
热门标签
热门文章
- 1LeetCode 73. 矩阵置零(java实现)_矩阵置0原地算法 java
- 2Oracle中给表赋予权限_oracle给用户赋予某个表的权限
- 3Android 11 解决开机动画到Launcher黑屏问题
- 4【Java程序设计实训】基于B/S架构的MyShop商城_java b/s架构 idea
- 5【Java编程教程】详解Java 构造函数_java构造函数
- 6org.greenrobot.eventbus.EventBusException_org.greenrobot.eventbus.eventbusexception: subscri
- 7移除设备和驱动器的WPS网盘图标,亲测有效,不在恢复_彻底删除wps网盘图标
- 8Jprofiler的使用查看oom_jprofile如何查看oom异常
- 9为什么人工智能用 Python?_为什么python在ai
- 10【SQL Server】实验四 数据更新
当前位置: article > 正文
python与深度学习(十三):CNN和IKUN模型_python ikun
作者:花生_TL007 | 2024-03-07 11:04:07
赞
踩
python ikun
1. 说明
本篇文章是CNN的另外一个例子,IKUN模型,是自制数据集的例子。之前的例子都是python中库自带的,但是这次的例子是自己搜集数据集,如下图所示整理。

在这里简单介绍如何自制数据集,本人采用爬虫下载图片,如下,只需要输入需要下载图片的名字,然后代码执行之后就会自动爬取图片。当然在使用爬虫的时候需要下载好相关的库。
""" objective:爬取任意偶像/单词的百度图片 coding: UTF-8 """ # 导入相关库 import re import requests import os def download(html, search_word, j): pic_url = re.findall('"objURL":"(.*?)",.*?"fromURL"', html, re.S) # 利用正则表达式找每一个图片的网址 # print(pic_url) n = j * 60 for k in pic_url: print('正在下载第' + str(n + 1) + '张图片,图片地址:' + str(k)) try: pic = requests.get(k, timeout=20) except requests.exceptions.ConnectionError: print('当前图片无法下载') continue dir_path = r'D:\偶像图片\偶像' + search_word + '_' + str(n + 1) + '.jpg' if not os.path.exists('D:\偶像图片'): os.makedirs('D:\偶像图片') fp = open(dir_path, 'wb') fp.write(pic.content) fp.close() n += 1 if __name__ == '__main__': name = input("输入你想要获取偶像的名称: ") headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'} page = 2 # 可以自定义,想获取几页就是几页,一页有60张图片,但是有的可能就很少,自己注意下 for i in range(page): url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + name + '&pn=' + str(i * 20) # 网址 result = requests.get(url, headers=headers) # 请求网址 # print(result.content) # 如果运行失败,一步一步找到原因,可以先看下网页输出的内容 download(result.content.decode('utf-8'), name, i) # 保存图片 print("偶像图片下载完成")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
2. IKUN模型
2.1 导入相关库
以下第三方库是python专门用于深度学习的库。需要提前下载并安装
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D
from keras.optimizers import RMSprop, Adam
from keras.preprocessing.image import ImageDataGenerator
import sys, os # 目录结构
import matplotlib.pyplot as plt
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.2 建立模型
这是采用另外一种书写方式建立模型。
构建了三层卷积层,三层池化层,然后是展平层(将二维特征图拉直输入给全连接层),然后是三层全连接层,并且加入了dropout层。
