
- 1数码管的静态显示(二)
- 2珠穆朗玛峰_用c#求一张纸折多少次和珠穆朗玛峰一样高
- 3LLMs之LLaMA-2:源码解读之所有py文件(包括example_text_completion.py/example_chat_completion.py+model.py/generation_llama 2 源码分析
- 4网站如何配置CDN加速?网站域名接入腾讯云CDN的步骤(附CDN防御)_天翼云 cnd 加速,配置到 腾讯云服务器
- 5Mybatis-plus尚硅谷跟学课堂笔记_尚硅谷杨博超
- 6竞赛 LSTM的预测算法 - 股票预测 天气预测 房价预测
- 7mysql(多级分销)无限极数据库设计方法_多级分销表设计 闭包表
- 8关于一些uniapp白屏debugger思路_前端debugger调试出现空白
- 9PyQt5学习笔记9_使用setStyle和setStyleSheet进行换肤_pyqt5 setstylesheet
- 10四维彩超宝宝长相预测软件有哪些?这三款助你开启新生命之窗_四维彩超预测宝宝长相app
Golang 中的 slice 详解_golang slice
赞
踩
一、数组和切片(slice)的区别
1、go 中的数组
数组是存放在连续内存空间上的相同类型数据的集合。查询简单,增加和删除困难。
数组可以通过下标快速访问数组元素。但是因为数组在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。数组的元素是不能删的,只能覆盖。
举一个字符数组的例子,如图所示:
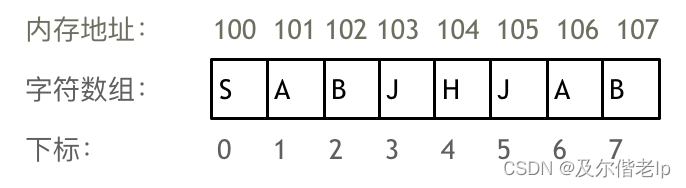
需要两点注意的是:
- 数组下标都是从0开始的。
- 数组内存空间的地址是连续的。
例如删除下标为3的元素,需要对下标为3的元素后面的所有元素做移动操作,如图所示:

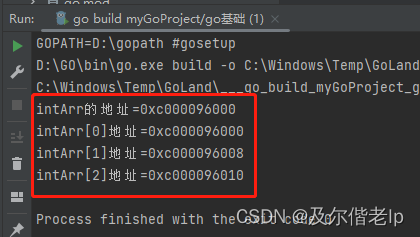
func main() {
// 数组的地址可以通过数组名来获取
// 数组的第一个元素的地址就是数组的地址
// 数组的各个元素的间隔是依据数组的类型决定的,比如int64间隔8个,int32间隔4个
// 输出的地址是16进制
intArr := [3]int{1, 2, 3}
fmt.Printf("intArr的地址=%p\n", &intArr)
fmt.Printf("intArr[0]地址=%p\n", &intArr[0])
fmt.Printf("intArr[1]地址=%p\n", &intArr[1])
fmt.Printf("intArr[2]地址=%p\n", &intArr[2])
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
二维数组
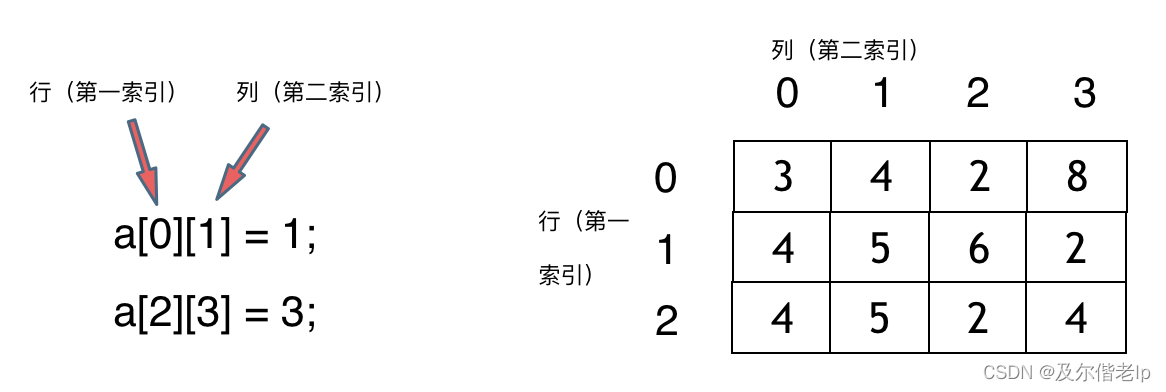
那么二维数组在内存的空间地址是连续的么?
