
现代异步存储访问API探索:libaio、io_uring和SPDK_libaio多线程
赞
踩
【摘要】
最近的高性能存储设备暴露了现有软件栈的低效,因而催生了对I/O栈的改进。Linux内核的最新API是io_uring。作者提供了第一个针对io_uring的深度研究,并且和libaio、SPDK比较,探讨它的下性能和优缺点。根据作者的发现,(1)轮询能极大影响性能(2)只要CPU核足够多,io_uring可以提供和SPKD接近的性能(3)在多核CPU和多设备场景下扩展需要仔细的考虑并且需要一个混合方案。最后,作者为存储密集的应用开发者提供了设计指导。
【三种API简介】
1、libaio
传统的同步I/O接口包括read()、write()、pread()、pwrite()等,线程开始I/O操作后立刻进入阻塞状态,直到I/O请求完成。而使用异步I/O接口,如aio,线程把I/O请求发送给内核后可以继续做其他工作,直到内核把I/O请求完成的信号发送给线程。通常,异步I/O接口效率更高,其中的核心系统调用是io_submit(用于提交I/O请求)和io_getevents(用于获得完成的I/O请求)。然而,在每个I/O操作中,libaio要依赖两个系统调用,而且使用中断的方式通知I/O请求的完成,这导致libaio的单个I/O性能并不好,如下图。

2、SPDK
SPDK是Linux的高性能API。它在用户空间映射了PCIe寄存器以配置CQ和SQ,用户通过轮询CQ来捕获I/O请求的完成,而不需要中断和系统调用。SPDK的缺点是它很复杂,而且相对于libaio适用范围很窄。SPDK不支持文件系统,也无法利用内核存储服务,如访问控制、调度、QoS和配额管理。
3、io_uring
io_uring中和了上述两类API的优缺点。它在用户空间实现了两个环形数据结构,同时内核可以访问它们,类似于NVMe的CQ和SQ,submission ring存储了用户提交的I/O请求,completion存储了I/O请求的完成结果。用户可以不通过系统调用插入和检索两个环。
io_uring提供的I/O机制有三种,如下图:
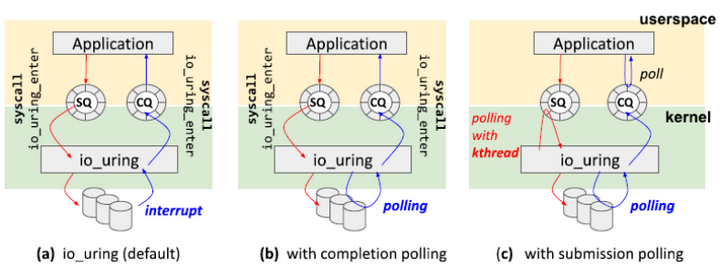
默认模式下,用户可以通过io_uring_enter系统调用通知内核新请求已经提交到SQ中。用户使用同一个io_uring_enter系统调用等待I/O请求完成。io_uring_enter支持中断模式(a)和轮询模式(b)。当然,因为用户也可以访问CQ,所以用户可以自己轮询CQ等待I/O请求完成,而不使用任何系统调用。并且,io_uring也可以使用一个内核线程轮询SQ,这样在整个I/O操作中不会使用任何系统调用(c)。
相关视频推荐
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

【性能测试分析】
