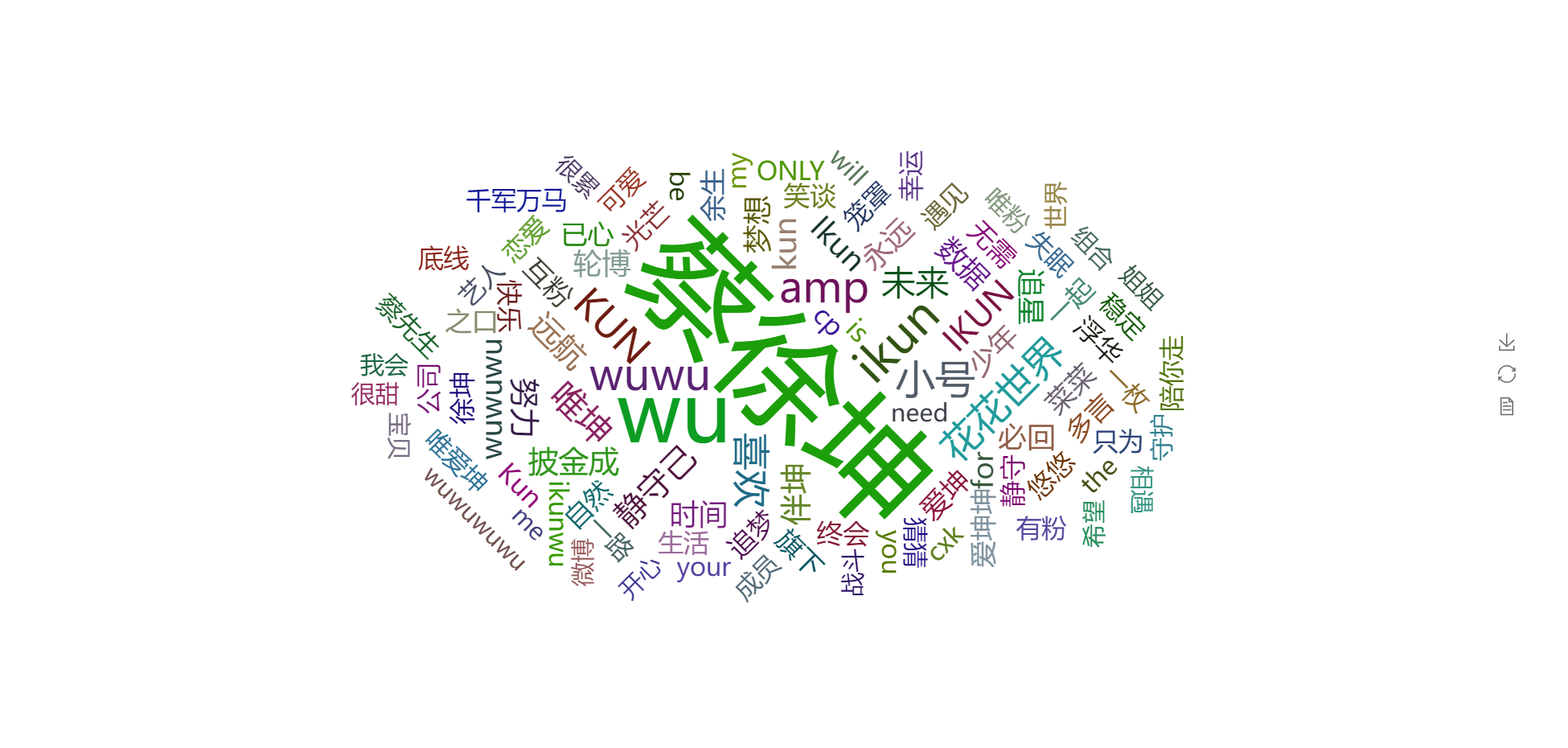
plot_word_cloud(data=data_true, swords=swords, columns='raw_text')
- 1

关注公众号:『AI学习星球』
回复:扒一扒蔡徐坤 即可获取数据下载。
论文辅导或算法学习可以通过公众号滴滴我
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/175359
推荐阅读
相关标签