func twoArray() {
intArr := [2][3]int{{1, 2, 3}, {4, 5, 6}}
fmt.Printf("intArr的地址=%p\n", &intArr)
fmt.Printf("intArr[0]地址=%p\n", &intArr[0])
fmt.Printf("intArr[0][0]地址=%p\n", &intArr[0][0])
fmt.Printf("intArr[0][1]地址=%p\n", &intArr[0][1])
fmt.Printf("intArr[0][2]地址=%p\n", &intArr[0][2])
fmt.Printf("intArr[1]地址=%p\n", &intArr[1])
fmt.Printf("intArr[1][0]地址=%p\n", &intArr[1][0])
fmt.Printf("intArr[1][1]地址=%p\n", &intArr[1][1])
fmt.Printf("intArr[1][2]地址=%p\n", &intArr[1][2])
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
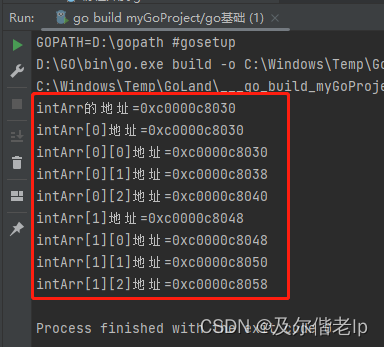
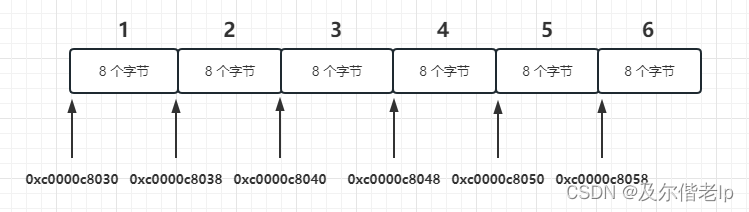
注意地址为16进制,可以看出二维数组在内存的空间地址是连续的。
简单介绍一下内存地址, 0xc0000c8030 与 0xc0000c8038 相差 8,就是 8 个字节,因为这是一个 int 型的数组(64位系统默认是 int64),所以两个相邻数组元素地址差 8 个字节。0xc0000c8038 与 0xc0000c8040 也是差了 8 个字节,在16进制里 8 + 8 = 0 ,0 就是16。
2、go 中的切片(slice)
Go语言中,数组在传递的时候,传递的是原数组的拷贝,对大数组来说,内存代价会非常大,影响性能。
