
热门标签
热门文章
- 1智能视频分析平台:食堂安全的守护者
- 2k8s部署之kubesphere安装与生产配置使用教程(问题整合,持续更新)
- 3CentOS网络配置_ifcfg-eno1
- 4ChatGLM2-6B从本地加载模型报错-解决办法_does not appear to have a file named config.json
- 5一文彻底玩转Android通知栏消息通知_android 通知栏消息
- 6nginx目录搜索_nginx 搜索拖到这里
- 7一分钟修改好Linux中root密码_putty修改root@中root名称
- 8HCIA-RS知识梳理(下)_vlan tci tpid
- 9Vuex的理解和应用
- 10Docker本地部署Rss订阅工具并实现公网远程访问_docker-hub-rss
当前位置: article > 正文
Python使用pandas读取excel表格数据_python pd读取excel
作者:花生_TL007 | 2024-03-08 11:00:10
赞
踩
python pd读取excel
导入
import pandas as pd
- 1
若使用的是Anaconda集成包则可直接使用,否则可能需要下载:pip install pandas
读取表格并得到表格行列信息
df=pd.read_excel('test.xlsx')
height,width = df.shape
print(height,width,type(df))
- 1
- 2
- 3
表格如下:
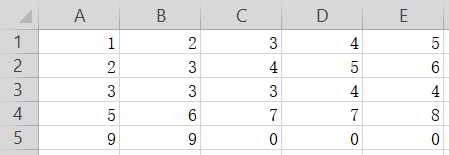
得到如下输出,为一个4行5列的数据块,为DataFrame格式:

直接print(df)得到的结果:
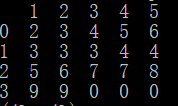
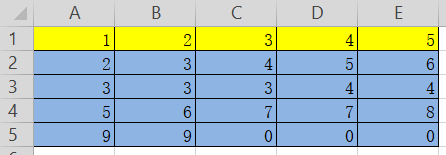
对比结果和表格,很显然表格中的第一行(黄色高亮部分)被定义为数据块的列下标,而实际视作数据的是后四行(蓝色高亮部分);并且自动在表格第一列之前加了一个行索引{0,1,2,3}。
提取数据放入数组中
x = np.zeros((height,width))
for i in range(0,height):
for j in range(1,width+1): #遍历的实际下标,即excel第一行
x[i][j-1] = df.ix[i,j]
print(x.shape)
print(x)
- 1
- 2
- 3
- 4
- 5
- 6
用np.zeros()方法定义一个初试值全为0的二维数组(需要导入numpy库),用df.ix[i,j]读取数据并复制入二维数组中,其中for i in range(0,height)循环表示从下标0到下标height-1(不包含height),得到的输出如下:

对代码做一些补充说明:
从DataFrame结构的数据中取值有三种常用的方法:
#第一种方法:ix
df.ix[i,j] # 这里面的i,j为内置数字索引,行列均从0开始计数
df.ix[row,col] # 这里面的row和col为表格行列索引,也就是表格中的行与列名称
#第二种方法:loc
df.loc[row,col] # loc只支持使用表格行列索引,不能用内置数字索引
#第三种方法:iloc
df.iloc[i,j] # iloc只支持使用内置数字索引,不能用表格行列索引
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
由于ix方法对两种索引都支持,所以这里就有一个问题:如果表格行列索引也是数字怎么办? 比如我上述例子中列索引为表格的第一行{1,2,3,4},而行索引为读取时自动添加的。
经过实验这种情况将会优先使用表格行列索引,也就对应了上面代码中得到的结果。不过为了不在使用时产生混乱,我个人建议还是使用loc或者iloc而不是ix为好。
在表格中自定义行列索引的情况
如果表格是下面这样的形式:
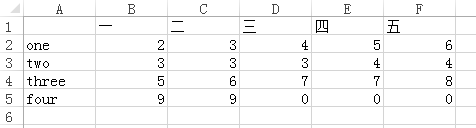
想要让读取得到的DataFrame行索引为{‘one’,‘two’,‘three’,‘four’},列索引为{‘一’,‘二’,‘三’,‘四’,‘五’}。如果直接使用read_excel(filename),虽然列索引会默认为第一行,但是行索引并不会默认为第一列,而是会自动添加一个{0,1,2,3}作为行索引。因此需要达到我们的目的需要设定一下读取时的参数,如下:
df = pd.read_excel(filename,index_col=0) # 即指定第一列为行索引
print(df)
print('第0行第1列的数据为:',df.iloc[0,1])
print('第three行第二列的数据为:',df.loc['three','二'])
- 1
- 2
- 3
- 4
得到的输出如下所示:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/209628?site
推荐阅读
相关标签