"1.模型建立" # 1.卷积层,输入图片大小(150, 150, 3), 卷积核个数16,卷积核大小(5, 5), 激活函数'relu' conv_layer1 = Conv2D(input_shape=(150, 150, 3), filters=16, kernel_size=(5, 5), activation='relu') # 2.最大池化层,池化层大小(2, 2), 步长为2 max_pool1 = MaxPool2D(pool_size=(2, 2), strides=2) # 3.卷积层,卷积核个数32,卷积核大小(5, 5), 激活函数'relu' conv_layer2 = Conv2D(filters=32, kernel_size=(5, 5), activation='relu') # 4.最大池化层,池化层大小(2, 2), 步长为2 max_pool2 = MaxPool2D(pool_size=(2, 2), strides=2) # 5.卷积层,卷积核个数64,卷积核大小(5, 5), 激活函数'relu' conv_layer3 = Conv2D(filters=64, kernel_size=(5, 5), activation='relu') # 6.最大池化层,池化层大小(2, 2), 步长为2 max_pool3 = MaxPool2D(pool_size=(2, 2), strides=2) # 7.卷积层,卷积核个数128,卷积核大小(5, 5), 激活函数'relu' conv_layer4 = Conv2D(filters=128, kernel_size=(5, 5), activation='relu') # 8.最大池化层,池化层大小(2, 2), 步长为2 max_pool4 = MaxPool2D(pool_size=(2, 2), strides=2) # 9.展平层 flatten_layer = Flatten() # 10.Dropout层, Dropout(0.2) third_dropout = Dropout(0.2) # 11.全连接层/隐藏层1,240个节点, 激活函数'relu' hidden_layer1 = Dense(240, activation='relu') # 12.全连接层/隐藏层2,84个节点, 激活函数'relu' hidden_layer3 = Dense(84, activation='relu') # 13.Dropout层, Dropout(0.2) fif_dropout = Dropout(0.5) # 14.输出层,输出节点个数1, 激活函数'sigmoid' output_layer = Dense(1, activation='sigmoid') model = Sequential([conv_layer1, max_pool1, conv_layer2, max_pool2, conv_layer3, max_pool3, conv_layer4, max_pool4, flatten_layer, third_dropout, hidden_layer1, hidden_layer3, fif_dropout, output_layer])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
2.3 模型编译
模型的优化器是Adam,学习率是0.01,
损失函数是binary_crossentropy,二分类交叉熵,
性能指标是正确率accuracy,
另外还加入了回调机制。
回调机制简单理解为训练集的准确率持续上升,而验证集准确率基本不变,此时已经出现过拟合,应该调制学习率,让验证集的准确率也上升。
"2.模型编译"
# 模型编译,2分类:binary_crossentropy
model.compile(optimizer=Adam(lr=0.0001), # 优化器选择Adam,初始学习率设置为0.0001
loss='binary_crossentropy', # 代价函数选择 binary_crossentropy
metrics=['accuracy']) # 设置指标为准确率
model.summary() # 模型统计
# 回调机制 动态调整学习率
reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracy
patience=2, # 设置耐心容忍次数为2
verbose=1, #
factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少
min_lr=0.000001 # 学习率最小值0.000001
) # 监控val_accuracy增加趋势
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.4 数据生成器
加载自制数据集
利用数据生成器对数据进行数据加强,即每次训练时输入的图片会是原图片的翻转,平移,旋转,缩放,这样是为了降低过拟合的影响。
然后通过迭代器进行数据加载,目标图像大小统一尺寸1501503,设置每次加载到训练网络的图像数目,设置而分类模型(默认one-hot编码),并且数据打乱。
# 生成器对象1: 归一化 gen = ImageDataGenerator(rescale=1 / 255.0) # 生成器对象2: 归一化 + 数据加强 gen1 = ImageDataGenerator( rescale=1 / 255.0, rotation_range=5, # 图片随机旋转的角度5度 width_shift_range=0.1, height_shift_range=0.1, # 水平和竖直方向随机移动0.1 shear_range=0.1, # 剪切变换的程度0.1 zoom_range=0.1, # 随机放大的程度0.1 fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充 # 拼接训练和验证的两个路径 train_path = os.path.join(sys.path[0], 'imgs', 'train') val_path = os.path.join(sys.path[0], 'imgs', 'val') print('训练数据路径: ', train_path) print('验证数据路径: ', val_path) # 训练和验证的两个迭代器 train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径 target_size=(150, 150), # 目标图像大小统一尺寸150 batch_size=8, # 设置每次加载到内存的图像大小 class_mode='binary', # 设置分类模型(默认one-hot编码) shuffle=True) # 是否打乱 val_iter = gen.flow_from_directory(val_path, # 测试val目录路径 target_size=(150, 150), # 目标图像大小统一尺寸150 batch_size=8, # 设置每次加载到内存的图像大小 class_mode='binary', # 设置分类模型(默认one-hot编码) shuffle=True) # 是否打乱
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.5 模型训练
模型训练的次数是20,每1次循环进行测试
"3.模型训练"
# 模型的训练, model.fit
result = model.fit(train_iter, # 设置训练数据的迭代器
epochs=20, # 循环次数12次
validation_data=val_iter, # 验证数据的迭代器
callbacks=[reduce], # 回调机制设置为reduce
verbose=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.6 模型保存
以.h5文件格式保存模型
"4.模型保存"
# 保存训练好的模型
model.save('my_ikun.h5')
- 1
- 2
- 3
2.7 模型训练结果的可视化
对模型的训练结果进行可视化,可视化的结果用曲线图的形式展现
"5.模型训练时的可视化" # 显示训练集和验证集的acc和loss曲线 acc = result.history['accuracy'] # 获取模型训练中的accuracy val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy loss = result.history['loss'] # 获取模型训练中的loss val_loss = result.history['val_loss'] # 获取模型训练中的val_loss # 绘值acc曲线 plt.figure(1) plt.plot(acc, label='Training Accuracy') plt.plot(val_acc, label='Validation Accuracy') plt.title('Training and Validation Accuracy') plt.legend() plt.savefig('my_ikun_acc.png', dpi=600) # 绘制loss曲线 plt.figure(2) plt.plot(loss, label='Training Loss') plt.plot(val_loss, label='Validation Loss') plt.title('Training and Validation Loss') plt.legend() plt.savefig('my_ikun_loss.png', dpi=600) plt.show() # 将结果显示出来
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3. IKUN的CNN模型可视化结果图
Epoch 1/20 125/125 [==============================] - 30s 229ms/step - loss: 0.6012 - accuracy: 0.6450 - val_loss: 0.3728 - val_accuracy: 0.8200 - lr: 1.0000e-04 Epoch 2/20 125/125 [==============================] - 28s 223ms/step - loss: 0.3209 - accuracy: 0.8710 - val_loss: 0.3090 - val_accuracy: 0.8900 - lr: 1.0000e-04 Epoch 3/20 125/125 [==============================] - 34s 270ms/step - loss: 0.2564 - accuracy: 0.8990 - val_loss: 0.4873 - val_accuracy: 0.8075 - lr: 1.0000e-04 Epoch 4/20 125/125 [==============================] - ETA: 0s - loss: 0.2546 - accuracy: 0.9050 Epoch 4: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-05. 