传递数组指针可以解决这个问题,但是数组指针也有一个弊端:原数组的指针指向改变了,那函数里面的指针指向也会跟着改变,某些情况下,可能会产生意想不到的bug。slice的出现,便是为了解决这个问题。
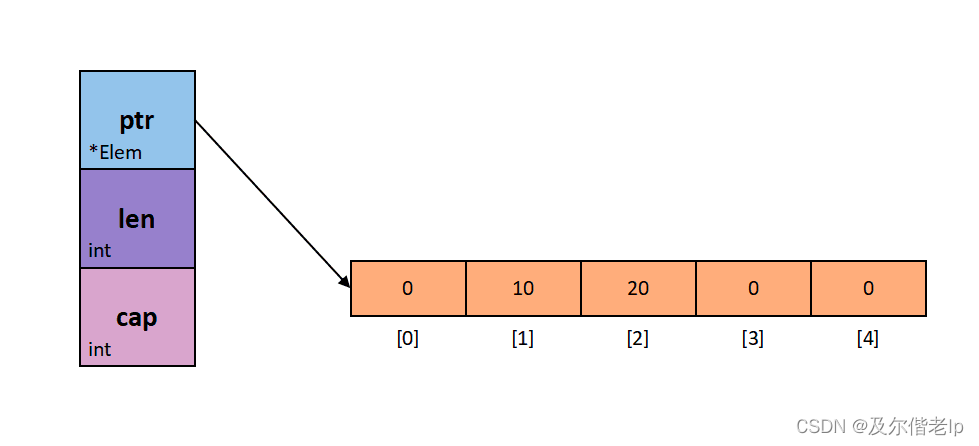
上图中,ptr 是指向底层数组的指针,len 是指slice 的长度,cap 是指 slice 的容量。
slice 是对数组的封装,是对数组中一个连续片段的引用,是一个引用类型。slice 本身并不是动态数组或者数组指针,它的内部实现是通过指针引用底层数组,设置相关的属性,将数据的读写操作限定在指定的区域内,修改的是底层数组,而不是slice本身。
3、数组和切片的区别
- 相同点:
(1)都是只能存储一组相同类型的数据结构;
(2)下标都是从0开始的,可以通过下标来访问单个元素;
(3)有容量、长度,长度通过 len 获取,容量通过 cap 获取。
- 不同点:
(1)数组是定长的,长度定义好之后,不能再更改,长度是类型的一部分,访问和复制不能超过数组定义的长度,否则就会下标越界。切片长度和容量可以自动扩容,切片的类型和长度无关。
在 Go 中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 [3]int 和 [4]int 就是不同的类型。
(2)数组是值类型,切片是引用类型,每个切片都引用了一个底层数组,切片本身不能存储任何数据,都是底层数组存储数据,修改切片的时候修改的是底层数组中的数据,切片一旦扩容,会指向一个新的底层数组,内存地址也就随之改变。
二、切片(slice)的底层实现
源码位于 src\runtime\slice.go 中。
golang 中 slice 实际上是一个结构体,包含三个字段:长度、容量、底层数组。
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 长度
cap int // 容量
}
- 1
- 2
- 3
