
- 1gitlab配置ssh自用精简步骤_gitlab查看ssh配置
- 2ssh内网穿透失败_usr/bin/ssh-copy-id: error: ssh: connect to host 1
- 3教程|幻兽帕鲁服务器数据备份与恢复_帕鲁 linux
- 410种常用的分析模型 数据分析必看
- 5ssh localhost免密登录
- 6anaconda_conda init bash
- 73 python pandas_python3 pandas
- 8美狐讲堂:视频用直播用SDK盘点_aliplayer和ijkplayer
- 9DHCP自动获取IP地址实验(思科)
- 10Pycharm踩坑路_win11无法启动pychar2023
AAAI顶会行人重识别算法详解——Relation Network for Person Re-identification
赞
踩
数据及代码链接见文末
源码详解:https://blog.csdn.net/qq_52053775/article/details/129344235
1.论文整体框架概述
在行人重识别任务中,通常都是对整个输入数据进行特征提取,但是缺少了局部信息。能不能既考虑局部与整体信息,也同时加入他们的联系呢?这篇论文主要的思想就是局部信息和全局信息的融合。
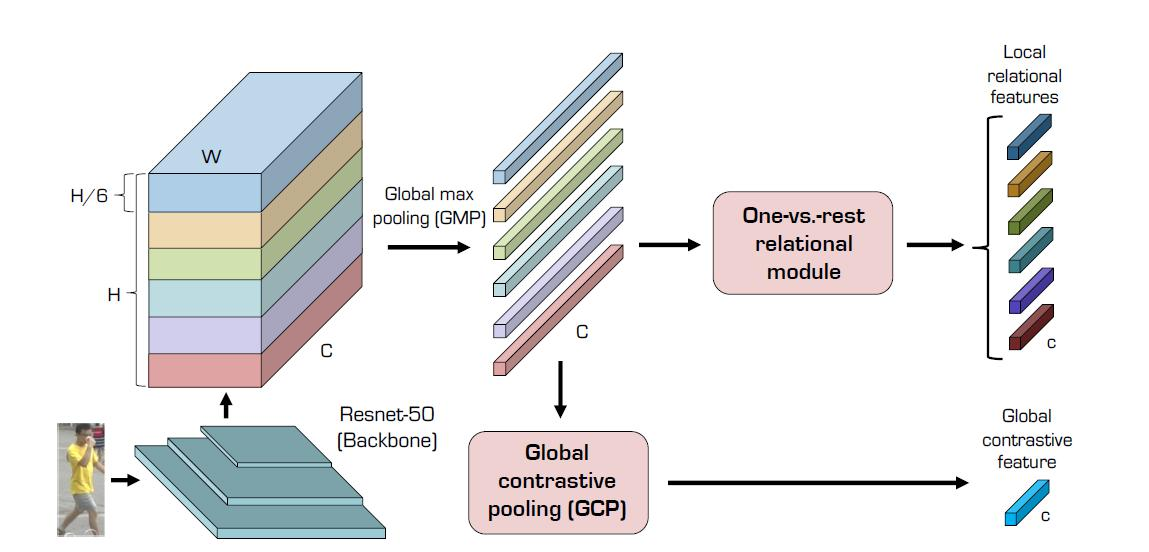
整体流程如上图所示,
- 首先对整体进行特征提取, 通常采用图像分类网络(如resnet50)进行特征提取,获得特征图
-
然后将特征图分块,这篇论文中直接在h维度进行截取分块,并没有利用其它辅助信息。可以理解为将人分为不同的局部区域
-
然后就是整个论文的核心部分,GCP模块提取得到全局特征,One-vs-Rest获得局部特征。对于全局特征的获取, Maxpool提取到的是整体全局的特征,avgPool代表的是分散的局部特征的平均,会引入局部与背景信息。为了消除干扰,使用Avgpool-MaxPool即得到了分散的局部特征与全局特征的差异程度(关系),然后使用卷积层去学习这种关系,并与Maxpool经过卷积的全局特征进行拼接,使用卷积提取出全局特征。但是作者并未给出证明,能否应用于其他领域还需要进行实验验证


- 局部特征提取one vs rest的核心思想是别把局部信息孤立来算。它的做法是取出一个特征,然后将剩余的特征分为一组。分别进行特征提取后进行拼接,然后经过卷积层得到最终的输出结果。我们可以将每一次的卷积过程视为一次特征整个过程,给予不同的特征点以不同的权重。

损失函数
通常是分类损失(交叉熵)+Triplet loss(目标其实就是为了让特征提取的更好)
分类损失不必多说,重点是Triplet loss。
Triplet loss首先需要我们准备3份数据(可以从一个batch中选择),假设为A,P,N,P与A是同一个人,N是其他人的图像。 Triplet loss的目的是使A与P的特征足够的近,而与N的特征足够的远。这样,我们就能够很好的区分同一个人和不同的人。

因此我们的初步的 公式为:(其中f表示通过网络进行编码)