125/125 [==============================] - 34s 275ms/step - loss: 0.2546 - accuracy: 0.9050 - val_loss: 0.3298 - val_accuracy: 0.8875 - lr: 1.0000e-04 Epoch 5/20 125/125 [==============================] - 31s 246ms/step - loss: 0.1867 - accuracy: 0.9310 - val_loss: 0.3577 - val_accuracy: 0.8500 - lr: 5.0000e-05 Epoch 6/20 125/125 [==============================] - 31s 245ms/step - loss: 0.1805 - accuracy: 0.9260 - val_loss: 0.2816 - val_accuracy: 0.8975 - lr: 5.0000e-05 Epoch 7/20 125/125 [==============================] - 30s 238ms/step - loss: 0.1689 - accuracy: 0.9340 - val_loss: 0.2679 - val_accuracy: 0.9100 - lr: 5.0000e-05 Epoch 8/20 125/125 [==============================] - 30s 237ms/step - loss: 0.2230 - accuracy: 0.9200 - val_loss: 0.2561 - val_accuracy: 0.9075 - lr: 5.0000e-05 Epoch 9/20 125/125 [==============================] - ETA: 0s - loss: 0.1542 - accuracy: 0.9480 Epoch 9: ReduceLROnPlateau reducing learning rate to 2.499999936844688e-05. 125/125 [==============================] - 30s 238ms/step - loss: 0.1542 - accuracy: 0.9480 - val_loss: 0.2527 - val_accuracy: 0.9100 - lr: 5.0000e-05 Epoch 10/20 125/125 [==============================] - 30s 239ms/step - loss: 0.1537 - accuracy: 0.9450 - val_loss: 0.2685 - val_accuracy: 0.9125 - lr: 2.5000e-05 Epoch 11/20 125/125 [==============================] - 33s 263ms/step - loss: 0.1395 - accuracy: 0.9540 - val_loss: 0.2703 - val_accuracy: 0.9100 - lr: 2.5000e-05 Epoch 12/20 125/125 [==============================] - ETA: 0s - loss: 0.1331 - accuracy: 0.9560 Epoch 12: ReduceLROnPlateau reducing learning rate to 1.249999968422344e-05. 125/125 [==============================] - 31s 250ms/step - loss: 0.1331 - accuracy: 0.9560 - val_loss: 0.2739 - val_accuracy: 0.9025 - lr: 2.5000e-05 Epoch 13/20 125/125 [==============================] - 31s 245ms/step - loss: 0.1374 - accuracy: 0.9500 - val_loss: 0.2551 - val_accuracy: 0.9250 - lr: 1.2500e-05 Epoch 14/20 125/125 [==============================] - 32s 254ms/step - loss: 0.1261 - accuracy: 0.9590 - val_loss: 0.2705 - val_accuracy: 0.9050 - lr: 1.2500e-05 Epoch 15/20 125/125 [==============================] - ETA: 0s - loss: 0.1256 - accuracy: 0.9620 Epoch 15: ReduceLROnPlateau reducing learning rate to 6.24999984211172e-06. 125/125 [==============================] - 31s 248ms/step - loss: 0.1256 - accuracy: 0.9620 - val_loss: 0.2449 - val_accuracy: 0.9125 - lr: 1.2500e-05 Epoch 16/20 125/125 [==============================] - 31s 245ms/step - loss: 0.1182 - accuracy: 0.9610 - val_loss: 0.2460 - val_accuracy: 0.9225 - lr: 6.2500e-06 Epoch 17/20 125/125 [==============================] - ETA: 0s - loss: 0.1261 - accuracy: 0.9610 Epoch 17: ReduceLROnPlateau reducing learning rate to 3.12499992105586e-06. 