
- 1Mysql客户端Android版的开源产品_手机版数据库连接工具
- 2Linux 的父进程和子进程的执行情况(附有案例代码)_linux进程的创建父进程创建子进程程序的执行顺序有什么特征
- 3Latex英文论文模板汇总(elsevier、arXiv、IEEE Access)
- 4Vue 数组添加元素的三种方式_vue集合添加元素
- 5【愚公系列】2023年12月 HarmonyOS教学课程 031-ArkUI动画(组件内转场动画)_鸿蒙foreach 动画
- 6解放生产力!10个开发编程变成插件 告别加班 每一款都可以当GPT来用
- 7Windows GDI句柄分析_windbg gdi句柄
- 8在主函数输入10个等长的字符串,用另一函数对他们排序, 然后在主函数输出这10个已经排好序的字符串。_在主函数中输入10个等长的字符串。用另一个函数对它们排序,然后在主函数输出这10
- 9近几年计算机毕设之论文参考文献(Java参考文献、MySQL参考文献、jsp参考文献、Python参考文献、微信小程序参考文献、外文参考文献)(10个一组)_参考文献计算机专业
- 10Vue—— vuex详解,彻底搞懂vuex
什么是扩散模型(Diffusion Models)?_扩散模型和gan的区别
赞
踩
1. 到目前为止,有3种类型的生成模型,即GAN、VAE和基于Flow的模型。它们在生成高质量样本方面获得了巨大的成功,但每一种都有其自身的一些局限性。例如,GAN模型由于其对抗性训练的性质,以潜在的不稳定的训练和较少的生成多样性而闻名。VAE依赖于代用损失。基于Flow的模型必须使用专门的架构来构建可逆变换。
GAN要训练两个网络(生成器和判别器),难度较大,容易不收敛,而且多样性比较差,只要能骗过判别器就行;而Diffusion model用一种更为简单的方法来诠释生成模型该如何学习以及生成,更为简单.
Diffusion Models(扩散模型)是一类新兴的生成模型,相对于GAN(生成对抗网络),具有以下一些优势:
易于训练和调节:GAN的训练过程相对困难,需要同时训练一个生成器和一个判别器,并且需要小心平衡二者的权衡。而扩散模型则采用自回归过程进行训练,具有更加直观和简单的训练流程,也更加易于调节。
生成图像更加稳定:GAN的生成结果可能存在模式崩塌和模式噪声等问题,这是因为GAN模型的生成过程是一个非常不稳定的过程。扩散模型通过迭代地将噪声图像转化为目标图像,可以生成更加稳定和清晰的图像。
难以攻击:GAN可能存在对抗样本攻击的问题,即攻击者可能通过修改输入噪声图像,生成看起来相似但含有误导信息的图像。扩散模型则具有更强的抗攻击性,因为其生成过程是基于扩散过程进行的,不容易受到针对输入噪声的攻击。
更加可解释:扩散模型生成过程基于一系列扩散过程,可以进行详细的解释和可视化,有利于深入理解生成图像的过程和机制。
总之,扩散模型相对于GAN具有更加直观、稳定、抗攻击和可解释的优势,这使得扩散模型成为了生成模型领域的一个重要研究方向。
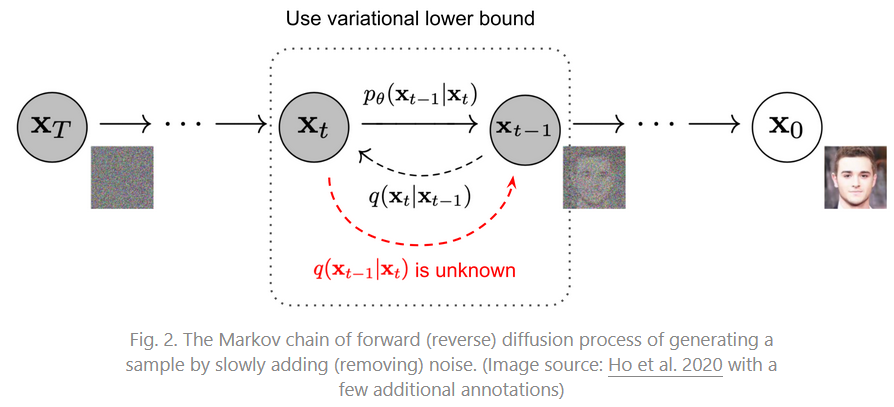
2. 扩散模型(Diffusion Models)是受非平衡热力学(Non-equilibrium thermodynamics )的启发。它们定义了一个扩散步骤的马尔可夫链(Markov chain),以缓慢地向数据添加随机噪声,然后学习逆转扩散过程(learn to reverse the diffusion process),从噪声中构建所需的数据样本。与VAE或基于Flow的模型不同的是,扩散模型是以固定的程序学习的,潜在的变量具有高维度(与原始数据相同)。