- 4
- 5
注意,底层数组是可以被多个 slice 同时指向的,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
看个经典的例子:
package main
import "fmt"
func main() {
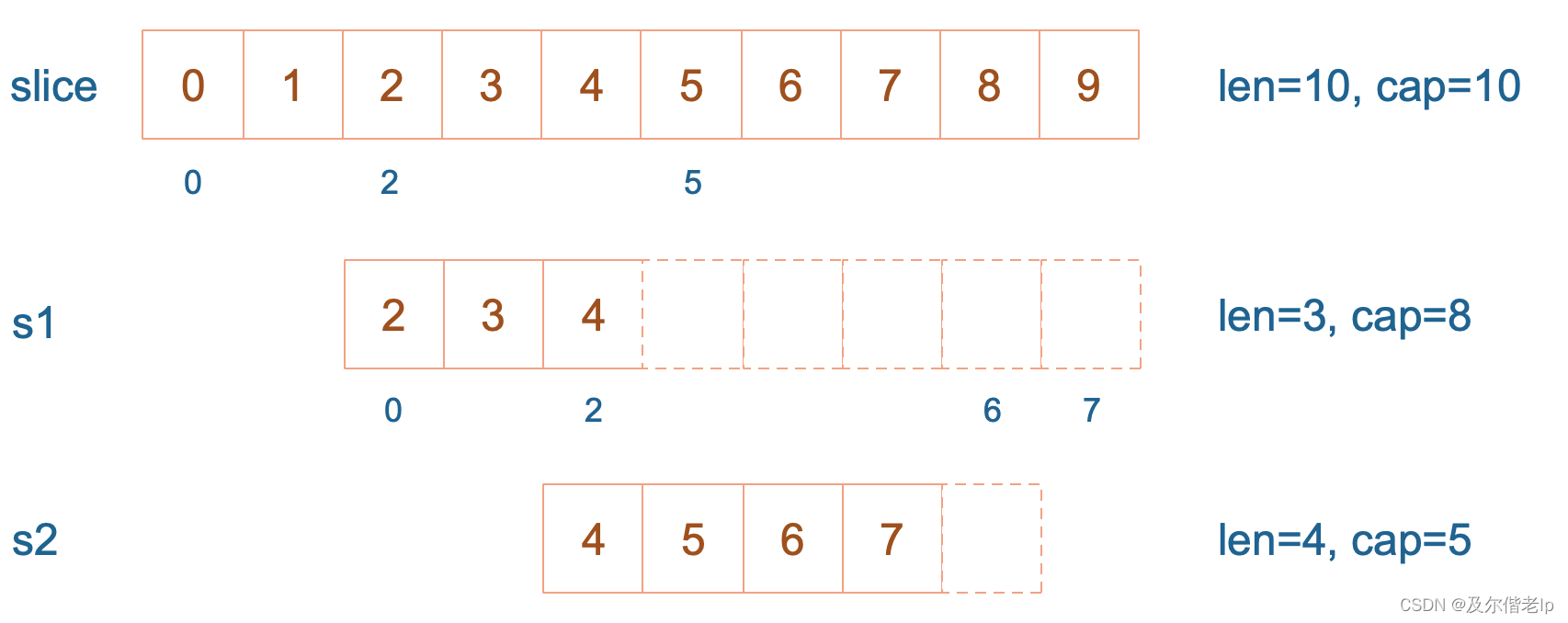
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
fmt.Println(s1) // [2 3 4]
s2 := s1[2:6:7] // 长度 2:6,容量 2:7
fmt.Println(s2) // [4 5 6 7]
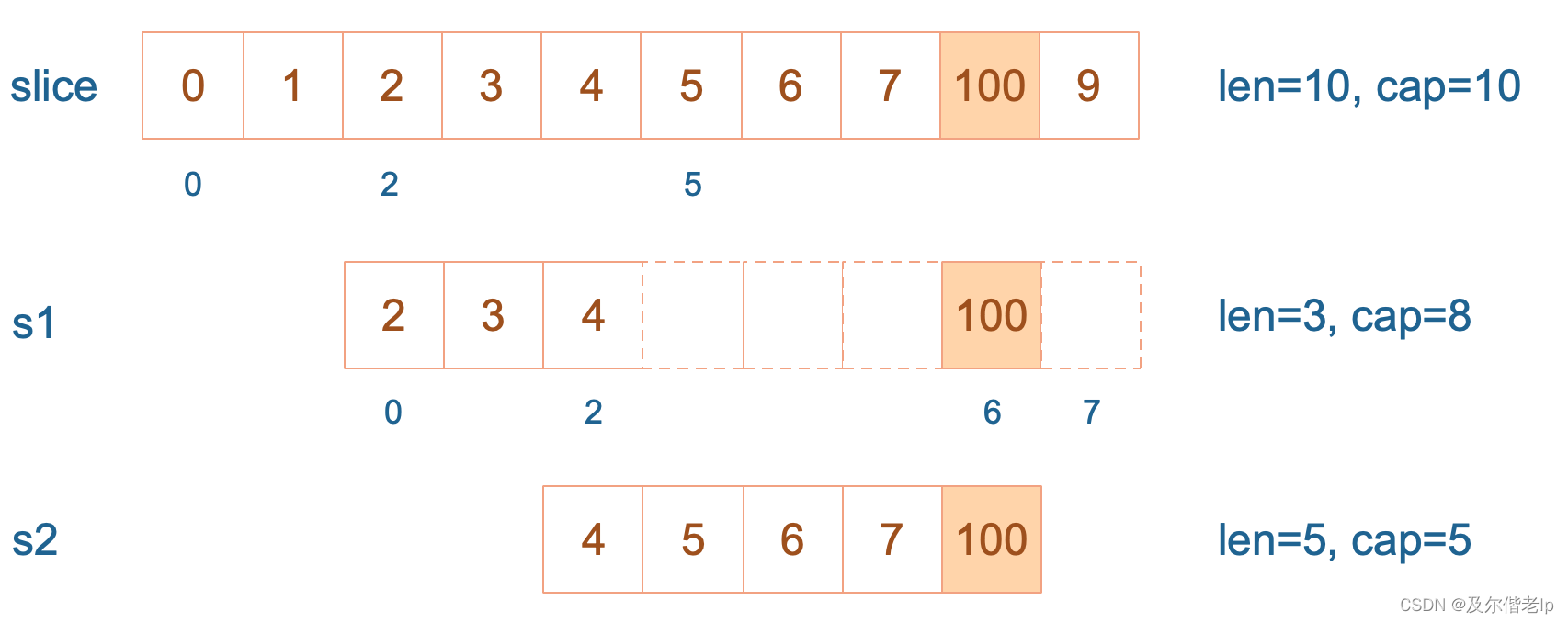
s2 = append(s2, 100)
s2 = append(s2, 200)
s1[2] = 20
fmt.Println(s1) // [2 3 20]
fmt.Println(s2) // [4 5 6 7 100 200]
fmt.Println(slice) // [0 1 2 3 20 5 6 7 100 9]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
s1 从 slice 索引2(闭区间)到索引5(开区间,元素真正取到索引4),长度为3,容量默认到数组结尾,为8。s2 从 s1 的索引2(闭区间)到索引6(开区间,元素真正取到索引5),容量到索引7(开区间,真正到索引6),为5。
接着,向 s2 尾部追加一个元素 100,s2 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 s1 都可以看得到。
再次向 s2 追加元素200,这时,s2 的容量不够用,该扩容了。于是,s2 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 append 带来的再一次扩容,s2 会在此次扩容的时候多留一些 buffer,将新的容量将扩大为原始容量的2倍,也就是10了。这一改动,不会影响数组和 s1 。