但是,我们可以发现,如果f的权重参数全部取0,这个目标完全成立。因此,我们做出优化:![]()
其中,a表示间隔,表示同一个人特征差异和不同的人的特征差异的距离。
在实际使用中,我们常用以下式子:
![]()
即我们计算同一个人特征差异和不同的人的特征差异的距离较小的损失,但是这显然大多数数据都符合,那么,损失函数如何进行优化呢?
由此,我们在引入hard negative方法,也就是在选择样本的时候:
让d(A,P)≈d(A,N) ,即选择相同人的样本的时候,选择相似度较小的,选择不同的人的样本时,选择相似度较大的,这样给网络一些挑战,才能刺激它来学习.
此外,为了能够使各个部分的特征提取得更好,作者还使用了辅助损失的训练策略。在图中、
、
、
、
、
均加入了辅助损失。

Abstract
以往行人重识别相关工作表明,利用描述身体部位的局部特征,以及一个人的图像本身的全局特征,可以提供健壮的特征表示,即使是在缺失的身体部位的情况下。然而,直接使用个体部位层次的特征,而不考虑身体部位之间的关系,很难分辨身体部分具有相似特征的人。为了解决这个问题,作者提出了一种reID关系网络,它考虑了个体身体部位与其他部分之间的关系。模型各部分的局部特征包含了身体其他部位的部分信息,使特征更具鉴别性。作者还引入了一种全局对比池(GCP)方法来获得一个人的图像的全局特征。作者建议使用GCP的对比特征来补充传统的最大值和平均池化技术。
Introduction
使用cnn的reID方法通常侧重于提取人图像的全局特征,但是这种特征表示比较有限,它可能不能解释类内的变化(例如,人的姿态、遮挡、背景杂波)。而划分身体部位的特征提取方式提取的部分层次的特征比全局特征提供更好的人表示,但是聚集单个局部特征时,仅仅通过连接它们而不考虑身体部位之间的关系,这并不能区分图像之间相应部分具有相似属性的不同人的身份。
为此,作者引入了一个新的利用身体部位的one-vs.-rest关系的关系模块。它解释了个体身体部位与其他部位之间的关系,使每个部分级特征都包含了相应部分本身和身体其他部位的信息,支持其更具区别性。
作者观察到,1)直接使用全局平均和最大池化技术(GAP和GMP)来获得一个人的图像的全局特征并不能提供性能增益,2) GMP比GAP提供更好的结果。在此基础上,作者还提出了一种基于GMP的全局对比池(GCP)方法,以获得更好的特征表示,该方法自适应地聚合了整个部分级特征的GAP和GMP结果。具体来说,它利用池化结果之间的差异,并以残余的方式提取互补信息以获得最大的池化特征。
Our Approach
如图所示,首先经过Backbone进行特征提取以获得H*W*C的特征图,然后在水平方向上分为6个网格,分别代表不同的身体区域。经过最大池化获得1*1*C的各部位的特征。然后,一方面,经过one-vs-rest同时获得局部特征和每个身体部位和其余部位的关系,最后输出的局部特征为1*1*c。另一方面,经过GCP模块获得全局特征,最后,将全局特征与局部特征进行特征,输出维度为1 × 1 × 7c 的融合特征。

Relation networks for part-based reID
Part-level features. 使用resnet50进行特征提取,取出resnet50的池化层和全连接层,并将最后一层卷积层stride置1. 然后将特征图在水平方向上划分为6个区域,每个部分维度为H/6 × W × C.使用全局最大池化获得每部分的特征1 × 1 × C
One-vs.-rest relational module. 局部特征提取one vs rest的核心思想是别把局部信息孤立来算。它的做法是取出一个部位的特征,然后将剩余的特征分为一组,将剩余的特征取平均代表整个剩余的特征。分别使用1*1的卷积获得1 × 1 × c的特征。将局部特征与剩余部位的特征
拼接,使用1*1的卷积获得 1 × 1 × c的最终的考虑到身体部位之间的关系的局部特征。然后使用残差连接获得最终的输出。


GCP
GAP获得的特征能够覆盖整个人,但是容易受到背景噪声的影响,GMP不易受到背景的影响,但是获取的仅仅是具有代表性的特征,并不能覆盖全身,但是GMP更加高效。作者提出的GCP是基于GMP的这种特点,使用GMP-GAP即得到了分散的局部特征与全局特征的差异程度(关系),对GMP和这种差异分别经过1*1的卷积,然后将GMP和差异特征进行拼接。并经过1*1的卷积得到1*1*c的最终的全局特征。
Experimental Results
Implementation details
Dataset. Market1501 CUHK03 DukeMTMC-reID
在实际的训练中,作者还混合了分两个区域、四个区域、6个区域的结果。
Comparison with the state of the art
 Qualitative results.
Qualitative results.

Discussion
- GMP的实验结果优于GMP
- GCP的实验结果优于GMP, GAP and GMP+GAP
- 使用多个分区(2个、4个、6个)能够极大的提升性能

链接:https://pan.baidu.com/s/1JD_9zea40JW--xbp-vRBoQ?pwd=6uop
提取码:6uop

