
- 1C++ //练习 9.34 假定vi是一个保存int的容器,其中有偶数值也有奇数值,分析下面循环的行为,然后编写程序验证你的分析是否正确。
- 2海思SD3403,SS928/926,hi3519dv500,hi3516dv500移植yolov7,yolov8(16)-Yolov9探索_3403 yolo
- 3git push 失败,You are not allowed to push code to this project 常见六大原因_you are not allowed to push code to this project.
- 4Ubuntu18.04修改主机名和用户名(八十八)_ubuntu接入网络后主机名更改
- 5机器学习各类算法的优缺点
- 6tomcat 只输ip或localhost就可以直接访问项目的步骤
- 7边缘智能:实现实时数据处理和智能决策的新一代技术
- 8JAVA我的世界给op_我的世界op指令代码_我的世界op指令大全_飞翔教程
- 9selenium+webdriver+HTML 经常遇到的问题_javascript error: arguments[0].click is not a func
- 10银河麒麟(kylin)下载_银河麒麟下载
机器学习 | 模型性能评估
赞
踩
现在我们已经对模型训练有了初步了解,下面我们接着聊评估:
一. 回归模型的性能评估
对于一个已经训练好的回归模型,我们需要知道模型训练的好坏程度,即需要对模型进行评估
这里给出几个评估指标:
1. 平均平方误差(MSE)
M S E = 1 m ∑ i = 1 m ( y i − y ^ i ) 2 ,又称为均方误差 MSE = \frac{1}{m} \sum_{i=1}^{m}(y_{i}-\hat{y}_{i} )^{2},又称为均方误差 MSE=m1i=1∑m(yi−y^i)2,又称为均方误差
2. 平均绝对误差(MAE)
M A E = 1 m ∑ i = 1 m ∣ y i − y ^ i ∣ ,又称为绝对误差 MAE = \frac{1}{m} \sum_{i=1}^{m}\mid y_{i}-\hat{y}_{i}\mid,又称为绝对误差 MAE=m1i=1∑m∣yi−y^i∣,又称为绝对误差
3. R 2 R^{2} R2 值
回归模型默认的score评估指标
R 2 = 1 − R S S T S S = 1 − ∑ i = 1 m ( y i − y ^ i ) 2 ( y i − y ˉ ) 2 ,其中 y ˉ = 1 m ∑ i = 1 m y i R^{2}=1-\frac{RSS}{TSS} = 1-\frac{\sum_{i=1}^{m}(y_{i}-\hat{y}_{i} )^{2}}{(y_{i}-\bar{y} )^{2}},其中\bar{y} = \frac{1}{m}\sum_{i=1}^{m}y_{i} R2=1−TSSRSS=1−(yi−yˉ)2∑i=1m(yi−y^i)2,其中yˉ=m1i=1∑myi
其中 r 2 r^{2} r2的取值范围为(-∞,1]
当值为1时,即 预测值 = 真值
当值为0时,即 预测值 = 均值 (预测结果很差)
当值小于0时,模型一定有问题,不如直接用均值
- 1
- 2
- 3
3.1 R 2 R^{2} R2优点
给定指标范围,对于模型好坏的判断会更直观
- 1
二. 分类模型的性能评估
这里我们先引入混淆矩阵
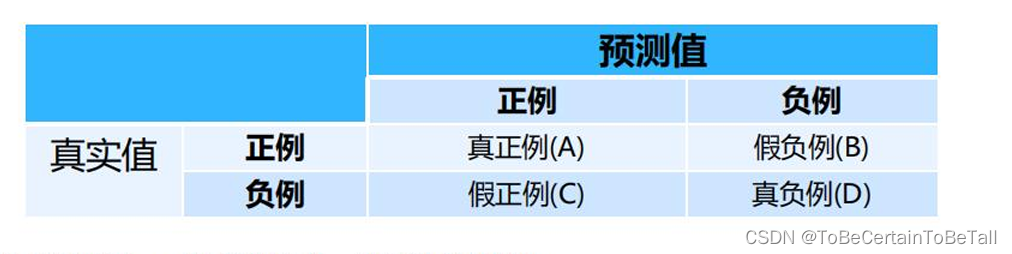
概念解释:
混淆矩阵是在统计学中用来衡量分类模型性能的矩阵
它以矩阵的形式展示了模型在测试数据集上的预测结果与实际结果之间的关系
- 1
- 2
- 3
这里补充什么是正例:工程中关注的为正例,取决于需求;比如,核酸的阳性,垃圾邮件等都可以为正例
1. 准确率(Accuracy)
A c c u r a c y = A + D A + B + C + D Accuracy=\frac{A+D}{A+B+C+D} Accuracy=A+B+C+DA+D
检测正确的样本数/总样本数
注意:一般不用这个指标
原因:在正负样本数差距太大时,会失真
比如:
阴性样本990个,阳性样本10个
模型检测到了所有得阴性样本,即990个
模型此时准确率为99%
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2. 召回率(Recall)
R e c a l l = A A + B Recall=\frac{A}{A+B} Recall=A+BA
检测正确的正例样本数/总正例样本数
- 1
3. 精确率(Precision)
P r e c i s i o n = A A + C Precision=\frac{A}{A+C} Precision=A+CA
检测正确的正例样本数/检测为正例的样本数
- 1
召回率和精确率,谁更重要?