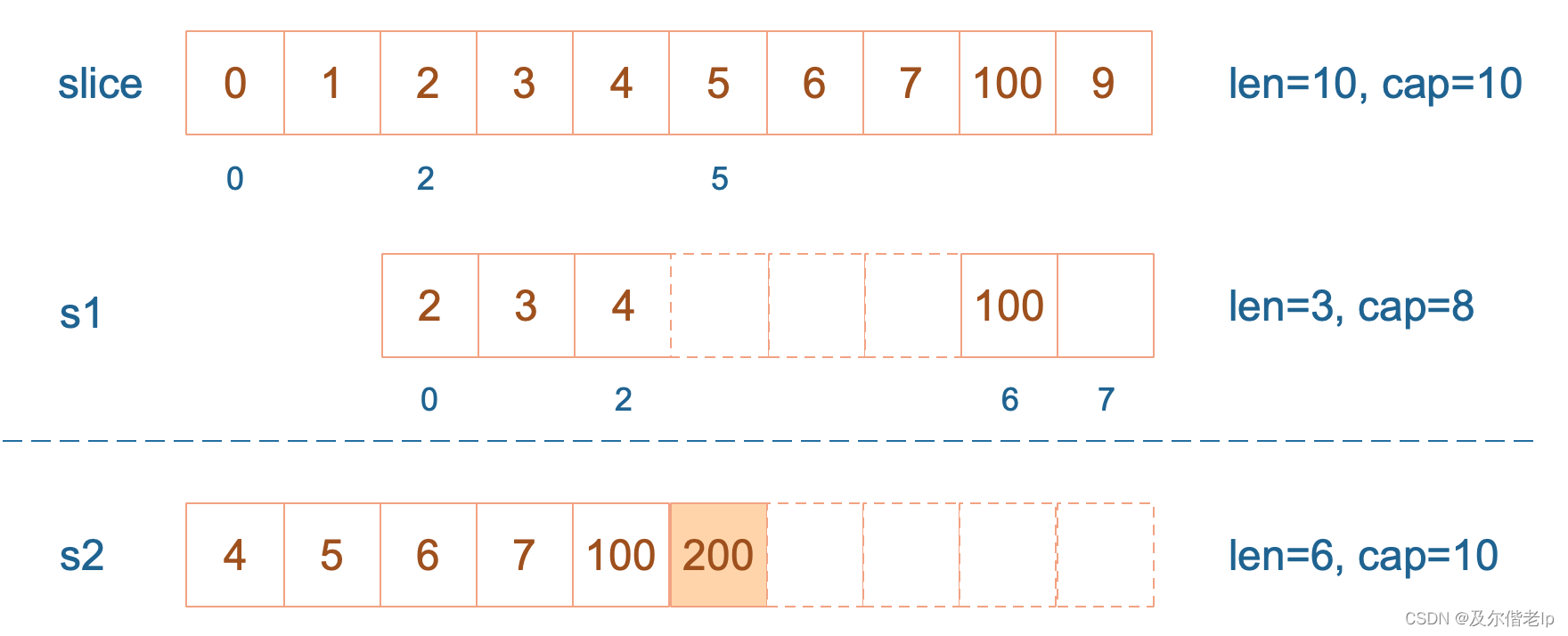
最后,修改 s1 索引为2位置的元素,这次只会影响原始数组相应位置的元素,它影响不到 s2 了,人家已经远走高飞了。
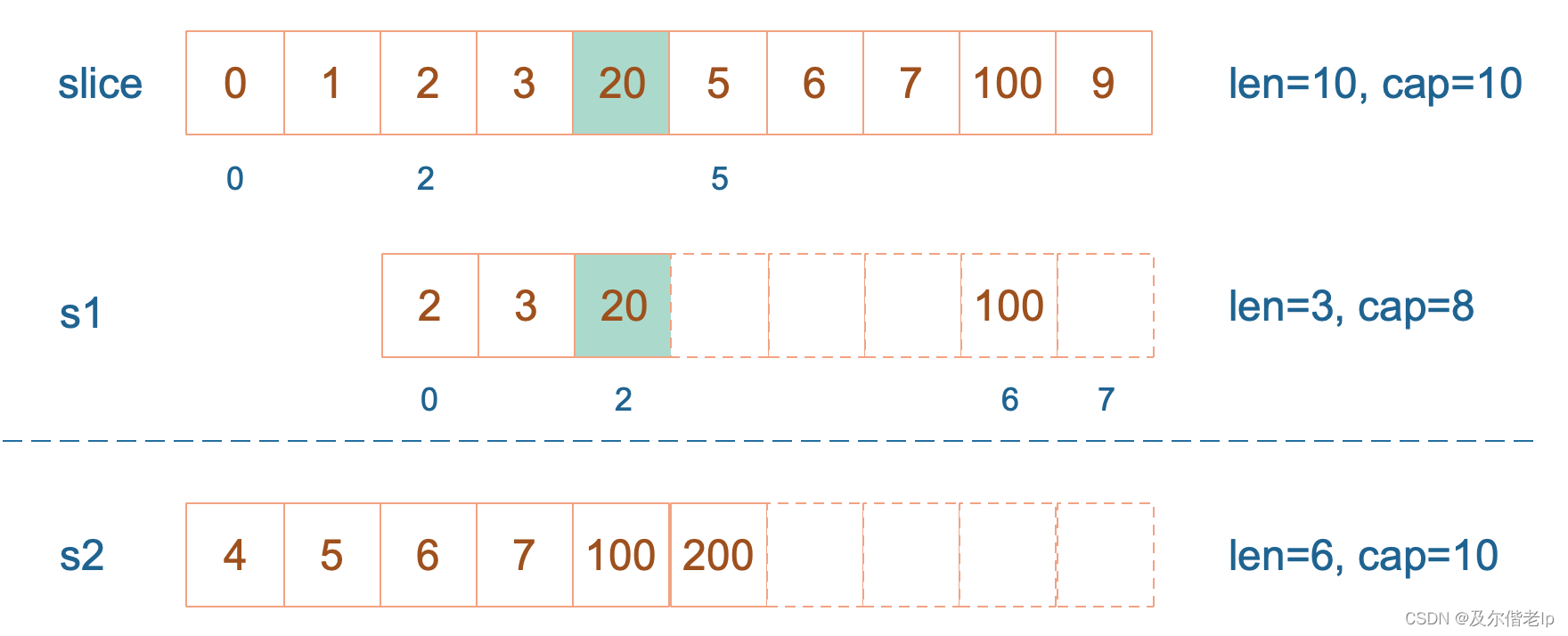
再提一点,打印 s1 的时候,只会打印出 s1 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。
当 slice 作为函数参数时,是值传递,函数内部对 slice 的作用并不会改变外层的 slice ,要想真的改变外层 slice,只有将返回的新的 slice 赋值到原始 slice,或者向函数传递一个指向 slice 的指针。slice 结构体自身不会被改变,指针指向的底层数组的地址也不会被改变,改变的是数组中的数据。
package main func main() { s := []int{1, 1, 1} f(s) fmt.Println(s) // [2 2 2] } func f(s []int) { // i只是一个副本,不能改变s中元素的值 /*for _, i := range s { i++ } */ for i := range s { s[i] += 1 } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
三、切片(slice)的扩容
slice可以理解为动态数组,既然是动态数组,那必然需要进行扩容。
1、触发扩容的时机
向 slice 追加元素,如果底层数组的容量不够(即便底层数组并未填满),就会触发扩容。追加元素调用的是 append 函数。
2、扩容规则
Go <= 1.17
1、首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