实验使用fio生成4KB随机读负载,不使用page cache。纯读负载能达到更高的IOPS,而高IOPS有助于分析不同API的可扩展性趋势和每个I/O操作的开销。除了io_uring外,其他API均使用默认配置。io_uring的配置如下:
(1)iou:上图(a)的配置(默认的fio参数)
(2)iou+p:上图(b)的配置(fio参数是hipri)
(3)iou+k:不使用系统调用,即使用内核线程轮询I/O的提交,同时应用轮询I/O的完成(fio的参数是sqthread_poll)
环境配置如下表:

P.S. 虽然io_uring里提供了io_uring_enter作为提交I/O请求和捕获完成的I/O请求的统一接口,但FIO里面还是分开使用了(即调用了两次io_uring_enter)。
1、理解轮询
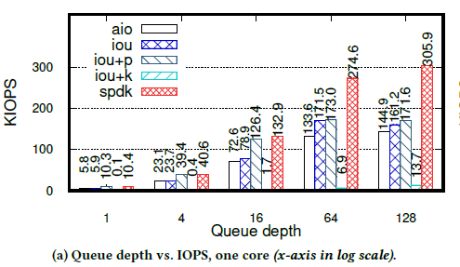
作者使用单个fio job、单个NVMe驱动和单个CPU,在不同队列深度下,测试三种API(libaio、io_uring和SPDK)的KIOPS,如下图:
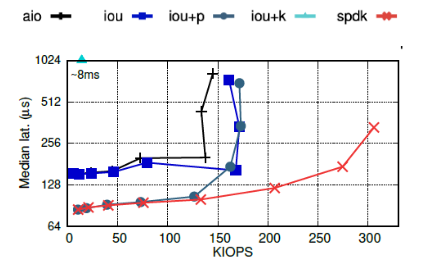
每个IOPS下对应的延迟中位数如下图:
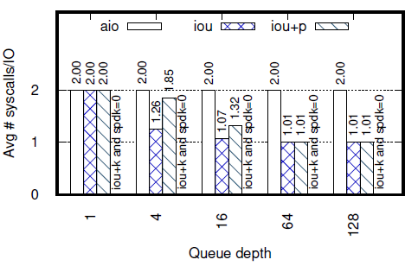
平均每个I/O操作进行的系统调用个数如下图:
① 可知,iou+k的KIOPS仅仅13,比其他API少一个数量级。因为此时fio线程和内核轮询线程共享一个CPU,减少了FIO每秒处理的I/O请求的数量。同时,iou+k的延迟是8ms,比其他API慢1~2个数量级。iou+k的延迟不随KIOPS的变化而变化,因为此时的延迟取决于CPU资源的竞争,而非排队等待。
当CPU数量增加到2时,iou+k的性能完全恢复了,如下图:
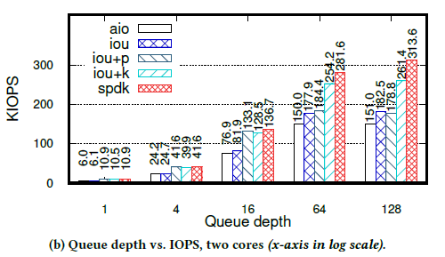
每个KIOPS对应的延迟中位数为:
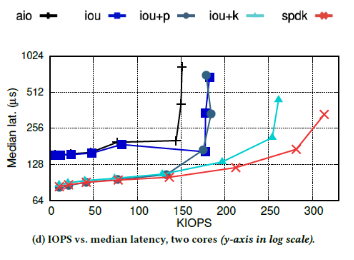
此时,iou+k的性能仅次于SPDK:最大带宽比SPDK小18%,延迟和SPDK相当。
② SPDK在所有场景下性能最好,也是唯一达到驱动带宽上限的API。SPDK和iou+k的区别在于,iou+k使用两个线程访问同一个变量,会产生原子访问和缓存失效的开销,而SPDK使用一个线程,能更加充分的利用资源。
③ 当IOPS较小时,iou+p的性能和SPDK接近,因为队列深度较小时,系统调用的开销还不足以成为性能瓶颈,此时系统态轮询和用户态轮询的性能接近。类似的还有iou和libaio,当队列深度小于16时,二者KIOPS和延迟都很接近,当队列深度大于16后,iou的KIOPS和延迟比libaio要好——因为iou使用的系统调用比libaio少,所以可以更加充分的利用CPU资源。
当队列深度小于16时,iou的系统调用比iou+p少,但延迟比iou+p高。原因是,队列较浅时,fio的队列很快会被填满,而当队列满时,fio会等待至少一个请求完成再进行下一步动作。此时,虽然中断比较慢,但iou可能会一次处理较多完成的请求,而轮询则是检测到一个请求完成就退出,从而错失了批量处理多个完成的请求的机会。当队列深度增加时,两个API最后都趋向于每个I/O请求只使用1个系统调用。