看工作需求,以及后续操作
对于这两个指标,再补充一种好理解得方式:
召回率:是目标就揪出来
精确率:目的地必须是目标
例子:
正常邮件必须放在A内,不能出现在垃圾邮件存放处
垃圾邮件偶尔可以出现在A处
垃圾邮件存放处只能存放垃圾邮件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4. F S c o r e F_{Score} FScore
精确率和召回率互相影响,理想状态下肯定追求两个都高
但是实际情况是两者相互“制约”:
追求精确率高,则召回率就低
追求召回率高,则通常会影响精确率
分类模型默认的score评估指标
F S c o r e = ( 1 + β 2 ) P r e c i s i o n ∗ R e c a l l β 2 P r e c i s i o n + R e c a l l F_{Score}=(1+\beta ^{2} ) \frac{Precision\ast Recall}{\beta ^{2}Precision+Recall} FScore=(1+β2)β2Precision+RecallPrecision∗Recall
β=1:表示Precision与Recall一样重要
F1可以看作是模型准确率和召回率的调和平均数,最大值是1,最小值是0
注意:存在精确率和召回率都为1时
β<1:表示Precision比Recall重要
β>1:表示Recall比Precision重要
- 1
- 2
- 3
- 4
- 5
5. PR-曲线和AP值
以召回率为横轴,精确率为纵轴,即画出PR-曲线
PR曲线与X轴围成的图形面积,即AP值
AP值为1时模型性能最好
- 1
- 2
- 3
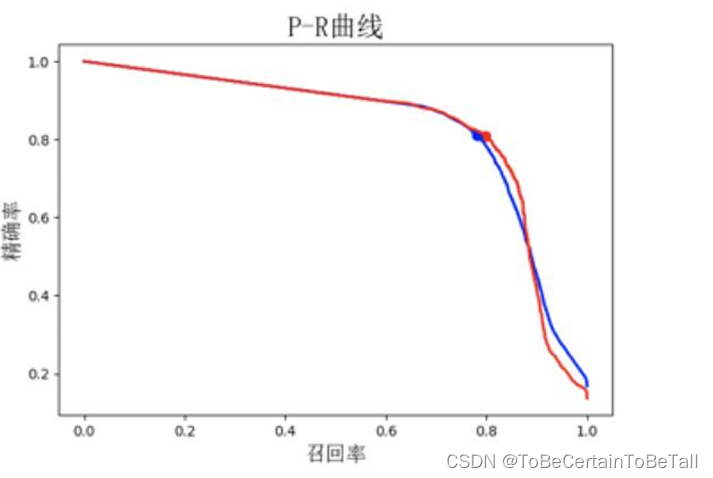
PR曲线由阈值控制
比如:
0.3以上全部判为阳性
抓回的样本数量多,即召回率高
抓回样本中有阴性样本,即精确率低
即随着阈值的降低,召回率越高,精确率越低
比如:
AP值小,即面积较小时,说明:P值下降很快,阈值在0.7左右时有大量负样本
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6. ROC曲线
当正负样本不平衡时,这种模型评价方式比起一般的精确度评价方式的好处尤其显著
横坐标为false positive rate(FPR): FP/(FP+TN) 对应混淆矩阵中的C/C+D,这个值的描述的点是预测错误的点,即越小越好,为1最差 纵坐标为true positive rate(TPR) TP/(TP+FN) 对应混淆矩阵中的A/A+B,这个值的描述的点是预测正确的点,即越大越好 ROC曲线: (0,1):即FPR为0,TPR为1;正样本全部检测到,负样本没有被误判 (1,0):即FPR为1,TPR为0;最糟糕的分类器,误判所有样本 但该分类器可以使用,因为分类很成功 (0,0):即FPR为0,TPR为0;正样本全部未检测到,负样本没有被误判 (1,1):分类器上预测所有的样本点都为1 在随机测下方的ROC曲线,需要进行翻转 阈值: 可以通过控制阈值,来改变预测的标签;阈值越严格,正样本数量越少 阈值由1向0滑动,TPR和FPR从0向1滑动 当阈值取0时,对应图中的右上角点(全部预测为正例) 当阈值取1时,对应图中的左下角点(全部预测为负例)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
ROC曲线越接近(0,1),该分类器的性能越好
ROC曲线反映了FPR与TPR之间权衡的情况:
在TPR随着FPR递增的情况下,谁增长得更快,快多少的问题
模型分类性能越好:
TPR增长得越快,曲线越往上屈,AUC就越大
其中,AUC为ROC曲线下的面积,取值范围是[0.5,1]
- 1
- 2
- 3
- 4
感谢阅读声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