2、否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的 2 倍。
3、否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)就是旧容量(old.cap)按照 1.25 倍循环递增,也就是每次加上 cap / 4。
4、如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
Go1.18之后
引入了新的扩容规则,首先 1024 的边界不复存在,取而代之的常量是 256 。超出256的情况,也不是直接扩容25%,而是设计了一个平滑过渡的计算方法,随着容量增大,扩容比例逐渐从100%平滑降低到25%,从 2 倍平滑过渡到 1.25 倍。
为什么要这样设计?
避免追加过程中频繁扩容,减少内存分配和数据复制开销,有助于性能提升。
3、内存对齐
计算出了新容量之后,还没有完,出于内存的高效利用考虑,还要进行内存对齐。进行内存对齐之后,新 slice 的容量是要 大于等于 老 slice 容量的 2倍或者1.25倍。
4、完整过程
向 slice 追加元素的时候,若容量不够,会触发扩容,会调用 growslice() 函数。首先,根据扩容规则,计算出新的容量,然后进行内存对齐,之后,向 Go 内存管理器申请内存,将老 slice 中的数据整个复制过去,并且将追加的元素添加到新的底层数组中。
四、切片(slice)的拷贝
1、浅拷贝
浅拷贝,拷贝的是地址,浅拷贝只复制了指向底层数据结构的指针,而不是复制整个底层数据结构,修改修改新对象的值会影响原对象值。对于引用类型,如切片和字典等都是浅拷贝。
slice2 := slice1
arr := []int{1, 2, 3}
copyArr := arr // 浅拷贝
copyArr[0] = 100 // 修改变量
fmt.Println(arr) // [100 2 3],原始变量的值也随之改变
- 1