What are Diffusion Models?
1. 一些基于扩散的生成模型被提出,其下有类似的想法,包括扩散概率模型(diffusion probabilistic models,Sohl-Dickstein et al.,2015)、噪声条件下的得分网络(noise-conditioned score network, NCSN, Yang & Ermon,2019),以及去噪扩散概率模型(denoising diffusion probabilistic models, DDPM, Ho等,2020).
给出一个从真实数据分布中采样的数据点
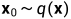 , 让我们定义一个前向扩散过程(Forward diffusion process),在这个过程中,我们以T个步骤向样本添加少量高斯噪声,产生一连串的噪声样本
, 让我们定义一个前向扩散过程(Forward diffusion process),在这个过程中,我们以T个步骤向样本添加少量高斯噪声,产生一连串的噪声样本 .步长是由一个方差表控制
.步长是由一个方差表控制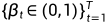 .
.
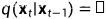
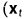 ;
;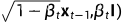 ,
,
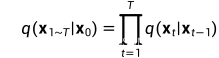
随着步长t的增大,数据样本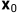 逐渐失去了其可辨识的特征。最终当
逐渐失去了其可辨识的特征。最终当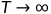 ,
,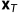 相当于一个各向同性的高斯分布(isotropic Gaussian distribution)。你要去噪,首先要知道噪音是什么加进去的?
相当于一个各向同性的高斯分布(isotropic Gaussian distribution)。你要去噪,首先要知道噪音是什么加进去的?
第一件事是做扩散(加噪),第二件事是做复原(去噪).
前向过程:不断往输入数据中加入噪声,最后变成了纯噪声;
其实每个时刻都要添加高斯噪声,后一时刻都是由前一时刻增加噪声得到;
其实这个过程可以看成我们不断构建标签(噪声)的过程,后续会用到。
第一个重要公式,如何得到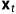 时刻的分布呢?(前向过程)
时刻的分布呢?(前向过程)
令

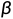 (权重)是先验知识,要越来越大,论文中0.0001到0.002(经验值),从而
(权重)是先验知识,要越来越大,论文中0.0001到0.002(经验值),从而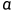 叫做衰减函数,要越来越小。
叫做衰减函数,要越来越小。
解释:一开始加的噪声小,稍微扩散一点,变化就比较多了. 而到了后面,例如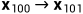 ,则需要加入多一些的噪声才行,才能更扩散。即随着时间t的增大,加噪越来越多(要越来越大).
,则需要加入多一些的噪声才行,才能更扩散。即随着时间t的增大,加噪越来越多(要越来越大).

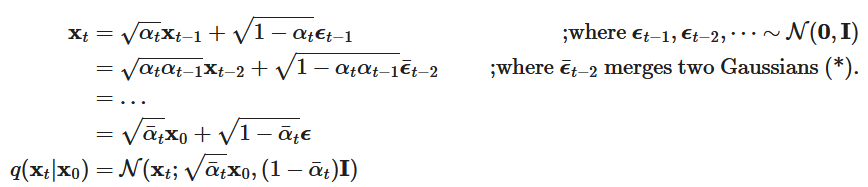
备注(本人推导):
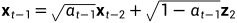 一步步来,再往前一时刻我们也能计算
一步步来,再往前一时刻我们也能计算

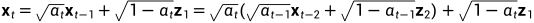
其中每次加入的噪声都不一样,是随机的,但都服从高斯分布 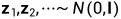 (加入的噪声在标准高斯/正态分布中随机采样得到)
(加入的噪声在标准高斯/正态分布中随机采样得到)

因为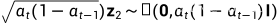 , 相等于对
, 相等于对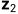 的方差做了改变
的方差做了改变
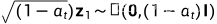 ,相等于对
,相等于对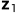 的方差做了改变
的方差做了改变
根据独立高斯分布可加性:

所以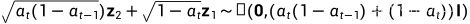 .
.
化简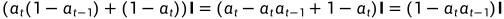 ,
,
所以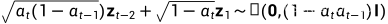
最后得到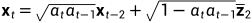 ,其中
,其中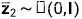
以此类推,