125/125 [==============================] - 30s 243ms/step - loss: 0.1261 - accuracy: 0.9610 - val_loss: 0.2466 - val_accuracy: 0.9250 - lr: 6.2500e-06 Epoch 18/20 125/125 [==============================] - 30s 240ms/step - loss: 0.1098 - accuracy: 0.9630 - val_loss: 0.2544 - val_accuracy: 0.9125 - lr: 3.1250e-06 Epoch 19/20 125/125 [==============================] - ETA: 0s - loss: 0.1165 - accuracy: 0.9630 Epoch 19: ReduceLROnPlateau reducing learning rate to 1.56249996052793e-06. 125/125 [==============================] - 31s 246ms/step - loss: 0.1165 - accuracy: 0.9630 - val_loss: 0.2476 - val_accuracy: 0.9225 - lr: 3.1250e-06 Epoch 20/20 125/125 [==============================] - 35s 281ms/step - loss: 0.1214 - accuracy: 0.9570 - val_loss: 0.2503 - val_accuracy: 0.9225 - lr: 1.5625e-06
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
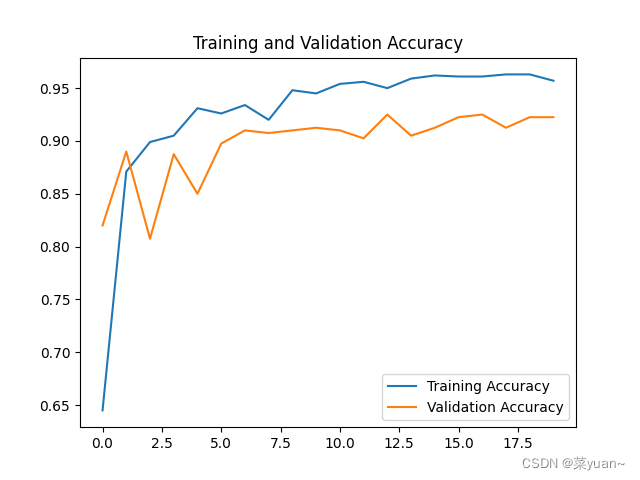
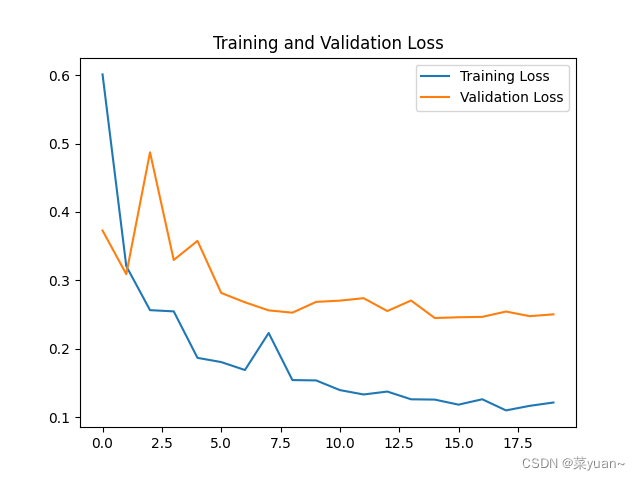
从以上结果可知,模型的准确率达到了92%,准确率还是很高的。
4. 完整代码
from keras.models import Sequential from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D from keras.optimizers import RMSprop, Adam from keras.preprocessing.image import ImageDataGenerator import sys, os # 目录结构 import matplotlib.pyplot as plt from keras.callbacks import EarlyStopping, ReduceLROnPlateau "1.模型建立" # 1.卷积层,输入图片大小(150, 150, 3), 卷积核个数16,卷积核大小(5, 5), 激活函数'relu' conv_layer1 = Conv2D(input_shape=(150, 150, 3), filters=16, kernel_size=(5, 5), activation='relu') # 2.最大池化层,池化层大小(2, 2), 步长为2 max_pool1 = MaxPool2D(pool_size=(2, 2), strides=2) # 3.卷积层,卷积核个数32,卷积核大小(5, 5), 激活函数'relu' conv_layer2 = Conv2D(filters=32, kernel_size=(5, 5), activation='relu') # 4.最大池化层,池化层大小(2, 2), 步长为2 max_pool2 = MaxPool2D(pool_size=(2, 2), strides=2) # 5.卷积层,卷积核个数64,卷积核大小(5, 5), 激活函数'relu' conv_layer3 = Conv2D(filters=64, kernel_size=(5, 5), activation='relu') # 6.最大池化层,池化层大小(2, 2), 步长为2 max_pool3 = MaxPool2D(pool_size=(2, 2), strides=2) # 7.卷积层,卷积核个数128,卷积核大小(5, 5), 激活函数'relu' conv_layer4 = Conv2D(filters=128, kernel_size=(5, 5), activation='relu') # 8.最大池化层,池化层大小(2, 2), 步长为2 max_pool4 = MaxPool2D(pool_size=(2, 2), strides=2) # 9.展平层 flatten_layer = Flatten() # 10.Dropout层, Dropout(0.2) third_dropout = Dropout(0.2) # 11.全连接层/隐藏层1,240个节点, 激活函数'relu' hidden_layer1 = Dense(240, activation='relu') # 12.全连接层/隐藏层2,84个节点, 激活函数'relu' hidden_layer3 = Dense(84, activation='relu') # 13.Dropout层, Dropout(0.2) fif_dropout = Dropout(0.5) # 14.