- 2
- 3
- 4
- 5
- 6
slice1和slice2指向的都是同一个底层数组,任何一个数组元素被改变,都可能会影响两个slice。在slice触发扩容操作前,slice1和slice2指向的都是相同数组,但在触发扩容操作后,二者指向的就不一定是相同的底层数组了。
在Go中,切片和字典类型默认都是以引用方式传递,所以默认情况下进行的是浅拷贝,如果需要进行深拷贝,则需要自己实现。对于值类型(如基本数据类型和结构体),都是以值拷贝的方式进行的,即进行深拷贝。
2、深拷贝
深拷贝,拷贝的是数据本身,完全复制了底层数据结构,而不是复制指向底层数据结构的指针,会创建一个新对象,新对象和原对象不共享内存,它们是完全独立的,修改新对象的值不会影响原对象值,内存地址不同,释放内存地址时,可以分别释放。
copy(slice2, slice1) src := []int{1, 2, 3, 4, 5} dst := make([]int, len(src), cap(src)) copy(dst, src) // 深拷贝 dst[0] = 100 // 修改变量 fmt.Println(src) // [1 2 3 4 5] fmt.Println(dst) // [100 2 3 4 5] short := make([]int, 3, 3) copy(short, src) // 深拷贝 fmt.Println(short) // [1 2 3] long := make([]int, 10, 10) copy(long, src) // 深拷贝 fmt.Println(long) // [1 2 3 4 5 0 0 0 0 0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
把 slice1 的数据复制到 slice2 中,修改 slice2 的数据,不会影响到 slice1 。如果 slice2 的长度和容量小于 slice1 的,那么只会复制 slice2 长度的数据。