iou和libaio的最大区别是,iou多了一个提交队列(SQ),这就是它具有批处理能力的原因。
2、不同的CPU-设备比
作者进一步分析了对于iou+k,每个驱动需要多少个CPU以获得最佳性能。此时,作者使用了J=5个FIO job测试,每个job运行在不同的驱动上,队列深度为128,C代表CPU的数目,本次实验中,分别测试了C=J,C=J+1,C=J+2和C=J*2的情况。
注意,在iou+k中,内核会为每个job产生一个内核线程以轮询SQ获得提交的请求。
实验结果如下图:

可见,除了iou+k,其他API的带宽表现和CPU-设备比无关。而iou+k需要两倍于驱动数的CPU才能达到最好的性能——即每个线程需要一个单独的CPU来轮询。糟糕的是,当CPU数不是最佳时,iou+k的KIOPS是最低的。这一实验结果揭示了iou+k要实现高性能的隐藏开销,而其他测试忽略了这一点。
3、可扩展性
作者控制job从1到20,以测试不同API的可扩展性。每个job访问不同的驱动,设置CPU数C=2*J(由于硬件限制,C最大可以取到20),队列深度为128。下图是测试结果:
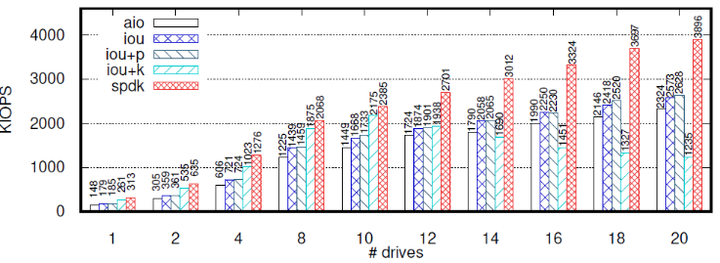
SPDK的性能总是最好的,而性能第二好的API取决于job的数量和CPU核的数量。当J不大于10时,iou+k可以给每个内核线程分配一个CPU,性能最好。此后随着J的增大,内核线程和应用线程开始抢夺CPU资源,KIOPS开始下滑。在J=12时,iou+k和iou、iou+p的KIOPS交汇,在J=14时,iou+k成为性能最差的API。其他的API随着job的增长,KIOPS也基本上稳定增长。
iou和iou+p的性能很接近,libaio的带宽也仅仅比iou、iou+p少10%。
【总结与讨论】
1、不同的轮询方式各有特点
-
lSPDK的优势不仅仅体现在用户态轮询、无系统调用开销,还体现在使用单个线程进行轮询。
-
liou+k的优势在CPU不够时不明显。
-
liou+p使用系统级轮询,在队列深度较小时可以和SPDK相当。
2、io_uring在特定配置下的性能接近SPDK3、性能的可扩展性需要仔细考虑
虽然SPDK的性能最好,但需要放弃Linux文件的支持。如果需要使用文件系统,且CPU足够多,iou+k是不错的选择(可以达到90% SPDK的性能),而若CPU资源不足,可以使用iou+p,当队列深度不深时和SPDK的性能接近。
未来可以在更在实际的I/O密集型应用上测试,如数据库。它们都需要文件系统的支持,可能会带来额外的同步开销,可能会覆盖I/O路径上的bottleneck。此外还可以研究更高效的iou+k设计,如不同的应用线程共享一个内核轮询线程,或者二者更好的使用CPU资源等。最后,io_uring支持socket I/O,所以它的性能也可以测试以评估网络应用的表现。