输出层,输出节点个数1, 激活函数'sigmoid' output_layer = Dense(1, activation='sigmoid') model = Sequential([conv_layer1, max_pool1, conv_layer2, max_pool2, conv_layer3, max_pool3, conv_layer4, max_pool4, flatten_layer, third_dropout, hidden_layer1, hidden_layer3, fif_dropout, output_layer]) "2.模型编译" # 模型编译,2分类:binary_crossentropy model.compile(optimizer=Adam(lr=0.0001), # 优化器选择Adam,初始学习率设置为0.0001 loss='binary_crossentropy', # 代价函数选择 binary_crossentropy metrics=['accuracy']) # 设置指标为准确率 model.summary() # 模型统计 # 回调机制 动态调整学习率 reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracy patience=2, # 设置耐心容忍次数为2 verbose=1, # factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少 min_lr=0.000001 # 学习率最小值0.000001 ) # 监控val_accuracy增加趋势 # 生成器对象1: 归一化 gen = ImageDataGenerator(rescale=1 / 255.0) # 生成器对象2: 归一化 + 数据加强 gen1 = ImageDataGenerator( rescale=1 / 255.0, rotation_range=5, # 图片随机旋转的角度5度 width_shift_range=0.1, height_shift_range=0.1, # 水平和竖直方向随机移动0.1 shear_range=0.1, # 剪切变换的程度0.1 zoom_range=0.1, # 随机放大的程度0.1 fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充 # 拼接训练和验证的两个路径 train_path = os.path.join(sys.path[0], 'imgs', 'train') val_path = os.path.join(sys.path[0], 'imgs', 'val') print('训练数据路径: ', train_path) print('验证数据路径: ', val_path) # 训练和验证的两个迭代器 train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径 target_size=(150, 150), # 目标图像大小统一尺寸150 batch_size=8, # 设置每次加载到内存的图像大小 class_mode='binary', # 设置分类模型(默认one-hot编码) shuffle=True) # 是否打乱 val_iter = gen.flow_from_directory(val_path, # 测试val目录路径 target_size=(150, 150), # 目标图像大小统一尺寸150 batch_size=8, # 设置每次加载到内存的图像大小 class_mode='binary', # 设置分类模型(默认one-hot编码) shuffle=True) # 是否打乱 "3.模型训练" # 模型的训练, model.fit result = model.fit(train_iter, # 设置训练数据的迭代器 epochs=20, # 循环次数12次 validation_data=val_iter, # 验证数据的迭代器 callbacks=[reduce], # 回调机制设置为reduce verbose=1) "4.模型保存" # 保存训练好的模型 model.save('my_ikun.h5') "5.模型训练时的可视化" # 显示训练集和验证集的acc和loss曲线 acc = result.history['accuracy'] # 获取模型训练中的accuracy val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy loss = result.history['loss'] # 获取模型训练中的loss val_loss = result.history['val_loss'] # 获取模型训练中的val_loss # 绘值acc曲线 plt.figure(1) plt.plot(acc, label='Training Accuracy') plt.plot(val_acc, label='Validation Accuracy') plt.title('Training and Validation Accuracy') plt.legend() plt.savefig('my_ikun_acc.png', dpi=600) # 绘制loss曲线 plt.figure(2) plt.plot(loss, label='Training Loss') plt.plot(val_loss, label='Validation Loss') plt.title('Training and Validation Loss') plt.legend() plt.savefig('my_ikun_loss.png', dpi=600) plt.show() # 将结果显示出来
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

